Metodtips för att använda Azure Data Lake Storage
Den här artikeln innehåller riktlinjer för bästa praxis som hjälper dig att optimera prestanda, minska kostnaderna och skydda ditt Data Lake Storage-aktiverade Azure Storage-konto.
Allmänna förslag på hur du strukturerar en datasjö finns i följande artiklar:
- Översikt över Azure Data Lake Storage för scenariot för datahantering och analys
- Etablera tre Azure Data Lake Storage-konton för varje datalandningszon
Hitta dokumentation
Azure Data Lake Storage är inte en dedikerad tjänst eller kontotyp. Det är en uppsättning funktioner som stöder analysarbetsbelastningar med högt dataflöde. Dokumentationen om Data Lake Storage innehåller metodtips och vägledning för att använda dessa funktioner. Alla andra aspekter av kontohantering, till exempel konfiguration av nätverkssäkerhet, design för hög tillgänglighet och haveriberedskap, finns i dokumentationsinnehållet för Blob Storage.
Utvärdera funktionsstöd och kända problem
Använd följande mönster när du konfigurerar ditt konto för att använda Blob Storage-funktioner.
Läs artikeln om stöd för Blob Storage-funktioner i Azure Storage-konton för att avgöra om en funktion stöds fullt ut i ditt konto. Vissa funktioner stöds ännu inte eller har delvis stöd i Data Lake Storage-aktiverade konton. Funktionsstöd expanderas alltid, så se till att regelbundet granska den här artikeln för uppdateringar.
Läs artikeln Kända problem med Azure Data Lake Storage för att se om det finns några begränsningar eller särskild vägledning kring den funktion som du tänker använda.
Sök igenom funktionsartiklar efter vägledning som är specifik för Data Lake Storage-aktiverade konton.
Förstå de termer som används i dokumentationen
När du flyttar mellan innehållsuppsättningar ser du några små terminologiskillnader. Innehåll som finns i bloblagringsdokumentationen använder till exempel termen blob i stället för fil. Tekniskt sett blir de filer som du matar in till ditt lagringskonto blobar i ditt konto. Termen är därför korrekt. Termen blob kan dock orsaka förvirring om du är van vid termfilen. Du ser även termen container som används för att referera till ett filsystem. Betrakta dessa termer som synonyma.
Överväg premium
Om dina arbetsbelastningar kräver en låg konsekvent svarstid och/eller kräver ett stort antal indatautdataåtgärder per sekund (IOP), bör du överväga att använda ett premium-blockbloblagringskonto. Den här typen av konto gör data tillgängliga via maskinvara med höga prestanda. Data lagras på solid state-enheter (SSD) som är optimerade för låg svarstid. SSD ger högre dataflöde jämfört med traditionella hårddiskar. Lagringskostnaderna för premiumprestanda är högre, men transaktionskostnaderna är lägre. Om dina arbetsbelastningar kör ett stort antal transaktioner kan därför ett blobkonto för premiumprestandablock vara ekonomiskt.
Om ditt lagringskonto ska användas för analys rekommenderar vi starkt att du använder Azure Data Lake Storage tillsammans med ett Premium-blockbloblagringskonto. Den här kombinationen av att använda Premium-blockbloblagringskonton tillsammans med ett Data Lake Storage-aktiverat konto kallas premiumnivån för Azure Data Lake Storage.
Optimera för datamatning
När du matar in data från ett källsystem kan källmaskinvaran, källnätverksmaskinvaran eller nätverksanslutningen till ditt lagringskonto vara en flaskhals.
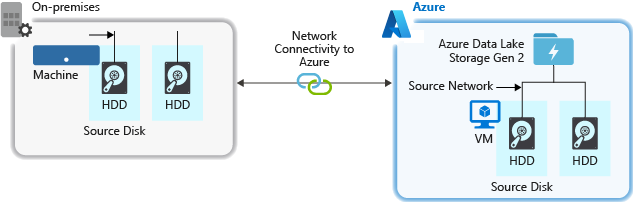
Källmaskinvara
Oavsett om du använder lokala datorer eller virtuella datorer i Azure bör du noga välja lämplig maskinvara. För diskmaskinvara bör du överväga att använda SSD (Solid State Drives) och välja diskmaskinvara som har snabbare spindlar. För nätverksmaskinvara använder du de snabbaste nätverkskorten (NIC) som möjligt. I Azure rekommenderar vi virtuella Azure D14-datorer som har rätt kraftfull disk- och nätverksmaskinvara.
