Rapportering av fakturering och användning för Apache Spark i Microsoft Fabric
Gäller för:✅ Dataingenjör ing och Datavetenskap i Microsoft Fabric
Den här artikeln beskriver beräkningsanvändningen och rapporteringen för ApacheSpark som driver arbetsbelastningarna Fabric Dataingenjör ing och Science i Microsoft Fabric. Beräkningsanvändningen omfattar lakehouse-åtgärder som förhandsversion av tabeller, inläsning till delta, notebook-körningar från gränssnittet, schemalagda körningar, körningar som utlöses av notebook-steg i pipelines och Apache Spark-jobbdefinitionskörningar.
Precis som andra upplevelser i Microsoft Fabric använder Dataingenjör ing även den kapacitet som är associerad med en arbetsyta för att köra det här jobbet och dina totala kapacitetsavgifter visas i Azure Portal under din Microsoft Cost Management-prenumeration. Mer information om infrastrukturfakturering finns i Förstå din Azure-faktura på en Infrastrukturkapacitet.
Infrastrukturkapacitet
Du som användare kan köpa en Fabric-kapacitet från Azure genom att ange med hjälp av en Azure-prenumeration. Kapacitetens storlek avgör hur mycket beräkningskraft som är tillgänglig. För Apache Spark för Fabric översätts varje CU som köpts till 2 virtuella Apache Spark-kärnor. Om du till exempel köper en Infrastrukturkapacitet F128 översätts detta till 256 SparkVCores. En infrastrukturresurskapacitet delas över alla arbetsytor som läggs till i den och där den totala tillåtna Apache Spark-beräkningen delas mellan alla jobb som skickas från alla arbetsytor som är associerade till en kapacitet. Information om de olika SKU:erna, allokering och begränsning av kärnor på Spark finns i Samtidighetsgränser och köer i Apache Spark för Microsoft Fabric.
Spark-beräkningskonfiguration och köpt kapacitet
Apache Spark-beräkning för Fabric erbjuder två alternativ när det gäller beräkningskonfiguration.
Startpooler: Dessa standardpooler är snabba och enkla sätt att använda Spark på Microsoft Fabric-plattformen inom några sekunder. Du kan använda Spark-sessioner direkt i stället för att vänta på att Spark ska konfigurera noderna åt dig, vilket hjälper dig att göra mer med data och få insikter snabbare. När det gäller fakturering och kapacitetsförbrukning debiteras du när du börjar köra notebook-filen eller Spark-jobbdefinitionen eller lakehouse-åtgärden. Du debiteras inte för den tid som klustren är inaktiva i poolen.
