Självstudie: Träna en modell i Azure Machine Learning
GÄLLER FÖR: Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
Lär dig hur en dataexpert använder Azure Machine Learning för att träna en modell. I det här exemplet använder du en kreditkortsdatauppsättning för att förstå hur du använder Azure Machine Learning för ett klassificeringsproblem. Målet är att förutsäga om en kund har hög sannolikhet att försumma en kreditkortsbetalning. Träningsskriptet hanterar förberedelse av data. Skriptet tränar och registrerar sedan en modell.
Den här självstudien tar dig igenom steg för att skicka ett molnbaserat utbildningsjobb (kommandojobb).
- Få ett handtag till din Azure Machine Learning-arbetsyta
- Skapa din beräkningsresurs och jobbmiljö
- Skapa ditt träningsskript
- Skapa och kör kommandojobbet för att köra träningsskriptet på beräkningsresursen
- Visa utdata från träningsskriptet
- Distribuera den nyligen tränade modellen som en slutpunkt
- Anropa Azure Machine Learning-slutpunkten för slutsatsdragning
Om du vill veta mer om hur du läser in dina data i Azure kan du läsa Självstudie: Ladda upp, komma åt och utforska dina data i Azure Machine Learning.
Den här videon visar hur du kommer igång i Azure Machine Learning-studio så att du kan följa stegen i självstudien. Videon visar hur du skapar en notebook-fil, skapar en beräkningsinstans och klonar notebook-filen. Stegen beskrivs också i följande avsnitt.
Förutsättningar
-
Om du vill använda Azure Machine Learning behöver du en arbetsyta. Om du inte har någon slutför du Skapa resurser som du behöver för att komma igång med att skapa en arbetsyta och lära dig mer om hur du använder den.
Viktigt!
Om din Azure Machine Learning-arbetsyta har konfigurerats med ett hanterat virtuellt nätverk kan du behöva lägga till regler för utgående trafik för att tillåta åtkomst till de offentliga Python-paketlagringsplatserna. Mer information finns i Scenario: Åtkomst till offentliga maskininlärningspaket.
-
Logga in i studion och välj din arbetsyta om den inte redan är öppen.
-
Öppna eller skapa en notebook-fil på din arbetsyta:
- Om du vill kopiera och klistra in kod i celler skapar du en ny notebook-fil.
- Eller öppna självstudier/komma igång-notebooks/train-model.ipynb från avsnittet Exempel i studio. Välj sedan Klona för att lägga till anteckningsboken i dina filer. Information om hur du hittar exempelanteckningsböcker finns i Learn from sample notebooks (Lär dig från exempelanteckningsböcker).
Ange kerneln och öppna i Visual Studio Code (VS Code)
I det övre fältet ovanför den öppnade notebook-filen skapar du en beräkningsinstans om du inte redan har en.

Om beräkningsinstansen har stoppats väljer du Starta beräkning och väntar tills den körs.

Vänta tills beräkningsinstansen körs. Kontrollera sedan att kerneln, som finns längst upp till höger, är
Python 3.10 - SDK v2. Annars använder du listrutan för att välja den här kerneln.
Om du inte ser den här kerneln kontrollerar du att beräkningsinstansen körs. I så fall väljer du knappen Uppdatera längst upp till höger i anteckningsboken.
Om du ser en banderoll som säger att du måste autentiseras väljer du Autentisera.
Du kan köra notebook-filen här eller öppna den i VS Code för en fullständig integrerad utvecklingsmiljö (IDE) med kraften i Azure Machine Learning-resurser. Välj Öppna i VS Code och välj sedan antingen webb- eller skrivbordsalternativet. När du startar på det här sättet kopplas VS Code till beräkningsinstansen, kerneln och arbetsytans filsystem.




Viktigt!
Resten av den här självstudien innehåller celler i notebook-filen för självstudien. Kopiera och klistra in dem i den nya anteckningsboken eller växla till anteckningsboken nu om du klonade den.
Använda ett kommandojobb för att träna en modell i Azure Machine Learning
Om du vill träna en modell måste du skicka ett jobb. Azure Machine Learning erbjuder flera olika typer av jobb för att träna modeller. Användare kan välja sin träningsmetod baserat på komplexiteten i modellen, datastorleken och kraven på träningshastighet. I den här självstudien får du lära dig hur du skickar ett kommandojobb för att köra ett träningsskript.
Ett kommandojobb är en funktion som gör att du kan skicka ett anpassat träningsskript för att träna din modell. Det här jobbet kan också definieras som ett anpassat träningsjobb. Ett kommandojobb i Azure Machine Learning är en typ av jobb som kör ett skript eller kommando i en angiven miljö. Du kan använda kommandojobb för att träna modeller, bearbeta data eller annan anpassad kod som du vill köra i molnet.
Den här självstudien fokuserar på att använda ett kommandojobb för att skapa ett anpassat träningsjobb som du använder för att träna en modell. Alla anpassade träningsjobb kräver följande:
- -miljö
- data
- kommandojobb
- träningsskript
Den här självstudien innehåller följande exempel: skapa en klassificerare för att förutsäga kunder som har hög sannolikhet att försumma kreditkortsbetalningar.
Skapa handtag till arbetsyta
Innan du går in i koden behöver du ett sätt att referera till din arbetsyta. Skapa ml_client för en referens till arbetsytan. Använd ml_client sedan för att hantera resurser och jobb.
I nästa cell anger du ditt prenumerations-ID, resursgruppsnamn och arbetsytenamn. Så här hittar du följande värden:
- I det övre högra Azure Machine Learning-studio verktygsfältet väljer du namnet på arbetsytan.
- Kopiera värdet för arbetsyta, resursgrupp och prenumerations-ID till koden. Du måste kopiera ett värde, stänga området och klistra in och sedan komma tillbaka för nästa.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Kommentar
Att skapa MLClient ansluter inte till arbetsytan. Klientinitiering är lat. Den väntar för första gången den behöver göra ett anrop, vilket händer i nästa kodcell.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Skapa en jobbmiljö
Om du vill köra ditt Azure Machine Learning-jobb på din beräkningsresurs behöver du en miljö. En miljö visar en lista över de programkörningar och bibliotek som du vill ha installerade på den beräkning där träningen sker. Det liknar Python-miljön på din lokala dator. Mer information finns i Vad är Azure Machine Learning-miljöer?
Azure Machine Learning tillhandahåller många utvalda eller färdiga miljöer som är användbara för vanliga tränings- och slutsatsdragningsscenarier.
I det här exemplet skapar du en anpassad conda-miljö för dina jobb med hjälp av en conda yaml-fil.
Skapa först en katalog som filen ska lagras i.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Nästa cell använder IPython-magi för att skriva conda-filen till den katalog som du skapade.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=1.0.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- mlflow==2.8.0
- mlflow-skinny==2.8.0
- azureml-mlflow==1.51.0
- psutil>=5.8,<5.9
- tqdm>=4.59,<4.60
- ipykernel~=6.0
- matplotlib
Specifikationen innehåller några vanliga paket som du använder i ditt jobb, till exempel numpy och pip.
Referera till den här yaml-filen för att skapa och registrera den här anpassade miljön på din arbetsyta:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
custom_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults job",
tags={"scikit-learn": "1.0.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
)
custom_job_env = ml_client.environments.create_or_update(custom_job_env)
print(
f"Environment with name {custom_job_env.name} is registered to workspace, the environment version is {custom_job_env.version}"
)
Konfigurera ett träningsjobb med hjälp av kommandofunktionen
Du skapar ett Azure Machine Learning-kommandojobb för att träna en modell för kreditstandardförutsägelse. Kommandojobbet kör ett träningsskript i en angiven miljö på en angiven beräkningsresurs. Du har redan skapat miljön och beräkningsklustret. Skapa sedan träningsskriptet. I det här fallet tränar du datamängden för att skapa en klassificerare med hjälp av GradientBoostingClassifier modellen.
Träningsskriptet hanterar förberedelse, träning och registrering av den tränade modellen. Metoden train_test_split delar upp datamängden i test- och träningsdata. I den här självstudien skapar du ett Python-träningsskript.
Kommandojobb kan köras från CLI, Python SDK eller studiogränssnittet. I den här självstudien använder du Azure Machine Learning Python SDK v2 för att skapa och köra kommandojobbet.
Skapa träningsskript
Börja med att skapa träningsskriptet: main.py Python-fil. Skapa först en källmapp för skriptet:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Det här skriptet förbearbetar data och delar upp dem i test- och träningsdata. Sedan används data för att träna en trädbaserad modell och returnera utdatamodellen.
MLFlow används för att logga parametrarna och måtten under det här jobbet. Med MLFlow-paketet kan du spåra mått och resultat för varje modell som Azure tränar. Använd MLFlow för att få den bästa modellen för dina data. Visa sedan modellens mått i Azure Studio. Mer information finns i MLflow och Azure Machine Learning.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
#Split train and test datasets
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
När modellen har tränats i det här skriptet sparas och registreras modellfilen på arbetsytan. Genom att registrera din modell kan du lagra och versionshantera dina modeller i Azure-molnet på din arbetsyta. När du har registrerat en modell kan du hitta alla andra registrerade modeller på ett ställe i Azure Studio som kallas modellregistret. Modellregistret hjälper dig att organisera och hålla reda på dina tränade modeller.
Konfigurera kommandot
Nu när du har ett skript som kan utföra klassificeringsuppgiften använder du kommandot generell användning som kan köra kommandoradsåtgärder. Den här kommandoradsåtgärden kan anropa systemkommandon direkt eller genom att köra ett skript.
Skapa indatavariabler för att ange indata, delningsförhållande, inlärningshastighet och registrerat modellnamn. Kommandoskriptet:
- Använder miljön som skapades tidigare. Använd notationen
@latestför att ange den senaste versionen av miljön när kommandot körs. - Konfigurerar själva kommandoradsåtgärden,
python main.pyi det här fallet. Du kan komma åt indata och utdata i kommandot med hjälp${{ ... }}av notation. - Eftersom en beräkningsresurs inte har angetts körs skriptet på ett serverlöst beräkningskluster som skapas automatiskt.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="aml-scikit-learn@latest",
display_name="credit_default_prediction",
)
Skicka jobbet
Skicka jobbet som ska köras i Azure Machine Learning-studio. Använd den här gången create_or_update på ml_client.
ml_client är en klientklass som gör att du kan ansluta till din Azure-prenumeration med Hjälp av Python och interagera med Azure Machine Learning-tjänster.
ml_client gör att du kan skicka dina jobb med Hjälp av Python.
ml_client.create_or_update(job)
Visa jobbutdata och vänta tills jobbet har slutförts
Om du vill visa jobbet i Azure Machine Learning-studio väljer du länken i utdata från föregående cell. Utdata för det här jobbet ser ut så här i Azure Machine Learning-studio. Utforska flikarna för olika detaljer som mått, utdata osv. När jobbet har slutförts registreras en modell på din arbetsyta som ett resultat av träningen.
Viktigt!
Vänta tills jobbets status är klar innan du återgår till den här notebook-filen för att fortsätta. Jobbet tar 2 till 3 minuter att köra. Det kan ta längre tid, upp till 10 minuter, om beräkningsklustret har skalats ned till noll noder och den anpassade miljön fortfarande skapas.
När du kör cellen visar notebook-utdata en länk till jobbets informationssida i Machine Learning Studio. Du kan också välja Jobb på den vänstra navigeringsmenyn.
Ett jobb är en gruppering av många körningar från ett angivet skript eller kodavsnitt. Information för körningen lagras under det jobbet. Informationssidan ger en översikt över jobbet, den tid det tog att köra, när det skapades och annan information. Sidan har också flikar till annan information om jobbet, till exempel mått, utdata + loggar och kod. Här är flikarna som är tillgängliga på jobbets informationssida:
- Översikt: Grundläggande information om jobbet, inklusive dess status, start- och sluttider och vilken typ av jobb som kördes
- Indata: Data och kod som användes som indata för jobbet. Det här avsnittet kan innehålla datauppsättningar, skript, miljökonfigurationer och andra resurser som användes under träningen.
- Utdata + loggar: Loggar som genererades när jobbet kördes. Den här fliken hjälper dig att felsöka om något går fel med ditt träningsskript eller modellskapande.
- Mått: Viktiga prestandamått från din modell, till exempel träningspoäng, f1-poäng och precisionspoäng.
Rensa resurser
Om du planerar att fortsätta nu till andra självstudier går du vidare till Relaterat innehåll.
Stoppa beräkningsinstans
Om du inte ska använda den nu stoppar du beräkningsinstansen:
- Välj Beräkning i det vänstra navigeringsområdet i studion.
- På de översta flikarna väljer du Beräkningsinstanser.
- Välj beräkningsinstansen i listan.
- I det övre verktygsfältet väljer du Stoppa.
Ta bort alla resurser
Viktigt!
De resurser som du har skapat kan användas som förutsättningar för andra Azure Machine Learning-självstudier och instruktionsartiklar.
Om du inte planerar att använda någon av de resurser som du har skapat tar du bort dem så att du inte debiteras några avgifter:
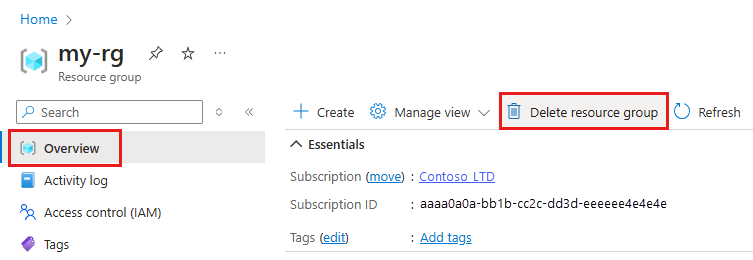
I Azure Portal i sökrutan anger du Resursgrupper och väljer dem i resultatet.
I listan väljer du den resursgrupp som du skapade.
På sidan Översikt väljer du Ta bort resursgrupp.
Ange resursgruppsnamnet. Välj sedan ta bort.
Relaterat innehåll
Lär dig mer om att distribuera en modell:
I den här självstudien användes en onlinedatafil. Mer information om andra sätt att komma åt data finns i Självstudie: Ladda upp, komma åt och utforska dina data i Azure Machine Learning.
Automatiserad ML är ett kompletterande verktyg för att minska den tid en dataexpert lägger ner på att hitta en modell som fungerar bäst med deras data. Mer information finns i Vad är automatiserad maskininlärning.
Om du vill ha fler exempel som liknar den här självstudien kan du läsa Learn from sample notebooks (Lär dig från exempelanteckningsböcker). De här exemplen finns på sidan Med GitHub-exempel. Exemplen omfattar fullständiga Python Notebooks som du kan köra kod och lära dig att träna en modell. Du kan ändra och köra befintliga skript från exemplen, som innehåller scenarier som klassificering, bearbetning av naturligt språk och avvikelseidentifiering.