Felsöka med hjälp av det fysiska jobbdiagrammet (förhandsversion) i Azure Portal
Det fysiska jobbdiagrammet i Azure Portal kan hjälpa dig att visualisera jobbets nyckelmått med direktuppspelningsnoden i diagram- eller tabellformat, till exempel processoranvändning, minnesanvändning, indatahändelser, partitions-ID:n och vattenstämpelfördröjning. Det hjälper dig att identifiera orsaken till ett problem när du felsöker problem.
Den här artikeln visar hur du använder ett fysiskt jobbdiagram för att analysera ett jobbs prestanda och snabbt identifiera flaskhalsen i Azure Portal.
Viktigt!
Den här funktionen är för närvarande i förhandsversion. Juridiska villkor för Azure-funktioner i betaversion, förhandsversion eller som av någon annan anledning inte har gjorts allmänt tillgängliga ännu finns i kompletterande användningsvillkor för Microsoft Azure-förhandsversioner.
Identifiera parallelliteten för ett jobb
Jobbet med parallellisering är det skalbara scenariot i Stream Analytics som kan ge bättre prestanda. Om ett jobb inte är i parallellt läge har det troligtvis en viss flaskhals för dess prestanda. Det är viktigt att identifiera om ett jobb är i parallellt läge eller inte. Fysiskt jobbdiagram innehåller ett visuellt diagram som illustrerar jobbparallelliteten. Om det finns datainteraktion mellan olika direktuppspelningsnoder i ett fysiskt jobbdiagram är det här jobbet ett icke-parallellt jobb som behöver mer uppmärksamhet. Till exempel det icke-parallella jobbdiagrammet nedan:

Du kan överväga att optimera den till parallella jobb (som exempel nedan) genom att skriva om frågan eller uppdatera indata-/utdatakonfigurationer med jobbdiagramsimulatorn i Visual Studio Code ASA-tillägget eller frågeredigeraren i Azure Portal. Mer information finns i Optimera fråga med hjälp av jobbdiagramsimulator (förhandsversion).

Viktiga mått för att identifiera flaskhalsen i ett parallellt jobb
Vattenstämpelfördröjning och eftersläppta indatahändelser är de viktigaste måtten för att fastställa prestanda för ditt Stream Analytics-jobb. Om vattenstämpelfördröjningen för jobbet ökar kontinuerligt och indatahändelserna är eftersläppta kan jobbet inte hålla jämna steg med indatahändelserna och producera utdata i tid. Från beräkningsresursens synvinkel används processor- och minnesresurserna på hög nivå när det här fallet inträffar.
Det fysiska jobbdiagrammet visualiserar dessa nyckelmått i diagrammet tillsammans för att ge dig en fullständig bild av dem för att enkelt identifiera flaskhalsen.

Mer information om måttdefinitionen finns i Nodnamnsdimensionen för Azure Stream Analytics.
Identifiera ojämna distribuerade indatahändelser (datasnedställning)
När du redan har ett jobb som körs i parallellt läge, men du ser en fördröjning med hög vattenstämpel, använder du den här metoden för att avgöra varför.
Om du vill hitta rotorsaken öppnar du det fysiska jobbdiagrammet i Azure Portal. Välj Jobbdiagram (förhandsversion) under Övervakning och växla till Fysiskt diagram.
Från det fysiska diagrammet kan du enkelt identifiera om alla partitioner har hög vattenstämpelfördröjning, eller bara några av dem genom att visa vattenstämpelns fördröjningsvärde i varje nod eller välja inställningen för vattenstämpelfördröjning för att sortera de strömmande noderna (rekommenderas):

När du har tillämpat de heatmap-inställningar som du gjorde ovan får du direktuppspelningsnoderna med hög vattenstämpelfördröjning i det övre vänstra hörnet. Sedan kan du kontrollera om motsvarande direktuppspelningsnoder har betydande fler indatahändelser än andra. I det här exemplet har streamingnode#0 och streamingnode#1 fler indatahändelser.

Du kan ytterligare kontrollera hur många partitioner som allokeras till direktuppspelningsnoderna individuellt för att ta reda på om fler indatahändelser orsakas av fler allokerade partitioner eller om någon specifik partition har fler indatahändelser. I det här exemplet har alla direktuppspelningsnoder två partitioner. Det innebär att streamingnode#0 och streamingnode#1 har en viss specifik partition som innehåller fler indatahändelser än andra partitioner.
Gör följande för att hitta vilken partition som har fler indatahändelser än andra partitioner i streamingnode#0 och streamingnode#1:
- Välj Lägg till diagram i diagramavsnittet
- Lägga till indatahändelser i mått och partitions-ID i splitter
- Välj Använd för att ta fram diagrammet för indatahändelser
- Tick streamingnode #0 och streamingnode#1 i diagrammet
Diagrammet nedan visas med måttet för indatahändelser filtrerat efter partitionerna i de två direktuppspelningsnoderna.

