Återhämtning på Azure-plattformen
Dricks
Det här innehållet är ett utdrag från eBook, Architecting Cloud Native .NET Applications for Azure, tillgängligt på .NET Docs eller som en kostnadsfri nedladdningsbar PDF som kan läsas offline.

Att skapa ett tillförlitligt program i molnet skiljer sig från traditionell lokal programutveckling. Tidigare har du köpt maskinvara med högre slutpunkt för att skala upp, men i en molnmiljö skalar du ut. I stället för att försöka förhindra fel är målet att minimera deras effekter och hålla systemet stabilt.
Med detta sagt visar tillförlitliga molnprogram distinkta egenskaper:
- De är motståndskraftiga, återhämtar sig smidigt från problem och fortsätter att fungera.
- De är mycket tillgängliga (HA) och körs som de är utformade i ett felfritt tillstånd utan betydande stilleståndstid.
Att förstå hur dessa egenskaper fungerar tillsammans – och hur de påverkar kostnaderna – är viktigt för att skapa ett tillförlitligt molnbaserat program. Nu ska vi titta på hur du kan skapa återhämtning och tillgänglighet i dina molnbaserade program som använder funktioner från Azure-molnet.
Designa med återhämtning
Vi har sagt att återhämtning gör det möjligt för ditt program att reagera på fel och fortfarande vara funktionellt. White paper, Resilience in Azure white paper, ger vägledning för att uppnå motståndskraft på Azure-plattformen. Här följer några viktiga rekommendationer:
Maskinvarufel. Skapa redundans i programmet genom att distribuera komponenter över olika feldomäner. Kontrollera till exempel att virtuella Azure-datorer placeras i olika rack med hjälp av tillgänglighetsuppsättningar.
Datacenterfel. Skapa redundans i programmet med felisoleringszoner mellan datacenter. Kontrollera till exempel att virtuella Azure-datorer placeras i olika felisolerade datacenter med hjälp av Azure Tillgänglighetszoner.
Regionalt fel. Replikera data och komponenter till en annan region så att program snabbt kan återställas. Du kan till exempel använda Azure Site Recovery för att replikera virtuella Azure-datorer till en annan Azure-region.
Tung belastning. Belastningsutjämning mellan instanser för att hantera toppar i användningen. Du kan till exempel placera två eller flera virtuella Azure-datorer bakom en lastbalanserare för att distribuera trafik till alla virtuella datorer.
Oavsiktlig databorttagning eller skada. Säkerhetskopiera data så att de kan återställas om det finns någon borttagning eller skada. Du kan till exempel använda Azure Backup för att regelbundet säkerhetskopiera dina virtuella Azure-datorer.
Designa med redundans
Felen varierar i effektomfånget. Ett maskinvarufel, till exempel en misslyckad disk, kan påverka en enskild nod i ett kluster. En misslyckad nätverksväxel kan påverka ett helt serverrack. Mindre vanliga fel, till exempel strömavbrott, kan störa ett helt datacenter. Sällan blir en hel region otillgänglig.
Redundans är ett sätt att ge programresiliens. Den exakta redundansnivån som krävs beror på dina affärskrav och påverkar både kostnaden och komplexiteten i systemet. En distribution i flera regioner är till exempel dyrare och mer komplex att hantera än en distribution med en enda region. Du behöver operativa procedurer för att hantera redundans och återställning efter fel. Den extra kostnaden och komplexiteten kan motiveras för vissa affärsscenarier, men inte andra.
För att skapa redundans måste du identifiera de kritiska sökvägarna i ditt program och sedan avgöra om det finns redundans vid varje punkt i sökvägen? Om ett undersystem skulle misslyckas, redundansväxlar programmet till något annat? Slutligen behöver du en tydlig förståelse för de funktioner som är inbyggda i Azure-molnplattformen som du kan utnyttja för att uppfylla dina redundanskrav. Här är rekommendationer för att skapa redundans:
Distribuera flera instanser av tjänster. Om ditt program är beroende av en enda instans av en tjänst skapas en enskild felpunkt. Etablering av flera instanser förbättrar både återhämtning och skalbarhet. När du är värd för Azure Kubernetes Service kan du deklarativt konfigurera redundanta instanser (replikuppsättningar) i Kubernetes-manifestfilen. Värdet för antal repliker kan hanteras programmatiskt, i portalen eller via funktioner för automatisk skalning.
Dra nytta av en lastbalanserare. Belastningsutjämning distribuerar programmets begäranden till felfria tjänstinstanser och tar automatiskt bort felaktiga instanser från rotation. När du distribuerar till Kubernetes kan belastningsutjämning anges i Kubernetes-manifestfilen i avsnittet Tjänster.
Planera för distribution i flera regioner. Om du distribuerar ditt program till en enda region och den regionen blir otillgänglig blir ditt program också otillgängligt. Detta kan vara oacceptabelt enligt villkoren i programmets serviceavtal. Överväg i stället att distribuera ditt program och dess tjänster i flera regioner. Till exempel distribueras ett AKS-kluster (Azure Kubernetes Service) till en enda region. För att skydda systemet mot ett regionalt fel kan du distribuera programmet till flera AKS-kluster i olika regioner och använda funktionen Parkopplade regioner för att samordna plattformsuppdateringar och prioritera återställningsåtgärder.
Aktivera geo-replikering. Geo-replikering för tjänster som Azure SQL Database och Cosmos DB skapar sekundära repliker av dina data i flera regioner. Båda tjänsterna replikerar automatiskt data inom samma region, men geo-replikering skyddar dig mot ett regionalt avbrott genom att du kan redundansväxla till en sekundär region. En annan metod för geo-replikeringscenter kring lagring av containeravbildningar. Om du vill distribuera en tjänst i AKS måste du lagra och hämta avbildningen från en lagringsplats. Azure Container Registry integreras med AKS och kan lagra containeravbildningar på ett säkert sätt. För att förbättra prestanda och tillgänglighet bör du överväga att georeplikera dina avbildningar till ett register i varje region där du har ett AKS-kluster. Varje AKS-kluster hämtar sedan containeravbildningar från det lokala containerregistret i sin region enligt bild 6–4:
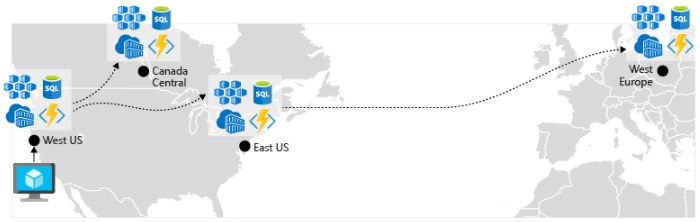
Bild 6-4. Replikerade resurser mellan regioner
- Implementera en DNS-trafiklastbalanserare.Azure Traffic Manager ger hög tillgänglighet för kritiska program genom belastningsutjämning på DNS-nivå. Den kan dirigera trafik till olika regioner baserat på geografi, klustersvarstid och till och med programmets slutpunktshälsa. Azure Traffic Manager kan till exempel dirigera kunder till närmaste AKS-kluster och programinstans. Om du har flera AKS-kluster i olika regioner använder du Traffic Manager för att styra hur trafiken flödar till de program som körs i varje kluster. Bild 6–5 visar det här scenariot.
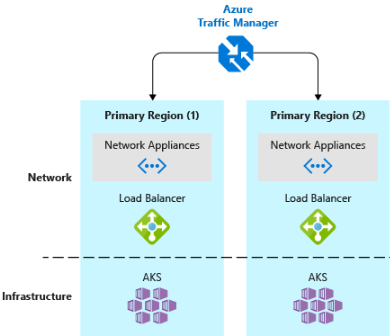
Bild 6-5. AKS och Azure Traffic Manager
Design för skalbarhet
Molnet utvecklas när det gäller skalning. Möjligheten att öka/minska systemresurser för att hantera ökande/minskande systembelastning är en viktig grundsats i Azure-molnet. Men för att effektivt skala ett program behöver du en förståelse för skalningsfunktionerna för varje Azure-tjänst som du inkluderar i ditt program. Här följer rekommendationer för att effektivt implementera skalning i systemet.