Nätverksanslutning till lagringskontot
Nätverksanslutningen mellan dina källdata och ditt lagringskonto kan ibland vara en flaskhals. När dina källdata är lokala bör du överväga att använda en dedikerad länk med Azure ExpressRoute. Om dina källdata finns i Azure är prestandan bäst när data finns i samma Azure-region som ditt Data Lake Storage-aktiverat konto.
Konfigurera datainmatningsverktyg för maximal parallellisering
Du får bästa möjliga prestanda genom att använda alla tillgängliga dataflöden genom att utföra så många läsningar och skrivningar som möjligt parallellt.
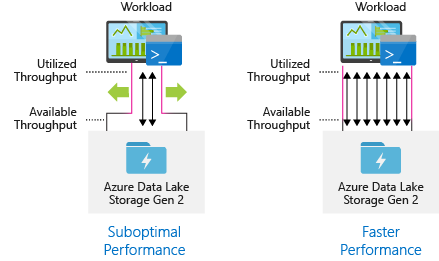
I följande tabell sammanfattas nyckelinställningarna för flera populära inmatningsverktyg.
| Verktyg | Inställningar |
|---|---|
| DistCp | -m (mapper) |
| Azure Data Factory | parallelCopies |
| Sqoop | fs.azure.block.size, -m (mapper) |
| AzCopy | AZCOPY_CONCURRENCY_VALUE |
Kommentar
Den övergripande prestandan för dina inmatningsåtgärder beror på andra faktorer som är specifika för det verktyg som du använder för att mata in data. Den bästa uppdaterade vägledningen finns i dokumentationen för varje verktyg som du tänker använda.
Ditt konto kan skalas för att tillhandahålla det dataflöde som krävs för alla analysscenarier. Som standard ger ett Data Lake Storage-aktiverat konto tillräckligt med dataflöde i standardkonfigurationen för att uppfylla behoven i en bred kategori av användningsfall. Om du stöter på standardgränsen kan kontot konfigureras för att ge mer dataflöde genom att kontakta Azure Support.
Strukturera datauppsättningar
Överväg att planera strukturen för dina data i förväg. Filformat, filstorlek och katalogstruktur kan påverka prestanda och kostnader.
Filformat
Data kan matas in i olika format. Data kan visas i läsbara format som JSON, CSV eller XML eller som komprimerade binära format som .tar.gz. Data kan också komma i olika storlekar. Data kan bestå av stora filer (några terabyte), till exempel data från en export av en SQL-tabell från dina lokala system. Data kan också komma i form av ett stort antal små filer (några kilobyte) som data från realtidshändelser från en IoT-lösning (Internet of things). Du kan optimera effektiviteten och kostnaderna genom att välja ett lämpligt filformat och filstorlek.
Hadoop stöder en uppsättning filformat som är optimerade för lagring och bearbetning av strukturerade data. Några vanliga format är ORC-format (Avro, Parquet och Optimized Row Columnar). Alla dessa format är maskinläsbara binära filformat. De komprimeras för att hjälpa dig att hantera filstorleken. De har ett schema inbäddat i varje fil, vilket gör dem självbeskrivande. Skillnaden mellan dessa format är hur data lagras. Avro lagrar data i ett radbaserat format och Parquet- och ORC-formaten lagrar data i ett kolumnformat.
Överväg att använda Avro-filformatet i de fall där dina I/O-mönster är mer skrivintensiva, eller om frågemönstren föredrar att hämta flera rader med poster i sin helhet. Avro-formatet fungerar till exempel bra med en meddelandebuss, till exempel Event Hubs eller Kafka som skriver flera händelser/meddelanden i följd.
