Använda Livy-API:et för att skicka och köra Livy-batchjobb
Kommentar
Livy API för Fabric Dataingenjör ing finns i förhandsversion.
Gäller för:✅ Dataingenjör ing och Datavetenskap i Microsoft Fabric
Skicka Spark-batchjobb med livy-API:et för Fabric-Dataingenjör ing.
Förutsättningar
Fabric Premium - eller Utvärderingskapacitet med en Lakehouse.
En fjärrklient som Visual Studio Code med Jupyter Notebooks, PySpark och Microsoft Authentication Library (MSAL) för Python.
En Microsoft Entra-apptoken krävs för att få åtkomst till Rest-API:et för infrastrukturresurser. Registrera ett program med Microsofts identitetsplattform.
Vissa data i ditt lakehouse använder det här exemplet NYC Taxi & Limousine Commission green_tripdata_2022_08 en parquet-fil som lästs in till lakehouse.
Livy-API:et definierar en enhetlig slutpunkt för åtgärder. Ersätt platshållarna {Entra_TenantID}, {Entra_ClientID}, {Fabric_WorkspaceID} och {Fabric_LakehouseID} med lämpliga värden när du följer exemplen i den här artikeln.
Konfigurera Visual Studio Code för ditt Livy API Batch
Välj Lakehouse-inställningar i din Fabric Lakehouse.

Gå till avsnittet Livy-slutpunkt .
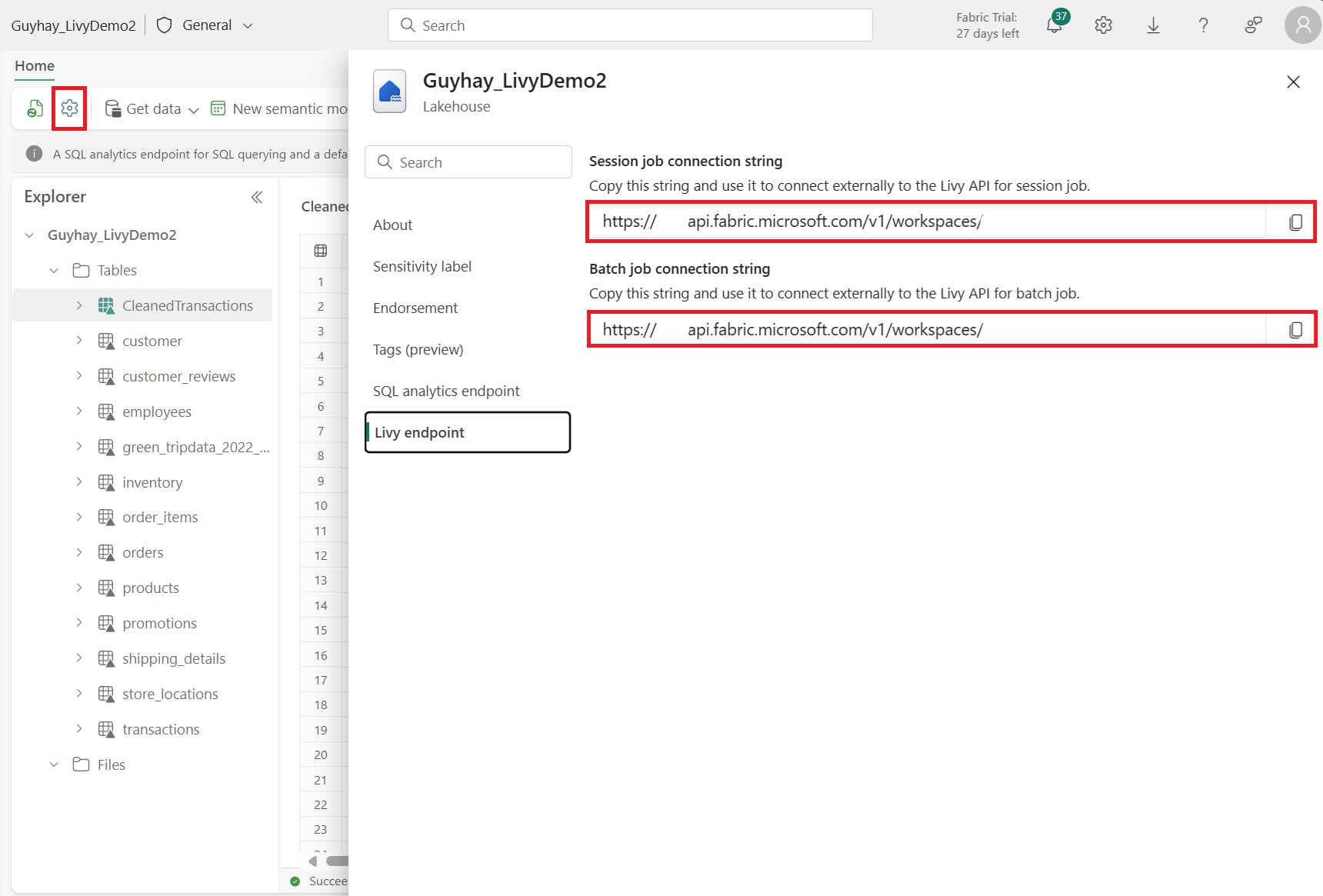
Kopiera Batch-jobbet anslutningssträng (den andra röda rutan i bilden) till koden.
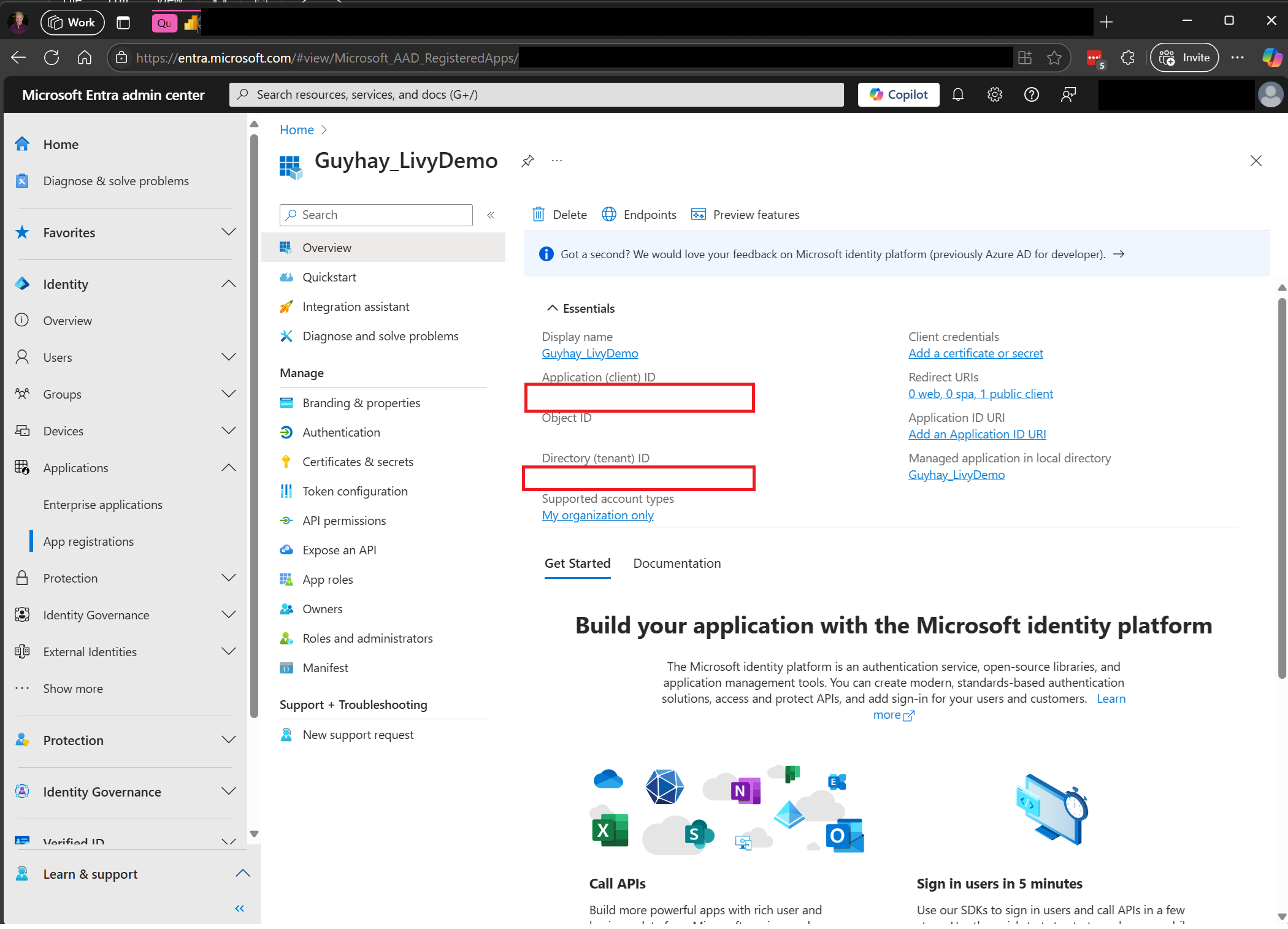
Gå till administrationscentret för Microsoft Entra och kopiera både program-ID:t (klient-) och katalog-ID:t (klientorganisation) till din kod.



