Utvärderingsflöden och mått
Utvärderingsflöden är en särskild typ av promptflöde som beräknar mått för att bedöma hur väl utdata från en körning uppfyller specifika kriterier och mål. Du kan skapa eller anpassa utvärderingsflöden och mått som är skräddarsydda för dina uppgifter och mål och använda dem för att utvärdera andra promptflöden. Den här artikeln beskriver utvärderingsflöden, hur du utvecklar och anpassar dem och hur du använder dem i batchkörningar för promptflöde för att utvärdera flödesprestanda.
Förstå utvärderingsflöden
Ett promptflöde är en sekvens med noder som bearbetar indata och genererar utdata. Utvärderingsflöden förbrukar också nödvändiga indata och producerar motsvarande utdata som vanligtvis är poäng eller mått. Utvärderingsflöden skiljer sig från standardflöden i deras redigeringsupplevelse och användning.
Utvärderingsflöden körs vanligtvis efter den körning som de testar genom att ta emot dess utdata och använda utdata för att beräkna poäng och mått. Loggmått för utvärderingsflöden med hjälp av funktionen SDK log_metric() för promptflöde.
Utdata från utvärderingsflödet är resultat som mäter prestanda för flödet som testas. Utvärderingsflöden kan ha en aggregeringsnod som beräknar den övergripande prestandan för flödet som testas över testdatauppsättningen.
I nästa avsnitt beskrivs hur du definierar indata och utdata i utvärderingsflöden.
Indata
Utvärderingsflöden beräknar mått eller poäng för batchkörningar genom att ta in utdata från den körning som de testar. Om flödet som testas till exempel är ett QnA-flöde som genererar ett svar baserat på en fråga kan du namnge en utvärderingsindata som answer. Om flödet som testas är ett klassificeringsflöde som klassificerar en text i en kategori kan du namnge en utvärderingsindata som category.
Du kan behöva andra indata som grund sanning. Om du till exempel vill beräkna noggrannheten för ett klassificeringsflöde måste du ange datamängdens category kolumn som grundsanning. Om du vill beräkna noggrannheten för ett QnA-flöde måste du ange datamängdens answer kolumn som grundsanning. Du kan behöva några andra indata för att beräkna mått, till exempel question och context i QnA- eller RAG-scenarier (augmented generation).
Du definierar indata för utvärderingsflödet på samma sätt som du definierar indata för ett standardflöde. Som standard använder utvärderingen samma datauppsättning som körningen som testas. Men om motsvarande etiketter eller målgrunds sanningsvärden finns i en annan datauppsättning kan du enkelt växla till den datauppsättningen.
Indatabeskrivningar
Om du vill beskriva de indata som behövs för att beräkna mått kan du lägga till beskrivningar. Beskrivningarna visas när du mappar indatakällorna i batchkörningsöverföringar.
Om du vill lägga till beskrivningar för varje indata väljer du Visa beskrivning i indataavsnittet när du utvecklar utvärderingsmetoden och anger sedan beskrivningarna.

Om du vill dölja beskrivningarna från indataformuläret väljer du Dölj beskrivning.

Utdata och mått
Utdata från en utvärdering är resultat som visar prestanda för flödet som testas. Utdata innehåller vanligtvis mått som poäng och kan även innehålla text för resonemang och förslag.
Utdatapoäng
En fråga flöden bearbetar en rad med data i taget och genererar en utdatapost. Utvärderingsflöden kan också beräkna poäng för varje datarad, så att du kan kontrollera hur ett flöde presterar på varje enskild datapunkt.
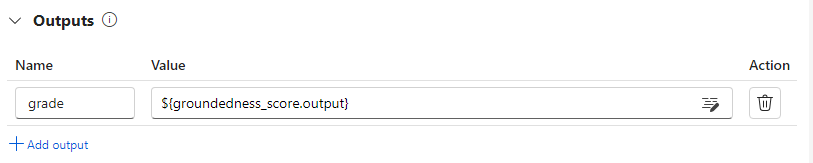
Du kan registrera poängen för varje datainstans som utvärderingsflödesutdata genom att ange dem i utdataavsnittet i utvärderingsflödet. Redigeringsupplevelsen är densamma som att definiera ett standardflödesutdata.
