Mappa i Azure Synapse Analytics
Vad är verktyget Kartdata?
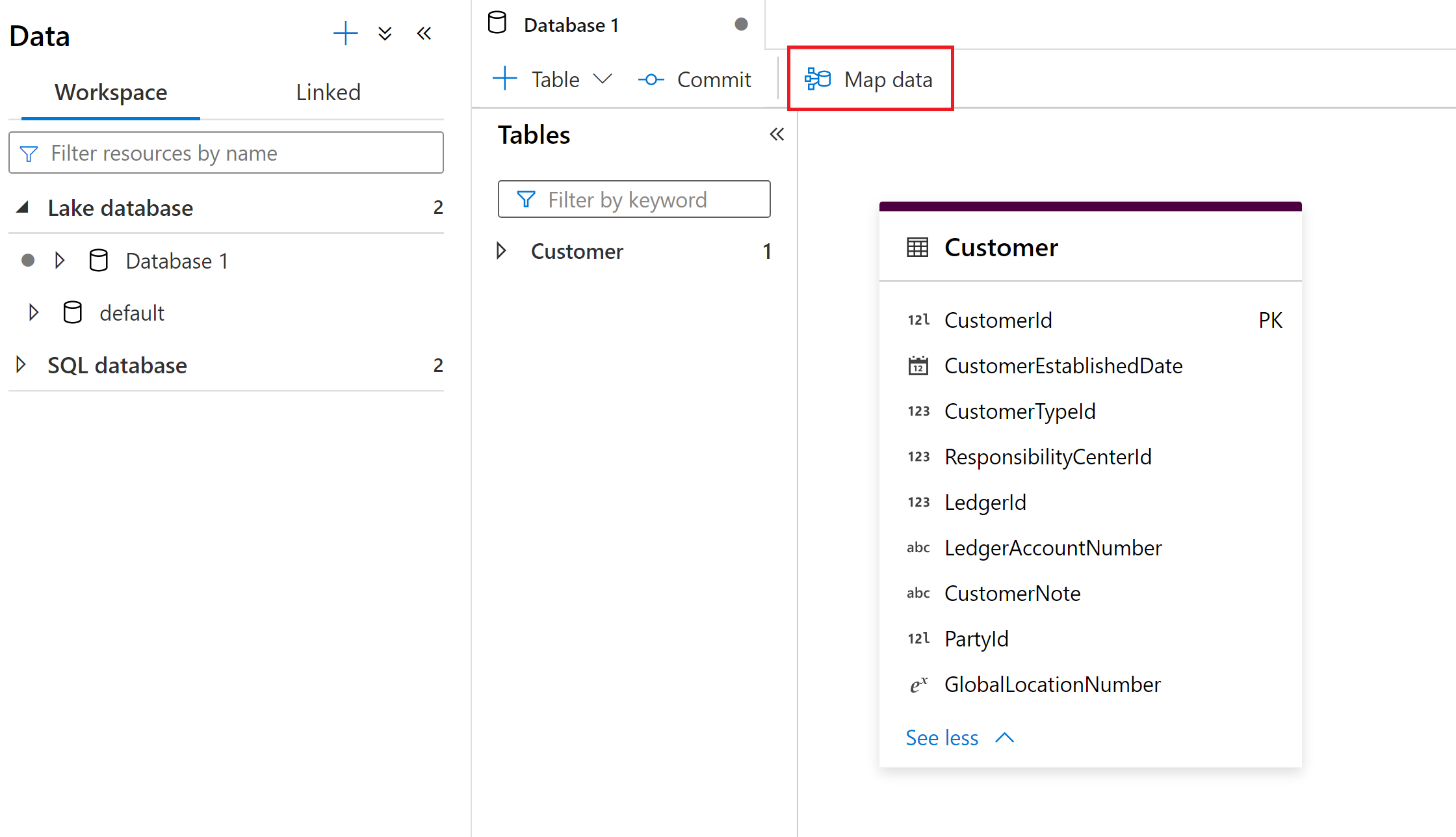
Verktyget Kartdata är en guidad process som hjälper användare att skapa ETL-mappningar och mappa dataflöden från sina källdata till Synapse Lake-databastabeller utan att skriva kod. Den här processen börjar med att användaren väljer måltabellerna i Synapse Lake-databaser och sedan mappar sina källdata till dessa tabeller.