Skapa en Spark-nyttolast och ladda upp till lakehouse
Skapa en
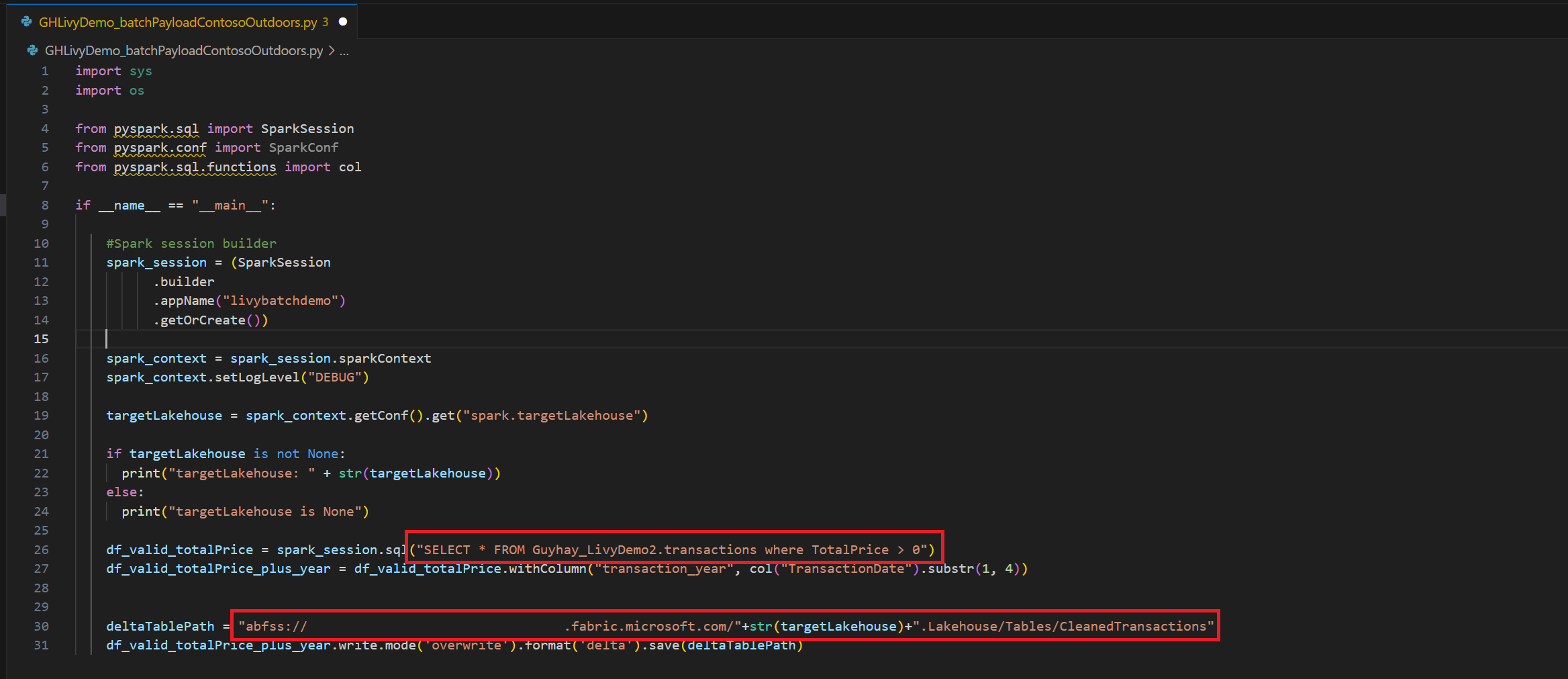
.ipynbnotebook-fil i Visual Studio Code och infoga följande kodimport sys import os from pyspark.sql import SparkSession from pyspark.conf import SparkConf from pyspark.sql.functions import col if __name__ == "__main__": #Spark session builder spark_session = (SparkSession .builder .appName("livybatchdemo") .getOrCreate()) spark_context = spark_session.sparkContext spark_context.setLogLevel("DEBUG") targetLakehouse = spark_context.getConf().get("spark.targetLakehouse") if targetLakehouse is not None: print("targetLakehouse: " + str(targetLakehouse)) else: print("targetLakehouse is None") df_valid_totalPrice = spark_session.sql("SELECT * FROM <YourLakeHouseDataTableName>.transactions where TotalPrice > 0") df_valid_totalPrice_plus_year = df_valid_totalPrice.withColumn("transaction_year", col("TransactionDate").substr(1, 4)) deltaTablePath = "abfss:<YourABFSSpath>"+str(targetLakehouse)+".Lakehouse/Tables/CleanedTransactions" df_valid_totalPrice_plus_year.write.mode('overwrite').format('delta').save(deltaTablePath)Spara Python-filen lokalt. Den här Python-kodnyttolasten innehåller två Spark-instruktioner som fungerar med data i ett Lakehouse och som måste laddas upp till lakehouse. Du behöver ABFS-sökvägen för nyttolasten som referens i ditt Livy API-batchjobb i Visual Studio Code och Lakehouse-tabellnamnet i SELECT SQL-instruktionen.
Ladda upp Python-nyttolasten till filavsnittet i Lakehouse. > Hämta data > Överför filer > klickar du i rutan Filer/indata.