Vilka ytterligare åtgärder kan du vidta?
Som du ser i exemplet har partitionerna (0 och 1) mer indata än andra partitioner. Vi kallar dessa data skeva. De direktuppspelningsnoder som bearbetar partitionerna med datasnedvridning måste förbruka mer PROCESSOR- och minnesresurser än andra. Den här obalansen leder till långsammare prestanda och ökar vattenstämpelfördröjningen. Du kan kontrollera cpu- och minnesanvändningen i de två direktuppspelningsnoderna samt i det fysiska diagrammet. För att lösa problemet måste du partitionera om dina indata jämnare.
Identifiera orsaken till överlagrade processorer eller minne
När ett parallellt jobb har en ökande vattenstämpelfördröjning utan den tidigare nämnda datasnedvridningssituationen kan det orsakas av en betydande mängd data över alla strömmande noder som hämmar prestanda. Du kan identifiera att jobbet har den här egenskapen med hjälp av det fysiska diagrammet.
Öppna det fysiska jobbdiagrammet, gå till jobbet Azure Portal under Övervakning, välj Jobbdiagram (förhandsversion) och växla till Fysiskt diagram. Du ser det fysiska diagrammet som läses in enligt nedan.
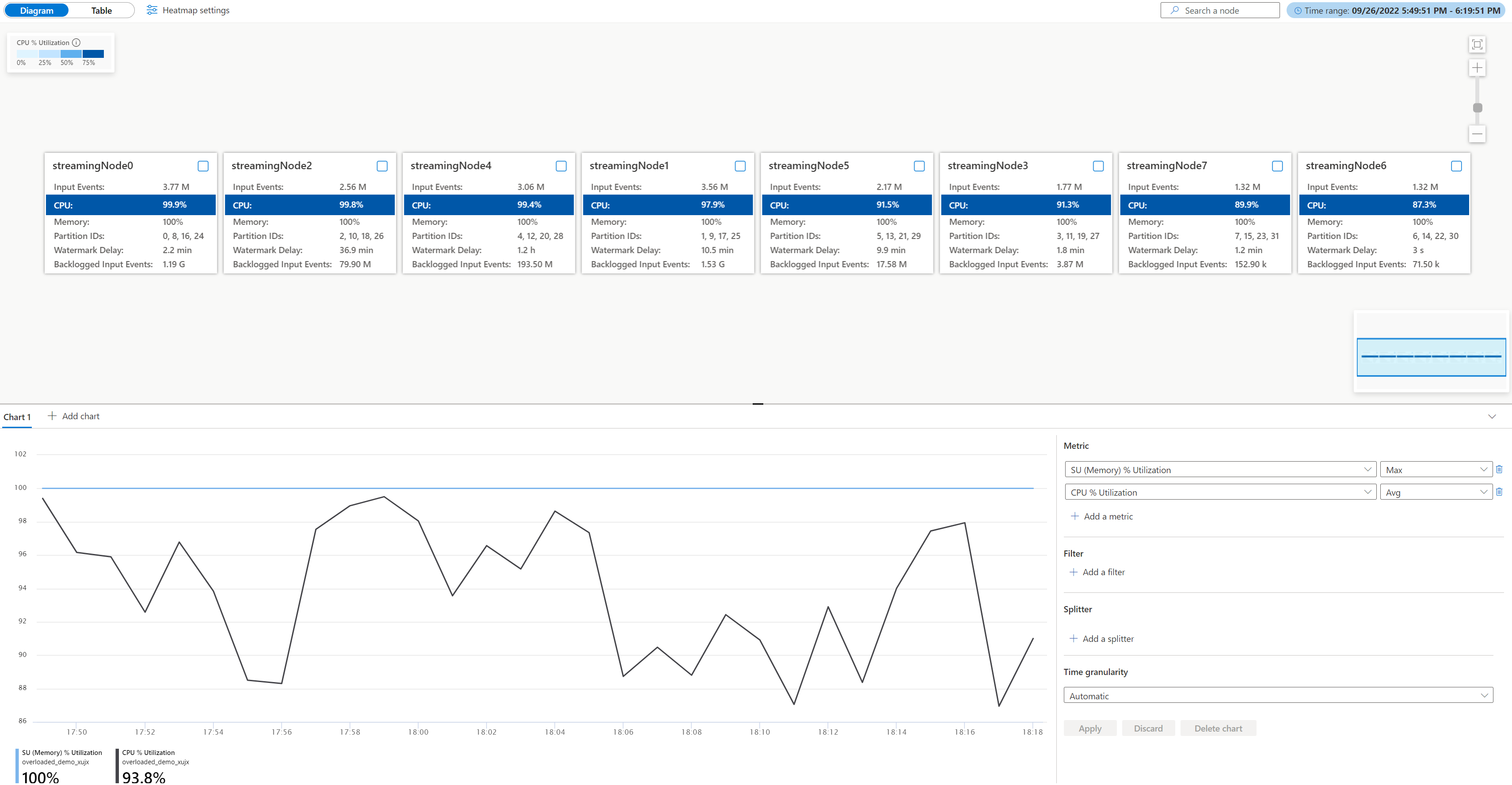
Kontrollera processor- och minnesanvändningen i varje direktuppspelningsnod för att se om användningen i alla strömmande noder är för hög. Om processor- och SU-användningen är hög (mer än 80 procent) i alla direktuppspelningsnoder kan du dra slutsatsen att det här jobbet har en stor mängd data som bearbetas inom varje direktuppspelningsnod.
