Analysera Stream Analytics-jobbprestanda med hjälp av mått och dimensioner
För att förstå ett Azure Stream Analytics-jobbs hälsa är det viktigt att du vet hur du använder jobbets mått och dimensioner. Du kan använda Azure Portal, Visual Studio Code Stream Analytics-tillägget eller en SDK för att hämta de mått och dimensioner som du är intresserad av.
Den här artikeln visar hur du använder Stream Analytics-jobbmått och dimensioner för att analysera ett jobbs prestanda via Azure Portal.
Vattenstämpelfördröjning och eftersläppta indatahändelser är de viktigaste måtten för att fastställa prestanda för ditt Stream Analytics-jobb. Om vattenstämpelfördröjningen för jobbet ökar kontinuerligt och indatahändelserna är eftersläppta kan jobbet inte hålla jämna steg med indatahändelserna och producera utdata i tid.
Nu ska vi titta på flera exempel för att analysera ett jobbs prestanda via måttdata för vattenstämpelfördröjning som utgångspunkt.
Inga indata för en viss partition ökar jobbvattenstämpelfördröjningen
Om ditt pinsamt parallella jobbs vattenstämpelfördröjning ökar stadigt går du till Mått. Använd sedan de här stegen för att ta reda på om rotorsaken är brist på data i vissa partitioner av din indatakälla:
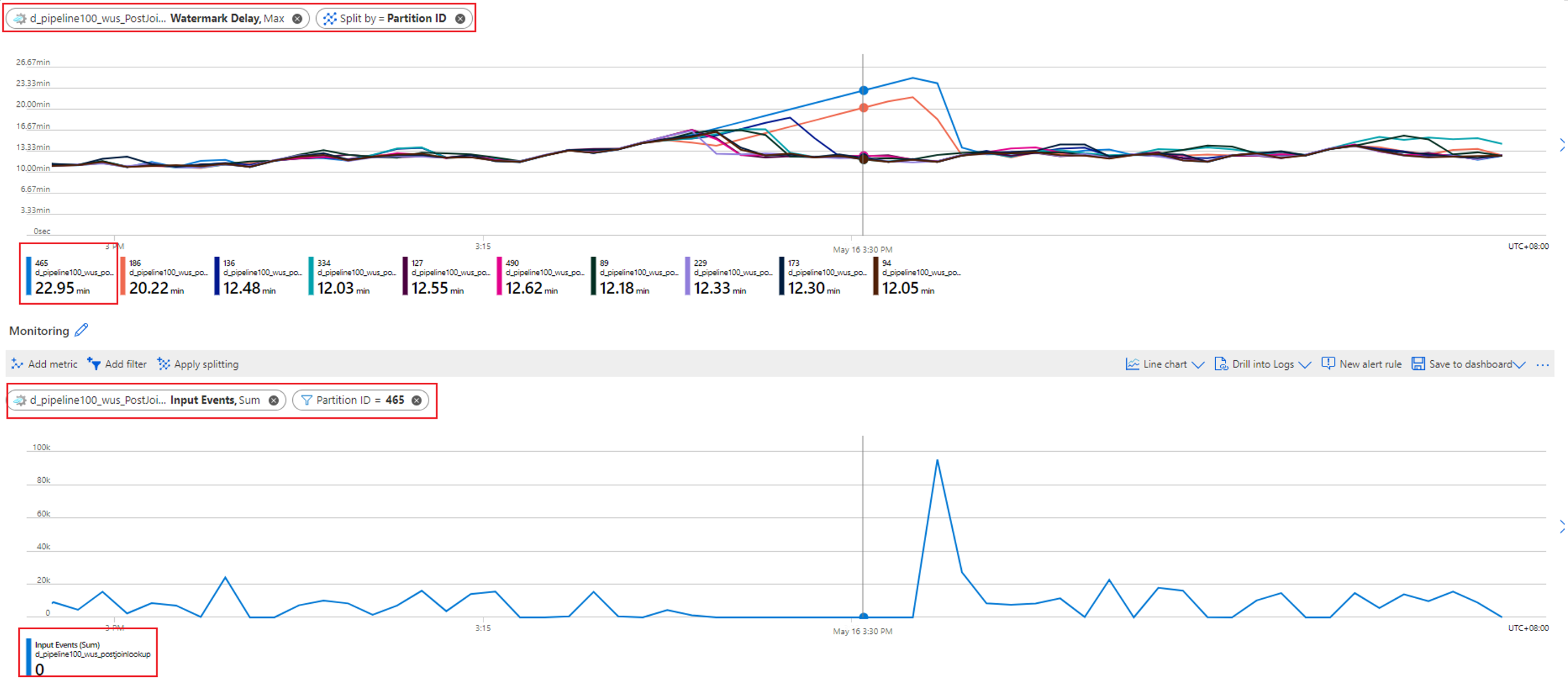
Kontrollera vilken partition som har den ökande vattenstämpelfördröjningen. Välj måttet Vattenstämpelfördröjning och dela upp det med dimensionen partitions-ID . I följande exempel har partition 465 en fördröjning med hög vattenstämpel.

