Mönster för programåterhämtning
Dricks
Det här innehållet är ett utdrag från eBook, Architecting Cloud Native .NET Applications for Azure, tillgängligt på .NET Docs eller som en kostnadsfri nedladdningsbar PDF som kan läsas offline.

Den första försvarslinjen är programåterhämtning.
Även om du kan investera mycket tid på att skriva ditt eget återhämtningsramverk, finns det redan sådana produkter. Polly är ett omfattande .NET-återhämtnings- och tillfälligt felhanteringsbibliotek som gör det möjligt för utvecklare att uttrycka återhämtningsprinciper på ett flytande och trådsäkert sätt. Polly riktar sig till program som skapats med .NET Framework eller .NET 7. I följande tabell beskrivs återhämtningsfunktionerna, som kallas policies, som är tillgängliga i Polly-biblioteket. De kan tillämpas individuellt eller grupperas tillsammans.
| Policy | Upplevelse |
|---|---|
| Försök igen | Konfigurerar återförsöksåtgärder för avsedda åtgärder. |
| Kretsbrytare | Blockerar begärda åtgärder under en fördefinierad period när fel överskrider ett konfigurerat tröskelvärde |
| Timeout | Anger hur länge en anropare kan vänta på ett svar. |
| Bulkhead | Begränsar åtgärder till resurspool med fast storlek för att förhindra misslyckade anrop från att översvämma en resurs. |
| Cache | Lagrar svar automatiskt. |
| Reserv | Definierar strukturerat beteende vid ett fel. |
Observera hur återhämtningsprinciperna i föregående bild gäller för begärandemeddelanden, oavsett om de kommer från en extern klient eller en serverdelstjänst. Målet är att kompensera begäran för en tjänst som kan vara tillfälligt otillgänglig. Dessa kortvariga avbrott visar sig vanligtvis med HTTP-statuskoderna som visas i följande tabell.
| HTTP-statuskod | Orsak |
|---|---|
| 404 | Hittades inte |
| 408 | Timeout för begäran |
| 429 | För många begäranden (du har troligen begränsats) |
| 502 | Felaktig gateway |
| 503 | Tjänst otillgänglig |
| 504 | Gateway-timeout |
Fråga: Försöker du igen med http-statuskoden 403 – Förbjuden? Nej. Här fungerar systemet korrekt, men meddelar anroparen att de inte har behörighet att utföra den begärda åtgärden. Var noga med att endast försöka utföra de åtgärder som orsakas av fel igen.
Som vi rekommenderar i kapitel 1 bör Microsoft-utvecklare som skapar molnbaserade program rikta in sig på .NET-plattformen. Version 2.1 introducerade HTTPClientFactory-biblioteket för att skapa HTTP-klientinstanser för interaktion med URL-baserade resurser. Fabriksklassen ersätter den ursprungliga HTTPClient-klassen och har stöd för många förbättrade funktioner, varav en är nära integrering med Polly-återhämtningsbiblioteket. Med den kan du enkelt definiera återhämtningsprinciper i programmets startklass för att hantera partiella fel och anslutningsproblem.
Nu ska vi utöka mönster för återförsök och kretsbrytare.
Återförsöksmönster
I en distribuerad molnbaserad miljö kan anrop till tjänster och molnresurser misslyckas på grund av tillfälliga (kortvariga) fel, som vanligtvis korrigerar sig själva efter en kort tidsperiod. Genom att implementera en återförsöksstrategi kan en molnbaserad tjänst minimera dessa scenarier.
Mönstret Försök igen gör det möjligt för en tjänst att försöka utföra en misslyckad begäran ett (konfigurerbart) antal gånger med en exponentiellt ökande väntetid. Bild 6–2 visar ett nytt försök i praktiken.