Överväg parquet- och ORC-filformat när I/O-mönstren är mer läsintensiva eller när frågemönstren fokuserar på en delmängd kolumner i posterna. Lästransaktioner kan optimeras för att hämta specifika kolumner i stället för att läsa hela posten.
Apache Parquet är ett öppen källkod filformat som är optimerat för läsintensiva analyspipelines. Med den kolumnära lagringsstrukturen i Parquet kan du hoppa över icke-relevanta data. Dina frågor är mycket effektivare eftersom de kan begränsa omfattningen av vilka data som ska skickas från lagring till analysmotorn. Eftersom liknande datatyper (för en kolumn) lagras tillsammans stöder Parquet också effektiva datakomprimerings- och kodningsscheman som kan sänka kostnaderna för datalagring. Tjänster som Azure Synapse Analytics, Azure Databricks och Azure Data Factory har inbyggda funktioner som utnyttjar Parquet-filformat.
Filstorlek
Större filer leder till bättre prestanda och lägre kostnader.
Vanligtvis har analysmotorer som HDInsight en omkostnad per fil som omfattar uppgifter som att lista, kontrollera åtkomst och utföra olika metadataåtgärder. Om du lagrar dina data så många små filer kan detta påverka prestanda negativt. I allmänhet kan du ordna dina data i större filer för bättre prestanda (256 TILL 100 GB i storlek). Vissa motorer och program kan ha problem med att effektivt bearbeta filer som är större än 100 GB.
Att öka filstorleken kan också minska transaktionskostnaderna. Läs- och skrivåtgärder faktureras i steg om 4 megabyte, så du debiteras för åtgärden oavsett om filen innehåller 4 megabyte eller bara några få kilobyte. Prisinformation finns i Priser för Azure Data Lake Storage.
Ibland har datapipelines begränsad kontroll över rådata, som har många små filer. I allmänhet rekommenderar vi att systemet har någon form av process för att aggregera små filer till större filer för användning av underordnade program. Om du bearbetar data i realtid kan du använda en realtidsströmningsmotor (till exempel Azure Stream Analytics eller Spark Streaming) tillsammans med en meddelandekö (till exempel Event Hubs eller Apache Kafka) för att lagra dina data som större filer. När du aggregerar små filer i större filer bör du överväga att spara dem i ett läsoptimerad format, till exempel Apache Parquet för nedströmsbearbetning.
Katalogstruktur
Varje arbetsbelastning har olika krav på hur data används, men det här är några vanliga layouter att tänka på när du arbetar med Sakernas Internet (IoT), batchscenarier eller när du optimerar för tidsseriedata.
IoT-struktur
I IoT-arbetsbelastningar kan det finnas en hel del data som matas in som sträcker sig över flera produkter, enheter, organisationer och kunder. Det är viktigt att planera kataloglayouten i förväg för organisation, säkerhet och effektiv bearbetning av data för nedströmskonsumenter. En allmän mall att tänka på kan vara följande layout:
- {Region}/{SubjectMatter(s)}/{yyyyy}/{mm}/{dd}/{hh}/
Landningstelemetri för en flygplansmotor i Storbritannien kan till exempel se ut som följande struktur:
- UK/Planes/BA1293/Engine1/2017/08/11/12/
I det här exemplet kan du använda ACL:er för att enklare skydda regioner och ämnesfrågor för specifika användare och grupper genom att ange datumet i slutet av katalogstrukturen. Om du sätter datumstrukturen i början skulle det vara mycket svårare att skydda dessa regioner och ämnesfrågor. Om du till exempel bara vill ge åtkomst till brittiska data eller vissa plan måste du tillämpa en separat behörighet för flera kataloger under katalogen varje timme. Den här strukturen skulle också exponentiellt öka antalet kataloger allt eftersom tiden gick.
Batch-jobbstruktur
En vanlig metod för batchbearbetning är att placera data i en "in"-katalog. När data har bearbetats placerar du sedan de nya data i en "out"-katalog för nedströmsprocesser som ska användas. Den här katalogstrukturen används ibland för jobb som kräver bearbetning av enskilda filer och kanske inte kräver massivt parallell bearbetning över stora datamängder. Precis som den IoT-struktur som rekommenderas ovan har en bra katalogstruktur kataloger på överordnad nivå för saker som region och ämnesfrågor (till exempel organisation, produkt eller producent). Överväg datum och tid i strukturen för att möjliggöra bättre organisation, filtrerade sökningar, säkerhet och automatisering i bearbetningen. Detaljnivån för datumstrukturen bestäms av det intervall som data laddas upp eller bearbetas, till exempel varje timme, varje dag eller till och med varje månad.
Ibland misslyckas filbearbetningen på grund av skadade data eller oväntade format. I sådana fall kan en katalogstruktur dra nytta av en /bad-mapp för att flytta filerna till för ytterligare kontroll. Batch-jobbet kan också hantera rapporteringen eller aviseringen av dessa felaktiga filer för manuella åtgärder. Överväg följande mallstruktur:
- {Region}/{SubjectMatter(s)}/In/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Out/{yyyy}/{mm}/{dd}/{hh}/
- {Region}/{SubjectMatter(s)}/Bad/{yyyy}/{mm}/{dd}/{hh}/
Ett marknadsföringsföretag tar till exempel emot dagliga dataextrakt av kunduppdateringar från sina klienter i Nordamerika. Det kan se ut som följande kodfragment före och efter bearbetningen:
- NA/Extracts/ACMEPaperCo/In/2017/08/14/updates_08142017.csv
- NA/Extracts/ACMEPaperCo/Out/2017/08/14/processed_updates_08142017.csv
I det vanliga fallet med batchdata som bearbetas direkt till databaser som Hive eller traditionella SQL-databaser, finns det inget behov av en /in - eller /out-katalog eftersom utdata redan hamnar i en separat mapp för Hive-tabellen eller den externa databasen. Till exempel skulle dagliga extrakt från kunder landa i deras respektive kataloger. Sedan skulle en tjänst som Azure Data Factory, Apache Oozie eller Apache Airflow utlösa ett dagligt Hive- eller Spark-jobb för att bearbeta och skriva data till en Hive-tabell.
Datastruktur för tidsserier
För Hive-arbetsbelastningar kan partitionsrensning av tidsseriedata hjälpa vissa frågor att bara läsa en delmängd av data, vilket förbättrar prestandan.
De pipelines som matar in tidsseriedata placerar ofta sina filer med strukturerad namngivning för filer och mappar. Nedan visas ett vanligt exempel på data som är strukturerade efter datum:
/DataSet/ÅÅÅÅ/MM/DD/datafile_YYYY_MM_DD.tsv
Observera att datetime-informationen visas både som mappar och i filnamnet.
För datum och tid är följande ett vanligt mönster
/DataSet/YYYY/MM/DD/HH/mm/datafile_YYYY_MM_DD_HH_mm.tsv
Återigen bör valet du gör med mappen och filorganisationen optimeras för de större filstorlekarna och ett rimligt antal filer i varje mapp.
Konfigurera säkerhet
Börja med att granska rekommendationerna i artikeln Säkerhetsrekommendationer för Blob Storage . Du hittar bästa praxis för att skydda dina data från oavsiktlig eller skadlig borttagning, skydda data bakom en brandvägg och använda Microsoft Entra-ID som grund för identitetshantering.
Läs sedan artikeln Åtkomstkontrollmodell i Azure Data Lake Storage för vägledning som är specifik för Data Lake Storage-aktiverade konton. Den här artikeln hjälper dig att förstå hur du använder rollbaserade Azure-åtkomstkontrollroller (Azure RBAC) tillsammans med åtkomstkontrollistor (ACL: er) för att framtvinga säkerhetsbehörigheter för kataloger och filer i ditt hierarkiska filsystem.
Mata in, bearbeta och analysera
Det finns många olika datakällor och olika sätt på vilka dessa data kan matas in i ett Data Lake Storage-aktiverat konto.
Du kan till exempel mata in stora uppsättningar data från HDInsight- och Hadoop-kluster eller mindre uppsättningar ad hoc-data för prototypprogram. Du kan mata in strömmade data som genereras av olika källor, till exempel program, enheter och sensorer. För den här typen av data kan du använda verktyg för att samla in och bearbeta data händelse för händelse i realtid och sedan skriva händelserna i batchar till ditt konto. Du kan också mata in webbserverloggar som innehåller information, till exempel historiken för sidbegäranden. För loggdata bör du överväga att skriva anpassade skript eller program för att ladda upp dem så att du har flexibiliteten att inkludera din datauppladdningskomponent som en del av ditt större stordataprogram.
När data är tillgängliga i ditt konto kan du köra analys på dessa data, skapa visualiseringar och till och med ladda ned data till din lokala dator eller till andra lagringsplatser, till exempel en Azure SQL-databas eller SQL Server-instans.
I följande tabell rekommenderas verktyg som du kan använda för att mata in, analysera, visualisera och ladda ned data. Använd länkarna i den här tabellen för att hitta vägledning om hur du konfigurerar och använder varje verktyg.
| Syfte | Vägledning för verktyg och verktyg |
|---|---|
| Mata in ad hoc-data | Azure Portal, Azure PowerShell, Azure CLI, REST, Azure Storage Explorer, Apache DistCp, AzCopy |
| Mata in relationsdata | Azure Data Factory |
| Mata in webbserverloggar | Azure PowerShell, Azure CLI, REST, Azure SDK:er (.NET, Java, Python och Node.js), Azure Data Factory |
| Mata in från HDInsight-kluster | Azure Data Factory, Apache DistCp, AzCopy |
| Mata in från Hadoop-kluster | Azure Data Factory, Apache DistCp, WANdisco LiveData Migrator för Azure, Azure Data Box |
| Mata in stora datamängder (flera terabyte) | Azure ExpressRoute |
| Bearbeta och analysera data | Azure Synapse Analytics, Azure HDInsight, Databricks |
| Visualisera data | Power BI, Azure Data Lake Storage-frågeacceleration |
| Nedladdning av data | Azure Portal, PowerShell, Azure CLI, REST, Azure SDK:er (.NET, Java, Python och Node.js), Azure Storage Explorer, AzCopy, Azure Data Factory, Apache DistCp |
Kommentar
Den här tabellen återspeglar inte den fullständiga listan över Azure-tjänster som stöder Data Lake Storage. En lista över Azure-tjänster som stöds finns i Azure-tjänster som stöder Azure Data Lake Storage.
Övervaka telemetri
Övervakning av användning och prestanda är en viktig del av driftsättningen av tjänsten. Exempel är frekventa åtgärder, åtgärder med hög svarstid eller åtgärder som orsakar begränsning på tjänstsidan.
All telemetri för ditt lagringskonto är tillgänglig via Azure Storage-loggar i Azure Monitor. Den här funktionen integrerar ditt lagringskonto med Log Analytics och Event Hubs, samtidigt som du kan arkivera loggar till ett annat lagringskonto. En fullständig lista över mått och resursloggar och deras associerade schema finns i Referens för Azure Storage-övervakningsdata.
Var du väljer att lagra loggarna beror på hur du planerar att komma åt dem. Om du till exempel vill komma åt loggarna i nära realtid och kunna korrelera händelser i loggar med andra mått från Azure Monitor kan du lagra loggarna på en Log Analytics-arbetsyta. Kör sedan frågor mot loggarna med hjälp av KQL- och redigeringsfrågor, som räknar StorageBlobLogs upp tabellen på din arbetsyta.
Om du vill lagra loggarna för både frågor i nära realtid och långsiktig kvarhållning kan du konfigurera diagnostikinställningarna för att skicka loggar till både en Log Analytics-arbetsyta och ett lagringskonto.
Om du vill komma åt loggarna via en annan frågemotor, till exempel Splunk, kan du konfigurera diagnostikinställningarna för att skicka loggar till en händelsehubb och mata in loggar från händelsehubben till ditt valda mål.
Azure Storage-loggar i Azure Monitor kan aktiveras via mallarna Azure Portal, PowerShell, Azure CLI och Azure Resource Manager. För distributioner i stor skala kan Azure Policy användas med fullständigt stöd för reparationsåtgärder. Mer information finns i chiffertxt/AzureStoragePolicy.