Kontrollera om indata saknas för den här partitionen. Välj måttet Indatahändelser och filtrera det till det här specifika partitions-ID:t.


Vilka ytterligare åtgärder kan du vidta?
Vattenstämpelfördröjningen för den här partitionen ökar eftersom inga indatahändelser flödar in i den här partitionen. Om ditt jobbs toleransfönster för sena ankomster är flera timmar och inga indata flödar in i en partition, förväntas vattenstämpelfördröjningen för partitionen fortsätta att öka tills fönstret för sen ankomst har nåtts.
Om fönstret för sen ankomst till exempel är 6 timmar och indata inte flödar till indatapartition 1, ökar vattenstämpelfördröjningen för utdatapartition 1 tills den når 6 timmar. Du kan kontrollera om din indatakälla producerar data som förväntat.
Snedställning av indata orsakar en fördröjning med hög vattenstämpel
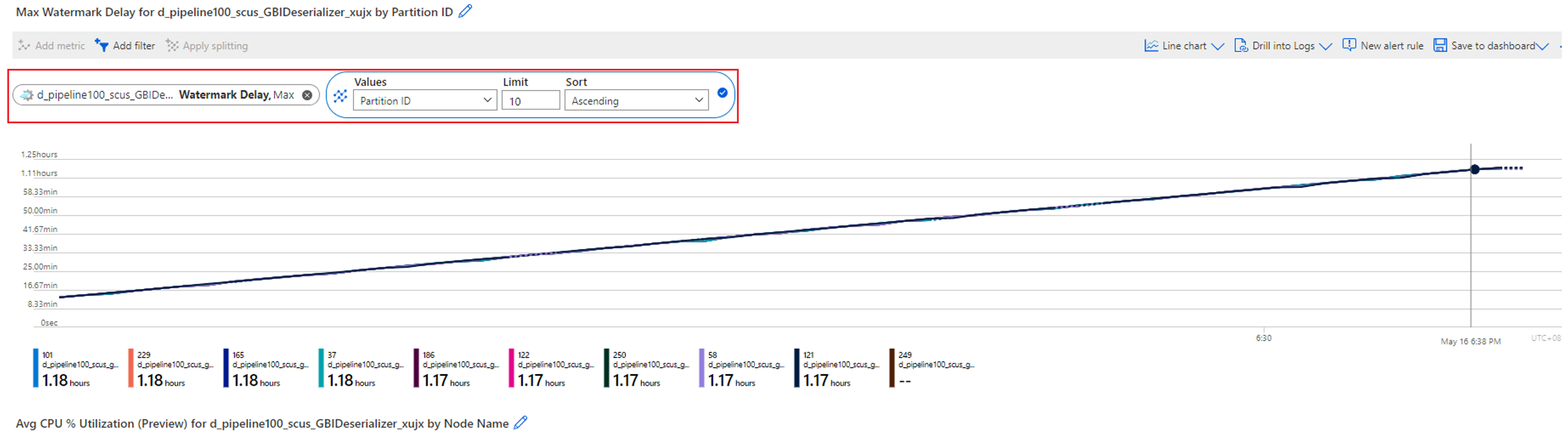
Som nämnts i föregående fall, när ditt pinsamt parallella jobb har en fördröjning med hög vattenstämpel, är det första du behöver göra att dela upp måttet Vattenstämpelfördröjning med partitions-ID-dimensionen . Du kan sedan identifiera om alla partitioner har hög vattenstämpelfördröjning eller bara några av dem.
I följande exempel har partitionerna 0 och 1 högre vattenstämpelfördröjning (cirka 20 till 30 sekunder) än de övriga åtta partitionerna har. De andra partitionernas vattenstämpelfördröjningar är alltid stabila på cirka 8 till 10 sekunder.

