Utvärdera förutsägelsemodellen för första kundbetalning
I det här ämnet beskrivs hur du utvärderar en förutsägelsemodell när du har aktiverat Finance Insights och sedan skapat och tränat din första modell. Det här ämnet handlar om modeller för att förutsäga kundbetalningar. Det beskriver de steg du kan vidta för att förstå modellen för kundbetalningsförutsägelse och utvärdera dess effektivitet.
Få information om modellen
På sidan Parametrar för Finance Insights i Microsoft Dynamics 365 Finance visas länken Förbättra modellens noggrannhet bredvid noggrannhetspoängen.

Med den här länken kommer du till AI Builder, där du kan lära dig mer om den aktuella modellen och även vidta åtgärder för att förbättra den. Följande illustration visar den sida som öppnas.
Den sida som öppnas visar följande information:
I avsnittet Prestanda ger modellens prestandapoäng ett perspektiv på modellens kvalitet. Mer information om den här poängen finns i Förutsägelsemodellens prestanda i dokumentationen för AI Builder.
Avsnittet Mest inflytelserika data visar hur viktiga olika indatatyper var för din modell. Du kan utvärdera den här listan och motsvarande procentsatser för att avgöra om informationen är överensstämmer med vad du känner till om ditt företag och din marknad.

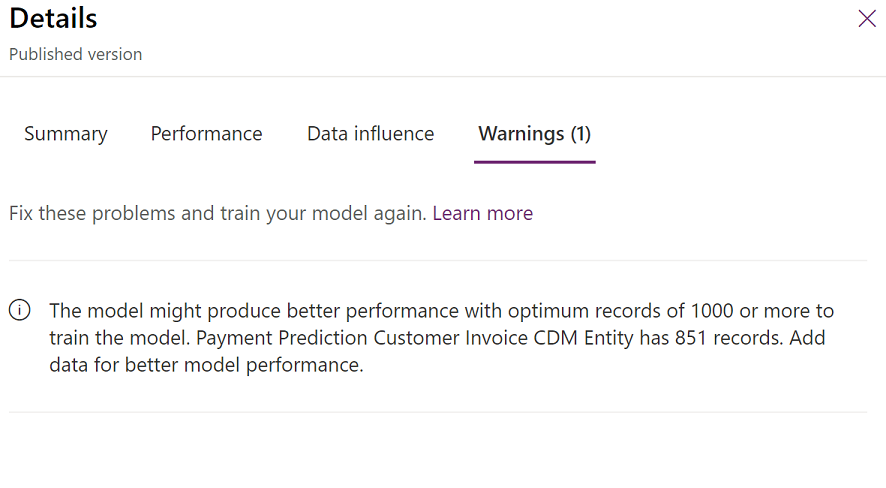
I avsnittet Prestanda väljer du Visa information för att få veta mer om poängen och andra överväganden. I bilden nedan visas information om att modellen använder mindre information än vad som rekommenderas. Därför har systemet genererat ett varningsmeddelande.
Gräva djupare
Även om noggrannhet är en bra utgångspunkt för utvärdering av en modell, och prestandapoängen ger perspektiv, innehåller AI Builder mer detaljerade mått som du kan använda för utvärderingen. Om du vill hämta informationen väljer du ellips-knappen (...) i avsnittet Prestanda bredvid knappen Använd modell, och väljer sedan Ladda ner detaljerade mått.
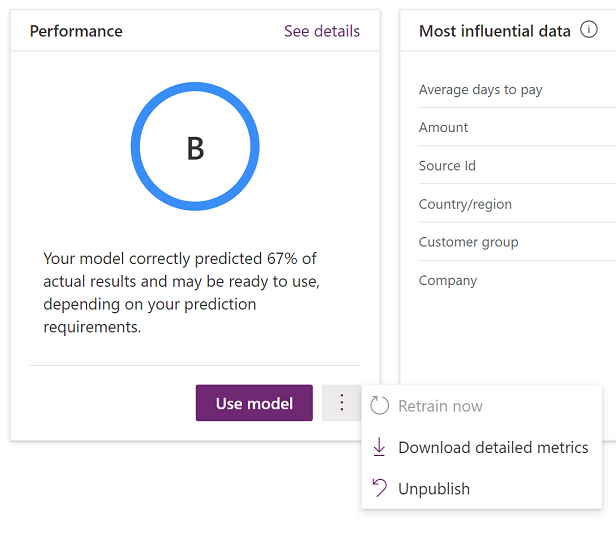
Följande bild visar det format som du kan ladda ner data i.

