Skicka ett utbildningsjobb i studio
Det finns många sätt att skapa ett träningsjobb med Azure Machine Learning. Du kan använda CLI (se Träna modeller (skapa jobb)), REST API (se Träna modeller med REST (förhandsversion)) eller så kan du använda användargränssnittet för att skapa ett träningsjobb direkt. I den här artikeln får du lära dig hur du använder dina egna data och din egen kod för att träna en maskininlärningsmodell med en guidad upplevelse för att skicka träningsjobb i Azure Machine Learning-studio.
Viktigt!
Den här funktionen är för närvarande i allmänt tillgänglig förhandsversion. Den här förhandsversionen tillhandahålls utan ett serviceavtal och vi rekommenderar det inte för produktionsarbetsbelastningar. Vissa funktioner kanske inte stöds eller kan vara begränsade.
Mer information finns i Kompletterande villkor för användning av Microsoft Azure-förhandsversioner.
Förutsättningar
En Azure-prenumeration. Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar. Prova den kostnadsfria eller betalda versionen av Azure Machine Learning idag.
En Azure Machine Learning-arbetsyta. Se Skapa arbetsyteresurser.
Förstå vad ett jobb är i Azure Machine Learning. Se hur du tränar modeller.
Kom igång
Logga in på Azure Machine Learning-studio.
Välj din prenumeration och arbetsyta.
- Du kan ange användargränssnittet för jobbskapande från startsidan. Välj Skapa ny och välj Jobb.
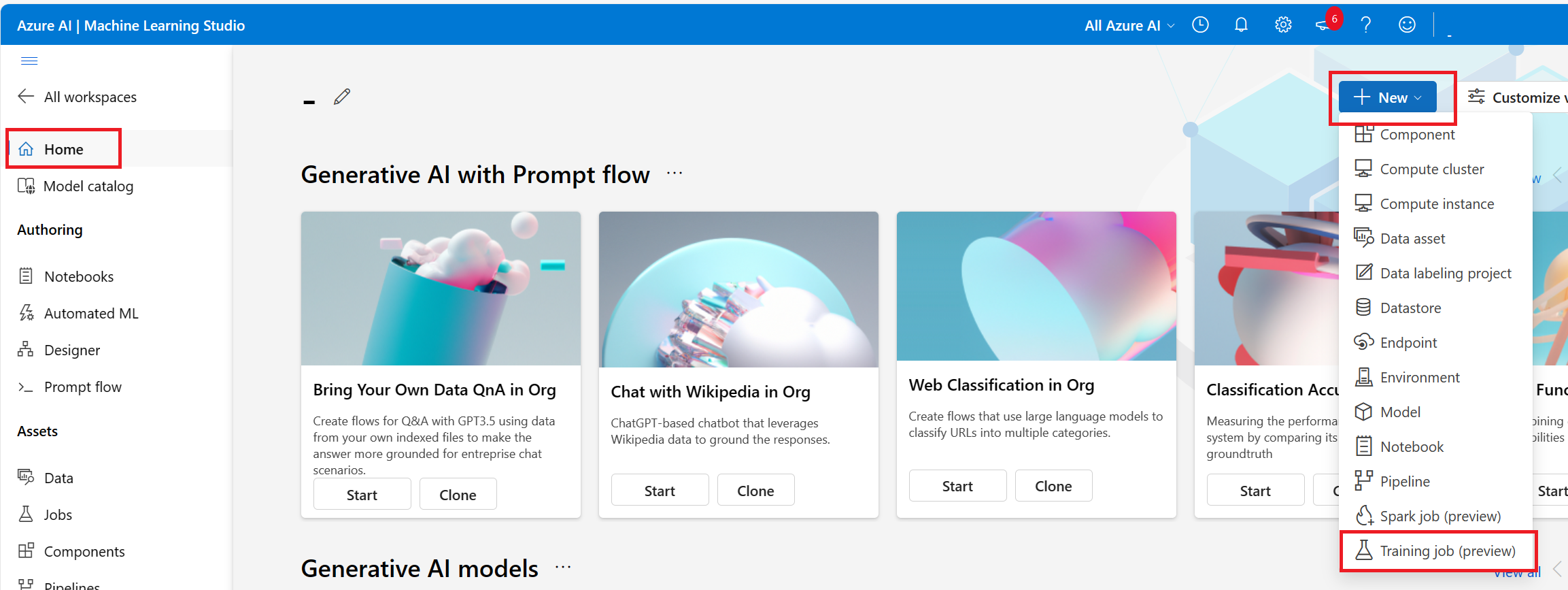
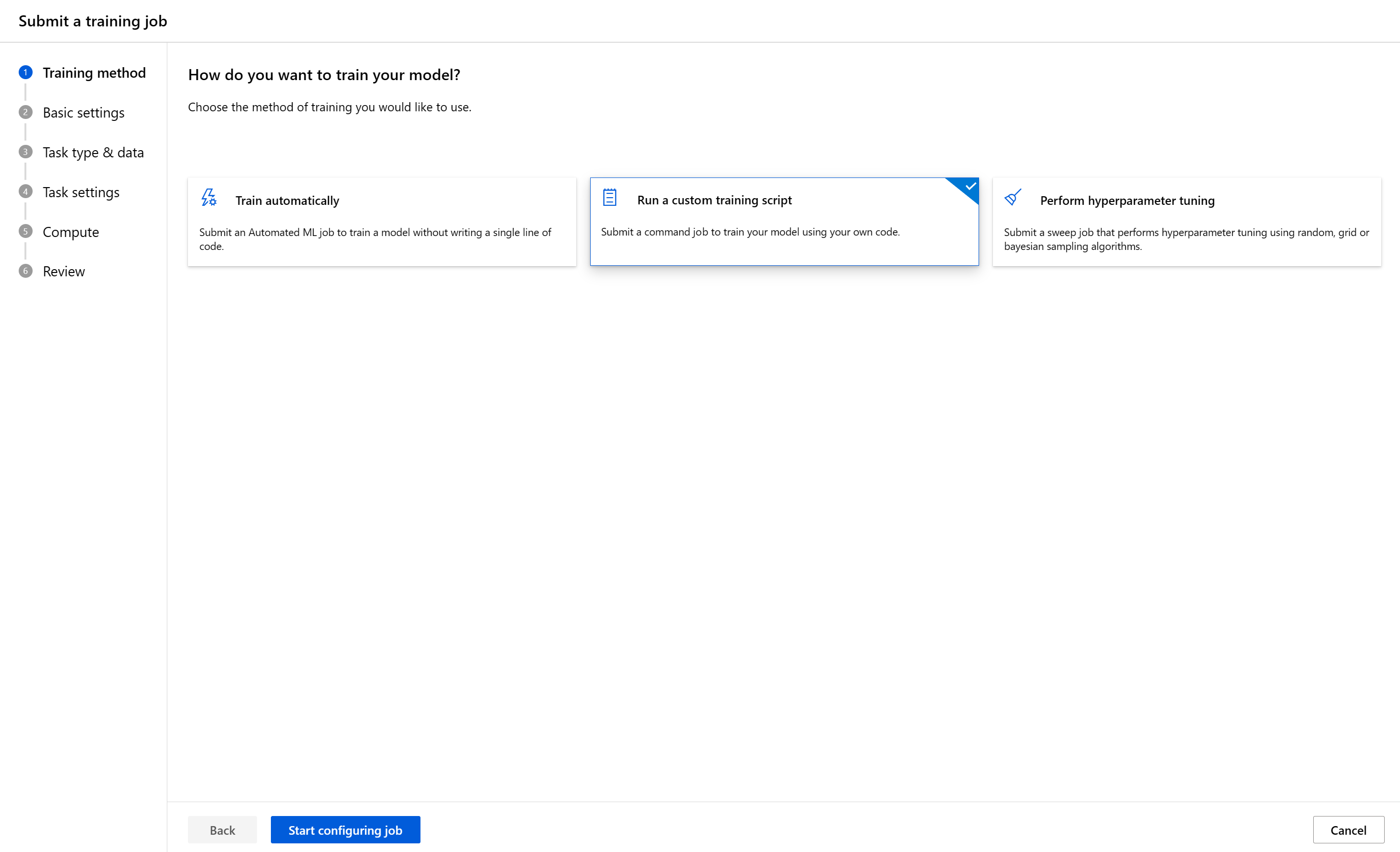
I det här steget kan du välja din träningsmetod, fylla i resten av sändningsformuläret baserat på ditt val och skicka träningsjobbet. Nedan går vi igenom formuläret med stegen för att köra ett anpassat skript (kommandojobb).
Konfigurera grundläggande inställningar
Det första steget är att konfigurera grundläggande information om ditt träningsjobb. Du kan fortsätta härnäst om du är nöjd med de standardvärden som vi har valt åt dig eller gör ändringar i önskad inställning.