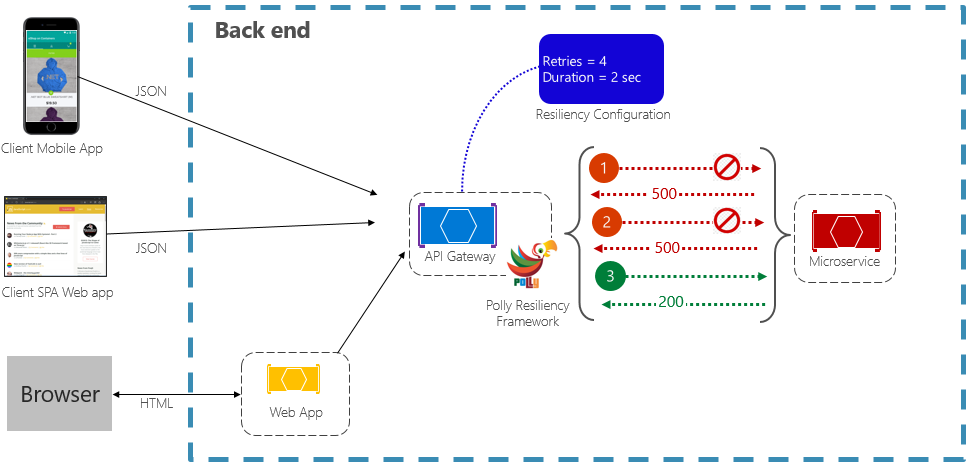
Bild 6-2. Återförsöksmönster i praktiken
I föregående bild har ett återförsöksmönster implementerats för en begärandeåtgärd. Den har konfigurerats för att tillåta upp till fyra återförsök innan det misslyckas med ett backoff-intervall (väntetid) som börjar med två sekunder, vilket exponentiellt fördubblas för varje efterföljande försök.
- Det första anropet misslyckas och returnerar en HTTP-statuskod på 500. Programmet väntar i två sekunder och försöker anropa igen.
- Det andra anropet misslyckas också och returnerar en HTTP-statuskod på 500. Programmet fördubblar nu backoff-intervallet till fyra sekunder och försöker anropa igen.
- Slutligen lyckas det tredje anropet.
- I det här scenariot skulle återförsöksåtgärden ha försökt upp till fyra återförsök samtidigt som backoff-varaktigheten dubblerades innan anropet misslyckades.
- Om det fjärde återförsöket misslyckades anropas en återställningsprincip för att hantera problemet på ett korrekt sätt.
Det är viktigt att öka backoff-perioden innan du försöker anropa igen så att tjänstens tid kan korrigeras själv. Det är bästa praxis att implementera en exponentiellt ökande backoff (dubblera perioden för varje nytt försök) för att tillåta lämplig korrigeringstid.
Kretsbrytarmönster
Även om återförsöksmönstret kan hjälpa till att rädda en begäran som är sammanflätad i ett partiellt fel, finns det situationer där fel kan orsakas av oväntade händelser som kräver längre tidsperioder att lösa. Felen kan variera i allvarlighetsgrad, från en partiell förlust av anslutning till fullständigt fel i en tjänst. I dessa situationer är det meningslöst för ett program att kontinuerligt försöka utföra en åtgärd som sannolikt inte lyckas.
För att göra saken värre kan kontinuerliga återförsöksåtgärder på en icke-dynamisk tjänst flytta dig till ett självpåtaget Denial of Service-scenario där du översvämmar tjänsten med ständiga anrop som uttömmer resurser som minne, trådar och databasanslutningar, vilket orsakar fel i orelaterade delar av systemet som använder samma resurser.
I dessa situationer är det bättre om åtgärden misslyckas omedelbart och endast försöker anropa tjänsten om den sannolikt kommer att lyckas.
Kretsbrytarmönstret kan förhindra att ett program upprepade gånger försöker köra en åtgärd som sannolikt kommer att misslyckas. Efter ett fördefinierat antal misslyckade anrop blockerar det all trafik till tjänsten. Med jämna mellanrum kan ett utvärderingsanrop avgöra om felet har lösts. Bild 6-3 visar kretsbrytarmönstret i praktiken.