För en djupare analys av resultaten är det en bra utgångspunkt att granska måttet "Sammanblandningsmatris". Här finns exempelvis de data som visas för det här måttet i föregående illustration.
{"name": "Confusion Matrix", "value": {"schema_type": "confusion_matrix", "schema_version": "1.0.0", "data": {"class_labels": ["0", "1", "2"], "matrix": [[71, 9, 21], [5, 0, 27], [2, 0, 45]]}}, "type": "dictionaryNumericalList", "isGlobalScore": false}
Du kan expandera dessa data på följande sätt.
| Förutsedd i tid | Förutsedd sen | Förutsedd mycket sen | |
|---|---|---|---|
| Faktisk betalning i tid | 71 | 0 | 21 |
| Faktisk sen betalning | 5 | 0 | 27 |
| Faktisk mycket sen betalning | 2 | 0 | 45 |
I sammanblandningsmatrisen visas resultatet av en slumpvis vald testdatamängd från träningsprocessen. Eftersom dessa stängda fakturor inte användes för att träna modellen är de bra testfall för modellen. Eftersom fakturans faktiska tillstånd är känt kan även modellens prestanda ses.
Det första du ska leta efter är det vanligaste faktiska värdet. Även om det här värdet kanske inte är perfekt justerat med den totala datamängden är det en rimlig uppskattning. I det här fallet inträffar Faktisk betalning i tid för 92 av de totalt 171 fakturorna och är det vanligaste faktiska värdet. Därför är det en bra baslinje för din modell. Om du bara har gissat att alla fakturor betalas i tid har du rätt 92 av 171 gånger (dvs. 54 procent av tiden).
Det är viktigt att du förstår hur balanserad din datamängd är. I det här fallet betalades 92 av 171 fakturor i tid, 32 betalades sent och 47 betalades mycket sent. Dessa värden indikerar en relativt balanserad datamängd eftersom det finns icke-triviala resultat i varje klassificering. En situation där ett av tillstånden har mycket få resultat kan vara en utmaning för en maskininlärningsmodell.
Modellens noggrannhet indikerar antalet korrekta förutsägelser för testdatauppmängden. Dessa korrekta förutsägelser är de värden som visas i fetstil i föregående exempel. I det här fallet ger värdena en beräknad noggrannhet på 67,8 procent (= [71 + 0 + 45] ÷ 171). Detta värde representerar en förbättring på 14 procent över baslinjegissningen på 54 procent och är en indikator på modellens kvalitet.
Om du tittar närmare på sammanblandningsmatrisen ser du att modellen gör ett bra jobb med att förutsäga fakturabetalningar i tid och mycket sena fakturabetalningar. Den har dock fel om alla 32 fakturor som faktiskt har betalats sent (men inte mycket sent). Det här resultatet tyder på att ytterligare utforskning och förbättring av modellen krävs.
Ett tal som representerar modellens prestanda bättre än noggrannhet är F1-makropoängen. Denna poäng tar hänsyn till resultaten av varje klassificeringstillstånd (i tid, sent och mycket sent). Här finns exempelvis de data som visas för "F1-makro"-måttet i föregående bild.
{"name": "F1 Macro", "value": 0.4927170868347339, "type": "percentage", "isGlobalScore": false}
I det här fallet visar F1-makropoängen på ungefär 49,3 procent att modellen inte ger effektiva förutsägelser för varje tillstånd, trots att det finns en övergripande noggrannhetspoäng som verkar relativt hög.
Förbättra modellen
När du har förstått resultatet av din första modell bättre kan du förbättra modellen genom att lägga till eller ta bort funktionskolumner eller genom att filtrera de delar av datamängden som inte stöder exakta förutsägelser. Stäng AI Builder och använd länken Förbättra modellen i Dynamics 365 Finance för att starta om AI Builder-processen. Du kan experimentera med olika egenskaper utan att den publicerade modellen påverkas. Den publicerade modellen påverkas bara när du väljer Publicera. Kom ihåg att en enda modell används för din instans av Dynamics 365 Finance. Därför bör du noggrant granska alla nya modeller innan du publicerar den.
Mer information
Mer information om att utvärdera förutsägelsemodeller finns i Resultat av maskininlärningsmodeller