Från ovanstående fall är processoranvändningen cirka 90 % och minnesanvändningen är redan 100 %. Den visar att varje strömmande nod börjar få slut på resurser för att bearbeta data.
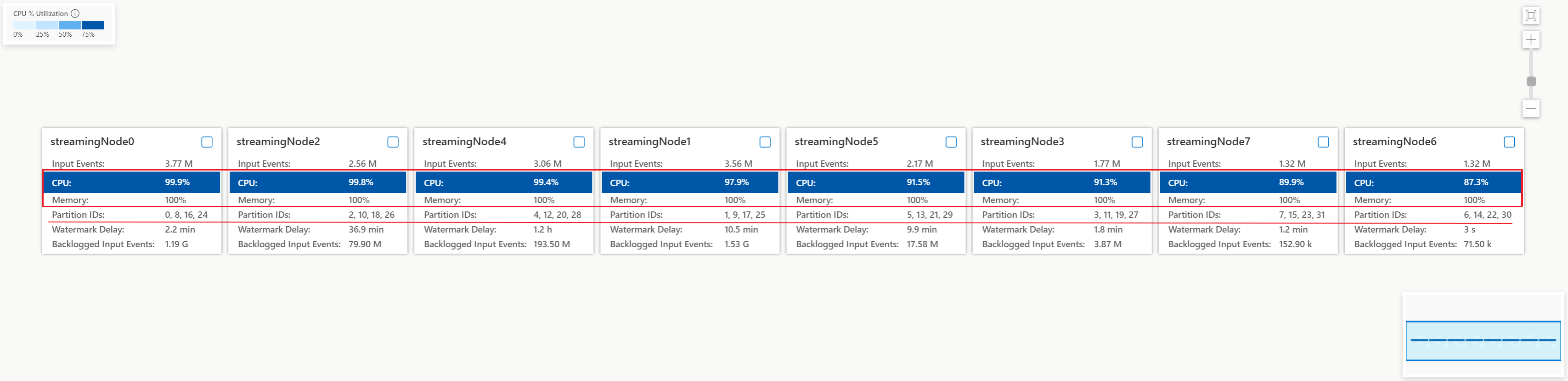
Kontrollera hur många partitioner som allokeras till varje direktuppspelningsnod så att du kan avgöra om du behöver fler direktuppspelningsnoder för att balansera partitionerna för att minska belastningen på befintliga direktuppspelningsnoder.
I det här fallet har varje direktuppspelningsnod fyra allokerade partitioner som ser för mycket ut till en direktuppspelningsnod.


Vilka ytterligare åtgärder kan du vidta?
Överväg att minska antalet partitioner för varje direktuppspelningsnod för att minska indata. Du kan fördubbla de SUS:er som allokerats till varje direktuppspelningsnod till två partitioner per nod genom att öka antalet strömmande noder från 8 till 16. Eller så kan du fyrdubbla SUS:erna så att varje strömmande nod hanterar data från en partition.
Mer information om relationen mellan strömningsnod och strömningsenhet finns i Förstå strömningsenhet och strömningsnod.
Vad ska du göra om vattenstämpelfördröjningen fortfarande ökar när en strömmande nod hanterar data från en partition? Partitionera om dina indata med fler partitioner för att minska mängden data i varje partition. Mer information finns i Använda ompartitionering för att optimera Azure Stream Analytics-jobb.