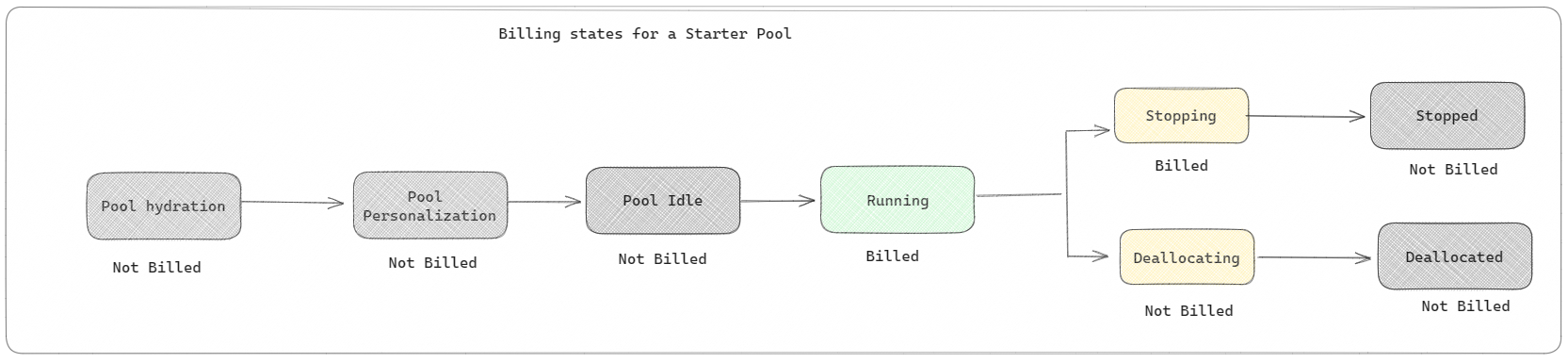
Om du till exempel skickar ett notebook-jobb till en startpool debiteras du endast för den tidsperiod då notebook-sessionen är aktiv. Den fakturerade tiden inkluderar inte inaktivitetstiden eller den tid det tar att anpassa sessionen med Spark-kontexten. Mer information om hur du konfigurerar startpooler baserat på den köpta SKU :n för infrastrukturkapacitet finns i Konfigurera startpooler baserat på infrastrukturresurser
Spark-pooler: Det här är anpassade pooler där du kan anpassa efter vilken storlek på resurser du behöver för dina dataanalysuppgifter. Du kan ge Spark-poolen ett namn och välja hur många och hur stora noderna (de datorer som utför arbetet) är. Du kan också berätta för Spark hur du justerar antalet noder beroende på hur mycket arbete du har. Det är kostnadsfritt att skapa en Spark-pool. du betalar bara när du kör ett Spark-jobb i poolen och sedan konfigurerar Spark noderna åt dig.
- Storleken och antalet noder som du kan ha i din anpassade Spark-pool beror på din Microsoft Fabric-kapacitet. Du kan använda dessa virtuella Spark-kärnor för att skapa noder av olika storlekar för din anpassade Spark-pool, så länge det totala antalet virtuella Spark-kärnor inte överstiger 128.
- Spark-pooler faktureras som startpooler. du betalar inte för de anpassade Spark-pooler som du har skapat om du inte har en aktiv Spark-session som skapats för att köra en notebook- eller Spark-jobbdefinition. Du debiteras bara under hela jobbkörningarna. Du debiteras inte för faser som när klustret skapas och frigörs när jobbet har slutförts.
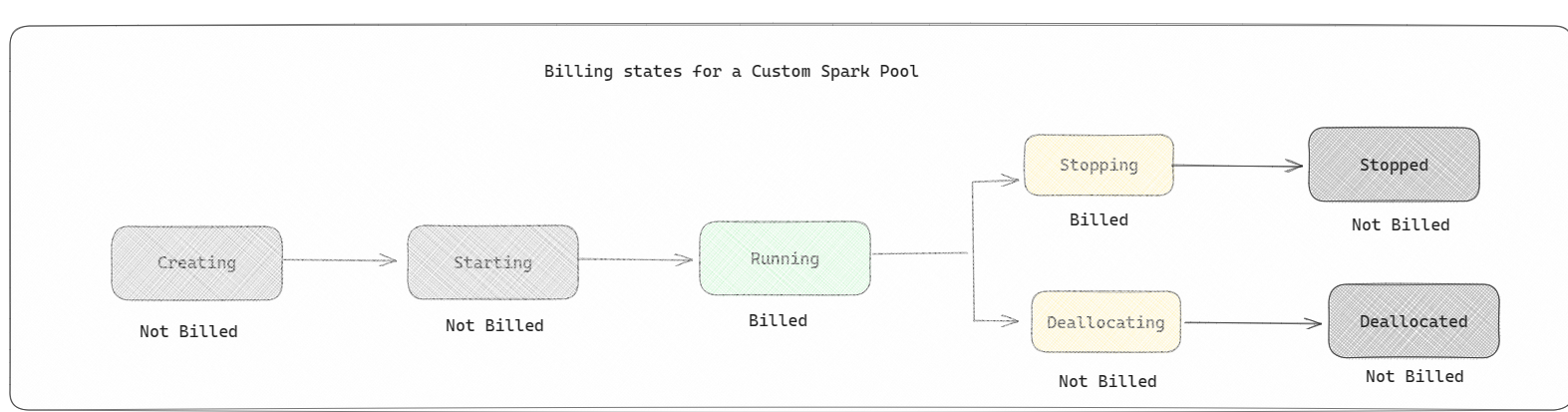
Om du till exempel skickar ett notebook-jobb till en anpassad Spark-pool debiteras du bara för den tidsperiod då sessionen är aktiv. Faktureringen för notebook-sessionen stoppas när Spark-sessionen har stoppats eller upphört att gälla. Du debiteras inte för den tid det tar att hämta klusterinstanser från molnet eller för den tid det tar att initiera Spark-kontexten. Mer information om hur du konfigurerar Spark-pooler baserat på den köpta SKU :n för infrastrukturkapacitet finns i Konfigurera pooler baserat på infrastrukturresurser


Kommentar
Standardperioden för sessionens förfallotid för startpooler och Spark-pooler som du skapar är inställd på 20 minuter. Om du inte använder Spark-poolen på två minuter efter att sessionen har gått ut frigörs Spark-poolen. Om du vill stoppa sessionen och faktureringen när du har slutfört notebook-körningen innan sessionen upphör att gälla kan du antingen klicka på knappen Stoppa session från startmenyn för notebook-filer eller gå till övervakningshubbens sida och stoppa sessionen där.
Rapportering av Spark-beräkningsanvändning
Appen Kapacitetsmått för Microsoft Fabric ger insyn i kapacitetsanvändningen för alla Infrastruktur-arbetsbelastningar på ett och samma ställe. Den används av kapacitetsadministratörer för att övervaka prestanda för arbetsbelastningar och deras användning jämfört med köpt kapacitet.
När du har installerat appen väljer du objekttypen Notebook,Lakehouse,Spark Job Definition i listrutan Välj objekttyp: . Flermåttsdiagrammet i menyfliksområdet kan nu justeras till en önskad tidsram för att förstå användningen från alla dessa markerade objekt.
Alla Spark-relaterade åtgärder klassificeras som bakgrundsåtgärder. Kapacitetsförbrukning från Spark visas under en notebook-fil, en Spark-jobbdefinition eller ett lakehouse och aggregeras efter åtgärdsnamn och objekt. Till exempel: Om du kör ett notebook-jobb kan du se notebook-körningen, de CUs som används av notebook-filen (Totalt Antal virtuella Spark-kärnor/2 som 1 CU ger 2 Virtuella Spark-kärnor), varaktighet som jobbet har tagit i rapporten.
 Mer information om rapportering av Spark-kapacitetsanvändning finns i Övervaka Apache Spark-kapacitetsförbrukning
Mer information om rapportering av Spark-kapacitetsanvändning finns i Övervaka Apache Spark-kapacitetsförbrukning
Faktureringsexempel
Föreställ dig följande scenario:
Det finns en kapacitet C1 som är värd för en infrastrukturarbetsyta W1 och den här arbetsytan innehåller Lakehouse LH1 och Notebook NB1.
- Alla Spark-åtgärder som notebook(NB1) eller lakehouse(LH1) utför rapporteras mot kapaciteten C1.
Utöka det här exemplet till ett scenario där det finns en annan kapacitet C2 som är värd för en Infrastrukturarbetsyta W2 och kan säga att den här arbetsytan innehåller en Spark-jobbdefinition (SJD1) och Lakehouse (LH2).
- Om Spark-jobbdefinitionen (SDJ2) från arbetsytan (W2) läser data från lakehouse (LH1) rapporteras användningen mot den kapacitet C2 som är associerad med arbetsytan (W2) som är värd för objektet.
- Om notebook-filen (NB1) utför en läsåtgärd från Lakehouse (LH2) rapporteras kapacitetsförbrukningen mot kapacitet C1 som driver arbetsytan W1 som är värd för notebook-objektet.