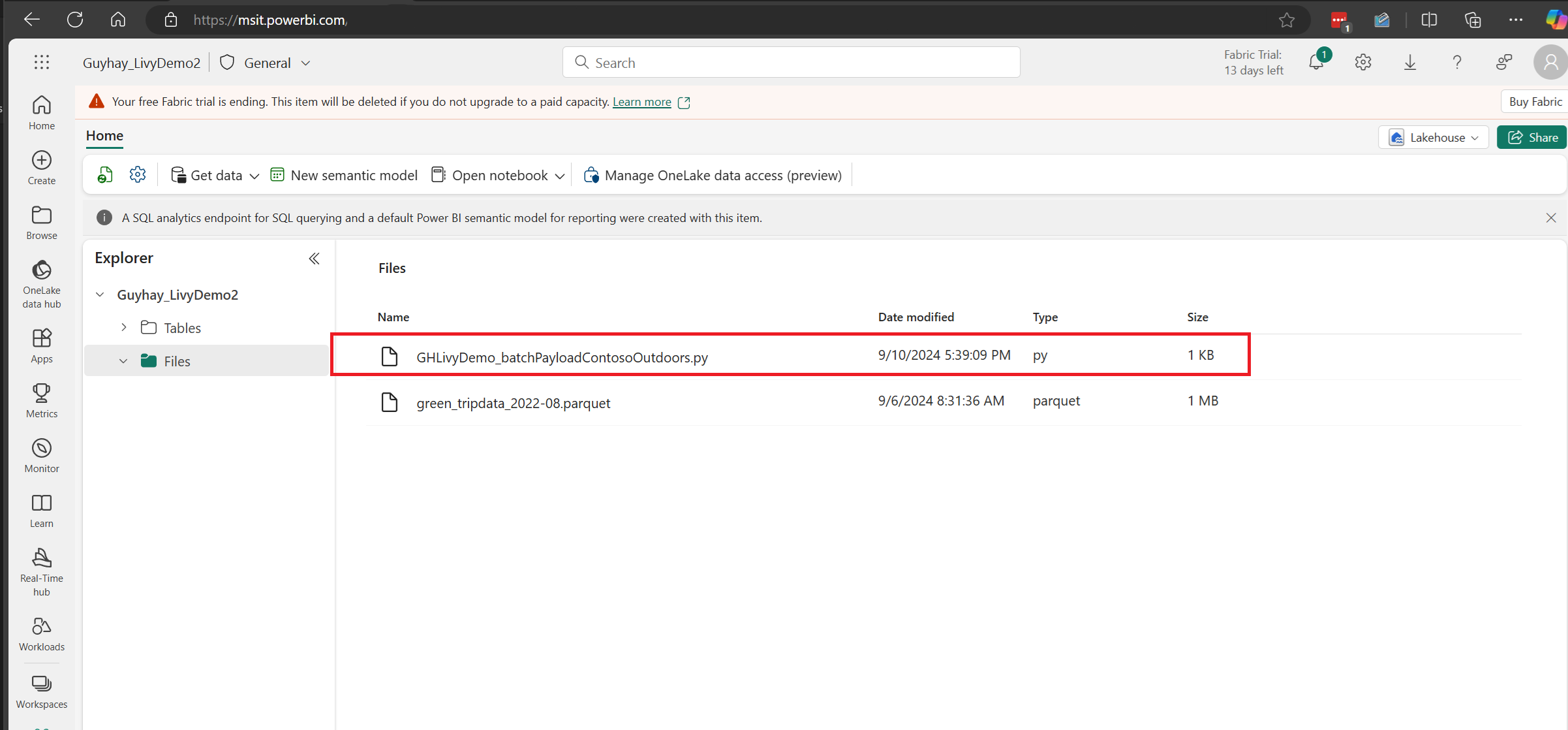
När filen finns i avsnittet Filer i Lakehouse klickar du på de tre punkterna till höger om nyttolastfilens namn och väljer Egenskaper.
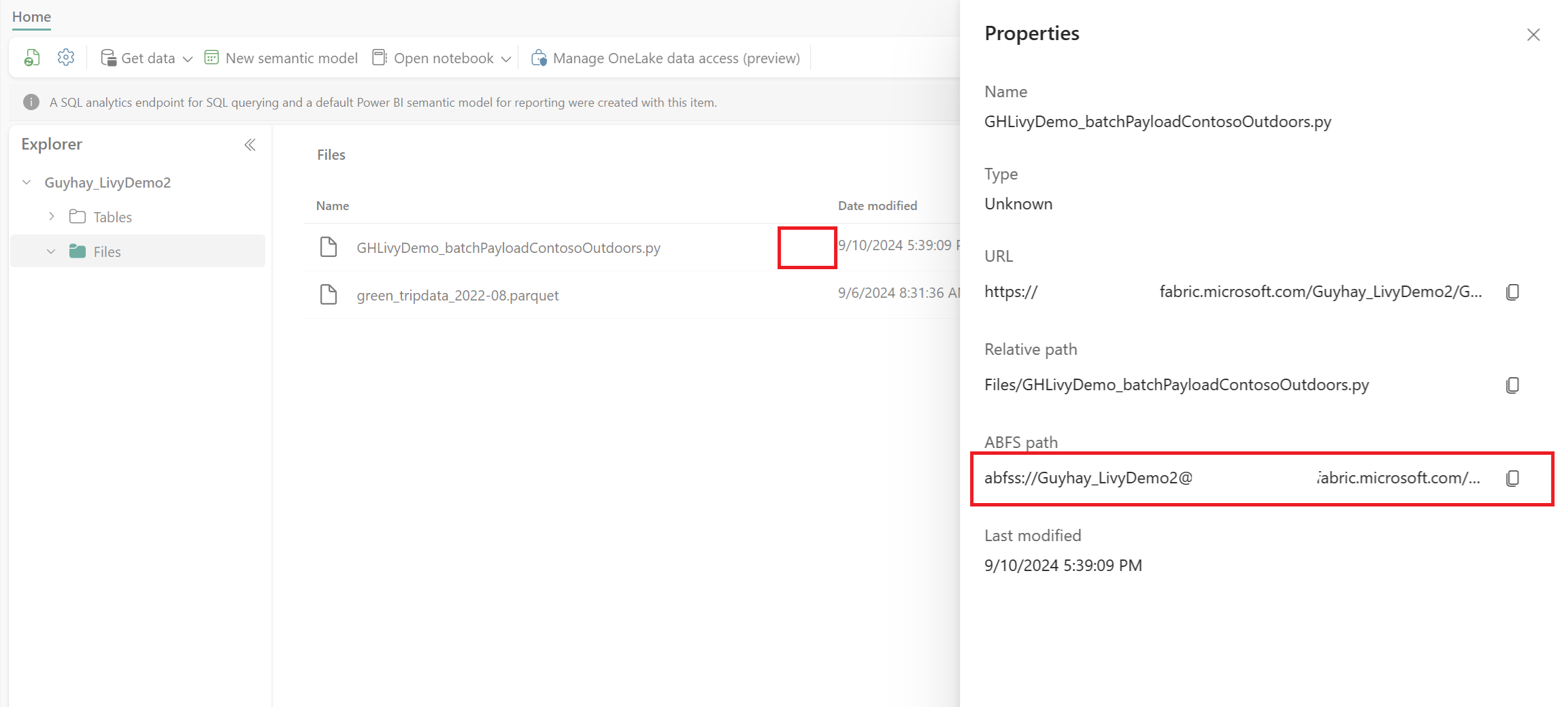
Kopiera den här ABFS-sökvägen till notebook-cellen i steg 1.



Skapa en Livy API Spark-batchsession
Skapa en
.ipynbnotebook-fil i Visual Studio Code och infoga följande kod.from msal import PublicClientApplication import requests import time tenant_id = "<Entra_TenantID>" client_id = "<Entra_ClientID>" workspace_id = "<Fabric_WorkspaceID>" lakehouse_id = "<Fabric_LakehouseID>" app = PublicClientApplication( client_id, authority="https://login.microsoftonline.com/43a26159-4e8e-442a-9f9c-cb7a13481d48" ) result = None # If no cached tokens or user interaction needed, acquire tokens interactively if not result: result = app.acquire_token_interactive(scopes=["https://api.fabric.microsoft.com/Lakehouse.Execute.All", "https://api.fabric.microsoft.com/Lakehouse.Read.All", "https://api.fabric.microsoft.com/Item.ReadWrite.All", "https://api.fabric.microsoft.com/Workspace.ReadWrite.All", "https://api.fabric.microsoft.com/Code.AccessStorage.All", "https://api.fabric.microsoft.com/Code.AccessAzureKeyvault.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataExplorer.All", "https://api.fabric.microsoft.com/Code.AccessAzureDataLake.All", "https://api.fabric.microsoft.com/Code.AccessFabric.All"]) # Print the access token (you can use it to call APIs) if "access_token" in result: print(f"Access token: {result['access_token']}") else: print("Authentication failed or no access token obtained.") if "access_token" in result: access_token = result['access_token'] api_base_url_mist='https://api.fabric.microsoft.com/v1' livy_base_url = api_base_url_mist + "/workspaces/"+workspace_id+"/lakehouses/"+lakehouse_id +"/livyApi/versions/2023-12-01/batches" headers = {"Authorization": "Bearer " + access_token}Kör notebook-cellen. Ett popup-fönster bör visas i webbläsaren så att du kan välja den identitet som du vill logga in med.
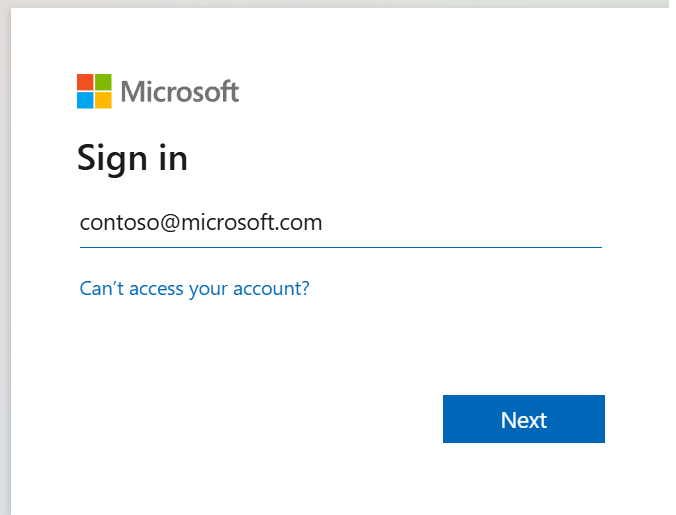
När du har valt den identitet som du vill logga in med uppmanas du också att godkänna API-behörigheterna för Microsoft Entra-appregistrering.
Stäng webbläsarfönstret när autentiseringen har slutförts.

I Visual Studio Code bör du se att Microsoft Entra-token returneras.
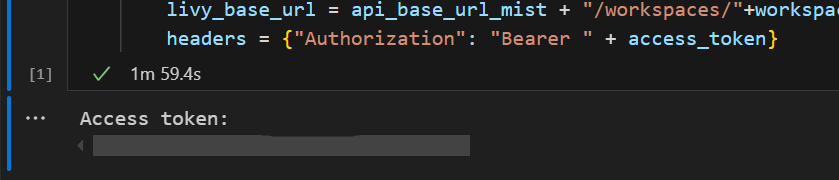
Lägg till ytterligare en notebook-cell och infoga den här koden.
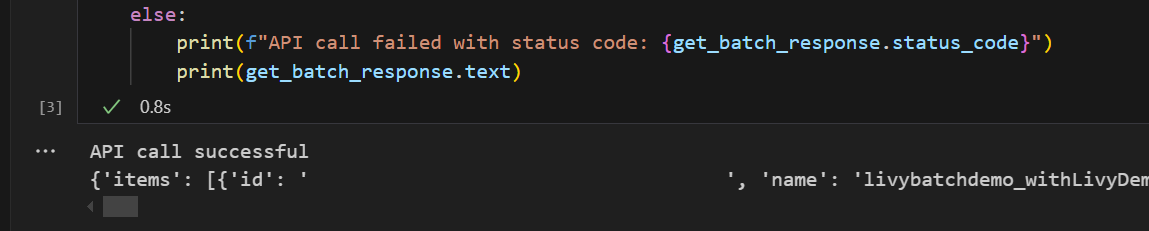
# call get batch API get_livy_get_batch = livy_base_url get_batch_response = requests.get(get_livy_get_batch, headers=headers) if get_batch_response.status_code == 200: print("API call successful") print(get_batch_response.json()) else: print(f"API call failed with status code: {get_batch_response.status_code}") print(get_batch_response.text)Kör notebook-cellen. Du bör se två rader som skrivs ut när Livy-batchjobbet skapas.





Skicka en spark.sql-instruktion med batchsessionen för Livy API
Lägg till ytterligare en notebook-cell och infoga den här koden.
# submit payload to existing batch session print('Submit a spark job via the livy batch API to ') newlakehouseName = "YourNewLakehouseName" create_lakehouse = api_base_url_mist + "/workspaces/" + workspace_id + "/items" create_lakehouse_payload = { "displayName": newlakehouseName, "type": 'Lakehouse' } create_lakehouse_response = requests.post(create_lakehouse, headers=headers, json=create_lakehouse_payload) print(create_lakehouse_response.json()) payload_data = { "name":"livybatchdemo_with"+ newlakehouseName, "file":"abfss://YourABFSPathToYourPayload.py", "conf": { "spark.targetLakehouse": "Fabric_LakehouseID" } } get_batch_response = requests.post(get_livy_get_batch, headers=headers, json=payload_data) print("The Livy batch job submitted successful") print(get_batch_response.json())Kör notebook-cellen. Du bör se flera rader som skrivs ut när Livy Batch-jobbet skapas och körs.

Gå tillbaka till Lakehouse för att se ändringarna.

Visa dina jobb i övervakningshubben
Du kan komma åt övervakningshubben för att visa olika Apache Spark-aktiviteter genom att välja Övervaka i navigeringslänkarna till vänster.
När batchjobbet har slutförts kan du visa sessionsstatusen genom att gå till Övervaka.