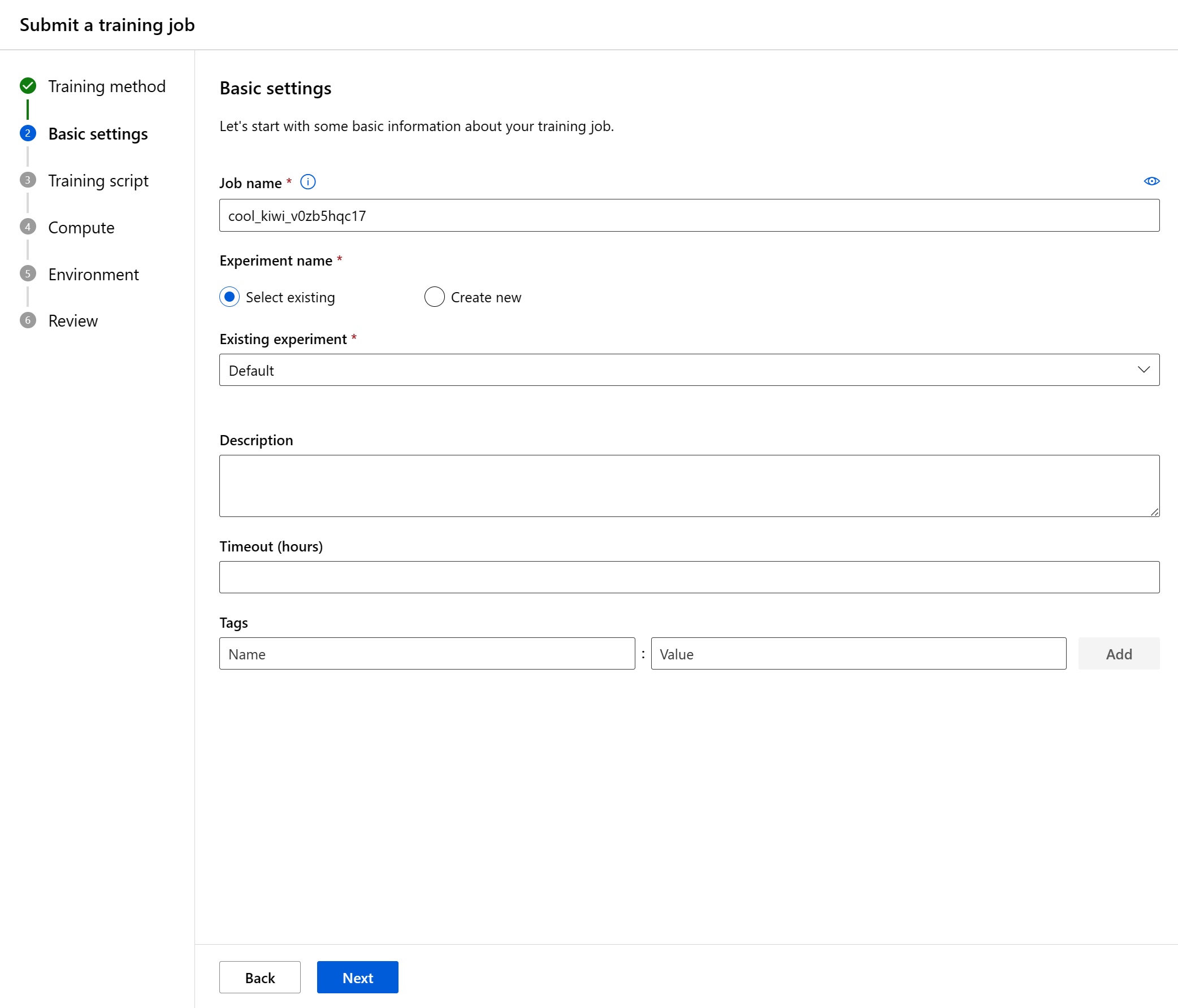
Det här är de fält som är tillgängliga:
| Fält | beskrivning |
|---|---|
| Jobbnamn | Jobbnamnsfältet används för att identifiera jobbet. Det används också som visningsnamn för jobbet. |
| Experimentnamn | Detta hjälper dig att organisera jobbet i Azure Machine Learning-studio. Varje jobbs körningspost ordnas under motsvarande experiment på studiofliken "Experiment". Som standard placerar Azure jobbet i standardexperimentet . |
| beskrivning | Lägg till text som beskriver ditt jobb om du vill. |
| Timeout | Ange hur många timmar hela träningsjobbet ska kunna köras. När den här gränsen har nåtts avbryter systemet jobbet, inklusive eventuella underordnade jobb. |
| Taggar | Lägg till taggar i ditt jobb för att hjälpa till med organisationen. |
Träningsskript
Nästa steg är att ladda upp källkoden, konfigurera indata eller utdata som krävs för att köra träningsjobbet och ange kommandot för att köra träningsskriptet.
Detta kan vara en kodfil eller en mapp från den lokala datorn eller arbetsytans standardbloblagring. Azure visar de filer som ska laddas upp när du har valt.
| Fält | Beskrivning |
|---|---|
| Kod | Det kan vara en fil eller en mapp från den lokala datorn eller arbetsytans standardbloblagring som träningsskript. Studio visar de filer som ska laddas upp när du har valt. |
| Indata | Ange så många indata som behövs för följande typer av data, heltal, tal, booleskt värde, sträng). |
| Command | Kommandot som ska köras. Kommandoradsargument kan uttryckligen skrivas in i kommandot eller härledas från andra avsnitt, särskilt indata med hjälp av klammerparenteser som beskrivs i nästa avsnitt. |
Kod
Kommandot körs från rotkatalogen i den uppladdade kodmappen. När du har valt din kodfil eller mapp kan du se de filer som ska laddas upp. Kopiera den relativa sökvägen till koden som innehåller startpunkten och klistra in den i rutan med etiketten Ange kommandot för att starta jobbet.