Mer information om Synapse Lake-databaser finns i Översikt av Azure Synapse-databasmallar – Azure Synapse Analytics | Microsoft Docs
Kartdata ger en guidad upplevelse där användaren kan generera ett mappningsdataflöde utan att behöva börja med en tom arbetsyta. Sedan kan du snabbt generera ett skalbart mappningsdataflöde som kan köras i Synapse-pipelines.
Komma igång
Verktyget Kartdata startas inifrån Synapse Lake-databasupplevelsen. Härifrån kan du välja verktyget Kartdata för att påbörja processen.
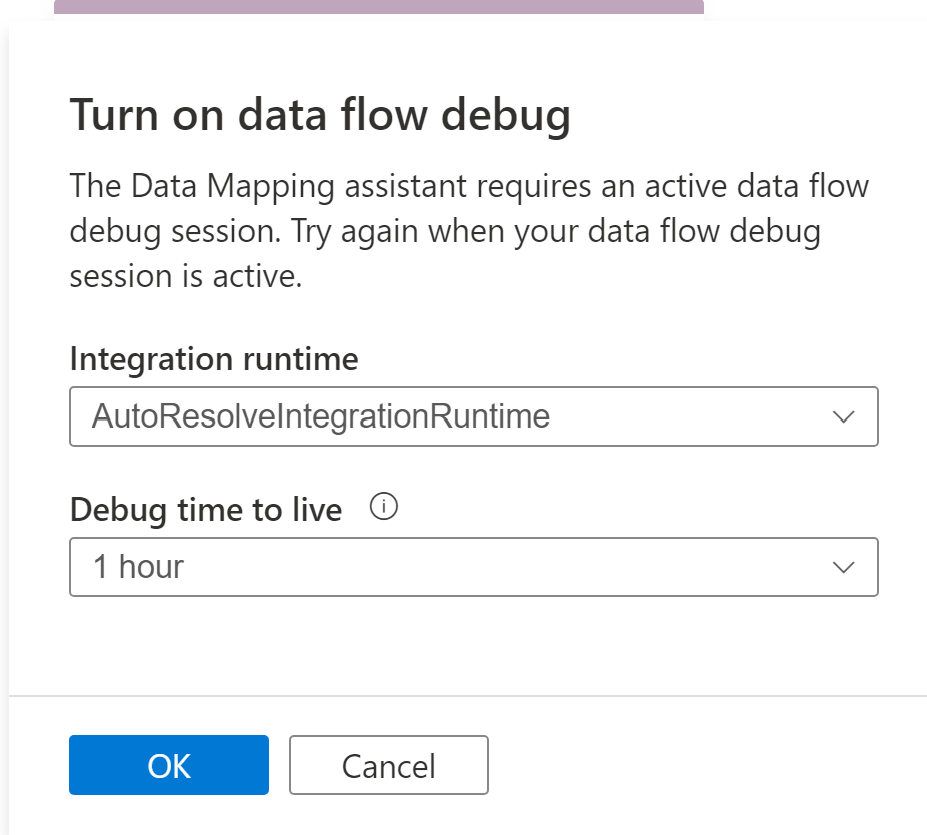
Kartdata behöver beräkning som är tillgänglig för att hjälpa användare att förhandsgranska data och läsa schema för sina källfiler. När du använder Kartdata för första gången i en session måste du värma upp ett kluster.
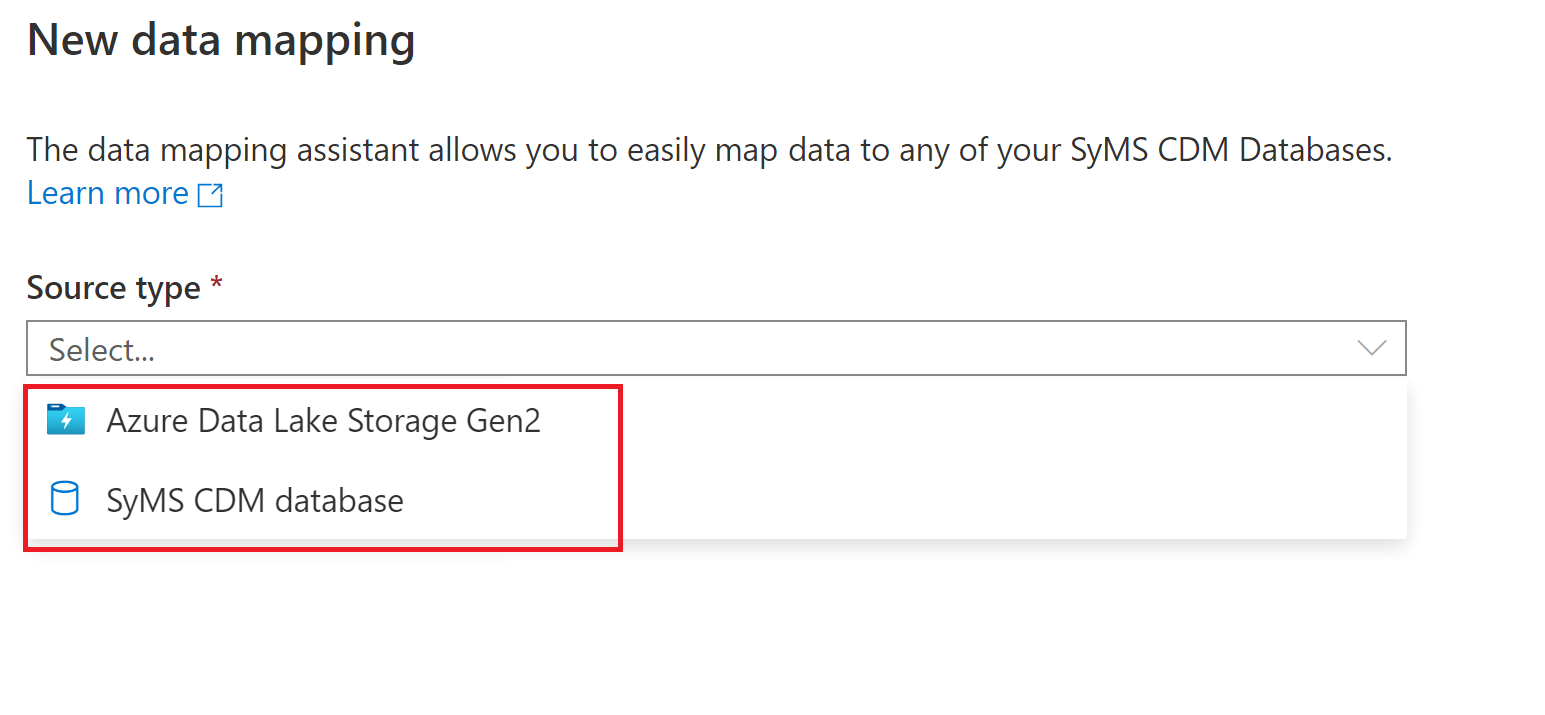
Börja genom att välja den datakälla som du vill mappa till dina lake-databastabeller. Datakällor som stöds för närvarande är Azure Data Lake Storage Gen 2- och Synapse Lake-databaser.
Filtypsalternativ
När du väljer ett filarkiv, till exempel Azure Data Lake Storage Gen 2, stöds följande filtyper:
- Common Data Model
- Avgränsad text
- Parquet
Skapa datamappning
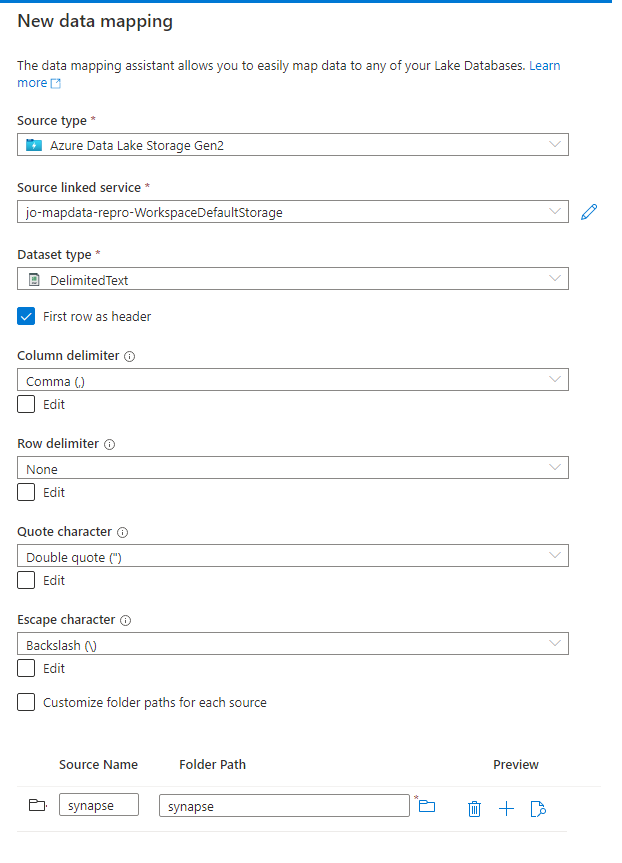
Konfigurera datamappningen med den källtyp som du har valt.
Anteckning
Du kan välja en mapp eller en enskild fil. Om du väljer en mapp kan du mappa flera filer till dina Lake-databastabeller. Om du väljer en mapp uppmanas du även att endast inkludera specifika filer, om så önskas, efter att du har valt att fortsätta.
Namnge datamappningen och välj Synapse Lake-databasmålet.
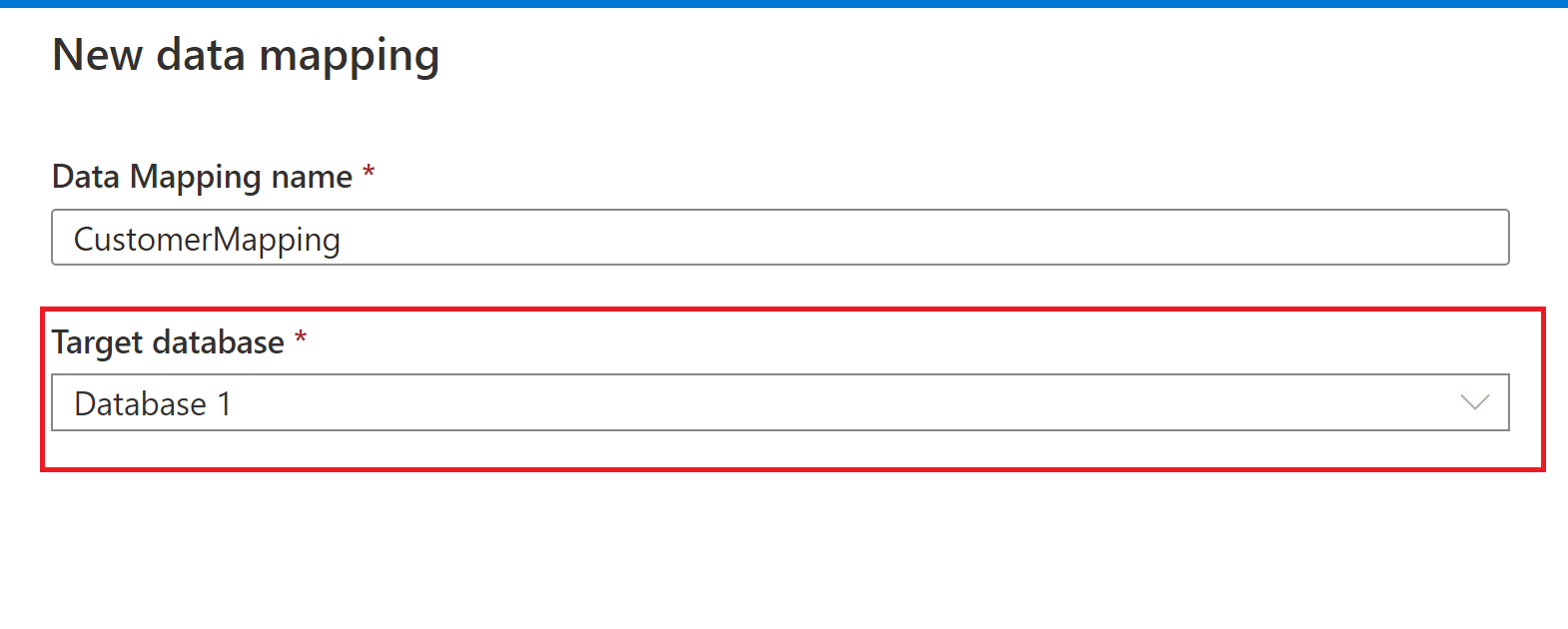
Käll-till-målmappning
Välj en primär källtabell som ska mappas till synapse lake-databasens måltabell.
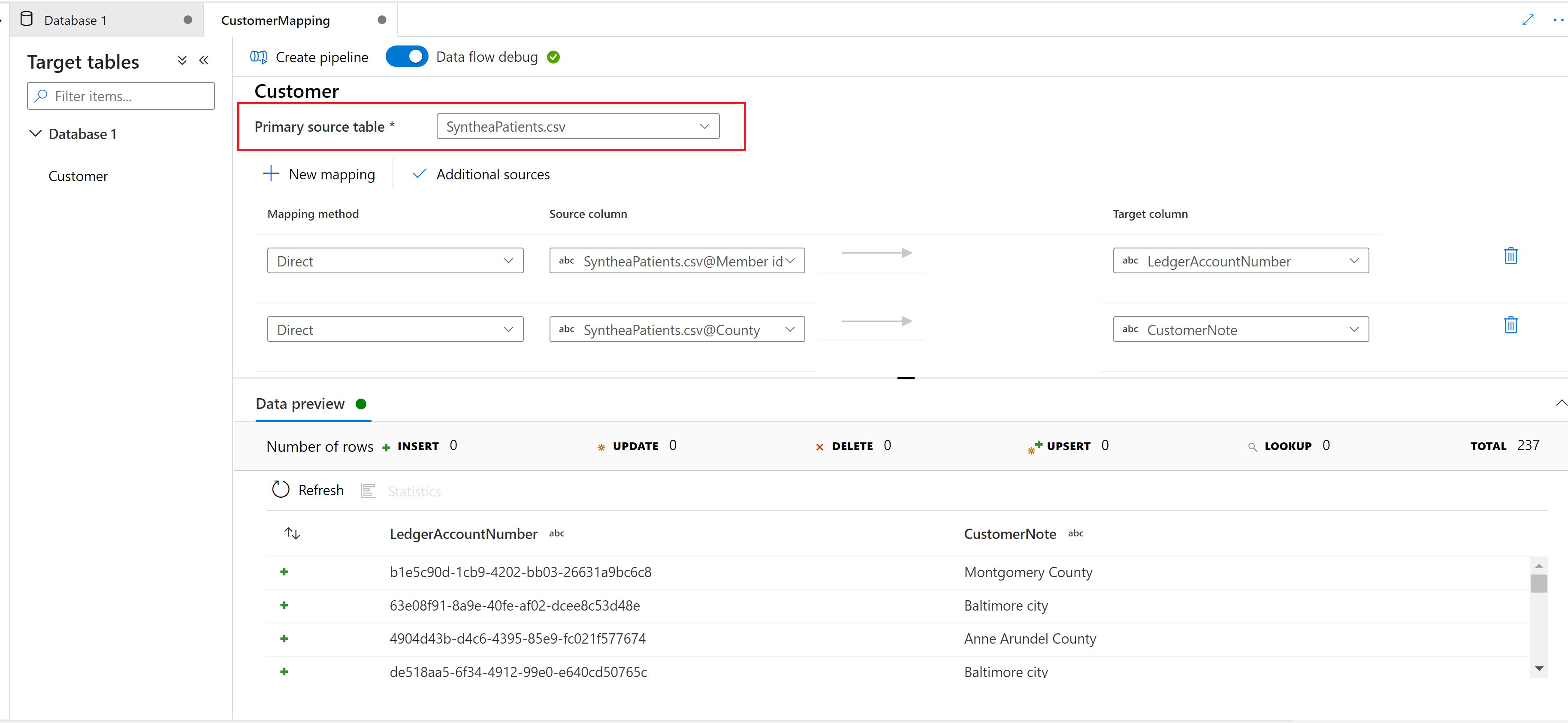
Ny mappning
Använd knappen Ny mappning för att lägga till en mappningsmetod för att skapa en mappning eller transformering.
Ytterligare källa
Använd knappen Ytterligare källa för att ansluta till och lägga till en annan källa i mappningen.
Förhandsgranska data
På fliken Dataförhandsgranskning får du en interaktiv ögonblicksbild av data för varje transformering. Mer information finns i Dataförhandsgranskning i felsökningsläge.
Mappningsmetoder
Följande mappningsmetoder stöds:
- Direct
- Surrogatnyckel
- Sökning
- Normalisera
-
Aggregera
- Sum
- Minimum
- Maximal
- Första
- Sista
- Standardavvikelse
- Genomsnitt
- Medelvärde
-
Härledd kolumn
- Trim
- Upper
- Lägre
- Avancerat
Skapa pipeline
När du är klar med dina Map Data-transformeringar väljer du knappen Skapa pipeline för att generera ett mappningsdataflöde och en pipeline för att felsöka och köra omvandlingen.