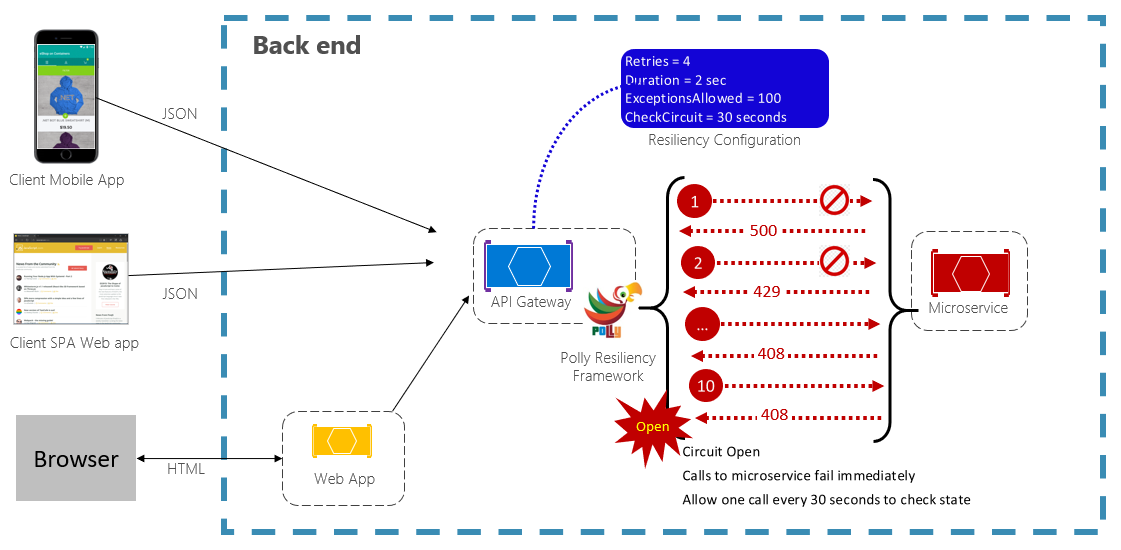
Bild 6-3. Kretsbrytarmönster i praktiken
I föregående bild har ett kretsbrytarmönster lagts till i det ursprungliga återförsöksmönstret. Observera hur kretsbrytarna öppnas efter 100 misslyckade begäranden och inte längre tillåter anrop till tjänsten. Värdet CheckCircuit, som anges till 30 sekunder, anger hur ofta biblioteket tillåter att en begäran fortsätter till tjänsten. Om det anropet lyckas stängs kretsen och tjänsten är återigen tillgänglig för trafik.
Tänk på att avsikten med kretsbrytarmönstret skiljer sig från mönstret För återförsök. Med återförsöksmönstret kan ett program försöka utföra en åtgärd igen i väntan på att den ska lyckas. Kretsbrytarmönstret hindrar ett program från att utföra en åtgärd som sannolikt kommer att misslyckas. Vanligtvis kombinerar ett program dessa två mönster med hjälp av återförsöksmönstret för att anropa en åtgärd via en kretsbrytare.
Testa för elasticitet
Det går inte alltid att testa återhämtning på samma sätt som du testar programfunktioner (genom att köra enhetstester, integreringstester och så vidare). I stället måste du testa hur arbetsbelastningen från slutpunkt till slutpunkt presterar under feltillstånd, som bara inträffar tillfälligt. Till exempel: mata in fel genom att krascha processer, utgångna certifikat, göra beroende tjänster otillgängliga osv. Ramverk som chaos-monkey kan användas för sådana kaostester.
Programåterhämtning är ett måste för att hantera problematiska begärda åtgärder. Men det är bara hälften av historien. Därefter tar vi upp återhämtningsfunktioner som är tillgängliga i Azure-molnet.