Nu ska vi kontrollera hur indata ser ut för alla dessa partitioner med måttet Indatahändelser som delas upp av partitions-ID:

Vilka ytterligare åtgärder kan du vidta?
Som du ser i exemplet får partitionerna (0 och 1) som har en fördröjning med hög vattenstämpel betydligt mer indata än andra partitioner. Vi kallar dessa data skeva. De direktuppspelningsnoder som bearbetar partitionerna med datasnedvridning måste förbruka mer processor- och minnesresurser än andra, som du ser i följande skärmbild.

Direktuppspelningsnoder som bearbetar partitioner med högre datasnedvridning uppvisar högre PROCESSOR- och/eller strömningsenhetsanvändning (SU). Den här användningen påverkar jobbets prestanda och ökar vattenstämpelfördröjningen. För att minimera detta måste du partitionera om dina indata jämnare.
Du kan också felsöka det här problemet med ett fysiskt jobbdiagram, se Fysiskt jobbdiagram: Identifiera ojämna distribuerade indatahändelser (datasnedställning).
Överbelastad PROCESSOR eller minne ökar vattenstämpelfördröjningen
När ett pinsamt parallellt jobb har en ökande vattenstämpelfördröjning kan det inträffa på inte bara en eller flera partitioner, utan på alla partitioner. Hur bekräftar du att ditt jobb hamnar i det här fallet?
Dela upp måttet Vattenstämpelfördröjning med partitions-ID. Till exempel:
Dela måttet Indatahändelser efter partitions-ID för att bekräfta om det finns dataförskjutning i indata för varje partition.
Kontrollera PROCESSOR- och SU-användningen för att se om användningen i alla direktuppspelningsnoder är för hög.
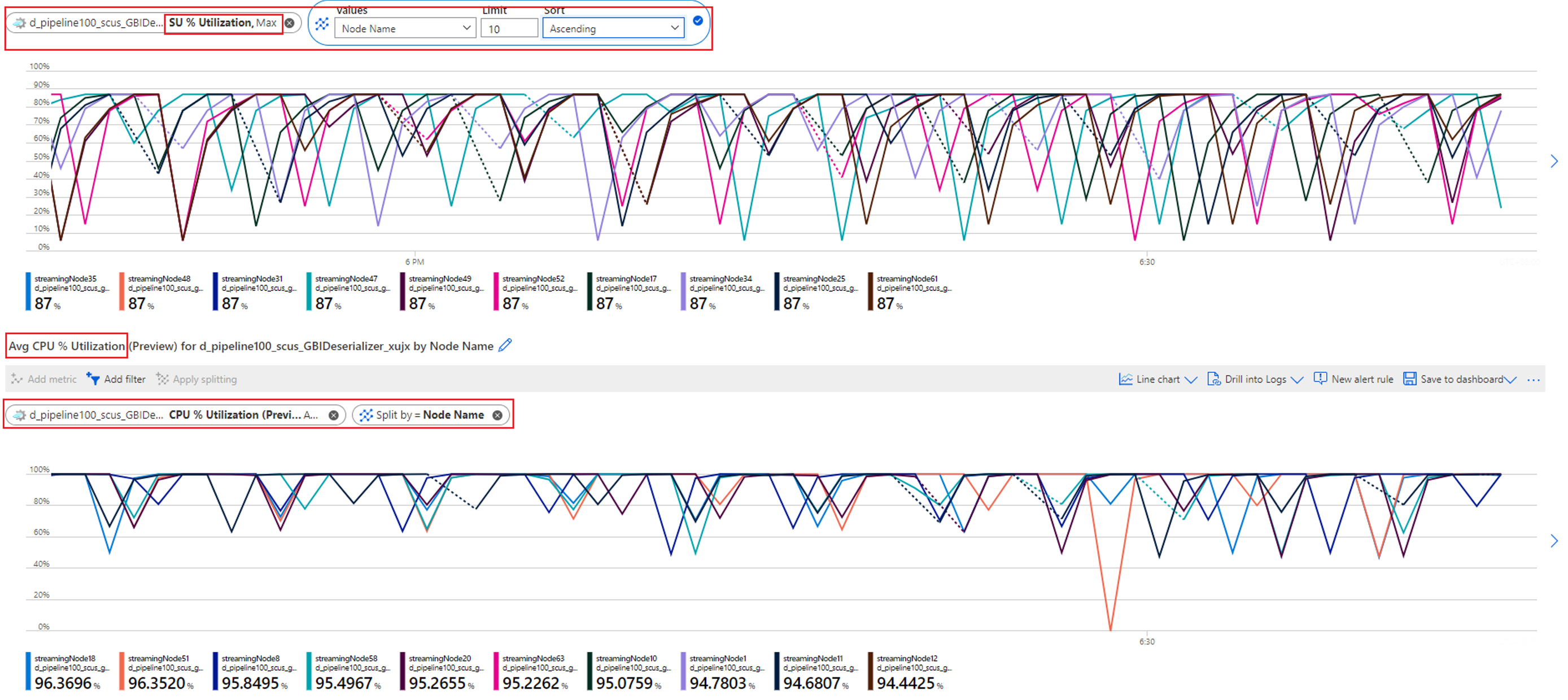
Om processor- och SU-användningen är mycket hög (mer än 80 procent) i alla direktuppspelningsnoder kan du dra slutsatsen att det här jobbet har en stor mängd data som bearbetas inom varje direktuppspelningsnod.
