Hantera indata och utdata för komponenter och pipelines
Azure Machine Learning-pipelines stöder indata och utdata på både komponent- och pipelinenivå. Den här artikeln beskriver pipeline- och komponentindata och utdata och hur du hanterar dem.
På komponentnivå definierar indata och utdata komponentgränssnittet. Du kan använda utdata från en komponent som indata för en annan komponent i samma överordnade pipeline, vilket gör att data eller modeller kan skickas mellan komponenter. Den här sammankopplingen representerar dataflödet i pipelinen.
På pipelinenivå kan du använda indata och utdata för att skicka pipelinejobb med varierande dataindata eller parametrar, till exempel learning_rate. Indata och utdata är särskilt användbara när du anropar en pipeline via en REST-slutpunkt. Du kan tilldela olika värden till pipelineindata eller komma åt utdata från olika pipelinejobb. Mer information finns i Skapa jobb och indata för batchslutpunkter.
Indata- och utdatatyper
Följande typer stöds som både indata och utdata för komponenter eller pipelines:
Datatyper. Mer information finns i Datatyper.
uri_fileuri_foldermltable
Modelltyper.
mlflow_modelcustom_model
Följande primitiva typer stöds också endast för indata:
- Primitiva typer
stringnumberintegerboolean
Primitiva typutdata stöds inte.
Exempel på indata och utdata
De här exemplen kommer från pipelinen NYC Taxi Data Regression i GitHub-lagringsplatsen för Azure Machine Learning-exempel.
- Träningskomponenten har en
numberindata med namnettest_split_ratio. - Förberedelsekomponenten har en
uri_foldertyputdata. Komponentens källkod läser CSV-filerna från indatamappen, bearbetar filerna och skriver de bearbetade CSV-filerna till utdatamappen. - Träningskomponenten har en
mlflow_modeltyputdata. Komponentens källkod sparar den tränade modellen med hjälp avmlflow.sklearn.save_modelmetoden .
Serialisering av utdata
Med data- eller modellutdata serialiseras utdata och sparas som filer på en lagringsplats. Senare steg kan komma åt filerna under jobbkörningen genom att montera den här lagringsplatsen eller genom att ladda ned eller ladda upp filerna till beräkningsfilsystemet.
Komponentens källkod måste serialisera utdataobjektet, som vanligtvis lagras i minnet, till filer. Du kan till exempel serialisera en Pandas-dataram till en CSV-fil. Azure Machine Learning definierar inte några standardiserade metoder för objektserialisering. Du har flexibiliteten att välja de metoder som du föredrar för att serialisera objekt till filer. I den underordnade komponenten kan du välja hur du ska deserialisera och läsa dessa filer.
Indata- och utdatasökvägar för datatyp
För indata och utdata för datatillgången måste du ange en sökvägsparameter som pekar på dataplatsen. I följande tabell visas de dataplatser som stöds för Azure Machine Learning-pipelineindata och utdata, med path parameterexempel.
| Plats | Indata | Utdata | Exempel |
|---|---|---|---|
| En sökväg på den lokala datorn | ✓ | ./home/<username>/data/my_data |
|
| En sökväg på en offentlig http/s-server | ✓ | https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/titanic.csv |
|
| En sökväg i Azure Storage | * | wasbs://<container_name>@<account_name>.blob.core.windows.net/<path>eller abfss://<file_system>@<account_name>.dfs.core.windows.net/<path> |
|
| En sökväg i ett Azure Machine Learning-datalager | ✓ | ✓ | azureml://datastores/<data_store_name>/paths/<path> |
| En sökväg till en datatillgång | ✓ | ✓ | azureml:my_data:<version> |
* Att använda Azure Storage direkt rekommenderas inte för indata, eftersom det kan behövas extra identitetskonfiguration för att läsa data. Det är bättre att använda Azure Machine Learning-datalagersökvägar, som stöds för olika typer av pipelinejobb.
