Informationsövervakning av Apache Spark-program
Med Microsoft Fabric kan du använda Apache Spark för att köra notebook-filer, jobb och andra typer av program på din arbetsyta. Den här artikeln beskriver hur du övervakar ditt Apache Spark-program så att du kan hålla ett öga på den senaste körningsstatusen, problemen och förloppet för dina jobb.
Visa Apache Spark-program
Du kan visa alla Apache Spark-program från Spark-jobbdefinitionen eller snabbmenyn för notebook-objekt som visar det senaste körningsalternativet ->Senaste körningar.

Du kan välja namnet på det program som du vill visa i programlistan. På sidan programinformation kan du visa programinformationen.
Övervaka Apache Spark-programstatus
Öppna sidan Senaste körningar i notebook- eller Spark-jobbdefinitionen. Du kan visa status för Apache-programmet.
- Klart

- I kö

- Stoppat

- Avbruten

- Misslyckad

Projekt
Öppna ett Apache Spark-programjobb från snabbmenyn För Spark-jobbdefinition eller notebook-objekt visas alternativet Senaste körning –> Senaste körningar –> välj ett jobb på sidan senaste körningar.
På sidan med övervakningsinformation för Apache Spark-programmet visas listan över jobbkörningar på fliken Jobb. Du kan visa information om varje jobb här, inklusive Jobb-ID, Beskrivning, Status, Steg, Uppgifter, Varaktighet, Bearbetad, Dataläsning, Data som skrivits och Kodfragment.
- Om du klickar på Jobb-ID kan du expandera/komprimera jobbet.
- Klicka på jobbbeskrivningen. Du kan gå till jobb- eller fassidan i Spark-användargränssnittet.
- Klicka på kodfragmentet för jobbet. Du kan kontrollera och kopiera koden som är relaterad till det här jobbet.

Resurser (förhandsversion)
Grafen för körningsanvändning visar visuellt allokeringen av Spark-jobbexekutorer och resursanvändning. För närvarande visas endast körningsinformationen för spark 3.4 och senare den här funktionen. Välj Resurser (förhandsversion) och sedan utformas fyra typer av kurvor för körningsanvändning, inklusive Körning, Inaktivt, Allokerat, Maximalt antal instanser.

För Allokerad refererar till den kärnsituation som allokeras under körningen av Spark-programmet.
För Maximalt antal instanser refererar till det maximala antalet kärnor som allokerats till Spark-programmet.
För Körs refererar till det faktiska antalet kärnor som används av Spark-programmet när det körs. Klicka vid en tidpunkt när Spark-programmet körs. Du kan se allokeringsinformationen för körbara exekutorkärnor längst ned i diagrammet.
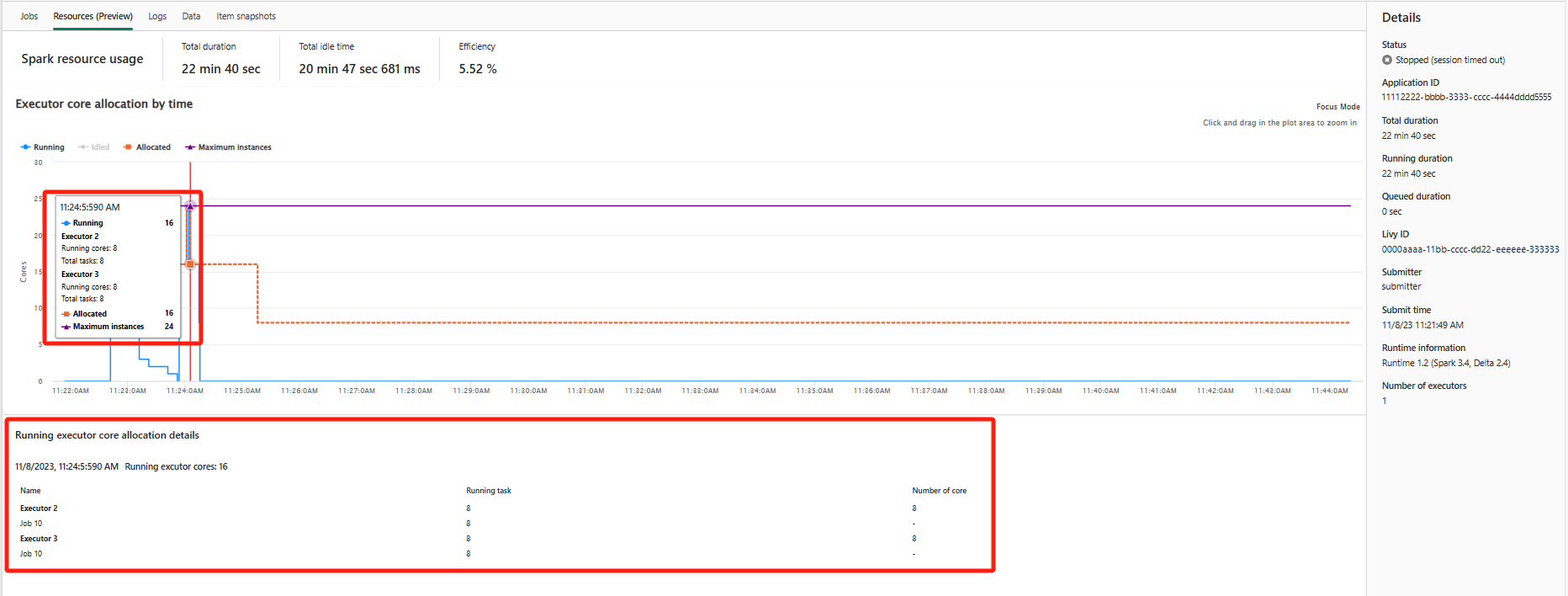
För Idled är det antalet oanvända kärnor medan Spark-programmet körs.