Design för skalning. Ett program måste vara utformat för skalning. För att starta bör tjänsterna vara tillståndslösa så att begäranden kan dirigeras till valfri instans. Att ha tillståndslösa tjänster innebär också att det inte påverkar aktuella användare negativt att lägga till eller ta bort en instans.
Partitionsarbetsbelastningar. Genom att dela upp domäner i oberoende, fristående mikrotjänster kan varje tjänst skalas oberoende av andra. Tjänsterna har vanligtvis olika skalbarhetsbehov och krav. Med partitionering kan du bara skala det som behöver skalas utan onödiga kostnader för att skala ett helt program.
Favor scale-out. Molnbaserade program föredrar att skala ut resurser i stället för att skala upp. Utskalning (kallas även horisontell skalning) innebär att lägga till fler tjänstresurser i ett befintligt system för att uppfylla och dela en önskad prestandanivå. Att skala upp (kallas även vertikal skalning) innebär att ersätta befintliga resurser med kraftfullare maskinvara (mer disk, minne och bearbetningskärnor). Utskalning kan anropas automatiskt med de funktioner för automatisk skalning som är tillgängliga i vissa Azure-molnresurser. Utskalning över flera resurser ger också redundans till det övergripande systemet. Slutligen är det vanligtvis dyrare att skala upp en enskild resurs än att skala ut över många mindre resurser. Bild 6–6 visar de två metoderna:
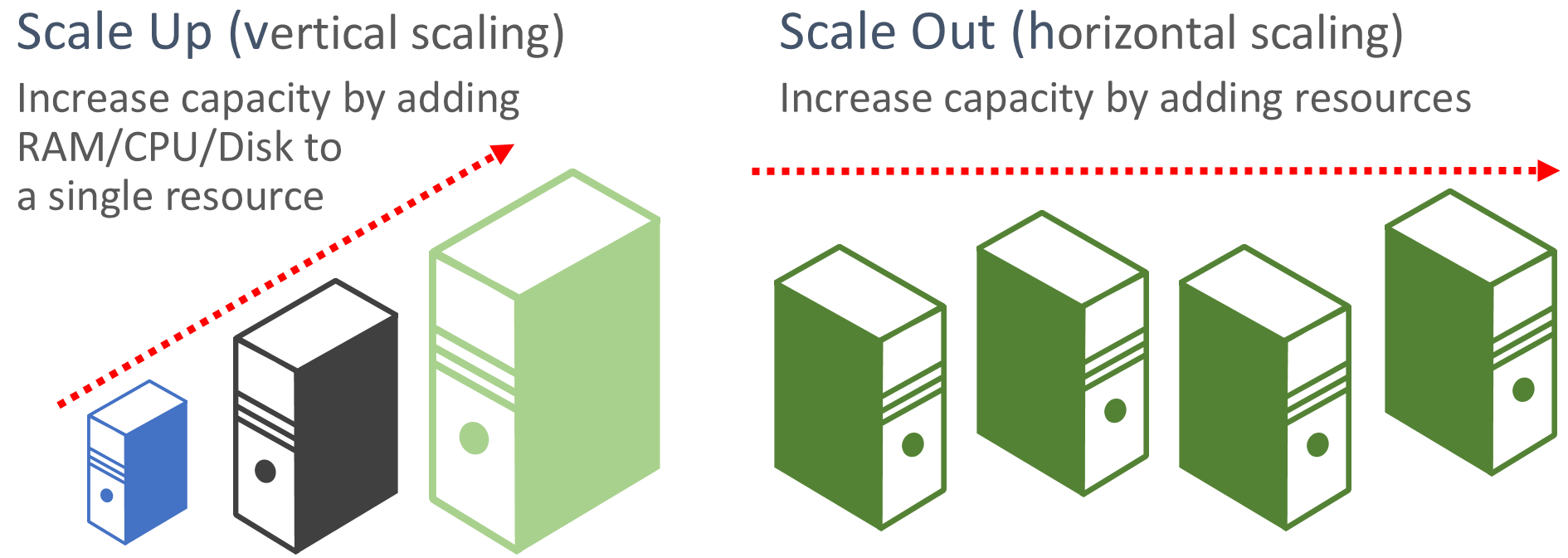
Bild 6-6. Skala upp jämfört med skala ut
Skala proportionellt. När du skalar en tjänst bör du tänka på resursuppsättningar. Om du skulle skala ut en specifik tjänst dramatiskt, vilken inverkan skulle det ha på serverdelsdatalager, cacheminnen och beroende tjänster? Vissa resurser som Cosmos DB kan skalas ut proportionellt, medan många andra inte kan det. Du vill se till att du inte skalar ut en resurs till en punkt där den kommer att uttömma andra associerade resurser.