Indata- och utdatalägen för datatyp
För datatypsindata och utdata kan du välja mellan flera lägen för nedladdning, uppladdning och montering för att definiera hur beräkningsmålet kommer åt data. I följande tabell visas de lägen som stöds för olika typer av indata och utdata.
| Typ | upload |
download |
ro_mount |
rw_mount |
direct |
eval_download |
eval_mount |
|---|---|---|---|---|---|---|---|
uri_folder inmatning |
✓ | ✓ | ✓ | ||||
uri_file inmatning |
✓ | ✓ | ✓ | ||||
mltable inmatning |
✓ | ✓ | ✓ | ✓ | ✓ | ||
uri_folder utdata |
✓ | ✓ | |||||
uri_file utdata |
✓ | ✓ | |||||
mltable utdata |
✓ | ✓ | ✓ |
Lägena ro_mount eller rw_mount rekommenderas i de flesta fall. Mer information finns i Lägen.
Indata och utdata i pipelinediagram
På sidan pipelinejobb i Azure Machine Learning-studio visas komponentindata och utdata som små cirklar som kallas indata-/utdataportar. Dessa portar representerar dataflödet i pipelinen. Utdata på pipelinenivå visas i lila rutor för enkel identifiering.
Följande skärmbild från pipelinediagrammet NYC Taxi Data Regression visar många komponent- och pipelineindata och utdata.

När du hovra över en in-/utdataport visas typen.
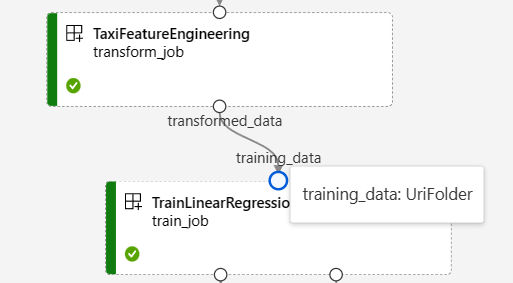
Pipelinediagrammet visar inte primitiva typindata. Dessa indata visas på fliken Inställningar i panelen för pipelinejobböversikt för indata på pipelinenivå eller komponentpanelen för indata på komponentnivå. Om du vill öppna komponentpanelen dubbelklickar du på komponenten i diagrammet.

När du redigerar en pipeline i studiodesignern finns pipelineindata och utdata i panelen Pipeline-gränssnitt , och komponentindata och utdata finns i komponentpanelen.
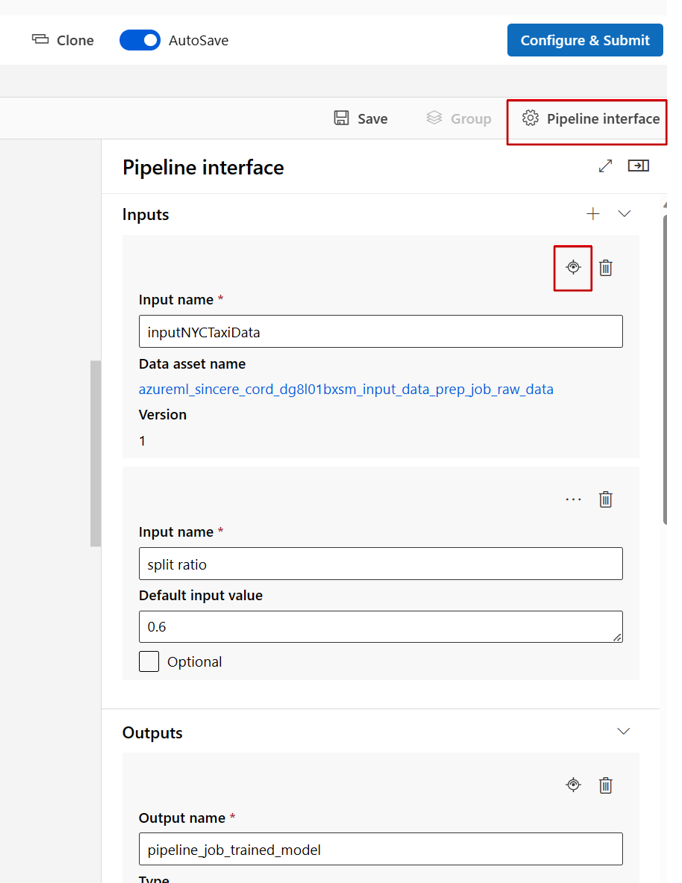
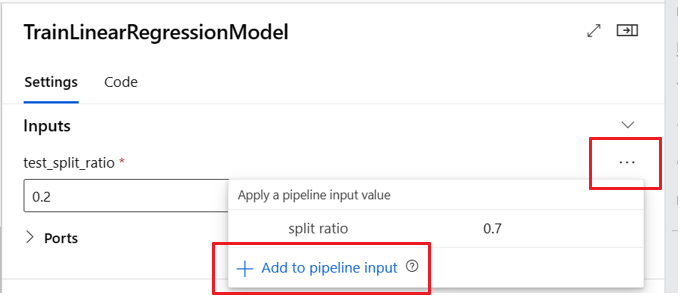
Flytta upp komponentindata/utdata till pipelinenivå
När du befordrar en komponents indata/utdata till pipelinenivån kan du skriva över komponentens indata/utdata när du skickar ett pipelinejobb. Den här möjligheten är särskilt användbar för att utlösa pipelines med hjälp av REST-slutpunkter.
I följande exempel visas hur du höjer upp indata/utdata på komponentnivå till indata/utdata på pipelinenivå.
Följande pipeline höjer upp tre indata och tre utdata till pipelinenivån. Till exempel pipeline_job_training_max_epocs är indata på pipelinenivå eftersom de deklareras under inputs avsnittet på rotnivå.
Under train_job i avsnittet jobs refereras indata med namnet max_epocs som ${{parent.inputs.pipeline_job_training_max_epocs}}, vilket innebär att train_job"s-indata max_epocs refererar till pipelinenivåindata pipeline_job_training_max_epocs . Pipelineutdata höjs upp med hjälp av samma schema.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: 1b_e2e_registered_components
description: E2E dummy train-score-eval pipeline with registered components
inputs:
pipeline_job_training_max_epocs: 20
pipeline_job_training_learning_rate: 1.8
pipeline_job_learning_rate_schedule: 'time-based'
outputs:
pipeline_job_trained_model:
mode: upload
pipeline_job_scored_data:
mode: upload
pipeline_job_evaluation_report:
mode: upload
settings:
default_compute: azureml:cpu-cluster
jobs:
train_job:
type: command
component: azureml:my_train@latest
inputs:
training_data:
type: uri_folder
path: ./data
max_epocs: ${{parent.inputs.pipeline_job_training_max_epocs}}
learning_rate: ${{parent.inputs.pipeline_job_training_learning_rate}}
learning_rate_schedule: ${{parent.inputs.pipeline_job_learning_rate_schedule}}
outputs:
model_output: ${{parent.outputs.pipeline_job_trained_model}}
services:
my_vscode:
type: vs_code
my_jupyter_lab:
type: jupyter_lab
my_tensorboard:
type: tensor_board
log_dir: "outputs/tblogs"
# my_ssh:
# type: tensor_board
# ssh_public_keys: <paste the entire pub key content>
# nodes: all # Use the `nodes` property to pick which node you want to enable interactive services on. If `nodes` are not selected, by default, interactive applications are only enabled on the head node.
score_job:
type: command
component: azureml:my_score@latest
inputs:
model_input: ${{parent.jobs.train_job.outputs.model_output}}
test_data:
type: uri_folder
path: ./data
outputs:
score_output: ${{parent.outputs.pipeline_job_scored_data}}
evaluate_job:
type: command
component: azureml:my_eval@latest
inputs:
scoring_result: ${{parent.jobs.score_job.outputs.score_output}}
outputs:
eval_output: ${{parent.outputs.pipeline_job_evaluation_report}}
Du hittar det fullständiga exemplet på pipelinen train-score-eval med registrerade komponenter i Azure Machine Learning-exempellagringsplatsen .
Definiera valfria indata
Som standard krävs alla indata och måste antingen ha ett standardvärde eller tilldelas ett värde varje gång du skickar ett pipelinejobb. Du kan dock definiera valfria indata.
Kommentar
Valfria utdata stöds inte.
Det kan vara användbart att ange valfria indata i två scenarier:
Om du definierar en valfri indata för data/modelltyp och inte tilldelar ett värde till den när du skickar pipelinejobbet, saknar pipelinekomponenten det databeroendet. Om komponentens indataport inte är länkad till någon komponent eller data/modellnod anropar pipelinen komponenten direkt i stället för att vänta på ett tidigare beroende.
Om du anger
continue_on_step_failure = Trueför pipelinen mennode2använder nödvändiga indata frånnode1,node2körs inte omnode1det misslyckas. Omnode1indata är valfrianode2körs även omnode1det misslyckas. Följande diagram visar det här scenariot.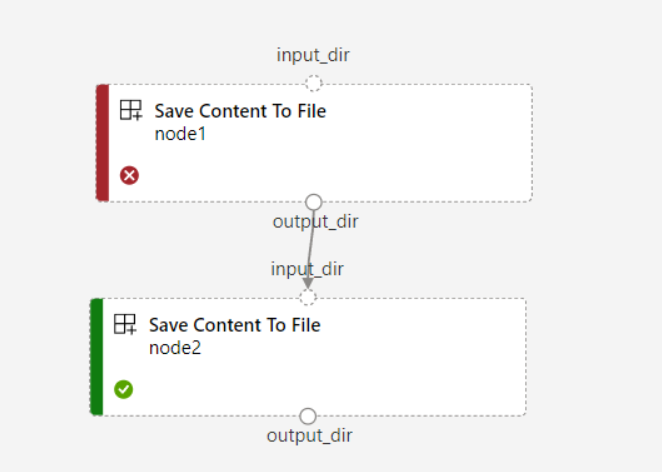
I följande kodexempel visas hur du definierar valfria indata. När indata anges som optional = truemåste du använda $[[]] för att använda kommandoradsindata, som i de markerade raderna i exemplet.
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_data_component_cli
display_name: train_data
description: A example train component
tags:
author: azureml-sdk-team
type: command
inputs:
training_data:
type: uri_folder
max_epocs:
type: integer
optional: true
learning_rate:
type: number
default: 0.01
optional: true
learning_rate_schedule:
type: string
default: time-based
optional: true
outputs:
model_output:
type: uri_folder
code: ./train_src
environment: azureml://registries/azureml/environments/sklearn-1.5/labels/latest
command: >-
python train.py
--training_data ${{inputs.training_data}}
$[[--max_epocs ${{inputs.max_epocs}}]]
$[[--learning_rate ${{inputs.learning_rate}}]]
$[[--learning_rate_schedule ${{inputs.learning_rate_schedule}}]]
--model_output ${{outputs.model_output}}

Anpassa utdatasökvägar
Som standard lagras komponentutdata i den {default_datastore} du anger för pipelinen, azureml://datastores/${{default_datastore}}/paths/${{name}}/${{output_name}}. Om den inte har angetts är standardinställningen bloblagring för arbetsytor.
Jobbet {name} löses vid jobbkörningen och {output_name} är det namn som du definierade i komponenten YAML. Du kan anpassa var utdata ska lagras genom att definiera en utdatasökväg.
Den pipeline.yml filen vid train-score-eval-pipelinen med exempel på registrerade komponenter definierar en pipeline som har tre utdata på pipelinenivå. Du kan använda följande kommando för att ange anpassade utdatasökvägar för pipeline_job_trained_model utdata.
# define the custom output path using datastore uri
# add relative path to your blob container after "azureml://datastores/<datastore_name>/paths"
output_path="azureml://datastores/{datastore_name}/paths/{relative_path_of_container}"
# create job and define path using --outputs.<outputname>
az ml job create -f ./pipeline.yml --set outputs.pipeline_job_trained_model.path=$output_path

Ladda ned utdata
Du kan ladda ned utdata på pipeline- eller komponentnivå.
Ladda ned utdata på pipelinenivå
Du kan ladda ned alla utdata från ett jobb eller ladda ned en specifik utdata.
# Download all the outputs of the job
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
# Download a specific output
az ml job download --output-name <OUTPUT_PORT_NAME> -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>

Ladda ned komponentutdata
Om du vill ladda ned utdata från en underordnad komponent anger du först alla underordnade jobb för ett pipelinejobb och använder sedan liknande kod för att ladda ned utdata.
# List all child jobs in the job and print job details in table format
az ml job list --parent-job-name <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID> -o table
# Select the desired child job name to download output
az ml job download --all -n <JOB_NAME> -g <RESOURCE_GROUP_NAME> -w <WORKSPACE_NAME> --subscription <SUBSCRIPTION_ID>
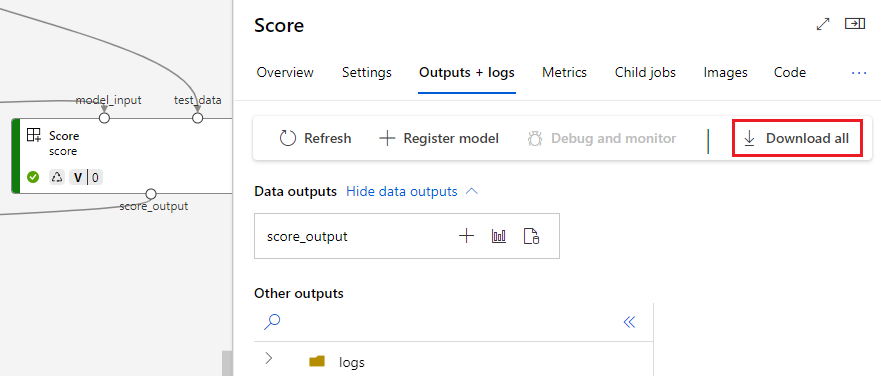
Registrera utdata som en namngiven tillgång
Du kan registrera utdata för en komponent eller pipeline som en namngiven tillgång genom att tilldela en name och version till utdata. Den registrerade tillgången kan visas i din arbetsyta via studiogränssnittet, CLI eller SDK och kan refereras till i framtida arbetsytejobb.
Registrera utdata på pipelinenivå
display_name: register_pipeline_output
type: pipeline
jobs:
node:
type: command
inputs:
component_in_path:
type: uri_file
path: https://dprepdata.blob.core.windows.net/demo/Titanic.csv
component: ../components/helloworld_component.yml
outputs:
component_out_path: ${{parent.outputs.component_out_path}}
outputs:
component_out_path:
type: mltable
name: pipeline_output # Define name and version to register pipeline output
version: '1'
settings:
default_compute: azureml:cpu-cluster
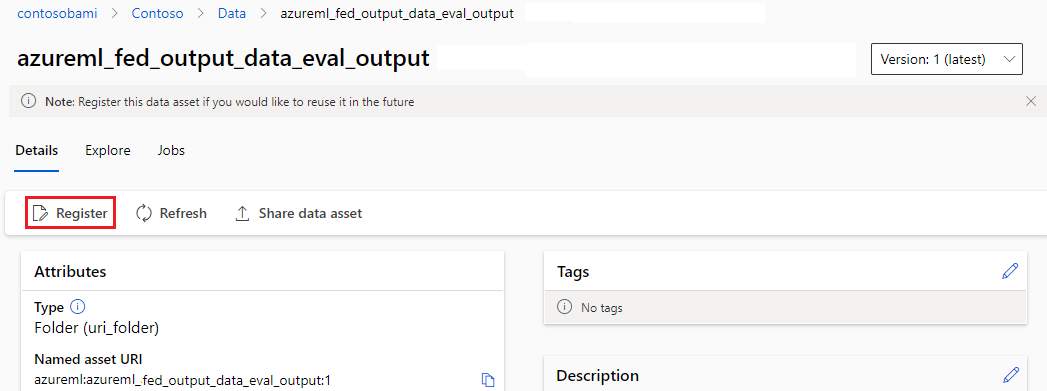
Registrera komponentutdata
display_name: register_node_output
type: pipeline
jobs:
node:
type: command
component: ../components/helloworld_component.yml
inputs:
component_in_path:
type: uri_file
path: 'https://dprepdata.blob.core.windows.net/demo/Titanic.csv'
outputs:
component_out_path:
type: uri_folder
name: 'node_output' # Define name and version to register a child job's output
version: '1'
settings:
default_compute: azureml:cpu-cluster