Felsöka Azure Stream Analytics-frågor
Den här artikeln beskriver vanliga problem med att utveckla Stream Analytics-frågor och hur du felsöker dem.
Den här artikeln beskriver vanliga problem med att utveckla Azure Stream Analytics-frågor, hur du felsöker frågeproblem och hur du åtgärdar problemen. Många felsökningssteg kräver att resursloggar aktiveras för ditt Stream Analytics-jobb. Om du inte har aktiverat resursloggar kan du läsa Felsöka Azure Stream Analytics med hjälp av resursloggar.
Frågan genererar inte förväntade utdata
Granska fel genom att testa lokalt:
- På Azure Portal går du till fliken Fråga och väljer Test. Använd hämtade exempeldata för att testa frågan. Granska eventuella fel och försök att korrigera dem.
- Du kan också testa din fråga lokalt med hjälp av Azure Stream Analytics-verktyg för Visual Studio eller Visual Studio Code.
Felsöka frågor steg för steg lokalt med hjälp av jobbdiagram i Azure Stream Analytics-verktyg för Visual Studio Code. Jobbdiagrammet visar hur data flödar från indatakällor (Event Hub, IoT Hub osv.) genom flera frågesteg och slutligen till utdatamottagare. Varje frågesteg mappas till en tillfällig resultatuppsättning som definierats i skriptet med hjälp av WITH-instruktionen. Du kan visa data och mått i varje mellanliggande resultatuppsättning för att hitta källan till problemet.
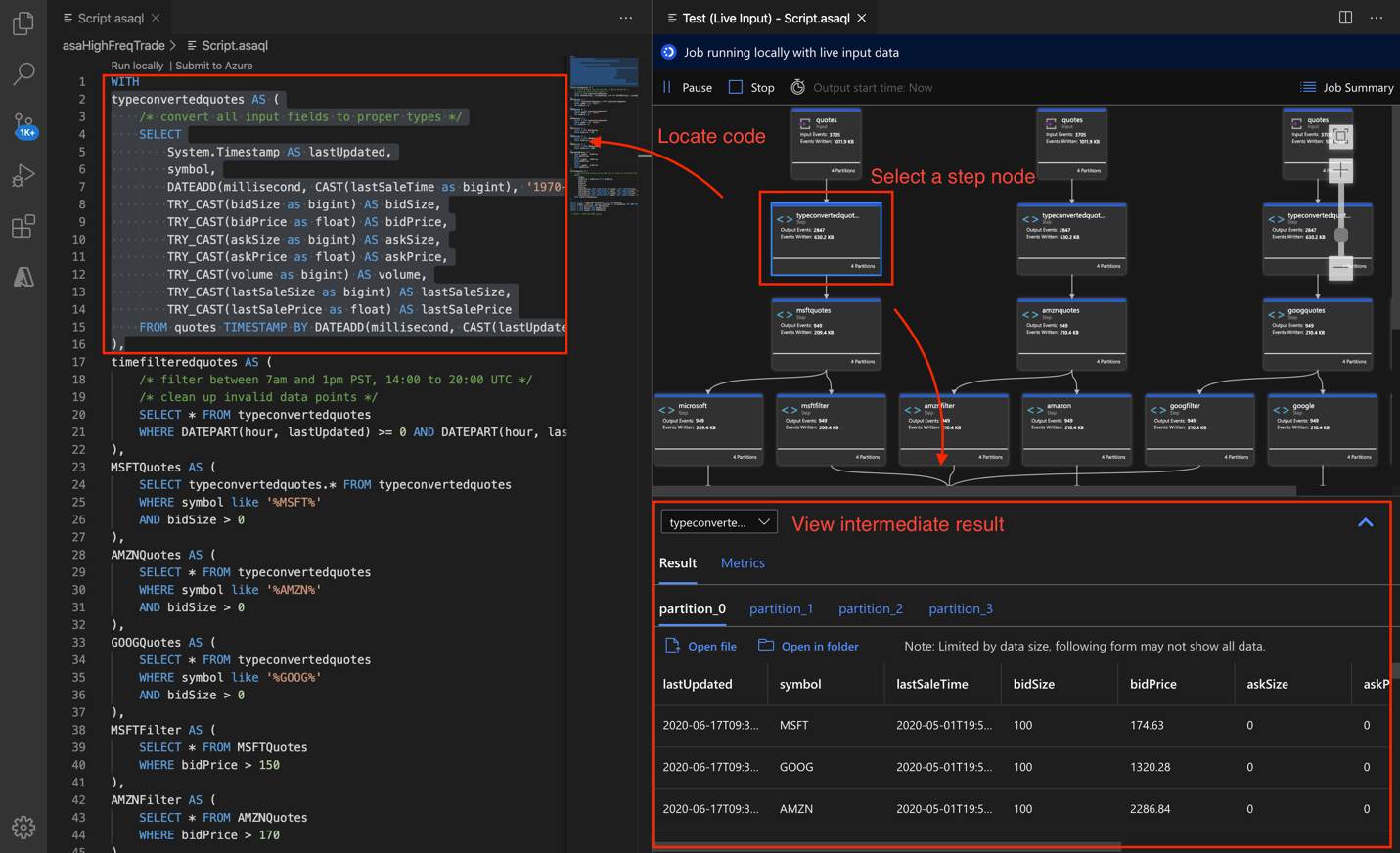
Om du använder Timestamp By kontrollerar du att händelserna har tidsstämplar som är större än jobbets starttid.
Eliminera vanliga fallgropar, till exempel:
- En WHERE-sats i frågan filtrerade bort alla händelser, vilket förhindrar att utdata genereras.
- En CAST-funktion misslyckas, vilket gör att jobbet misslyckas. Undvik typfel genom att använda TRY_CAST i stället.