Undvik tillhörighet. Bästa praxis är att se till att en nod inte kräver lokal tillhörighet, vilket ofta kallas för en klibbig session. En begäran ska kunna dirigeras till valfri instans. Om du behöver bevara tillståndet bör det sparas i en distribuerad cache, till exempel Azure Redis-cache.
Dra nytta av funktioner för automatisk skalning av plattformar. Använd inbyggda funktioner för automatisk skalning när det är möjligt, i stället för anpassade mekanismer eller mekanismer från tredje part. Använd om möjligt schemalagda skalningsregler för att säkerställa att resurser är tillgängliga utan startfördröjning, men lägg till reaktiv autoskalning i reglerna efter behov, för att hantera oväntade ändringar i efterfrågan. Mer information finns i Vägledning för automatisk skalning.
Skala ut aggressivt. En sista metod skulle vara att skala ut aggressivt så att du snabbt kan möta omedelbara toppar i trafiken utan att förlora affärer. Och skala sedan in (d.v.s. ta bort onödiga instanser) försiktigt för att hålla systemet stabilt. Ett enkelt sätt att implementera detta är att ange nedkylningsperioden, vilket är tiden att vänta mellan skalningsåtgärder, till fem minuter för att lägga till resurser och upp till 15 minuter för att ta bort instanser.
Inbyggda återförsök i tjänster
Vi rekommenderar att du implementerar programmatiska återförsöksåtgärder i ett tidigare avsnitt. Tänk på att många Azure-tjänster och deras motsvarande klient-SDK:er även omfattar återförsöksmekanismer. I följande lista sammanfattas återförsöksfunktionerna i de många Av De Azure-tjänster som beskrivs i den här boken:
Azure Cosmos DB. Den DocumentClient-klassen från klient-API:et försöker automatiskt utföra misslyckade försök igen. Antalet återförsök och maximal väntetid kan konfigureras. Undantag som genereras av klient-API:et är antingen begäranden som överskrider återförsöksprincipen eller icke-tillfälliga fel.
Azure Redis Cache. Redis StackExchange-klienten använder en anslutningshanterare-klass som innehåller återförsök vid misslyckade försök. Antalet återförsök, en specifik återförsöksprincip och väntetiden kan alla konfigureras.
Azure Service Bus. Service Bus-klienten exponerar en RetryPolicy-klass som kan konfigureras med ett back-off-intervall, antal återförsök och TerminationTimeBuffer, som anger den maximala tid en åtgärd kan ta. Standardprincipen är nio maximala återförsök med en 30-sekunders backoff-period mellan försöken.
Azure SQL Database. Stöd för återförsök tillhandahålls när du använder Entity Framework Core-biblioteket .
Azure Storage. Lagringsklientbiblioteket stöder återförsöksåtgärder. Strategierna varierar mellan Azure-lagringstabeller, blobbar och köer. Dessutom växlar alternativa återförsök mellan primära och sekundära lagringstjänster när geo-redundansfunktionen är aktiverad.
Azure Event Hubs. Event Hub-klientbiblioteket har en RetryPolicy-egenskap, som innehåller en konfigurerbar exponentiell backoff-funktion.