Du kan kontrollera hur många partitioner som allokeras till en direktuppspelningsnod genom att kontrollera måttet Indatahändelser . Filtrera efter strömmande nod-ID med dimensionen Nodnamn och dela upp med partitions-ID.
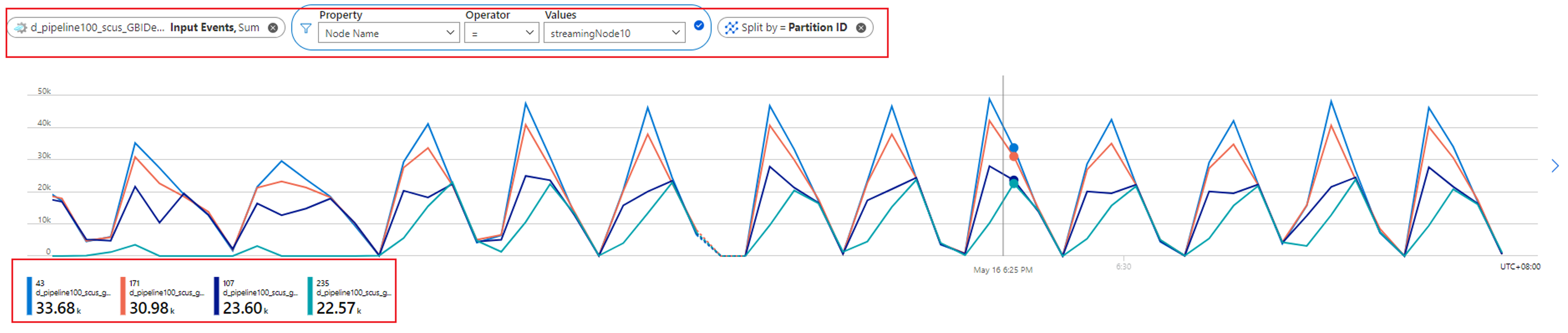
Föregående skärmbild visar att fyra partitioner allokeras till en direktuppspelningsnod som upptar cirka 90 till 100 procent av den strömmande nodresursen. Du kan använda en liknande metod för att kontrollera resten av strömningsnoderna för att bekräfta att de också bearbetar data från fyra partitioner.



Vilka ytterligare åtgärder kan du vidta?
Du kanske vill minska antalet partitioner för varje direktuppspelningsnod för att minska indata för varje strömmande nod. För att uppnå detta kan du dubbla SUS:erna så att varje strömmande nod hanterar data från två partitioner. Eller så kan du fyrdubbla SUS:erna så att varje strömmande nod hanterar data från en partition. Information om relationen mellan SU-tilldelning och antal direktuppspelningsnoder finns i Förstå och justera strömningsenheter.
Vad ska du göra om vattenstämpelfördröjningen fortfarande ökar när en strömmande nod hanterar data från en partition? Partitionera om dina indata med fler partitioner för att minska mängden data i varje partition. Mer information finns i Använda ompartitionering för att optimera Azure Stream Analytics-jobb.
Du kan också felsöka det här problemet med ett fysiskt jobbdiagram, se Fysiskt jobbdiagram: Identifiera orsaken till överlagrade processorer eller minne.