Kapacitetsplanering för HDInsight-kluster
Innan du distribuerar ett HDInsight-kluster ska du planera för den avsedda klusterkapaciteten genom att fastställa vilken prestanda och skalning som krävs. Den här planeringen hjälper till att optimera både användbarhet och kostnader. Vissa beslut om klusterkapacitet kan inte ändras efter distributionen. Om prestandaparametrarna ändras kan ett kluster demonteras och återskapas utan att lagrade data förloras.
De viktigaste frågorna att ställa för kapacitetsplanering är:
- I vilken geografisk region ska du distribuera klustret?
- Hur mycket lagringsutrymme behöver du?
- Vilken klustertyp ska du distribuera?
- Vilken storlek och typ av virtuell dator ska klusternoderna använda?
- Hur många arbetsnoder ska klustret ha?
Välj en Azure-region
Azure-regionen avgör var klustret är fysiskt etablerat. För att minimera svarstiden för läsningar och skrivningar bör klustret vara nära dina data.
HDInsight är tillgängligt i många Azure-regioner. Information om hur du hittar den närmaste regionen finns i Produkter tillgängliga per region.
Välj lagringsplats och storlek
Plats för standardlagring
Standardlagringen, antingen ett Azure Storage-konto eller Azure Data Lake Storage, måste finnas på samma plats som klustret. Azure Storage är tillgängligt på alla platser. Data Lake Storage är tillgängligt i vissa regioner – se aktuell Data Lake Storage-tillgänglighet.
Plats för befintliga data
Om du vill använda ett befintligt lagringskonto eller Data Lake Storage som standardlagring för klustret måste du distribuera klustret på samma plats.
Lagringsstorlek
I ett distribuerat kluster kan du koppla ett annat Azure Storage-konton eller komma åt andra Data Lake Storage. Alla dina lagringskonton måste finnas på samma plats som klustret. En Data Lake Storage kan finnas på en annan plats, även om långa avstånd kan medföra viss fördröjning.
Azure Storage har vissa kapacitetsbegränsningar, medan Data Lake Storage är nästan obegränsat. Ett kluster kan komma åt en kombination av olika lagringskonton. Vanliga exempel är:
- När mängden data sannolikt kommer att överskrida lagringskapaciteten för en enda bloblagringscontainer.
- När åtkomsthastigheten till blobcontainern kan överskrida tröskelvärdet där begränsning sker.
- När du vill göra data har du redan laddat upp till en blobcontainer som är tillgänglig för klustret.
- När du vill isolera olika delar av lagringen av säkerhetsskäl eller för att förenkla administrationen.
För bättre prestanda använder du bara en container per lagringskonto.
Välj en klustertyp
Klustertypen avgör vilken arbetsbelastning ditt HDInsight-kluster är konfigurerat att köra. Typerna är Apache Hadoop, Apache Kafka eller Apache Spark. En detaljerad beskrivning av tillgängliga klustertyper finns i Introduktion till Azure HDInsight. Varje klustertyp har en specifik distributionstopologi som innehåller krav på storlek och antal noder.
Välj vm-storlek och typ
Varje klustertyp har en uppsättning nodtyper och varje nodtyp har specifika alternativ för deras VM-storlek och typ.
För att fastställa den optimala klusterstorleken för ditt program kan du jämföra klusterkapaciteten och öka storleken enligt angivet. Du kan till exempel använda en simulerad arbetsbelastning eller en kanariefråga. Kör dina simulerade arbetsbelastningar i olika storlekskluster. Öka storleken gradvis tills den avsedda prestandan uppnås. En kanariefråga kan infogas regelbundet bland de andra produktionsfrågorna för att visa om klustret har tillräckligt med resurser.
Mer information om hur du väljer rätt VM-familj för din arbetsbelastning finns i Välja rätt VM-storlek för klustret.
Välj klusterskala
Ett klusters skala bestäms av mängden av dess VM-noder. För alla klustertyper finns det nodtyper som har en specifik skalning och nodtyper som stöder utskalning. Ett kluster kan till exempel kräva exakt tre Apache ZooKeeper-noder eller två huvudnoder. Arbetsnoder som utför databearbetning på ett distribuerat sätt drar nytta av en annan arbetsnod.
Beroende på klustertyp ökar antalet arbetsnoder mer beräkningskapacitet (till exempel fler kärnor). Fler noder ökar det totala minne som krävs för hela klustret för att stödja minnesintern lagring av data som bearbetas. Precis som med valet av VM-storlek och typ uppnås vanligtvis val av rätt klusterskala empiriskt. Använd simulerade arbetsbelastningar eller kanariefrågor.
Du kan skala ut klustret för att uppfylla belastningstopparna. Skala sedan ned den igen när de extra noderna inte längre behövs. Med funktionen Autoskalning kan du automatiskt skala klustret baserat på förutbestämda mått och tidsinställningar. Mer information om hur du skalar dina kluster manuellt finns i Skala HDInsight-kluster.
Klusterlivscykel
Du debiteras för ett klusters livslängd. Om det bara finns specifika tider som du behöver klustret skapar du kluster på begäran med Hjälp av Azure Data Factory. Du kan också skapa PowerShell-skript som etablerar och tar bort klustret och sedan schemalägger skripten med Hjälp av Azure Automation.
Kommentar
När ett kluster tas bort tas även standardmetaarkivet hive bort. Om du vill spara metaarkivet för nästa kluster som återskapas använder du ett externt metadatalager som Azure Database eller Apache Oozie.
Isolera klusterjobbsfel
Ibland kan fel uppstå på grund av parallell körning av flera kartor och minska komponenter i ett kluster med flera noder. Prova distribuerad testning för att isolera problemet. Kör flera samtidiga jobb i ett enda arbetsnodkluster. Expandera sedan den här metoden för att köra flera jobb samtidigt i kluster som innehåller mer än en nod. Om du vill skapa ett HDInsight-kluster med en nod i Azure använder du Custom(size, settings, apps) alternativet och använder värdet 1 för Antal arbetsnoder i avsnittet Klusterstorlek när du etablerar ett nytt kluster i portalen.
Visa kvothantering för HDInsight
Visa en detaljerad nivå och kategorisering av kvoten på vm-familjenivå. Visa den aktuella kvoten och hur mycket kvot som återstår för en region på vm-familjenivå.
Kommentar
Den här funktionen är för närvarande tillgänglig i HDInsight 4.x och 5.x för EUAP-regionen USA, östra. Andra regioner att följa därefter.
Visa aktuell kvot:
Se den aktuella kvoten och hur mycket kvot som återstår för en region på vm-familjenivå.
I det övre sökfältet i Azure-portalen söker du efter och väljer Kvoter.
På sidan Kvot väljer du Azure HDInsight
I listrutan väljer du din prenumeration och region
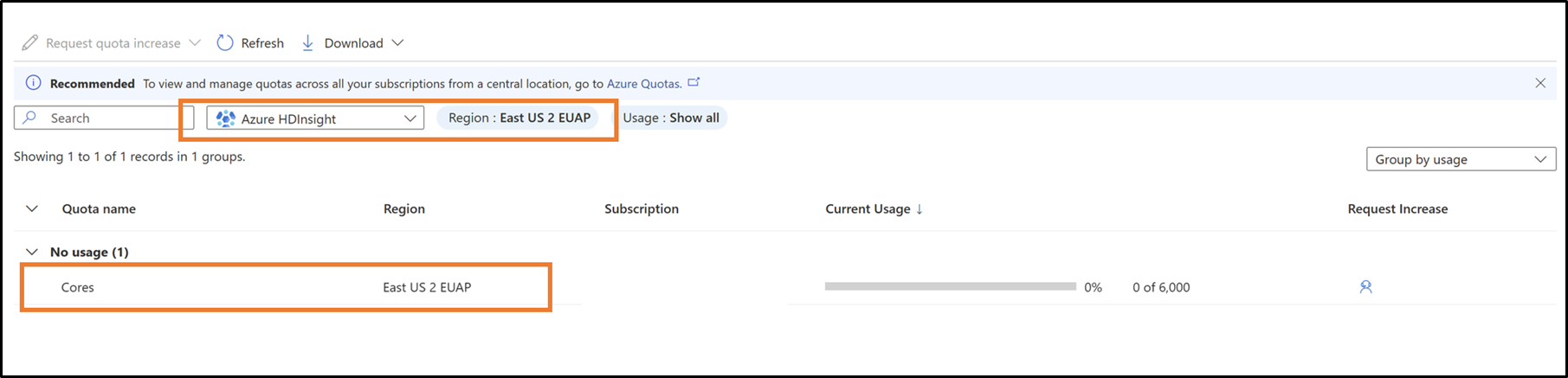

Begär nya kvoter per VM-familj och region
- Klicka på den rad som du vill visa kvotinformationen för.
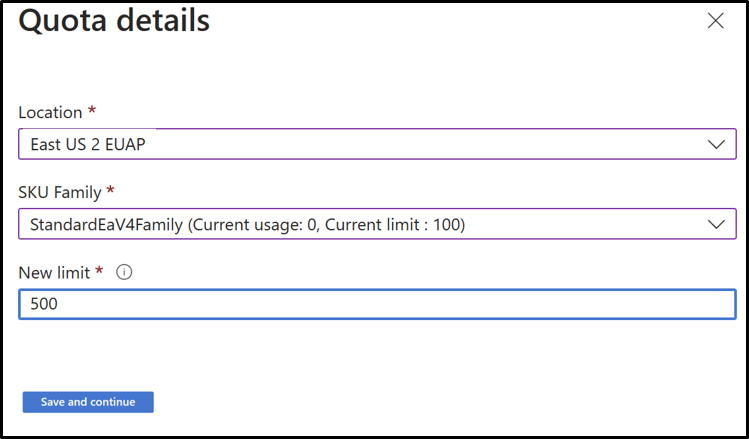




Säljbudgetar
Mer information om hur du hanterar prenumerationskvoter finns i Begära kvotökningar.
Nästa steg
- Konfigurera kluster i HDInsight med Apache Hadoop, Spark, Kafka med mera: Lär dig hur du konfigurerar kluster i HDInsight.
- Övervaka klusterprestanda: Lär dig mer om viktiga scenarier att övervaka för ditt HDInsight-kluster som kan påverka klustrets kapacitet.