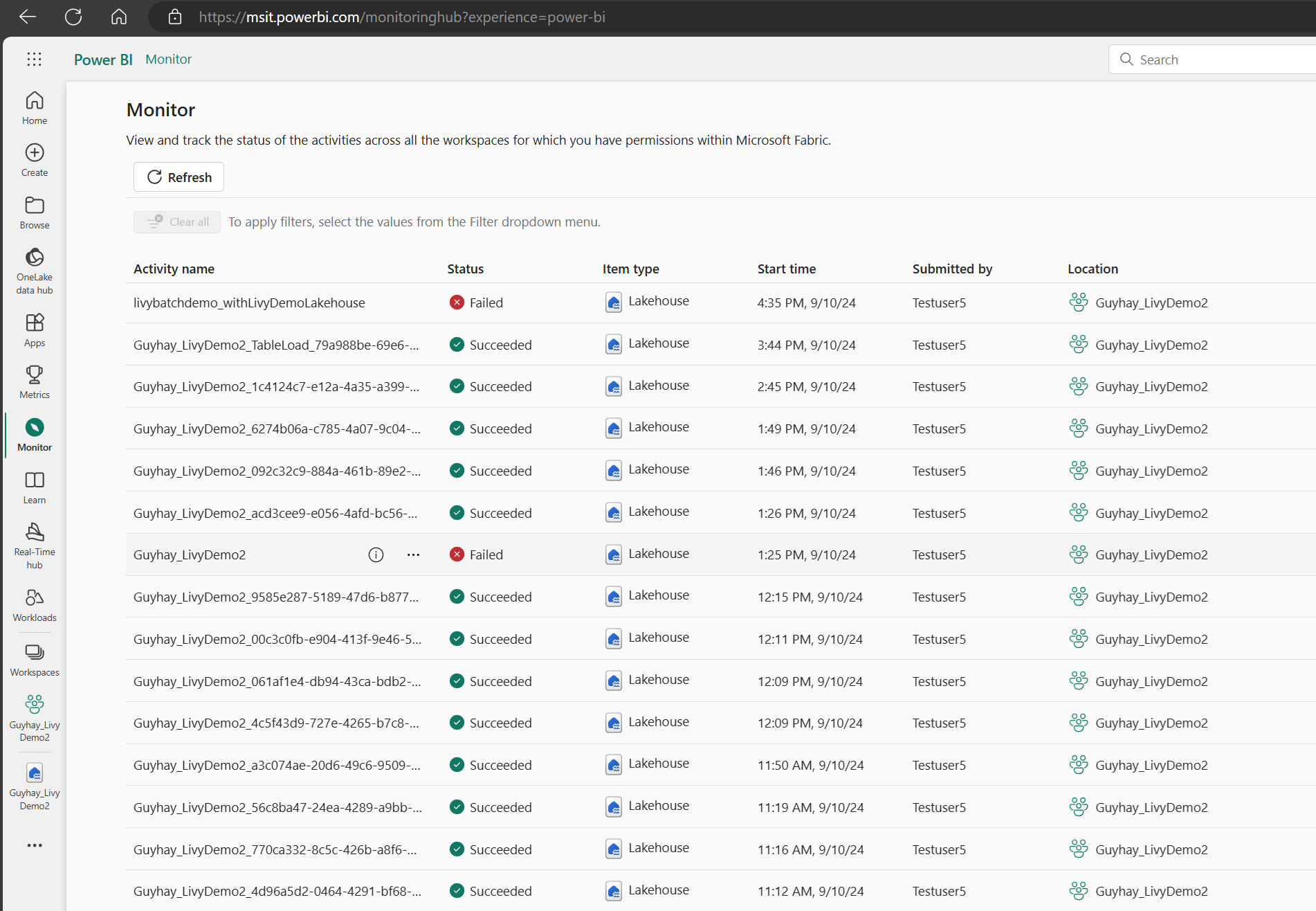
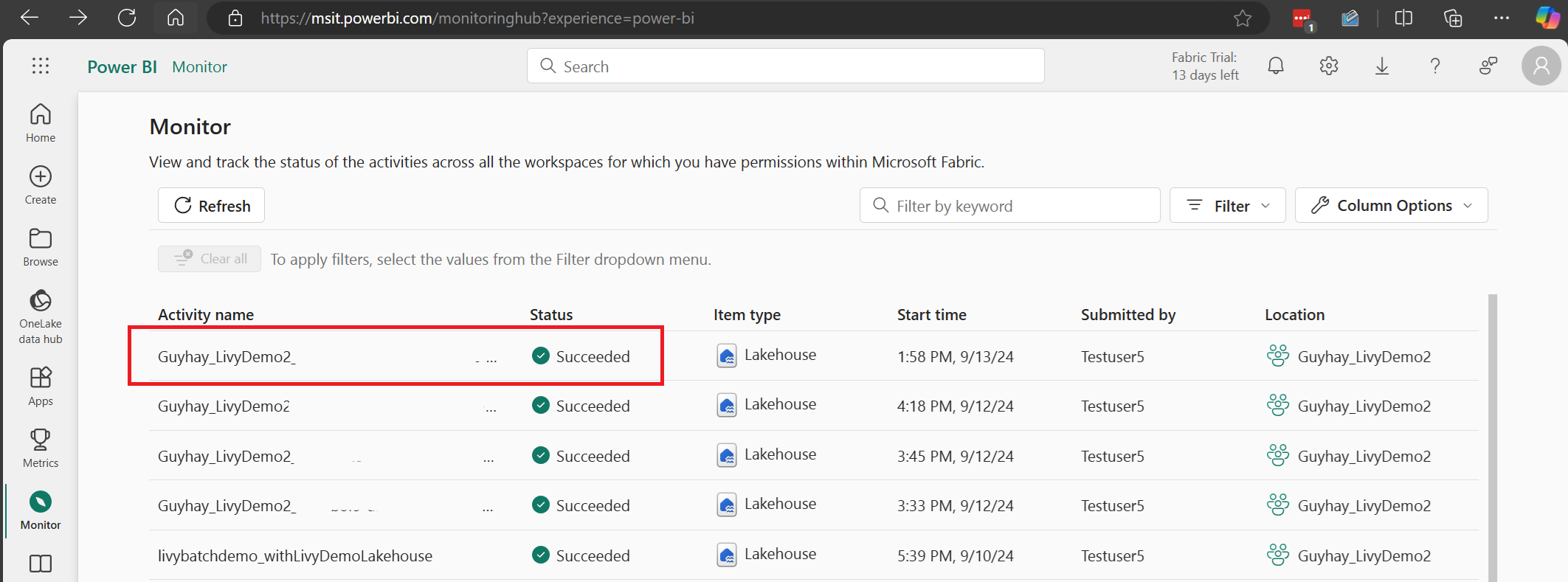
Välj och öppna det senaste aktivitetsnamnet.