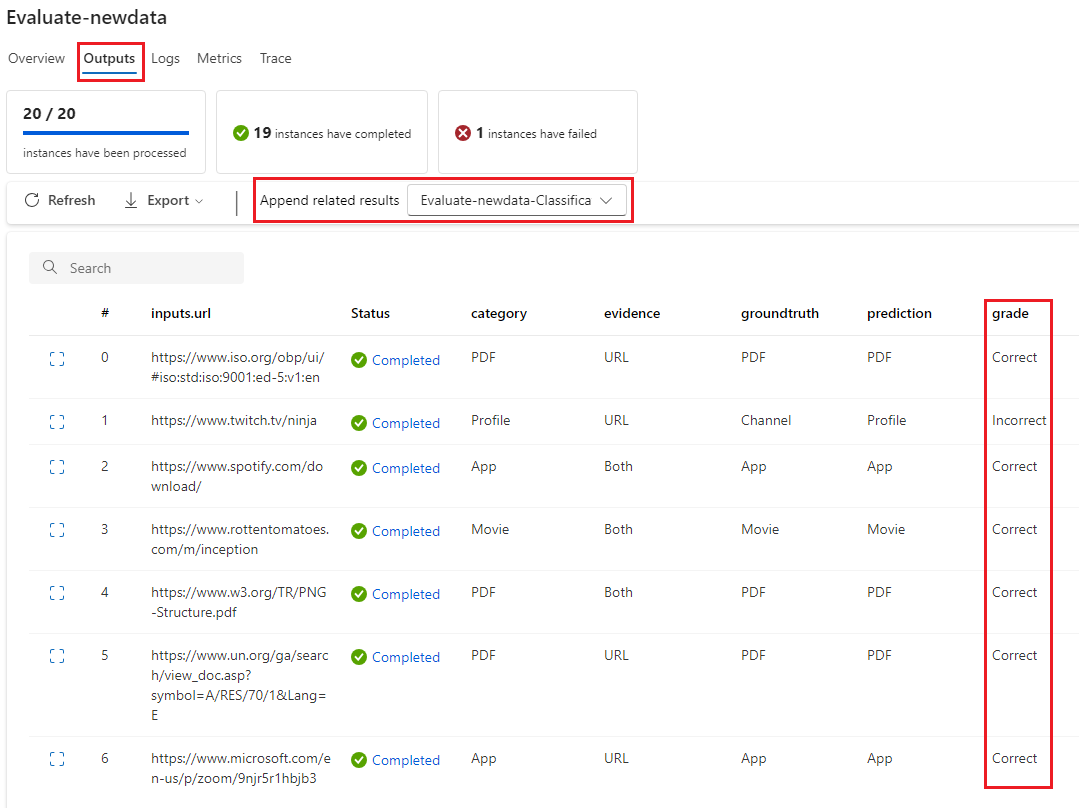
Du kan visa de enskilda poängen på fliken Utdata när du väljer Visa utdata, på samma sätt som du kontrollerar utdata från en standardflödesbatchkörning. Du kan lägga till dessa poäng på instansnivå i utdata från det flöde som du testade.
Aggregering och måttloggning
Utvärderingsflödet innehåller också en övergripande utvärdering för körningen. För att skilja de övergripande resultaten från enskilda utdatapoäng kallas dessa övergripande körningsprestandavärden för mått.
Om du vill beräkna ett övergripande utvärderingsvärde baserat på enskilda poäng markerar du kryssrutan Sammansättning på en Python-nod i ett utvärderingsflöde för att omvandla det till en reduce-nod . Noden tar sedan in indata som en lista och bearbetar dem som en batch.

Genom att använda aggregering kan du beräkna och bearbeta alla poäng för varje flödes utdata och beräkna ett övergripande resultat med hjälp av varje poäng. Om du till exempel vill beräkna noggrannheten för ett klassificeringsflöde kan du beräkna noggrannheten för varje poängutdata och sedan beräkna den genomsnittliga noggrannheten för alla poängutdata. Sedan kan du logga den genomsnittliga noggrannheten som ett mått med hjälp promptflow_sdk.log_metric()av . Mått måste vara numeriska, till exempel float eller int. Loggning av strängtypsmått stöds inte.
Följande kodfragment är ett exempel på beräkning av total noggrannhet genom att i genomsnitt beräkna noggrannhetspoängen grades för alla datapunkter. Den övergripande noggrannheten loggas som ett mått med hjälp promptflow_sdk.log_metric()av .
from typing import List
from promptflow import tool, log_metric
@tool
def calculate_accuracy(grades: List[str]): # Receive a list of grades from a previous node
# calculate accuracy
accuracy = round((grades.count("Correct") / len(grades)), 2)
log_metric("accuracy", accuracy)
return accuracy
Eftersom du anropar den här funktionen i Python-noden behöver du inte tilldela den någon annanstans och du kan visa måtten senare. När du har använt den här utvärderingsmetoden i en batchkörning kan du visa måttet som visar övergripande prestanda genom att välja fliken Mått när du visar utdata.

Utveckla ett utvärderingsflöde
Om du vill utveckla ett eget utvärderingsflöde väljer du Skapa på sidan Azure Machine Learning-studio Fråga efter flöde. På sidan Skapa ett nytt flöde kan du antingen:
Välj Skapa på kortet Utvärderingsflöde under Skapa efter typ. Det här valet innehåller en mall för att utveckla en ny utvärderingsmetod.
Välj Utvärderingsflöde i galleriet Utforska och välj från ett av de tillgängliga inbyggda flödena. Välj Visa information för att få en sammanfattning av varje flöde och välj Klona för att öppna och anpassa flödet. Guiden för att skapa flödet hjälper dig att ändra flödet för ditt eget scenario.

Beräkna poäng för varje datapunkt
Utvärderingsflöden beräknar poäng och mått för flöden som körs på datauppsättningar. Det första steget i utvärderingsflöden är att beräkna poäng för varje enskild datautdata.
I det inbyggda flödet grade för utvärdering av klassificeringsnoggrannhet beräknas till exempel den som mäter noggrannheten för varje flödesgenererade utdata till motsvarande grundsanning i python-noden.
Om du använder utvärderingsflödesmallen beräknar du den här poängen i line_process Python-noden. Du kan också ersätta line_process python-nod med en llm-nod (large language model) för att använda en LLM för att beräkna poängen eller använda flera noder för att utföra beräkningen.

Du anger utdata för den här noden som utdata från utvärderingsflödet, vilket indikerar att utdata är poängen som beräknas för varje dataexempel. Du kan också utdataskäl för mer information, och det är samma upplevelse som att definiera utdata i ett standardflöde.
Beräkna och logga mått
Nästa steg i utvärderingen är att beräkna övergripande mått för att utvärdera körningen. Du beräknar mått i en Python-nod som har alternativet Sammansättning valt. Den här noden tar in poängen från den tidigare beräkningsnoden och organiserar dem i en lista och beräknar sedan övergripande värden.
Om du använder utvärderingsmallen beräknas den här poängen i den aggregerade noden. Följande kodfragment visar mallen för aggregeringsnoden.
from typing import List
from promptflow import tool
@tool
def aggregate(processed_results: List[str]):
"""
This tool aggregates the processed result of all lines and log metric.
:param processed_results: List of the output of line_process node.
"""
# Add your aggregation logic here
aggregated_results = {}
# Log metric
# from promptflow import log_metric
# log_metric(key="<my-metric-name>", value=aggregated_results["<my-metric-name>"])
return aggregated_results
Du kan använda din egen aggregeringslogik, till exempel beräkning av poäng medelvärde, median eller standardavvikelse.
Logga måtten med hjälp promptflow.log_metric() av funktionen . Du kan logga flera mått i ett enda utvärderingsflöde. Mått måste vara numeriska (float/int).
Använda utvärderingsflöden
När du har skapat ett eget utvärderingsflöde och mått kan du använda flödet för att utvärdera prestanda för ett standardflöde. Du kan till exempel utvärdera ett QnA-flöde för att testa hur det fungerar på en stor datauppsättning.
I Azure Machine Learning-studio öppnar du det flöde som du vill utvärdera och väljer Utvärdera i den översta menyraden.

I guiden Kör och utvärdera i Batch slutför du inställningarna Grundläggande inställningar och Batch-körning för att läsa in datauppsättningen för testning och konfigurera indatamappningen. Mer information finns i Skicka batchkörning och utvärdera ett flöde.
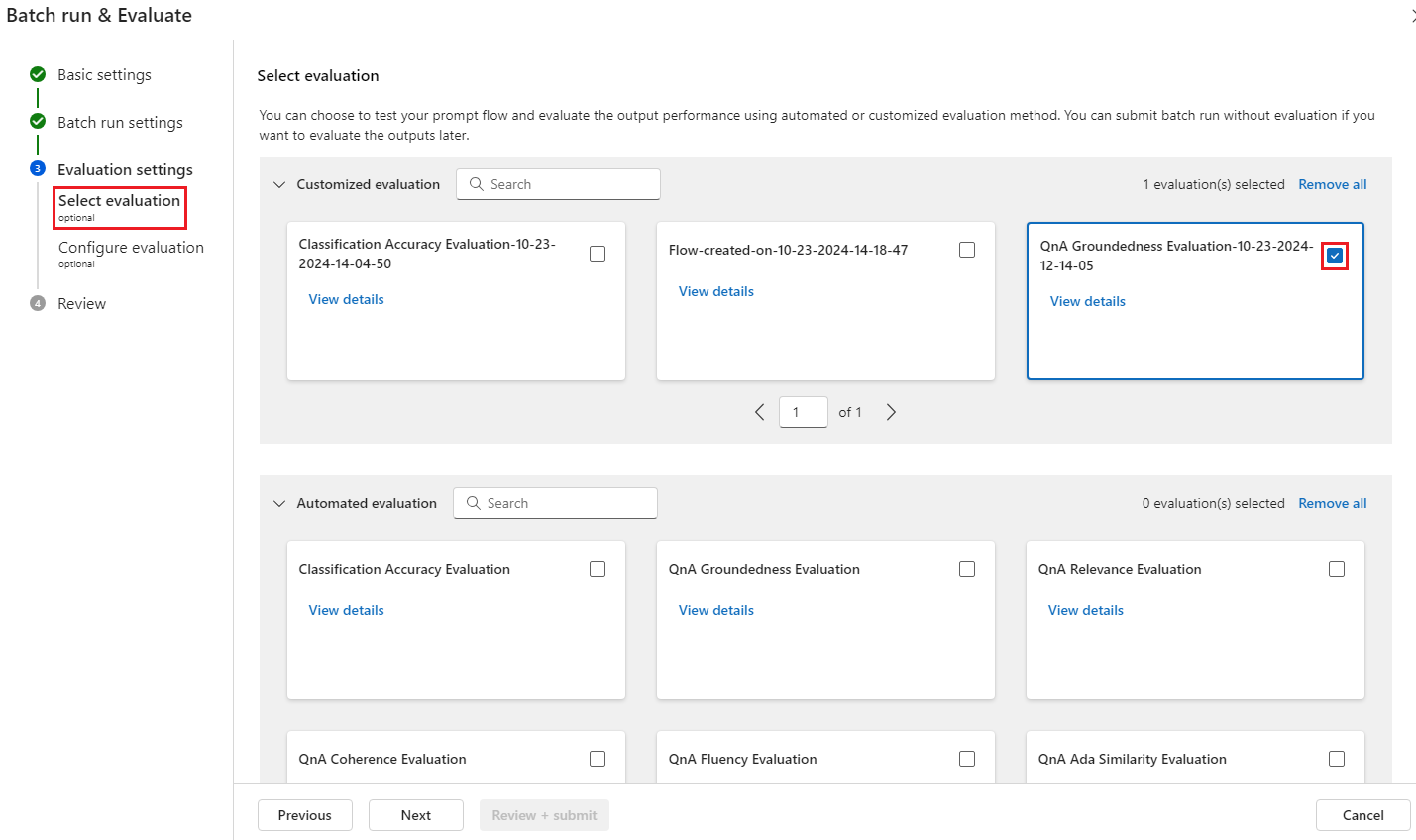
I steget Välj utvärdering kan du välja en eller flera av dina anpassade utvärderingar eller inbyggda utvärderingar som ska köras. Anpassad utvärdering visar en lista över alla utvärderingsflöden som du har skapat, klonat eller anpassat. Utvärderingsflöden som skapats av andra som arbetar med samma projekt visas inte i det här avsnittet.
På skärmen Konfigurera utvärdering anger du källorna för de indata som behövs för utvärderingsmetoden. Till exempel kan kolumnen grundsanning komma från en datauppsättning. Om utvärderingsmetoden inte kräver data från en datauppsättning behöver du inte välja en datauppsättning eller referera till några datauppsättningskolumner i avsnittet för indatamappning.
I avsnittet Utvärderingsindatamappning kan du ange källorna till nödvändiga indata för utvärderingen. Om datakällan kommer från körningsutdata anger du källan som
${run.outputs.[OutputName]}. Om data kommer från testdatauppsättningen anger du källan som${data.[ColumnName]}. Alla beskrivningar som du anger för dataindata visas också här. Mer information finns i Skicka batchkörning och utvärdera ett flöde.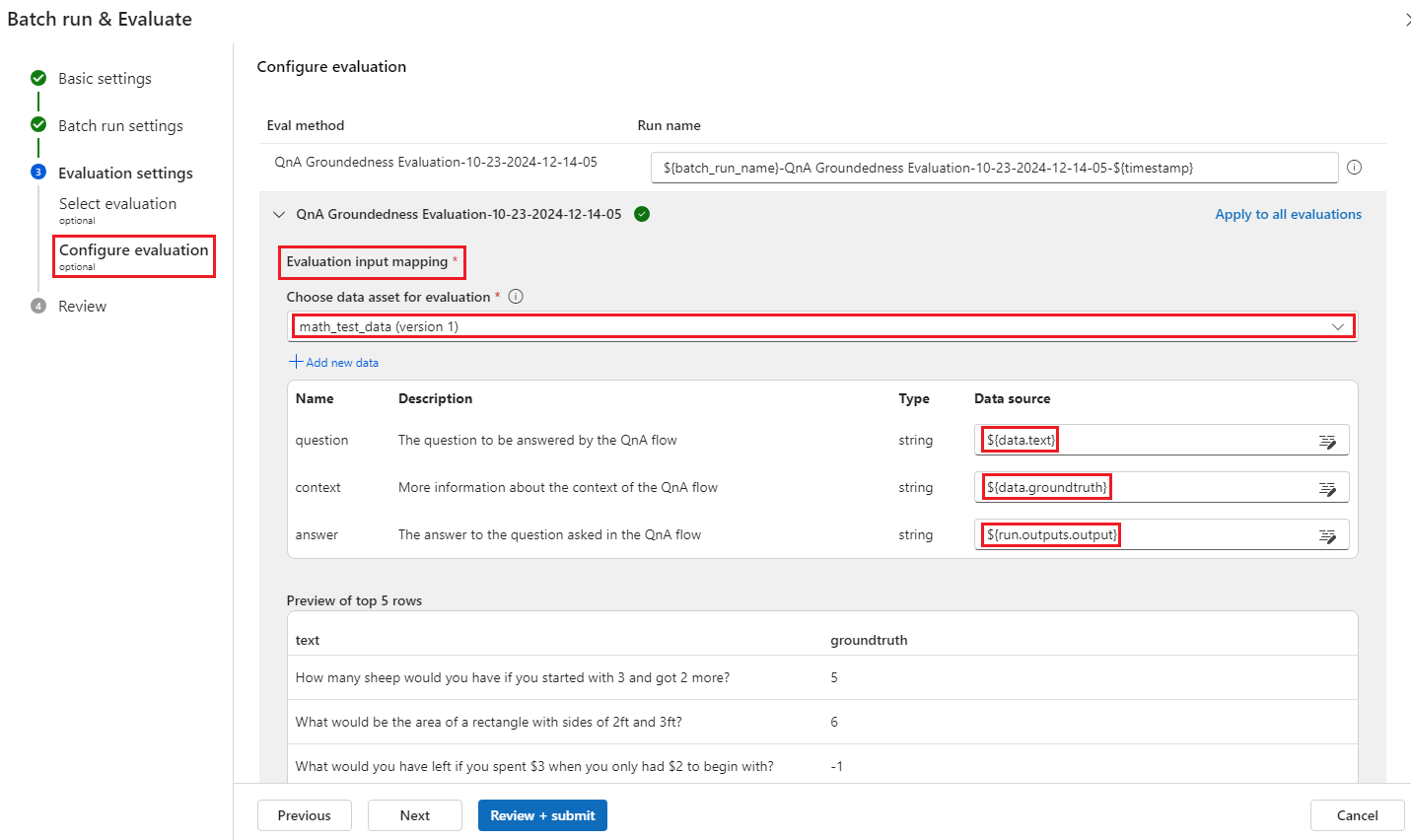
Viktigt!
Om ditt utvärderingsflöde har en LLM-nod eller kräver en anslutning för att använda autentiseringsuppgifter eller andra nycklar måste du ange anslutningsdata i avsnittet Anslutning på den här skärmen för att kunna använda utvärderingsflödet.
Välj Granska + skicka och välj sedan Skicka för att köra utvärderingsflödet.
När utvärderingsflödet har slutförts kan du se poäng på instansnivå genom att välja Visa batchkörningar>Visa de senaste batchkörningsutdata överst i det flöde som du utvärderade. Välj din utvärderingskörning i listrutan Lägg till relaterade resultat för att se resultatet för varje datarad.