- När du använder fönsterfunktioner väntar du hela fönstervaraktigheten för att se utdata från frågan.
- Tidsstämpeln för händelser föregår jobbets starttid och händelser tas bort.
- Kopplingsvillkoren matchar inte. Om det inte finns några matchningar blir det noll utdata.
Se till att händelseordningsprinciperna är konfigurerade som förväntat. Gå till Inställningar och välj Händelseordning. Principen tillämpas inte när du använder knappen Test för att testa frågan. Det här resultatet är en skillnad mellan att testa i webbläsaren och att köra jobbet i produktion.
Felsök med hjälp av aktivitets- och resursloggar:
- Använd aktivitetsloggar och filtrera för att identifiera och felsöka fel.
- Använd jobbresursloggar för att identifiera och felsöka fel.
Resursanvändningen är hög
Se till att du drar nytta av parallellisering i Azure Stream Analytics. Du kan lära dig att skala med frågeparallellisering av Stream Analytics-jobb genom att konfigurera indatapartitioner och justera analysfrågedefinitionen.
Om resursutnyttjandet är konsekvent över 80 %, ökar vattenstämpelfördröjningen och antalet eftersläppta händelser ökar, överväg att öka strömningsenheterna. Hög användning anger att jobbet använder nära de maximalt allokerade resurserna.
Felsöka frågor progressivt
Vid databearbetning i realtid kan det vara bra att veta hur data ser ut mitt i frågan. Du kan se detta med hjälp av jobbdiagrammet i Visual Studio. Om du inte har Visual Studio kan du vidta ytterligare åtgärder för att mata ut mellanliggande data.
Eftersom indata eller steg i ett Azure Stream Analytics-jobb kan läsas flera gånger kan du skriva extra SELECT INTO-instruktioner. När du gör det matas mellanliggande data in i lagringen och du kan kontrollera datans korrekthet, precis som när du felsöker ett program.
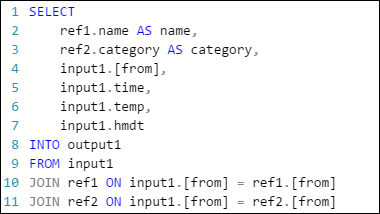
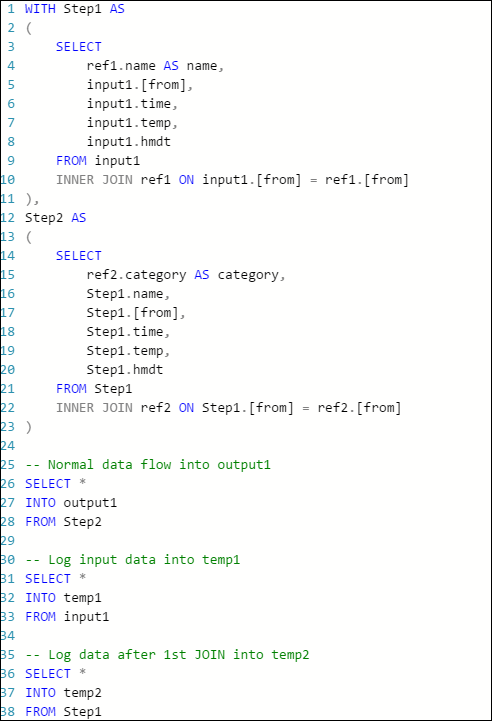
Följande exempelfråga i ett Azure Stream Analytics-jobb har en indataström, två referensdataindata och utdata till Azure Table Storage. Frågan kopplar data från händelsehubben och två referensblobar för att hämta namn- och kategoriinformationen:
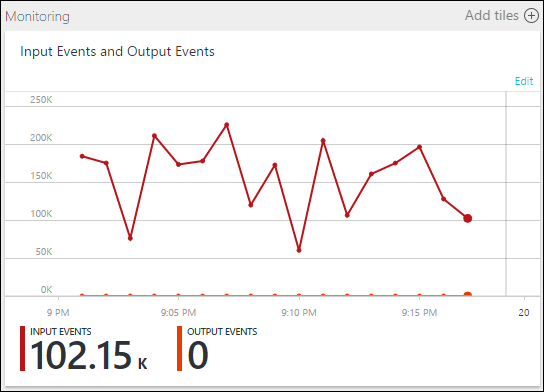
Observera att jobbet körs, men inga händelser skapas i utdata. På panelen Övervakning , som visas här, kan du se att indata producerar data, men du vet inte vilket steg i JOIN som orsakade att alla händelser släpptes.
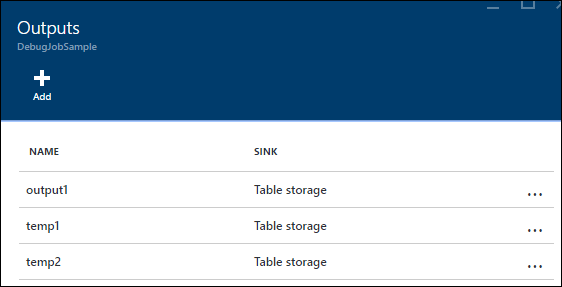
I det här fallet kan du lägga till några extra SELECT INTO-instruktioner för att "logga" mellanliggande JOIN-resultat och de data som läse från indata.
I det här exemplet har vi lagt till två nya "tillfälliga utdata". De kan vara vilken handfat du vill. Här använder vi Azure Storage som exempel:
Du kan sedan skriva om frågan så här:
Starta jobbet igen och låt det köras i några minuter. Fråga sedan temp1 och temp2 med Visual Studio Cloud Explorer för att skapa följande tabeller:
temp1-tabell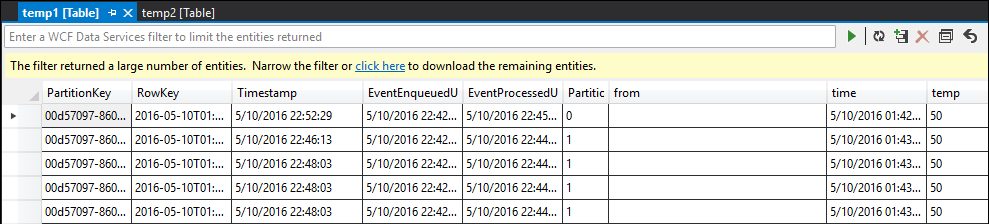
temp2-tabell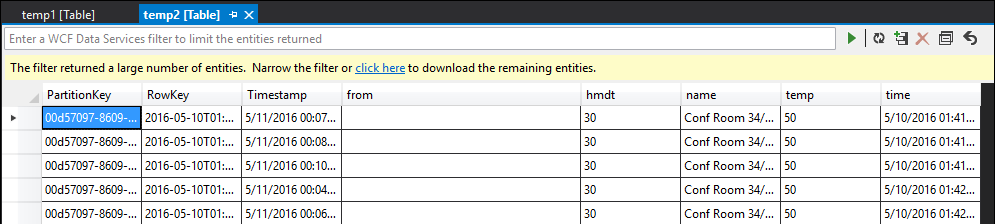
Som du ser har både temp1 och temp2 data, och namnkolumnen fylls korrekt i temp2. Men eftersom det fortfarande inte finns några data i utdata är något fel:
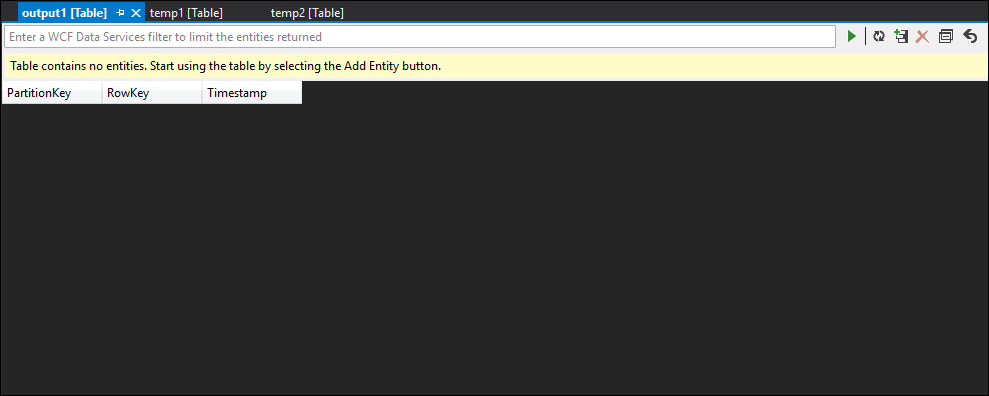
Genom att sampling av data kan du vara nästan säker på att problemet är med den andra JOIN. Du kan ladda ned referensdata från blobben och ta en titt:
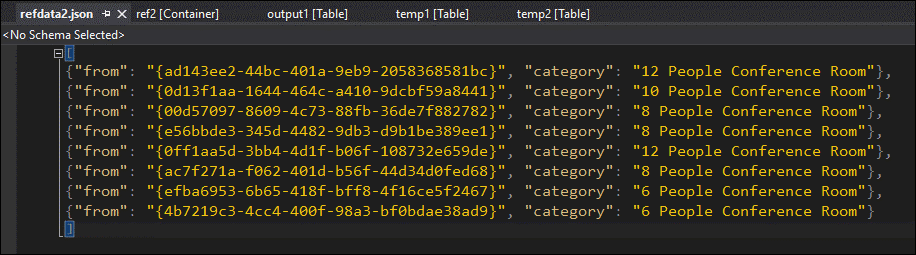
Som du ser skiljer sig formatet för GUID i dessa referensdata från formatet för kolumnen [från] i temp2. Det är därför data inte kom in i utdata1 som förväntat.
Du kan åtgärda dataformatet, ladda upp det till referensbloben och försöka igen:
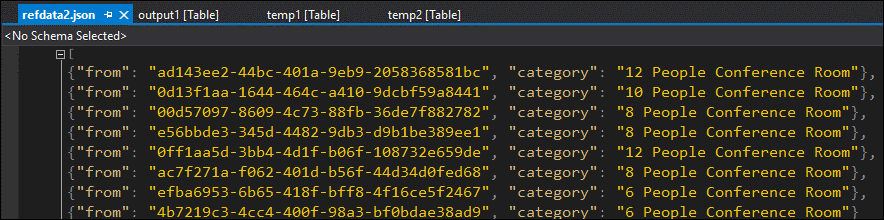
Den här gången formateras och fylls data i utdata som förväntat.
Få hjälp
Om du vill ha mer hjälp kan du prova vår frågesida för Microsoft Q&A för Azure Stream Analytics.