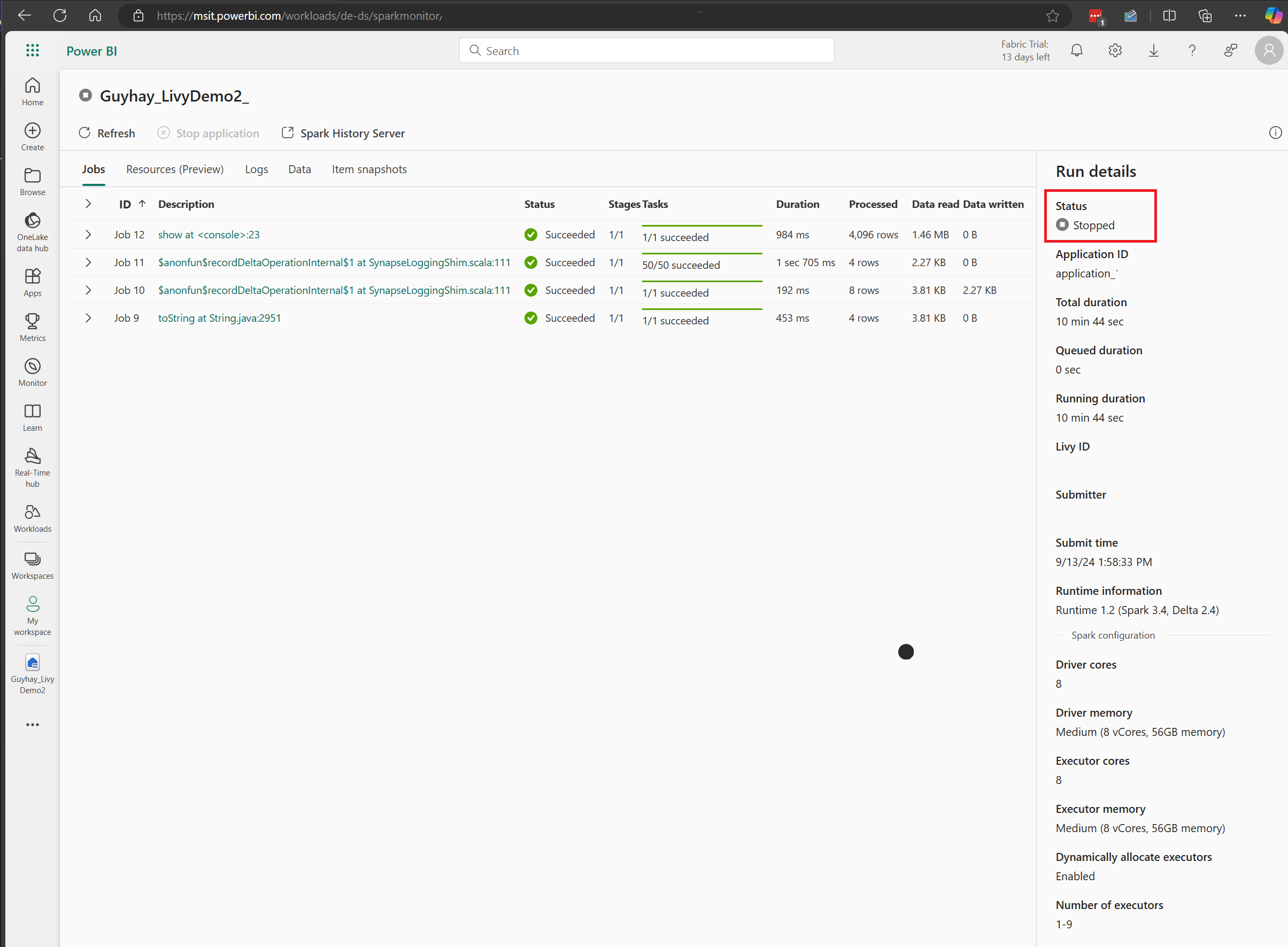
I det här Livy API-sessionsfallet kan du se din tidigare batchöverföring, körningsinformation, Spark-versioner och konfiguration. Observera den stoppade statusen längst upp till höger.



För att sammanfatta hela processen behöver du en fjärrklient som Visual Studio Code, en Microsoft Entra-apptoken, Livy API-slutpunkts-URL, autentisering mot Lakehouse, en Spark-nyttolast i Lakehouse och slutligen en Batch Livy API-session.