Skicka en batchkörning för att utvärdera ett flöde
En batchkörning kör ett promptflöde med en stor datamängd och genererar utdata för varje datarad. Om du vill utvärdera hur bra ditt promptflöde presterar med en stor datamängd kan du skicka en batchkörning och använda utvärderingsmetoder för att generera prestandapoäng och mått.
När batchflödet har slutförts körs utvärderingsmetoderna automatiskt för att beräkna poäng och mått. Du kan använda utvärderingsmåtten för att utvärdera resultatet av ditt flöde mot dina prestandakriterier och mål.
Den här artikeln beskriver hur du skickar en batchkörning och använder en utvärderingsmetod för att mäta kvaliteten på dina flödesutdata. Du lär dig hur du visar utvärderingsresultatet och måtten och hur du startar en ny utvärderingsrunda med en annan metod eller delmängd av varianter.
Förutsättningar
Om du vill köra ett batchflöde med en utvärderingsmetod behöver du följande komponenter:
Ett fungerande Azure Machine Learning-promptflöde som du vill testa prestanda för.
En testdatauppsättning som ska användas för batchkörningen.
Din testdatauppsättning måste vara i CSV-, TSV- eller JSONL-format och ska ha rubriker som matchar indatanamnen för ditt flöde. Du kan dock mappa olika datamängdskolumner till indatakolumner under konfigurationsprocessen för utvärderingskörningen.
Skapa och skicka en utvärderings batchkörning
Om du vill skicka en batchkörning väljer du den datauppsättning som du vill testa flödet med. Du kan också välja en utvärderingsmetod för att beräkna mått för dina flödesutdata. Om du inte vill använda en utvärderingsmetod kan du hoppa över utvärderingsstegen och köra batchkörningen utan att beräkna några mått. Du kan också köra en utvärderingsrunda senare.
Om du vill starta en batchkörning med eller utan utvärdering väljer du Utvärdera överst på sidan för promptflöde.
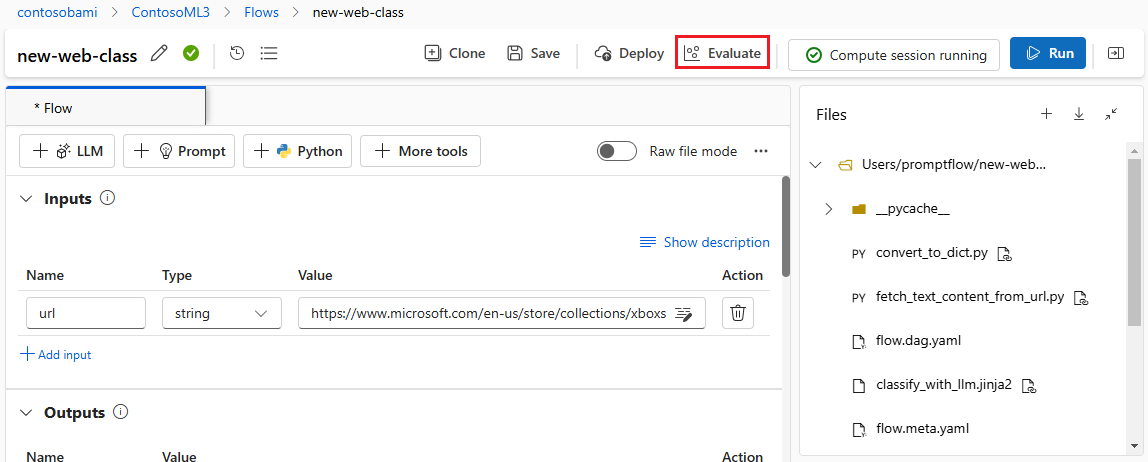
På sidan Grundläggande inställningar i guiden Kör och utvärdera i Batch anpassar du visningsnamnet Kör om du vill och kan också ange en Körningsbeskrivning och Taggar. Välj Nästa.
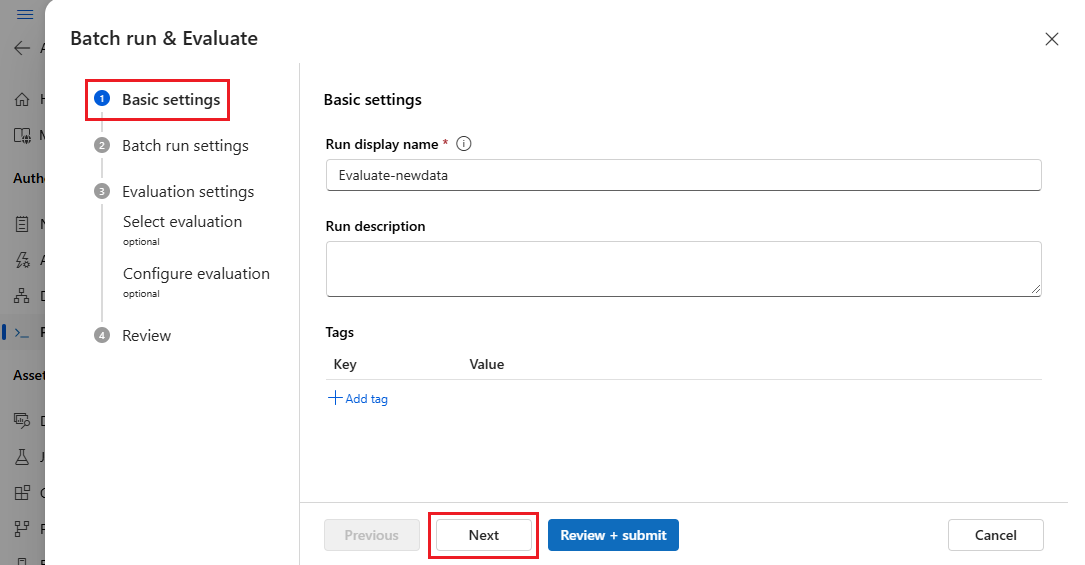
På sidan Inställningar för Batch-körning väljer du den datauppsättning som ska användas och konfigurerar indatamappning.
Prompt flow stöder mappning av flödesindata till en specifik datakolumn i datauppsättningen. Du kan tilldela en datamängdskolumn till en viss indata med hjälp
${data.<column>}av . Om du vill tilldela ett konstant värde till en indata kan du ange det värdet direkt.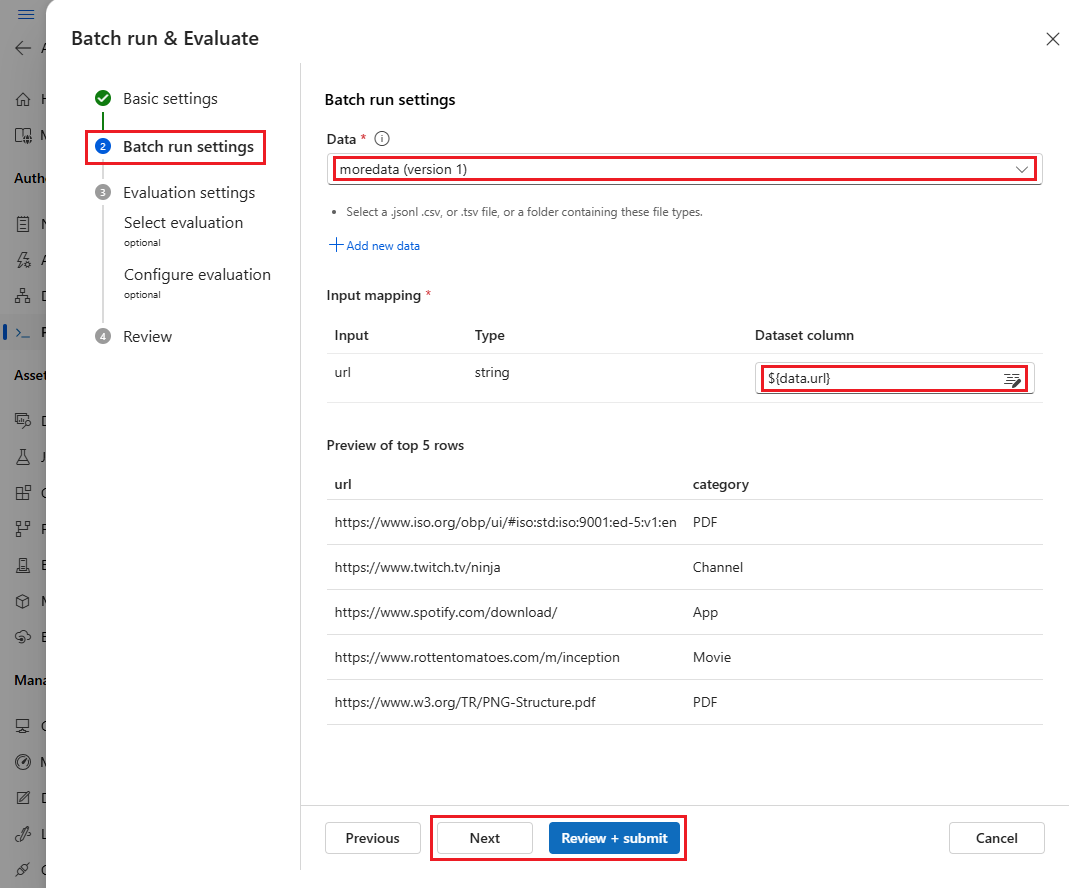
Du kan välja Granska + skicka nu för att hoppa över utvärderingsstegen och köra batchkörningen utan att använda någon utvärderingsmetod. Batchkörningen genererar sedan enskilda utdata för varje objekt i datauppsättningen. Du kan kontrollera utdata manuellt eller exportera dem för ytterligare analys.
Om du vill använda en utvärderingsmetod för att verifiera körningens prestanda väljer du Nästa. Du kan också lägga till en ny utvärderingsrunda till en slutförd batchkörning.
På sidan Välj utvärdering väljer du en eller flera anpassade eller inbyggda utvärderingar som ska köras. Du kan välja knappen Visa information för att se mer information om utvärderingsmetoden, till exempel de mått som den genererar och de anslutningar och indata som krävs.
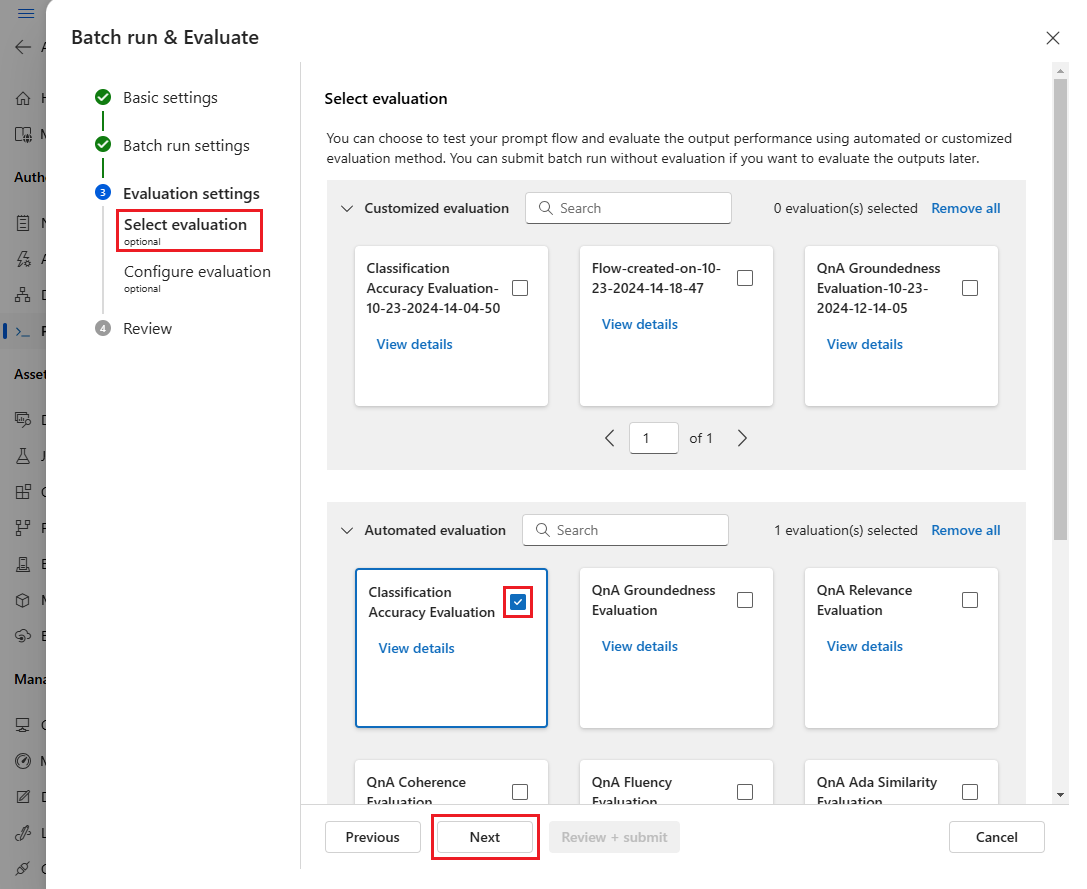
På skärmen Konfigurera utvärdering anger du sedan källorna till nödvändiga indata för utvärderingen. Till exempel kan kolumnen grundsanning komma från en datauppsättning. Som standard använder utvärderingen samma datauppsättning som den övergripande batchkörningen. Men om motsvarande etiketter eller målgrunds sanningsvärden finns i en annan datauppsättning kan du använda den.
Kommentar
Om utvärderingsmetoden inte kräver data från en datauppsättning är valet av datamängd en valfri konfiguration som inte påverkar utvärderingsresultaten. Du behöver inte välja en datauppsättning eller referera till några datamängdskolumner i avsnittet för indatamappning.
I avsnittet Utvärderingsindatamappning anger du källorna till nödvändiga indata för utvärderingen.
- Om data kommer från testdatauppsättningen anger du källan som
${data.[ColumnName]}. - Om data kommer från körningsutdata anger du källan som
${run.outputs.[OutputName]}.
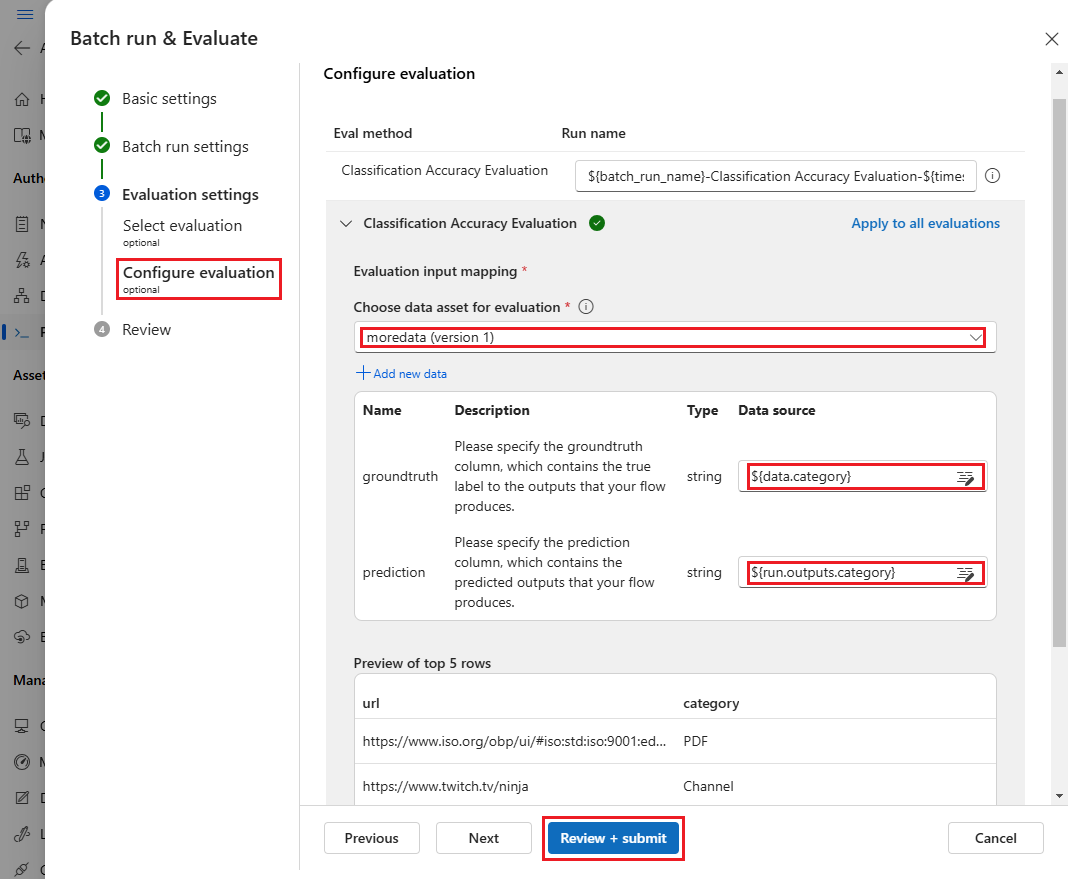
- Om data kommer från testdatauppsättningen anger du källan som
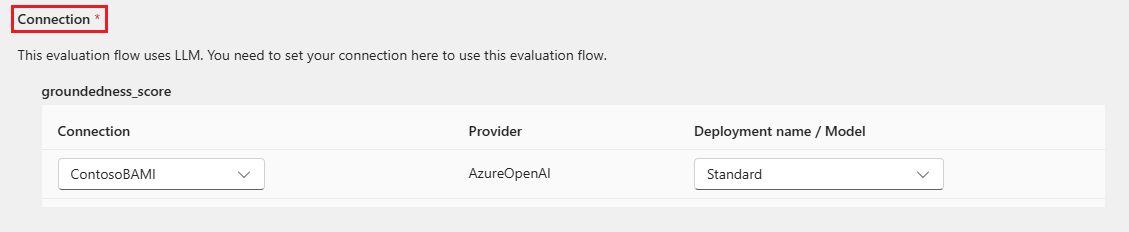
Vissa utvärderingsmetoder kräver stora språkmodeller (LLM: er) som GPT-4 eller GPT-3, eller behöver andra anslutningar för att använda autentiseringsuppgifter eller nycklar. För dessa metoder måste du ange anslutningsdata i avsnittet Anslutning längst ned på den här skärmen för att kunna använda utvärderingsflödet. Mer information finns i Konfigurera en anslutning.
Välj Granska + skicka för att granska inställningarna och välj sedan Skicka för att starta batchkörningen med utvärdering.






Kommentar
- Vissa utvärderingsprocesser använder många token, så vi rekommenderar att du använder en modell som har stöd >för =16 000 token.
- Batchkörningar har en maximal varaktighet på 10 timmar. Om en batchkörning överskrider den här gränsen avslutas den och visas som misslyckad. Övervaka DIN LLM-kapacitet för att undvika begränsning. Om det behövs bör du överväga att minska storleken på dina data. Om du fortfarande har problem kan du lämna in ett feedbackformulär eller en supportbegäran.
Visa utvärderingsresultat och mått
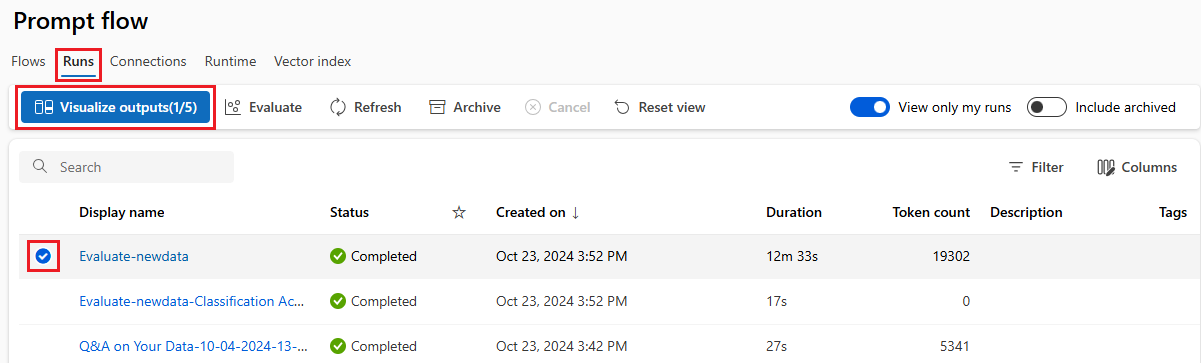
Du hittar listan över skickade batchkörningar på fliken Körningar på sidan Azure Machine Learning-studio Fråga flöde.
Om du vill kontrollera resultatet av en batchkörning väljer du körningen och väljer sedan Visualisera utdata.
På skärmen Visualisera utdata visar avsnittet Körningar och mått övergripande resultat för batchkörningen och utvärderingskörningen. Avsnittet Utdata visar körningsindata rad för rad i en resultattabell som även innehåller rad-ID, Körning, Status och Systemmått.
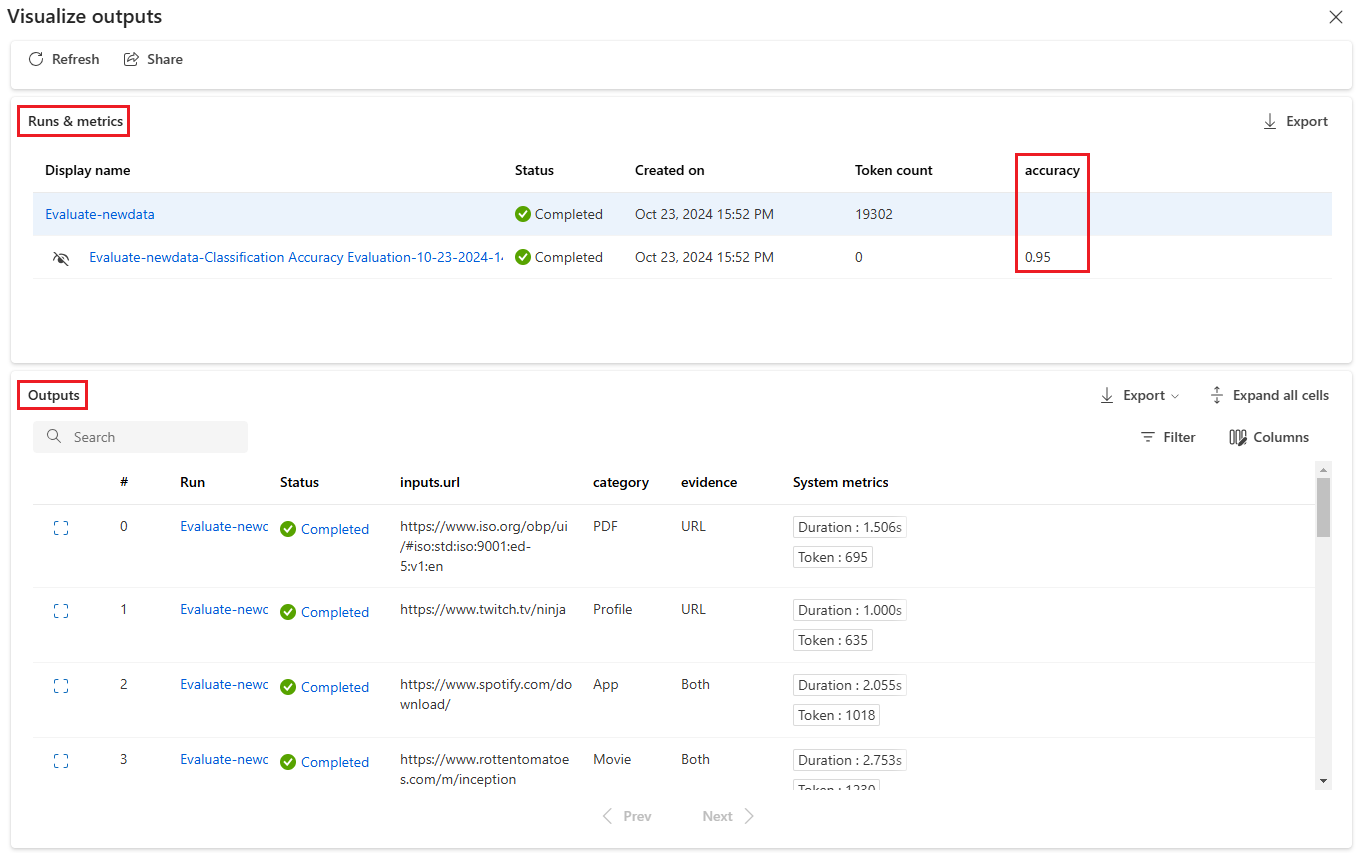
Om du aktiverar ikonen Visa bredvid utvärderingskörningen i avsnittet Körningar och mått visar tabellen Utdata också utvärderingspoängen eller betyget för varje rad.
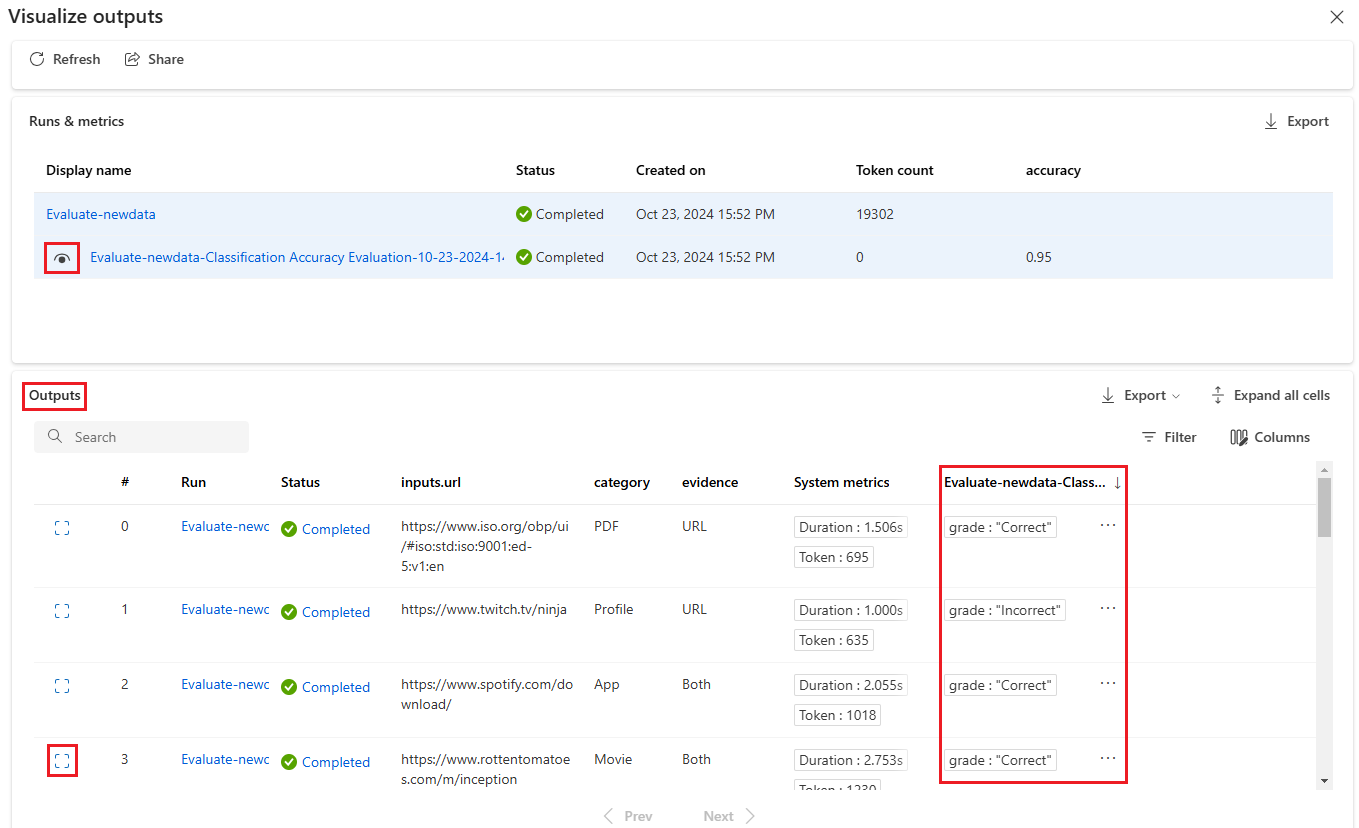
Välj ikonen Visa information bredvid varje rad i tabellen Utdata för att observera och felsöka spårningsvyn och information för det testfallet. Spårningsvyn visar information, till exempel antal token och varaktighet för det fallet. Expandera och välj ett steg för att se översikten och indata för det steget.
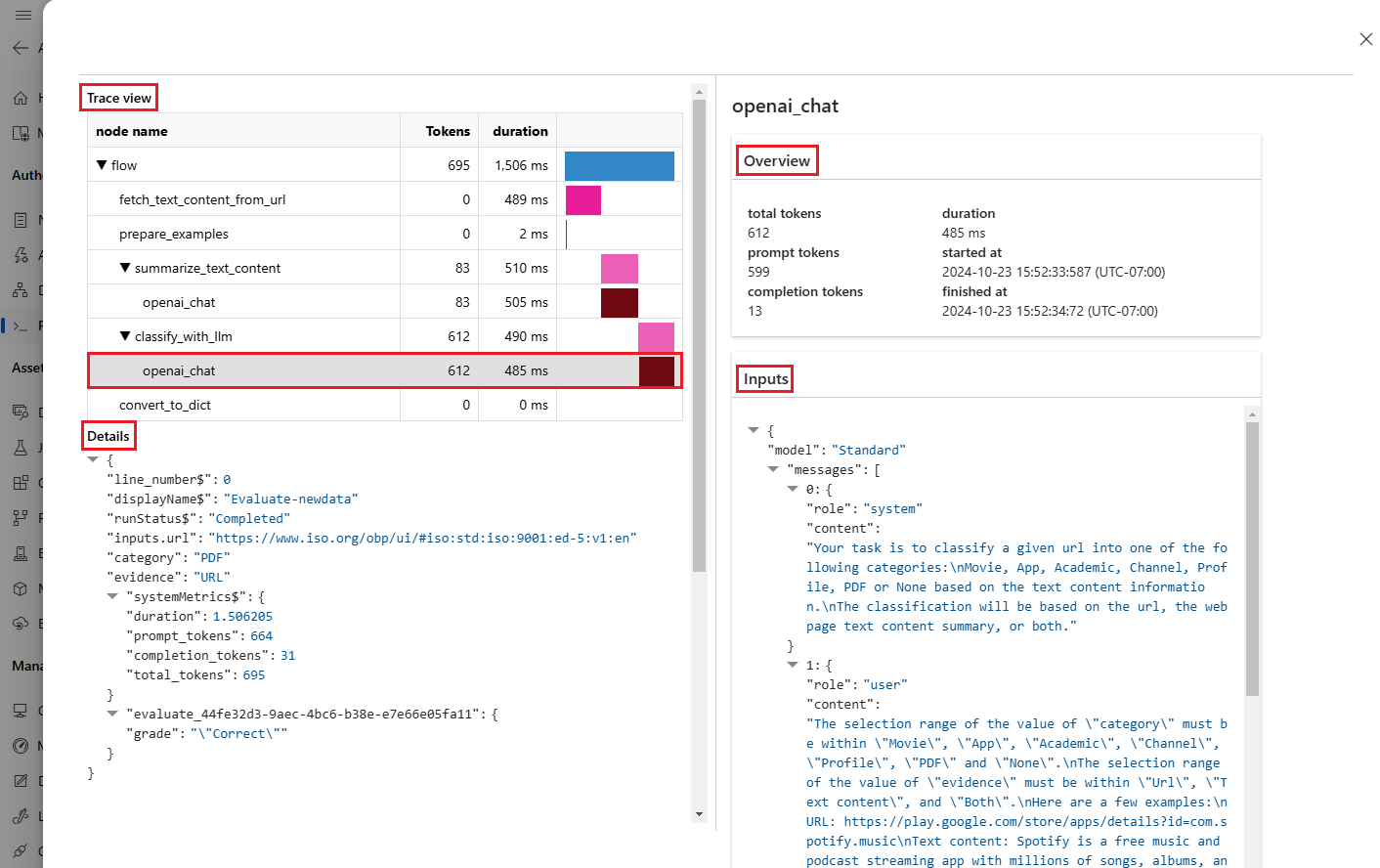




Du kan också visa utvärderingskörningsresultat från det promptflöde som du testade. Under Visa batchkörningar väljer du Visa batchkörningar för att se listan över batchkörningar för flödet, eller välj Visa de senaste batchkörningsutdata för att se utdata för den senaste körningen.

I batchkörningslistan väljer du ett batchkörningsnamn för att öppna flödessidan för den körningen.
På flödessidan för en utvärderingskörning väljer du Visa utdata eller Information för att se information om flödet. Du kan också klona flödet för att skapa ett nytt flöde eller distribuera det som en onlineslutpunkt.

På skärmen Information:
Fliken Översikt visar omfattande information om körningen, inklusive körningsegenskaper, indatauppsättning, utdatauppsättning, taggar och beskrivning.
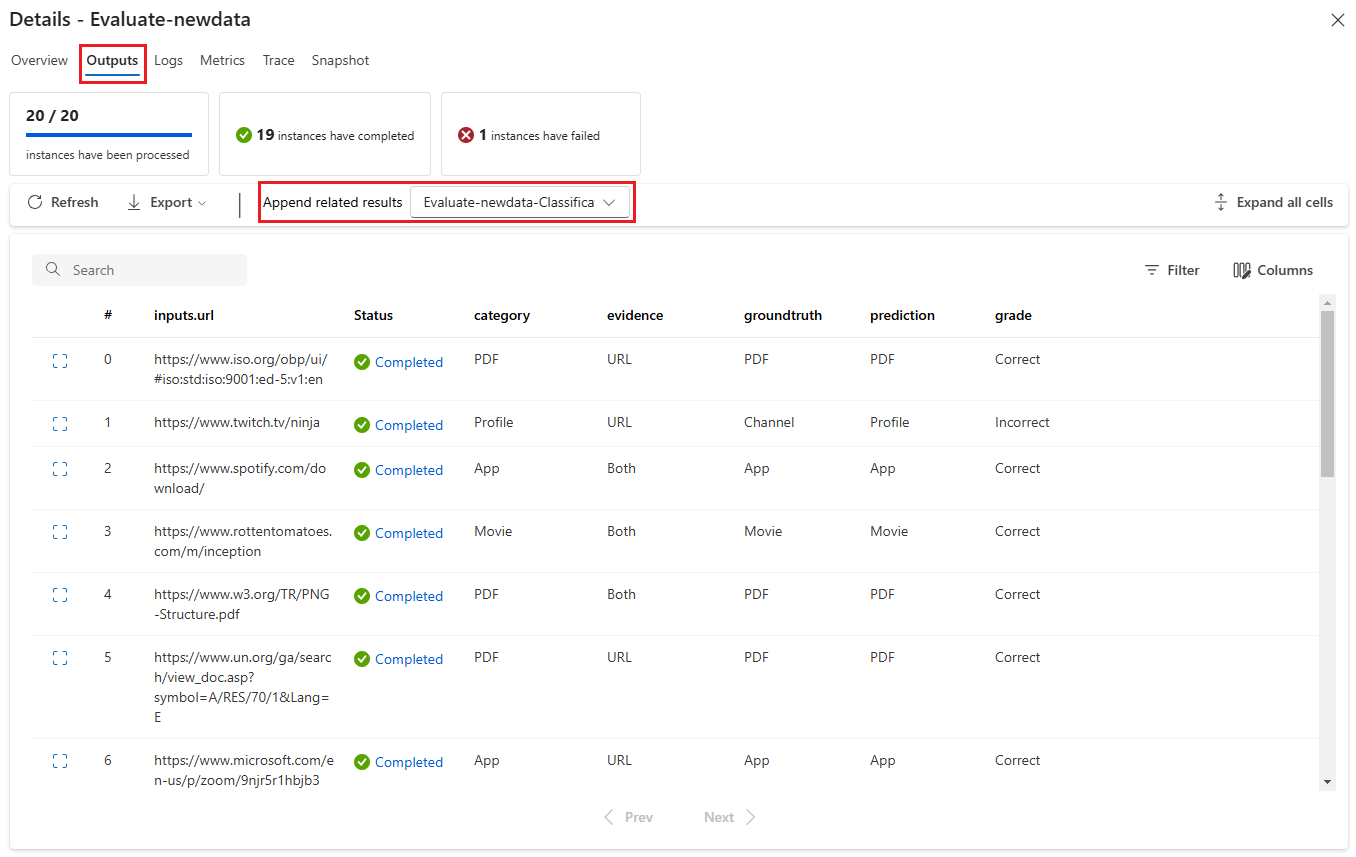
Fliken Utdata visar en sammanfattning av resultaten överst på sidan följt av resultattabellen för batchkörningen. Om du väljer utvärderingskörningen bredvid Lägg till relaterade resultat visar tabellen även utvärderingskörningsresultatet.
Fliken Loggar visar körningsloggarna, vilket kan vara användbart för detaljerad felsökning av körningsfel. Du kan ladda ned loggfilerna.
Fliken Mått innehåller en länk till måtten för körningen.
Fliken Spårning visar detaljerad information, till exempel antal token och varaktighet för varje testfall. Expandera och välj ett steg för att se översikten och indata för det steget.
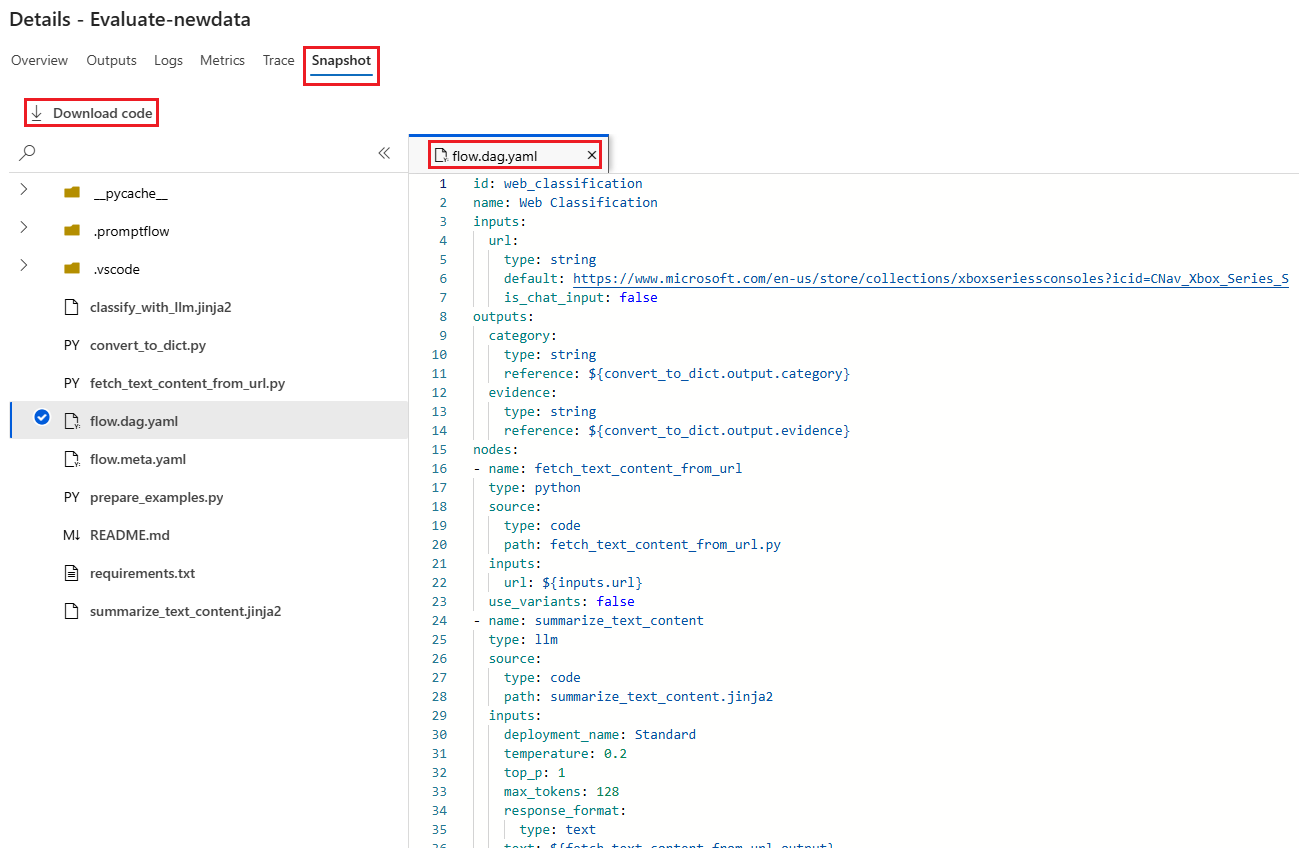
Fliken Ögonblicksbild visar filerna och koden från körningen. Du kan se flödesdefinitionen flow.dag.yaml och ladda ned någon av filerna.


Starta en ny utvärderingsrunda för samma körning
Du kan köra en ny utvärderingsrunda för att beräkna mått för en slutförd batchkörning utan att köra flödet igen. Den här processen sparar kostnaden för att köra flödet igen och är användbar i följande scenarier:
- Du valde inte en utvärderingsmetod när du skickade en batchkörning och vill nu utvärdera körningsprestanda.
- Du använde en utvärderingsmetod för att beräkna ett visst mått och vill nu beräkna ett annat mått.
- Din tidigare utvärderingskörning misslyckades, men batchkörningen genererade utdata och du vill prova utvärderingen igen.
Om du vill starta en ny utvärderingsrunda väljer du Utvärdera överst på batchkörningsflödessidan. Guiden Ny utvärdering öppnas på skärmen Välj utvärdering . Slutför installationen och skicka den nya utvärderingskörningen.
Den nya körningen visas i listan körning av promptflöde och du kan välja mer än en rad i listan och sedan välja Visualisera utdata för att jämföra utdata och mått.
Jämför historik och mått för utvärderingskörning
Om du ändrar flödet för att förbättra dess prestanda kan du skicka flera batchkörningar för att jämföra prestanda för de olika flödesversionerna. Du kan också jämföra måtten som beräknas med olika utvärderingsmetoder för att se vilken metod som är lämpligare för ditt flöde.
Om du vill kontrollera flödes batchkörningshistoriken väljer du Visa batchkörningar överst på flödessidan. Du kan markera varje körning för att kontrollera informationen. Du kan också välja flera körningar och välja Visualisera utdata för att jämföra måtten och utdata för dessa körningar.

Förstå inbyggda utvärderingsmått
Azure Machine Learning-promptflödet innehåller flera inbyggda utvärderingsmetoder som hjälper dig att mäta prestanda för dina flödesutdata. Varje utvärderingsmetod beräknar olika mått. I följande tabell beskrivs de tillgängliga inbyggda utvärderingsmetoderna.
| Utvärderingsmetod | Mätvärde | Beskrivning | Anslutning krävs? | Nödvändiga indata | Poängvärden |
|---|---|---|---|---|---|
| Utvärdering av klassificeringsnoggrannhet | Noggrannhet | Mäter prestandan för ett klassificeringssystem genom att jämföra dess utdata med grund sanning | Nej | förutsägelse, grund sanning | I intervallet [0, 1] |
| Utvärdering av QnA Groundedness | Grundstötning | Mäter hur grundade modellens förutsagda svar finns i indatakällan. Även om LLM-svaren är korrekta är de ogrundade om de inte kan verifieras mot källan. | Ja | fråga, svar, sammanhang (ingen grund sanning) | 1 till 5, med 1 = sämsta och 5 = bäst |
| QnA GPT-likhetsutvärdering | GPT-likhet | Mäter likheten mellan svar från användarbaserad grundsanning och modellens förutsagda svar med hjälp av en GPT-modell | Ja | fråga, svar, grund sanning (kontext behövs inte) | 1 till 5, med 1 = sämsta och 5 = bäst |
| Utvärdering av QnA-relevans | Relevans | Mäter hur relevanta modellens förutsagda svar är på de frågor som ställs | Ja | fråga, svar, sammanhang (ingen grund sanning) | 1 till 5, med 1 = sämsta och 5 = bäst |
| Utvärdering av QnA-konsekvens | Koherens | Mäter kvaliteten på alla meningar i en modells förutsagda svar och hur de passar ihop naturligt | Ja | fråga, svar (ingen grund sanning eller kontext) | 1 till 5, med 1 = sämsta och 5 = bäst |
| Utvärdering av QnA-fluency | Flyt | Mäter grammatisk och språklig korrekthet i modellens förutsagda svar | Ja | fråga, svar (ingen grund sanning eller kontext) | 1 till 5, med 1 = sämsta och 5 = bäst |
| Utvärdering av QnA F1-poäng | F1-poäng | Mäter förhållandet mellan antalet delade ord mellan modellförutsägelse och grundsanning | Nej | fråga, svar, grund sanning (kontext behövs inte) | I intervallet [0, 1] |
| Utvärdering av QnA Ada-likhet | Ada-likhet | Beräknar inbäddningar på meningsnivå (dokument) med api för Ada-inbäddningar för både grundsanning och förutsägelse och beräknar sedan cosinnalikhet mellan dem (ett flyttalsnummer) | Ja | fråga, svar, grund sanning (kontext behövs inte) | I intervallet [0, 1] |
Förbättra flödesprestanda
Om körningen misslyckas kontrollerar du utdata och loggdata och felsöker eventuella flödesfel. Om du vill åtgärda flödet eller förbättra prestandan kan du prova att ändra flödesprompten, systemmeddelandet, flödesparametrarna eller flödeslogiken.
Promptkonstruktion
Snabb konstruktion kan vara svårt. Mer information om frågekonstruktionskoncept finns i Översikt över frågor. Mer information om hur du skapar en fråga som kan hjälpa dig att uppnå dina mål finns i Prompt engineering techniques (Fråga tekniska tekniker).
Systemmeddelande
Du kan använda systemmeddelandet, som ibland kallas metaprompt eller systemprompt, för att vägleda ai-systemets beteende och förbättra systemets prestanda. Information om hur du förbättrar flödesprestandan med systemmeddelanden finns i Stegvis redigering av systemmeddelanden.
Gyllene datauppsättningar
Att skapa en andrepilot som använder LLM:er innebär vanligtvis att grunda modellen i verkligheten med hjälp av källdatauppsättningar. En gyllene datauppsättning hjälper till att säkerställa att LLM:erna ger de mest exakta och användbara svaren på kundfrågor.
En gyllene datamängd är en samling realistiska kundfrågor och skickligt utformade svar som fungerar som ett kvalitetssäkringsverktyg för de LLM:er som din andrepilot använder. Gyllene datauppsättningar används inte för att träna en LLM eller mata in kontext i en LLM-prompt, utan för att utvärdera kvaliteten på de svar som LLM genererar.
Om ditt scenario omfattar en andrepilot, eller om du skapar en egen andrepilot, kan du läsa Skapa golden datauppsättningar för detaljerad vägledning och metodtips.