Om koden finns i rotkatalogen kan du referera direkt till den i kommandot . Till exempel python main.py.
Om koden inte finns i rotkatalogen bör du använda den relativa sökvägen. Strukturen för ordspråksmodellen är till exempel:
.
├── job.yml
├── data
└── src
└── main.py
Här finns källkoden i underkatalogen src . Kommandot skulle vara python ./src/main.py (plus andra kommandoradsargument).
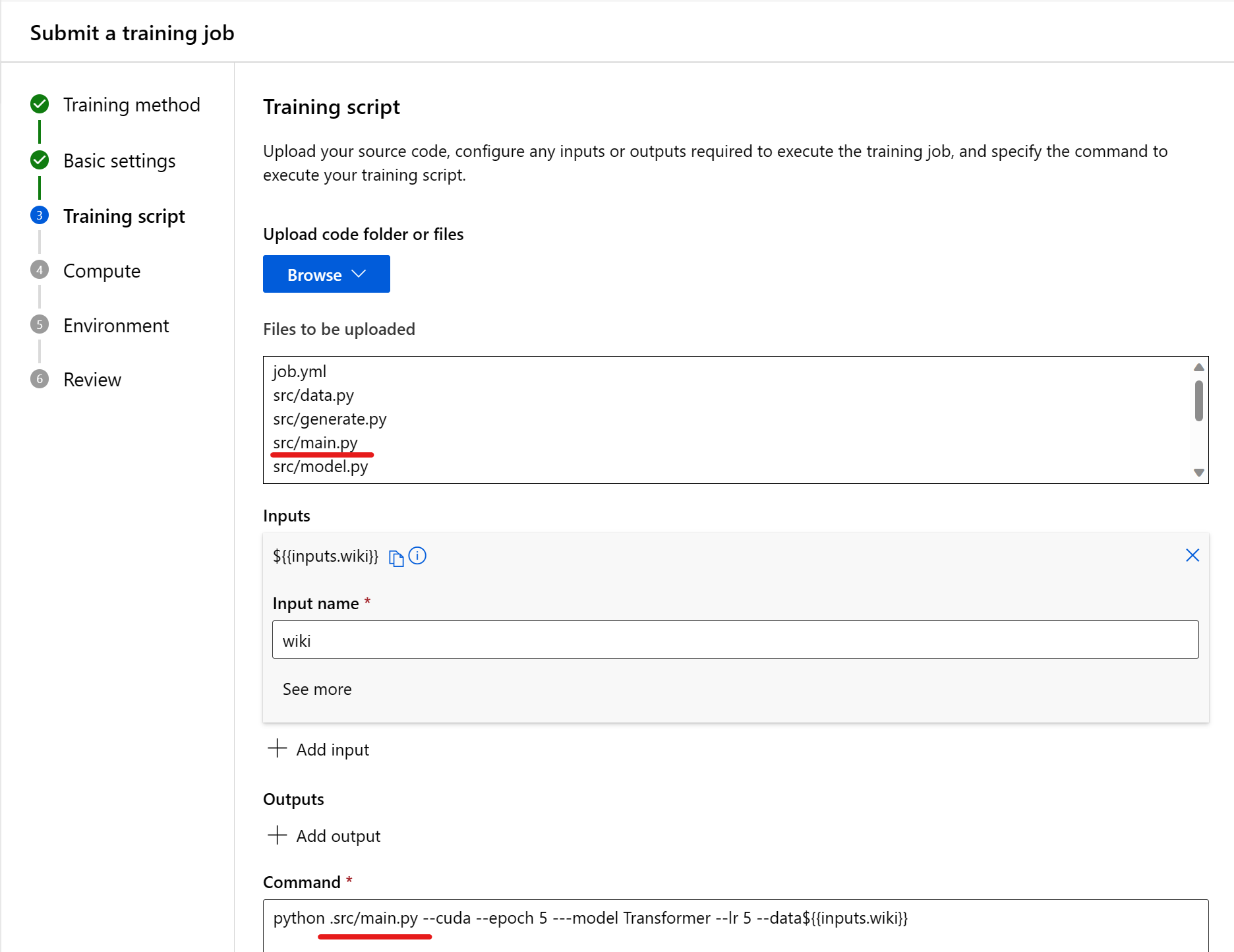
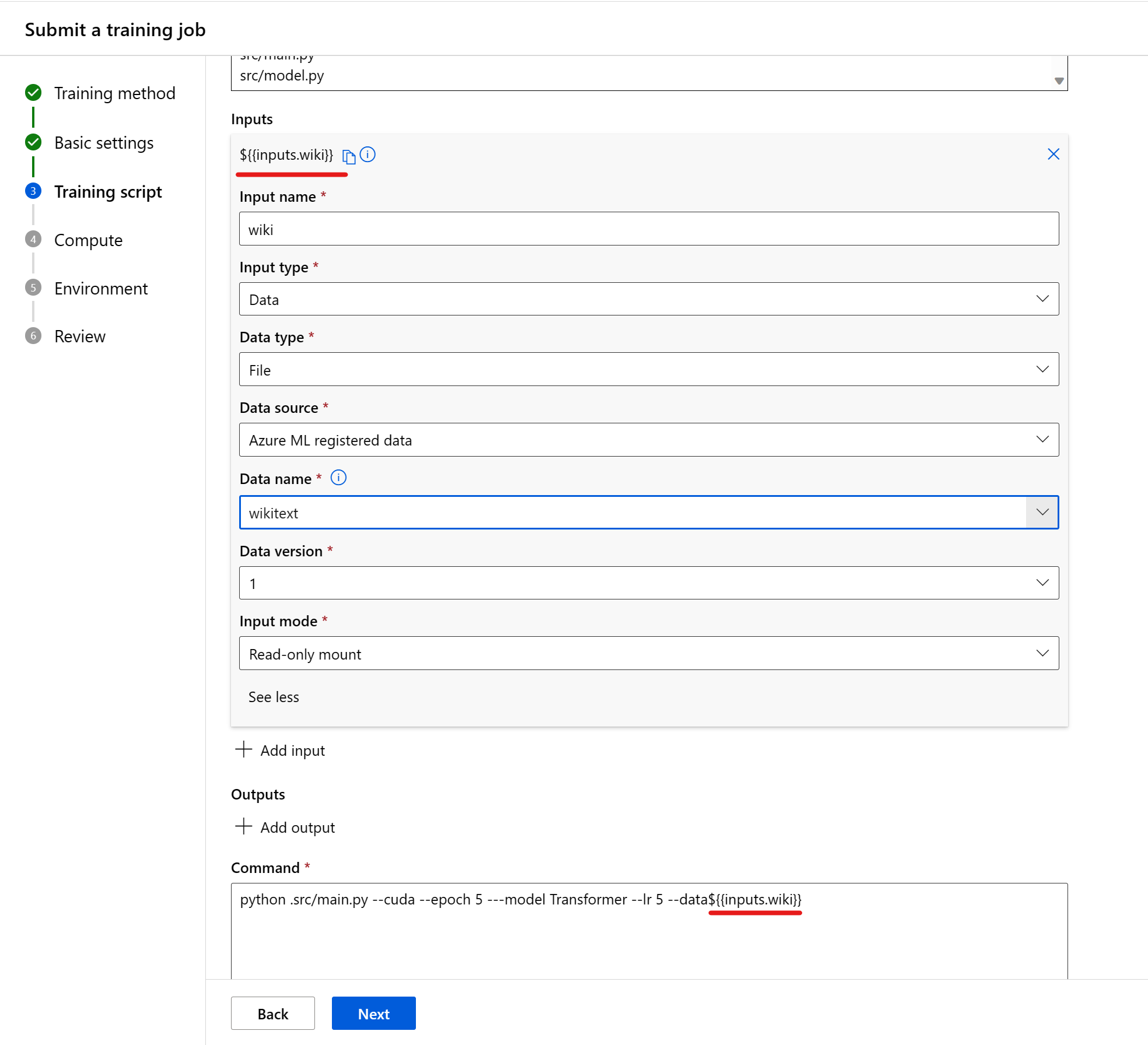
Indata
När du använder indata i kommandot måste du ange indatanamnet. Om du vill ange en indatavariabel använder du formuläret ${{inputs.input_name}}. Till exempel ${{inputs.wiki}}. Du kan sedan referera till den i kommandot, till exempel --data ${{inputs.wiki}}.
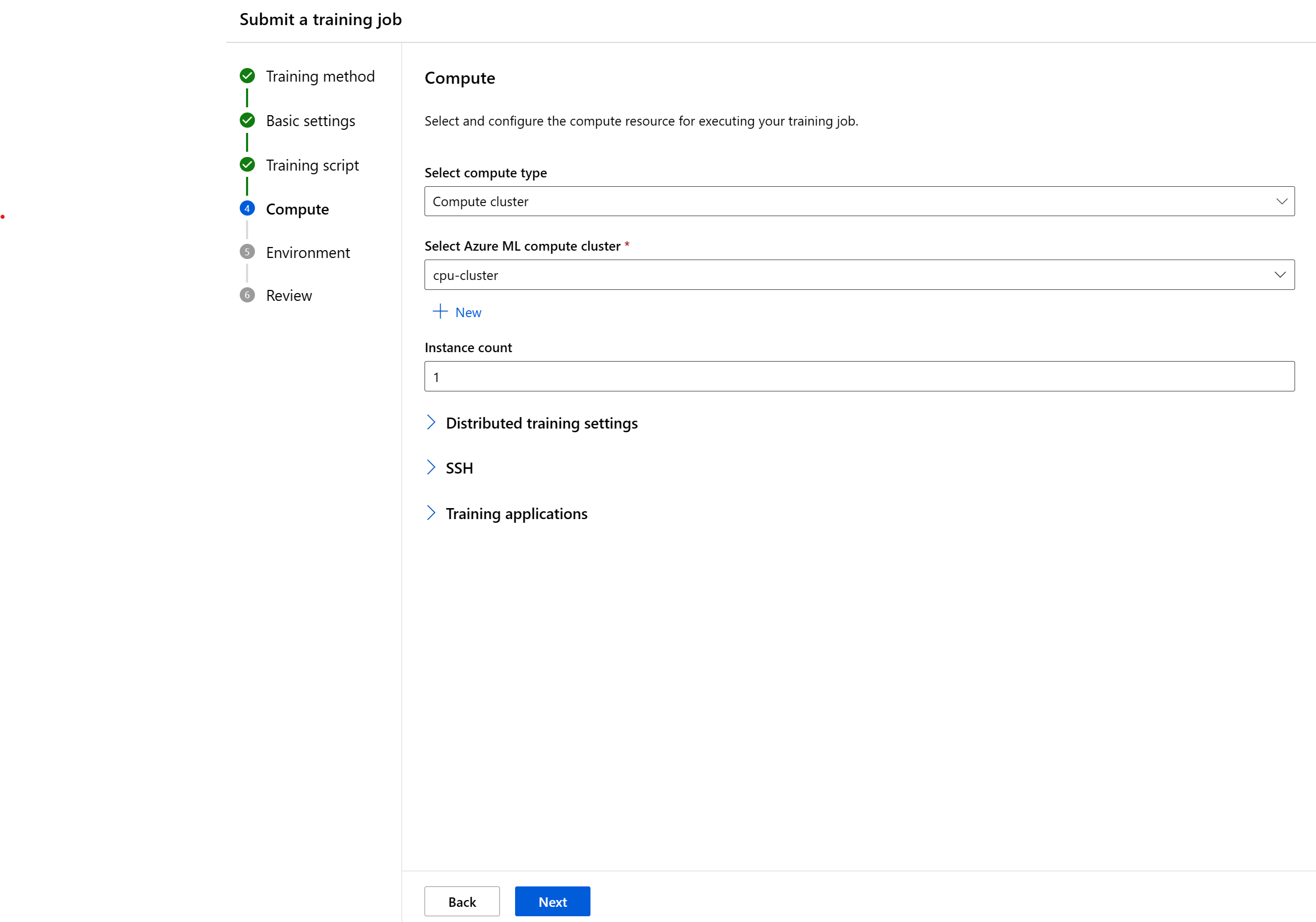
Välj beräkningsresurser
Nästa steg är att välja det beräkningsmål som du vill att jobbet ska köras på. Användargränssnittet för jobbskapande stöder flera beräkningstyper:
| Typ av beräkning | Introduktion |
|---|---|
| Beräkningsinstans | Vad är en Azure Machine Learning-beräkningsinstans? |
| Beräkningskluster | Vad är ett beräkningskluster? |
| Ansluten beräkning (Kubernetes-kluster) | Konfigurera och koppla Kubernetes-kluster var som helst (förhandsversion). |
- Välj en beräkningstyp
- Välj en befintlig beräkningsresurs. Listrutan visar nodinformationen och SKU-typen som hjälper dig att välja.
- För ett beräkningskluster eller ett Kubernetes-kluster kan du också ange hur många noder du vill ha för jobbet i Antal instanser. Standardantalet för instanser är 1.
- När du är nöjd med dina val väljer du Nästa.
Om du använder Azure Machine Learning för första gången visas en tom lista och en länk för att skapa en ny beräkning. Mer information om hur du skapar de olika typerna finns i:
| Typ av beräkning | Gör så här |
|---|---|
| Beräkningsinstans | Skapa en Azure Machine Learning-beräkningsinstans |
| Beräkningskluster | Skapa ett Azure Machine Learning-beräkningskluster |
| Bifogat Kubernetes-kluster | Bifoga ett Azure Arc-aktiverat Kubernetes-kluster |
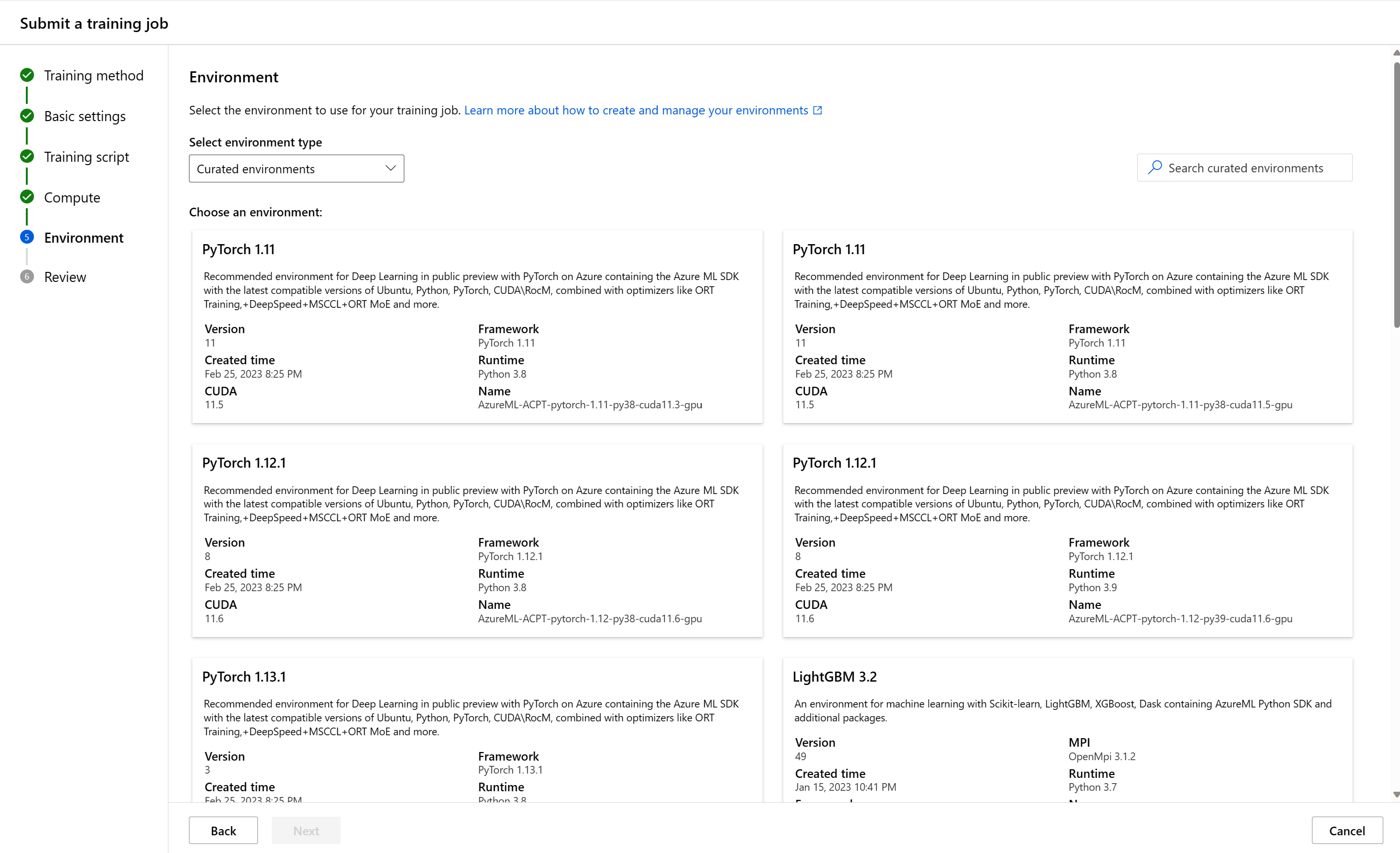
Ange den nödvändiga miljön
När du har valt ett beräkningsmål måste du ange körningsmiljön för ditt jobb. Användargränssnittet för jobbskapande har stöd för tre typer av miljöer:
- Organiserade miljöer
- Anpassade miljöer
- Containerregisteravbildning
Organiserade miljöer
Utvalda miljöer är Azure-definierade samlingar av Python-paket som används i vanliga ML-arbetsbelastningar. Utvalda miljöer är tillgängliga på din arbetsyta som standard. Dessa miljöer backas upp av cachelagrade Docker-avbildningar, vilket minskar jobbförberedelsekostnaderna. Korten som visas på sidan "Kurerade miljöer" visar information om varje miljö. Mer information finns i utvalda miljöer i Azure Machine Learning.
Anpassade miljöer
Anpassade miljöer är miljöer som du har angett själv. Du kan ange en miljö eller återanvända en miljö som du redan har skapat. Mer information finns i Hantera programvarumiljöer i Azure Machine Learning-studio (förhandsversion).
Containerregisteravbildning
Om du inte vill använda Azure Machine Learning-kurerade miljöer eller ange en egen anpassad miljö kan du använda en Docker-avbildning från ett offentligt containerregister, till exempel Docker Hub.
Granska och skapa
När du har konfigurerat jobbet väljer du Nästa för att gå till sidan Granska . Om du vill ändra en inställning väljer du pennikonen och gör ändringen.
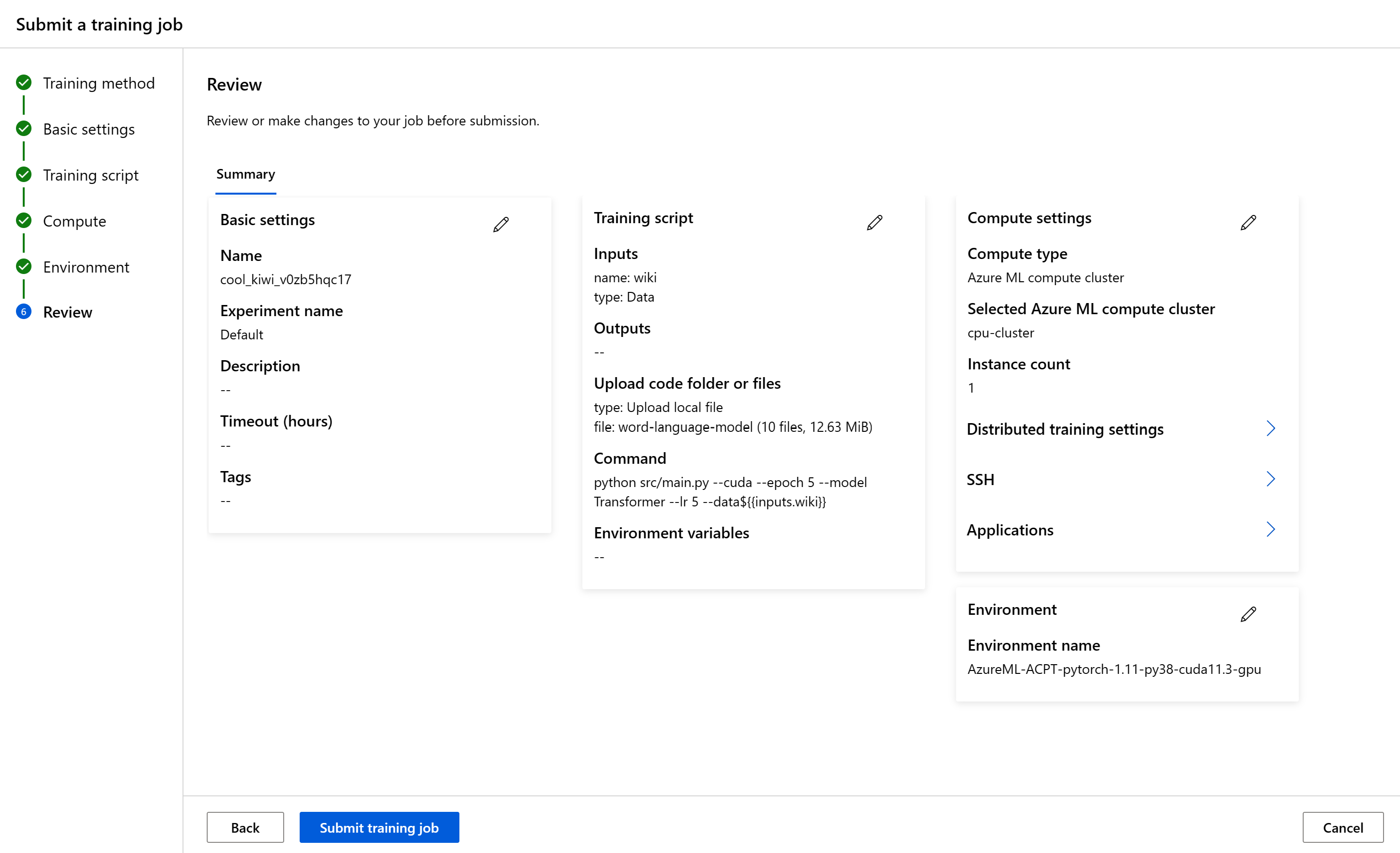
Starta jobbet genom att välja Skicka träningsjobb. När jobbet har skapats visar Azure sidan med jobbinformation, där du kan övervaka och hantera ditt träningsjobb.
Så här konfigurerar du e-postmeddelanden i studion
Om du vill börja ta emot e-postmeddelanden när jobbet, onlineslutpunkten eller batchslutpunkten är klar eller om det uppstår ett problem (misslyckades, avbröts) använder du följande steg:
- I Azure ML Studio går du till inställningar genom att välja kugghjulsikonen.
- Välj fliken E-postaviseringar .
- Växla om du vill aktivera eller inaktivera e-postaviseringar för en viss händelse.