I vissa fall kan antalet uppgifter vid vissa tidpunkter överskrida kapaciteten för körkärnor (dvs. uppgiftsnummer > , totalt antal executor-kärnor/spark.task.cpus). Det här är som förväntat, eftersom det finns ett tidsgap mellan en aktivitet som markerats som körs och den faktiskt körs på en körkärna. Vissa uppgifter kan därför visas som körs, men de körs inte på någon kärna.
Välj färgikonen för att markera eller avmarkera motsvarande innehåll i alla diagram.

Sammanfattningspanel
På sidan Övervakning av Apache Spark-program klickar du på knappen Egenskaper för att öppna/komprimera sammanfattningspanelen. Du kan visa information för det här programmet i Information.
- Status för det här Spark-programmet.
- Spark-programmets ID.
- Total varaktighet.
- Kör varaktighet för det här Spark-programmet.
- Köad varaktighet för det här Spark-programmet.
- Livy ID
- Skicka för det här Spark-programmet.
- Skicka tid för det här Spark-programmet.
- Antal utförare.

Loggar
På fliken Loggar kan du visa hela loggen för Livy, Prelaunch, Drivrutinsloggen med olika alternativ valda i den vänstra panelen. Och du kan hämta nödvändig logginformation direkt genom att söka efter nyckelord och visa loggarna genom att filtrera loggstatusen. Klicka på Ladda ned logg för att ladda ned logginformationen till den lokala.
Ibland är inga loggar tillgängliga, till exempel att jobbets status placeras i kö och att klusterskapandet misslyckades.
Liveloggar är endast tillgängliga när appöverföringen misslyckas och drivrutinsloggar tillhandahålls också.

Data
På fliken Data kan du kopiera datalistan i Urklipp, ladda ned datalistan och enskilda data och kontrollera egenskaperna för varje data.
- Den vänstra panelen kan expanderas eller komprimeras.
- Namn, läsformat, storlek, källa och sökväg för indata- och utdatafilerna visas i den här listan.
- Filerna i indata och utdata kan laddas ned, kopiera sökväg och visa egenskaper.

Ögonblicksbilder av objekt
På fliken Objektögonblicksbilder kan du bläddra bland och visa objekt som är associerade med Apache Spark-programmet, inklusive Notebooks, Spark-jobbdefinition och/eller pipelines. Sidan ögonblicksbilder av objekt visar ögonblicksbilden av kod- och parametervärdena vid tidpunkten för körningen för Notebooks. Den visar också ögonblicksbilden av alla inställningar och parametrar vid tidpunkten för sändningen av Spark-jobbdefinitioner. Om Apache Spark-programmet är associerat med en pipeline visar den relaterade objektsidan även motsvarande pipeline och Spark-aktiviteten.
På skärmen Objektögonblicksbilder kan du:
- Bläddra bland och navigera i relaterade objekt i det hierarkiska trädet.
- Klicka på ellipsikonen "En lista över fler åtgärder" för varje objekt för att vidta olika åtgärder.
- Klicka på ögonblicksbildobjektet för att visa dess innehåll.
- Visa Sökvägen för att se sökvägen från det markerade objektet till roten.

Kommentar
Funktionen ögonblicksbilder av notebook-filer stöder för närvarande inte notebook-filer som körs eller i en Spark-session med hög samtidighet.
Diagnostik
Diagnostikpanelen ger användarna rekommendationer i realtid och felanalys som genereras av Spark Advisor genom en analys av användarens kod. Med inbyggda mönster hjälper Apache Spark Advisor användarna att undvika vanliga misstag och analyserar fel för att identifiera sin rotorsak.

Relaterat innehåll
Nästa steg när du har tittat på information om ett Apache Spark-program är att visa Spark-jobbframsteg under notebook-cellen. Du kan läsa följande: