Självstudie: Ladda upp, komma åt och utforska dina data i Azure Machine Learning
GÄLLER FÖR: Python SDK azure-ai-ml v2 (aktuell)
Python SDK azure-ai-ml v2 (aktuell)
I den här självstudiekursen får du lära du dig att:
- Ladda upp dina data till molnlagring
- Skapa en Azure Machine Learning-datatillgång
- Få åtkomst till dina data i en notebook-fil för interaktiv utveckling
- Skapa nya versioner av datatillgångar
Ett maskininlärningsprojekt börjar vanligtvis med undersökande dataanalys (EDA), förbearbetning av data (rengöring, funktionsutveckling) och skapandet av prototyper för Machine Learning-modell för att validera hypoteser. Den här prototypprojektfasen är mycket interaktiv. Den lämpar sig för utveckling i en IDE eller en Jupyter Notebook med en interaktiv Python-konsol. I den här självstudien beskrivs dessa idéer.
Den här videon visar hur du kommer igång i Azure Machine Learning-studio, så att du kan följa stegen i självstudien. Videon visar hur du skapar en notebook-fil, klonar anteckningsboken, skapar en beräkningsinstans och laddar ned de data som behövs för självstudien. Stegen beskrivs också i följande avsnitt.
Förutsättningar
-
Om du vill använda Azure Machine Learning behöver du en arbetsyta. Om du inte har någon slutför du Skapa resurser som du behöver för att komma igång med att skapa en arbetsyta och lära dig mer om hur du använder den.
Viktigt!
Om din Azure Machine Learning-arbetsyta har konfigurerats med ett hanterat virtuellt nätverk kan du behöva lägga till regler för utgående trafik för att tillåta åtkomst till de offentliga Python-paketlagringsplatserna. Mer information finns i Scenario: Åtkomst till offentliga maskininlärningspaket.
-
Logga in i studion och välj din arbetsyta om den inte redan är öppen.
-
Öppna eller skapa en notebook-fil på din arbetsyta:
- Om du vill kopiera och klistra in kod i celler skapar du en ny notebook-fil.
- Eller öppna självstudier/komma igång-notebooks/explore-data.ipynb från avsnittet Exempel i studio. Välj sedan Klona för att lägga till anteckningsboken i dina filer. Information om hur du hittar exempelanteckningsböcker finns i Learn from sample notebooks (Lär dig från exempelanteckningsböcker).
Ange kerneln och öppna i Visual Studio Code (VS Code)
I det övre fältet ovanför den öppnade notebook-filen skapar du en beräkningsinstans om du inte redan har en.

Om beräkningsinstansen har stoppats väljer du Starta beräkning och väntar tills den körs.

Vänta tills beräkningsinstansen körs. Kontrollera sedan att kerneln, som finns längst upp till höger, är
Python 3.10 - SDK v2. Annars använder du listrutan för att välja den här kerneln.
Om du inte ser den här kerneln kontrollerar du att beräkningsinstansen körs. I så fall väljer du knappen Uppdatera längst upp till höger i anteckningsboken.
Om du ser en banderoll som säger att du måste autentiseras väljer du Autentisera.
Du kan köra notebook-filen här eller öppna den i VS Code för en fullständig integrerad utvecklingsmiljö (IDE) med kraften i Azure Machine Learning-resurser. Välj Öppna i VS Code och välj sedan antingen webb- eller skrivbordsalternativet. När du startar på det här sättet kopplas VS Code till beräkningsinstansen, kerneln och arbetsytans filsystem.
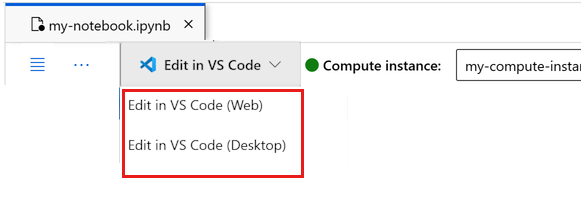




Viktigt!
Resten av den här självstudien innehåller celler i notebook-filen för självstudien. Kopiera och klistra in dem i den nya anteckningsboken eller växla till anteckningsboken nu om du klonade den.
Ladda ned data som används i den här självstudien
För datainmatning hanterar Azure Data Explorer rådata i dessa format. I den här självstudien används det här CSV-formatet för kreditkortsklientdataexempel. Stegen fortsätter i en Azure Machine Learning-resurs. I den resursen skapar vi en lokal mapp, med det föreslagna namnet på data, direkt under mappen där den här notebook-filen finns.
Kommentar
Den här självstudien beror på data som placeras på en plats för en Azure Machine Learning-resursmapp. I den här självstudien innebär "lokal" en mappplats i den Azure Machine Learning-resursen.
Välj Öppna terminalen under de tre punkterna, som du ser i den här bilden:
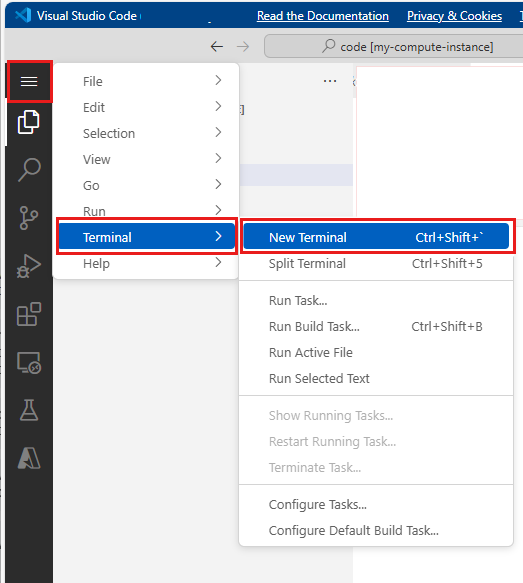
Terminalfönstret öppnas på en ny flik.
Kontrollera att du
cd(Ändra katalog) till samma mapp där anteckningsboken finns. Om notebook-filen till exempel finns i en mapp med namnet get-started-notebooks:cd get-started-notebooks # modify this to the path where your notebook is locatedAnge dessa kommandon i terminalfönstret för att kopiera data till din beräkningsinstans:
mkdir data cd data # the sub-folder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvNu kan du stänga terminalfönstret.
Mer information om data i UC Irvine Machine Learning-lagringsplatsen finns i den här resursen.
Skapa ett handtag till arbetsytan
Innan vi utforskar koden behöver du ett sätt att referera till din arbetsyta. Du skapar ml_client för en referens till arbetsytan. Du använder ml_client sedan för att hantera resurser och jobb.
I nästa cell anger du ditt prenumerations-ID, resursgruppsnamn och arbetsytenamn. Så här hittar du följande värden:
- I det övre högra Azure Machine Learning-studio verktygsfältet väljer du namnet på arbetsytan.
- Kopiera värdet för arbetsyta, resursgrupp och prenumerations-ID till koden.
- Du måste kopiera värdena individuellt en i taget, stänga området och klistra in och sedan fortsätta till nästa.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Kommentar
Skapande av MLClient ansluter inte till arbetsytan. Klientinitiering är lat. Den väntar för första gången den behöver göra ett anrop. Detta inträffar I nästa kodcell.
Ladda upp data till molnlagring
Azure Machine Learning använder URI:er (Uniform Resource Identifiers), som pekar på lagringsplatser i molnet. En URI gör det enkelt att komma åt data i notebook-filer och jobb. Data-URI-format har ett format som liknar de webb-URL:er som du använder i webbläsaren för att få åtkomst till webbsidor. Till exempel:
- Få åtkomst till data från en offentlig https-server:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Få åtkomst till data från Azure Data Lake Gen 2:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
En Azure Machine Learning-datatillgång liknar webbläsarbokmärken (favoriter). I stället för att komma ihåg långa lagringssökvägar (URI:er) som pekar på dina mest använda data kan du skapa en datatillgång och sedan komma åt tillgången med ett eget namn.
Skapande av datatillgång skapar också en referens till datakällans plats, tillsammans med en kopia av dess metadata. Eftersom data finns kvar på den befintliga platsen medför du ingen extra lagringskostnad och du riskerar inte datakällans integritet. Du kan skapa datatillgångar från Azure Machine Learning-datalager, Azure Storage, offentliga URL:er och lokala filer.
Dricks
För datauppladdningar med mindre storlek fungerar skapande av Azure Machine Learning-datatillgångar bra för datauppladdningar från lokala datorresurser till molnlagring. Den här metoden undviker behovet av extra verktyg eller verktyg. En större datauppladdning kan dock kräva ett dedikerat verktyg eller verktyg, till exempel azcopy. Kommandoradsverktyget azcopy flyttar data till och från Azure Storage. Mer information om azcopy finns i den här resursen.
Nästa notebook-cell skapar datatillgången. Kodexemplet laddar upp rådatafilen till den avsedda molnlagringsresursen.
Varje gång du skapar en datatillgång behöver du en unik version för den. Om versionen redan finns får du ett fel. I den här koden använder vi "initial" för den första läsningen av data. Om den versionen redan finns återskapar vi den inte.
Du kan också utelämna versionsparametern. I det här fallet genereras ett versionsnummer åt dig, från och med 1 och sedan ökar därifrån.
I den här självstudien används namnet "initial" som den första versionen. Självstudien Skapa maskininlärningspipelines för produktion använder också den här versionen av data, så här använder vi ett värde som du ser igen i den självstudien.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Om du vill undersöka de uppladdade data väljer du Data till vänster. Data laddas upp och en datatillgång skapas:
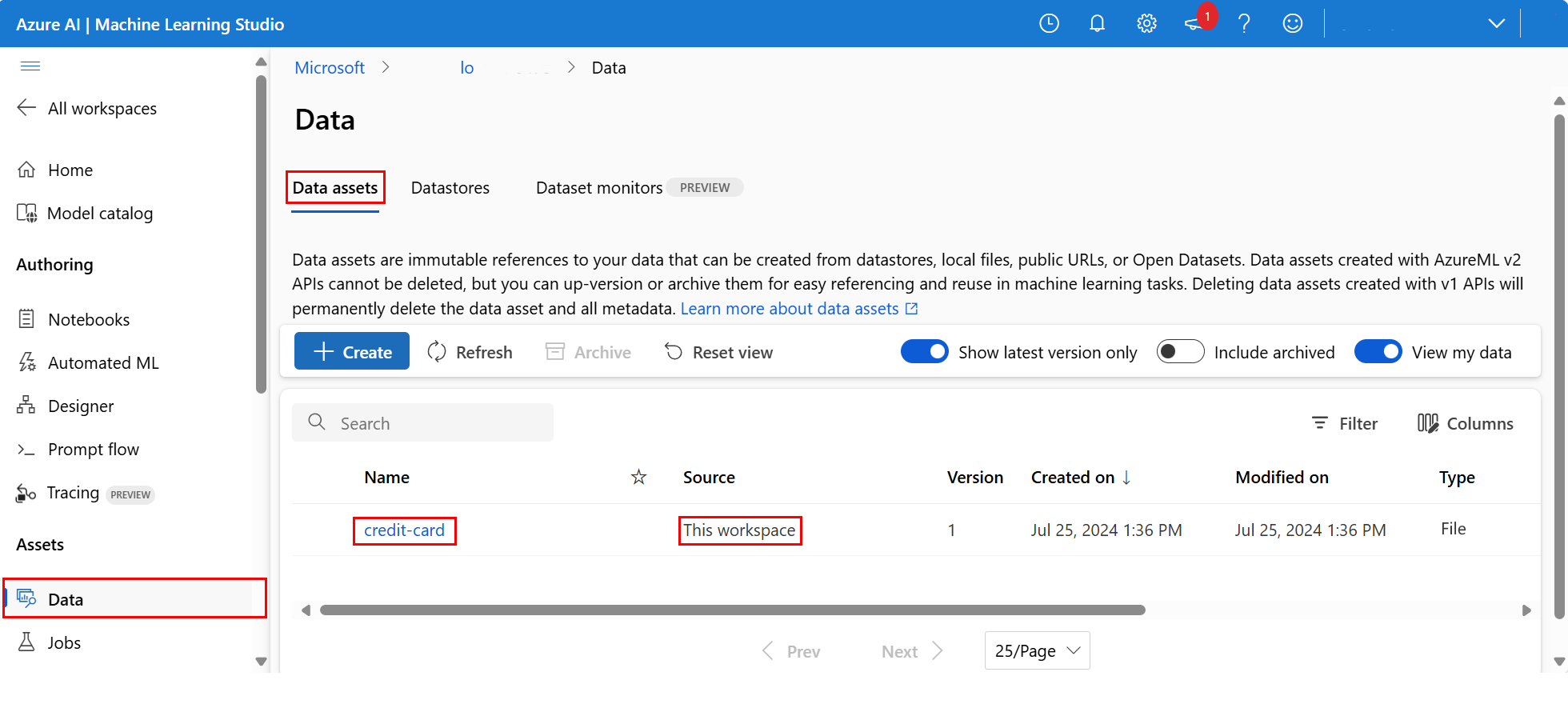
Dessa data heter kreditkort och på fliken Datatillgångar kan vi se dem i kolumnen Namn.
Ett Azure Machine Learning-datalager är en referens till ett befintligt lagringskonto i Azure. Ett datalager erbjuder följande fördelar:
Ett vanligt och lätthanterad API för att interagera med olika lagringstyper
- Azure Data Lake Storage
- Blob
- Filer
och autentiseringsmetoder.
Ett enklare sätt att identifiera användbara datalager när du arbetar som ett team.
I skripten kan du dölja anslutningsinformation för autentiseringsbaserad dataåtkomst (tjänstens huvudnamn/SAS/nyckel).
Få åtkomst till dina data i en notebook-fil
Pandas har direkt stöd för URI:er – det här exemplet visar hur du läser en CSV-fil från ett Azure Machine Learning-datalager:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Men som tidigare nämnts kan det bli svårt att komma ihåg dessa URI:er. Dessutom måste du manuellt ersätta alla <delsträngsvärden> i kommandot pd.read_csv med de verkliga värdena för dina resurser.
Du vill skapa datatillgångar för data som används ofta. Här är ett enklare sätt att komma åt CSV-filen i Pandas:
Viktigt!
I en notebook-cell kör du den här koden för att installera azureml-fsspec Python-biblioteket i Jupyter-kerneln:
%pip install -U azureml-fsspec
import pandas as pd
# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
Mer information om dataåtkomst i en notebook-fil finns i Åtkomst till data från Azure Cloud Storage under interaktiv utveckling.
Skapa en ny version av datatillgången
Data behöver viss ljusrengöring så att de passar för att träna en maskininlärningsmodell. Den har:
- två rubriker
- en klient-ID-kolumn. vi skulle inte använda den här funktionen i Machine Learning
- blanksteg i svarsvariabelns namn
Jämfört med CSV-formatet blir Parquet-filformatet också ett bättre sätt att lagra dessa data. Parquet erbjuder komprimering och underhåller schemat. Om du vill rensa data och lagra dem i Parquet använder du:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
Den här tabellen visar strukturen för data i den ursprungliga default_of_credit_card_clients.csv filen . CSV-fil som laddades ned i ett tidigare steg. De uppladdade data innehåller 23 förklarande variabler och en svarsvariabel, enligt följande:
| Kolumnnamn | Variabeltyp | beskrivning |
|---|---|---|
| X1 | Förklarande | Beloppet för den givna krediten (NT-dollar): den omfattar både den individuella konsumentkrediten och deras familjekredit (tilläggskredit). |
| X2 | Förklarande | Kön (1 = man, 2 = kvinna). |
| X3 | Förklarande | Utbildning (1 = forskarskola; 2 = universitet; 3 = gymnasiet; 4 = andra). |
| X4 | Förklarande | Civilstånd (1 = gift; 2 = singel; 3 = andra). |
| X5 | Förklarande | Ålder (år). |
| X6-X11 | Förklarande | Historik över tidigare betalning. Vi spårade de senaste månatliga betalningsposterna (från april till september 2005). -1 = betala vederbörligen; 1 = betalningsfördröjning för en månad; 2 = betalningsfördröjning i två månader; . . .; 8 = betalningsfördröjning i åtta månader. 9 = betalningsfördröjning i nio månader och senare. |
| X12-17 | Förklarande | Belopp för fakturautdrag (NT-dollar) från april till september 2005. |
| X18-23 | Förklarande | Belopp för tidigare betalning (NT-dollar) från april till september 2005. |
| Y | Response | Standardbetalning (Ja = 1, Nej = 0) |
Skapa sedan en ny version av datatillgången (data överförs automatiskt till molnlagring). För den här versionen lägger du till ett tidsvärde så att varje gång koden körs skapas ett annat versionsnummer.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Den rensade parquet-filen är den senaste versionens datakälla. Den här koden visar resultatuppsättningen för CSV-versionen först och sedan Parquet-versionen:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
Rensa resurser
Om du planerar att fortsätta nu till andra självstudier går du vidare till Nästa steg.
Stoppa beräkningsinstans
Om du inte planerar att använda den nu stoppar du beräkningsinstansen:
- Välj Beräkning i det vänstra navigeringsområdet i studion.
- På de översta flikarna väljer du Beräkningsinstanser
- Välj beräkningsinstansen i listan.
- I det övre verktygsfältet väljer du Stoppa.
Ta bort alla resurser
Viktigt!
De resurser som du har skapat kan användas som förutsättningar för andra Azure Machine Learning-självstudier och instruktionsartiklar.
Om du inte planerar att använda någon av de resurser som du har skapat tar du bort dem så att du inte debiteras några avgifter:
I Azure Portal i sökrutan anger du Resursgrupper och väljer dem i resultatet.
I listan väljer du den resursgrupp som du skapade.
På sidan Översikt väljer du Ta bort resursgrupp.
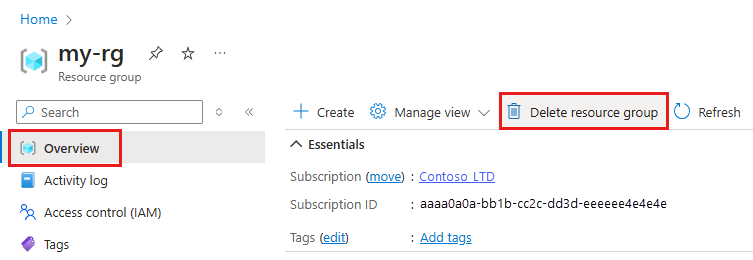
Ange resursgruppsnamnet. Välj sedan ta bort.
Nästa steg
Mer information om datatillgångar finns i Skapa datatillgångar.
Mer information om datalager finns i Skapa datalager.
Fortsätt med nästa självstudie för att lära dig hur du utvecklar ett träningsskript: