Övervaka klusterprestanda i Azure HDInsight
Det är viktigt att övervaka hälsotillståndet och prestandan för ett HDInsight-kluster för att upprätthålla optimal prestanda och resursanvändning. Övervakning kan också hjälpa dig att identifiera och åtgärda klusterkonfigurationsfel och problem med användarkod.
I följande avsnitt beskrivs hur du övervakar och optimerar belastningen på dina kluster, Apache Hadoop YARN-köer och identifierar problem med lagringsbegränsning.
Övervaka klusterbelastning
Hadoop-kluster kan ge bästa möjliga prestanda när belastningen på klustret är jämnt fördelad över alla noder. Detta gör att bearbetningsuppgifterna kan köras utan att begränsas av RAM-, CPU- eller diskresurser på enskilda noder.
Om du vill få en övergripande titt på noderna i klustret och deras inläsning loggar du in på webbgränssnittet för Ambari och väljer sedan fliken Värdar. Dina värdar listas med sina fullständigt kvalificerade domännamn. Varje värds driftstatus visas med en färgad hälsoindikator:
| Färg | beskrivning |
|---|---|
| Röd | Minst en huvudkomponent på värden är nere. Hovra om du vill se en knappbeskrivning som visar de komponenter som påverkas. |
| Orange | Minst en sekundär komponent på värden är nere. Hovra om du vill se en knappbeskrivning som visar de komponenter som påverkas. |
| Gul | Ambari Server har inte fått pulsslag från värden på mer än 3 minuter. |
| Grönt | Normalt körningstillstånd. |
Du ser också kolumner som visar antalet kärnor och mängden RAM-minne för varje värd, samt diskanvändningen och belastningsgenomsnittet.
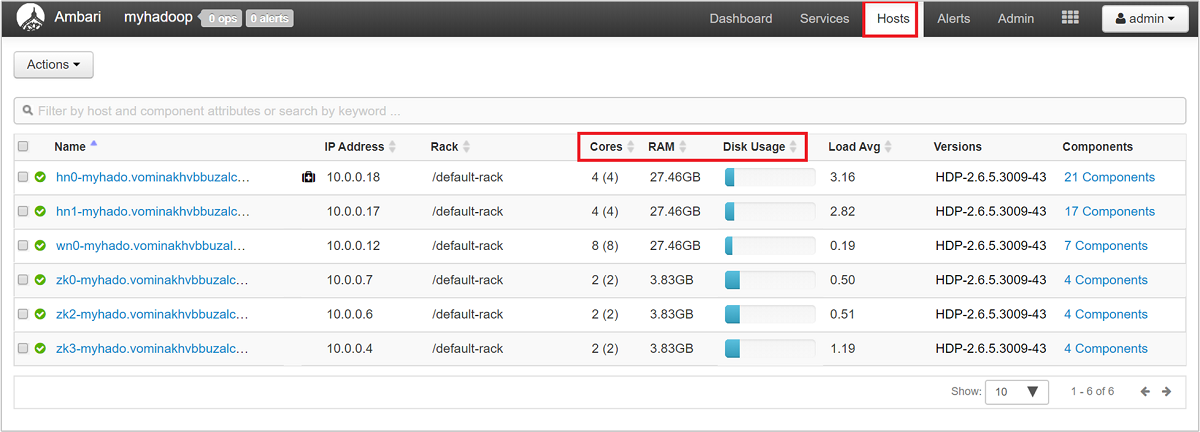
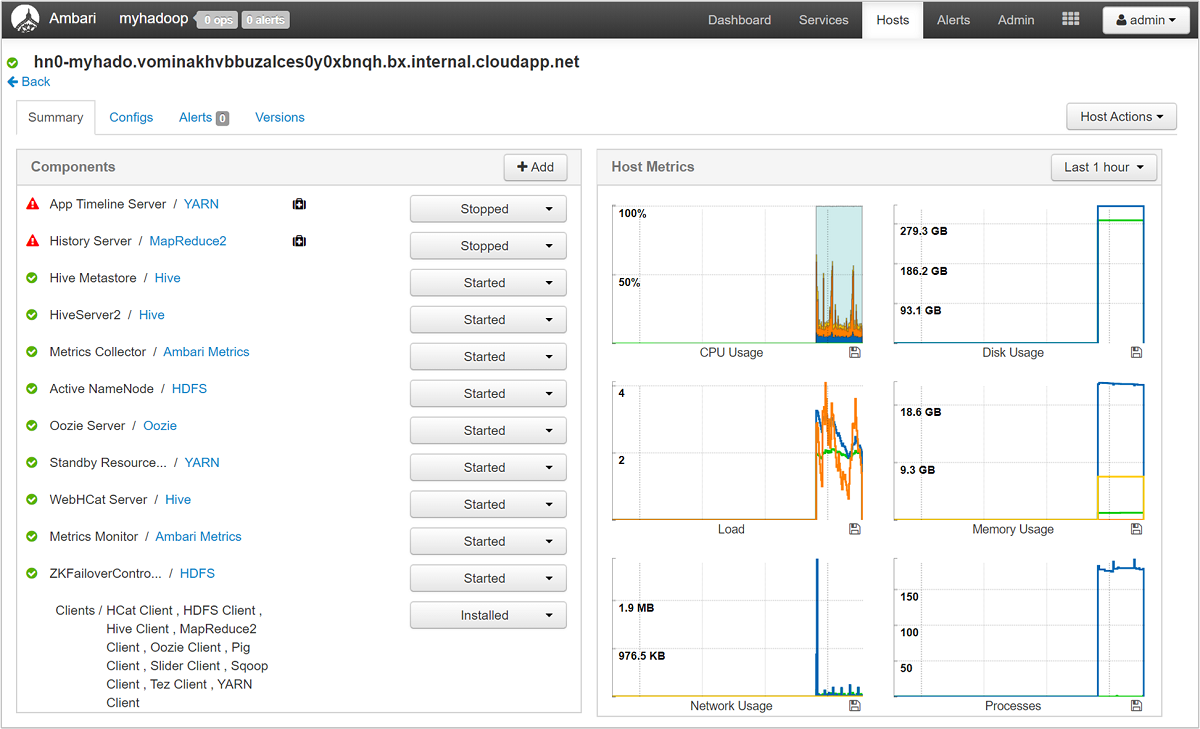
Välj något av värdnamnen för en detaljerad titt på komponenter som körs på värden och deras mått. Måtten visas som en valbar tidslinje för CPU-användning, belastning, diskanvändning, minnesanvändning, nätverksanvändning och antal processer.
YARN-kökonfiguration
Hadoop har olika tjänster som körs på den distribuerade plattformen. YARN (Ännu en resursförhandlare) samordnar dessa tjänster och allokerar klusterresurser för att säkerställa att all belastning fördelas jämnt över klustret.
YARN delar upp de två ansvarsområdena för JobTracker, resurshantering och schemaläggning/övervakning av jobb, i två daemoner: en global Resource Manager och en ApplicationMaster per program (AM).
Resource Manager är en ren schemaläggare och godtyckligt tillgängliga resurser mellan alla konkurrerande program. Resource Manager säkerställer att alla resurser alltid används och optimerar för olika konstanter som serviceavtal, kapacitetsgarantier och så vidare. ApplicationMaster förhandlar om resurser från Resource Manager och arbetar med NodeManager(er) för att köra och övervaka containrarna och deras resursförbrukning.
När flera klienter delar ett stort kluster finns det konkurrens om klustrets resurser. CapacityScheduler är en schemaläggare som kan anslutas och som hjälper till med resursdelning genom att köa begäranden. CapacityScheduler stöder också hierarkiska köer för att säkerställa att resurser delas mellan underfrågorna i en organisation, innan andra programköer tillåts använda kostnadsfria resurser.
YARN gör att vi kan allokera resurser till dessa köer och visar dig om alla tillgängliga resurser har tilldelats. Om du vill visa information om dina köer loggar du in på webbgränssnittet för Ambari och väljer sedan YARN Queue Manager på den översta menyn.
Sidan YARN Queue Manager visar en lista över dina köer till vänster, tillsammans med procentandelen kapacitet som tilldelats var och en.
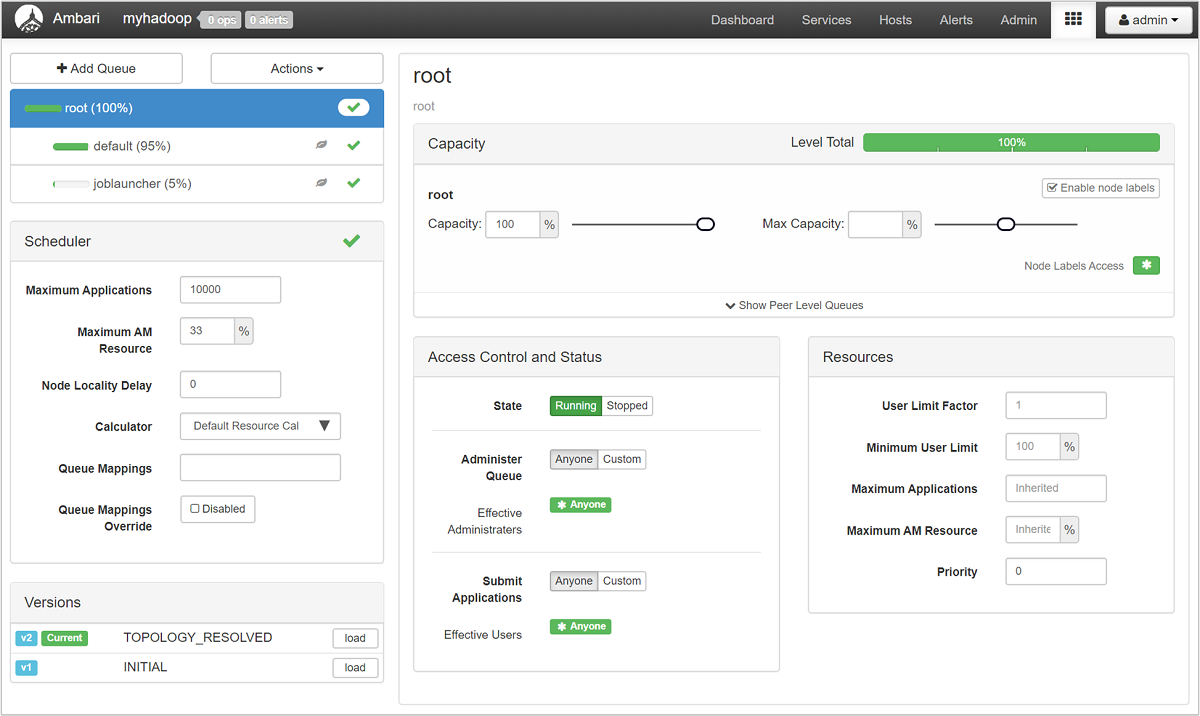
Om du vill ha en mer detaljerad titt på dina köer väljer du YARN-tjänsten från listan till vänster från instrumentpanelen Ambari. Under listrutan Snabblänkar väljer du sedan Resource Manager-användargränssnittet under den aktiva noden.
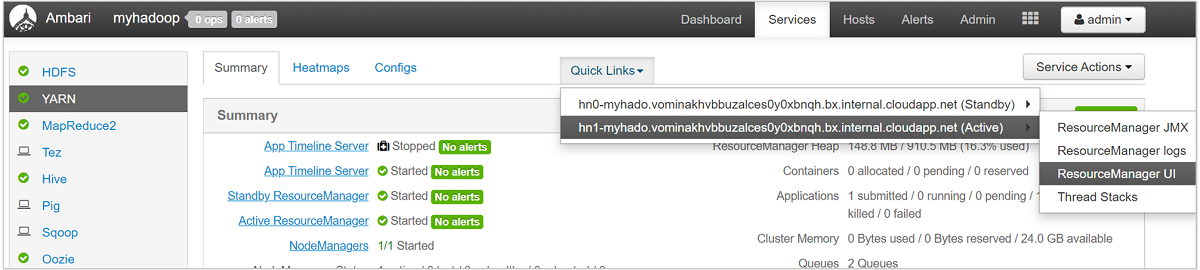
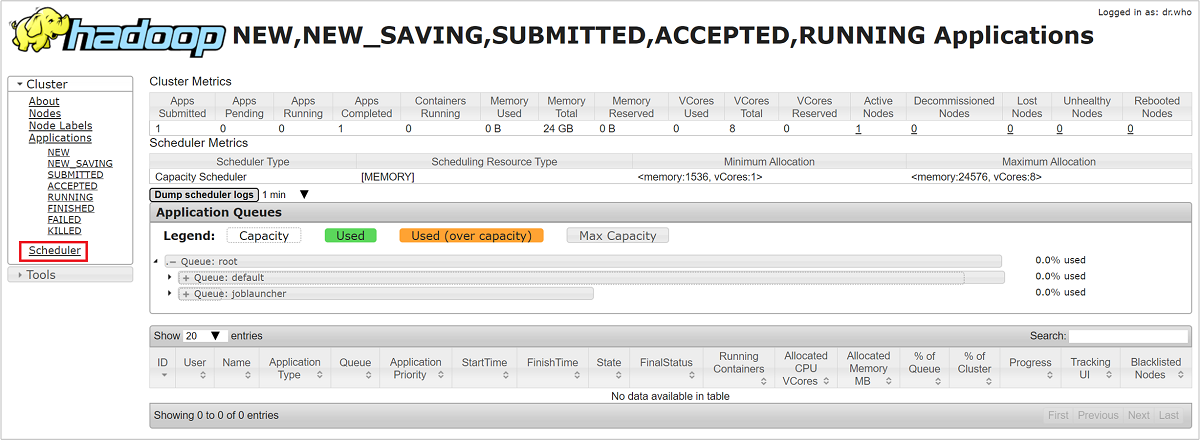
I Användargränssnittet för Resource Manager väljer du Scheduler på den vänstra menyn. Du ser en lista över dina köer under programköer. Här kan du se den kapacitet som används för var och en av dina köer, hur väl jobben fördelas mellan dem och om några jobb är resursbegränsade.
Lagringsbegränsning
Ett klusters prestandaflaskhals kan inträffa på lagringsnivå. Den här typen av flaskhals beror oftast på blockering av indata-/utdataåtgärder (I/O), vilket inträffar när dina aktiviteter som körs skickar mer I/O än vad lagringstjänsten kan hantera. Den här blockeringen skapar en kö med I/O-begäranden som väntar på att bearbetas tills de aktuella IO:erna har bearbetats. Blocken beror på lagringsbegränsning, vilket inte är en fysisk gräns, utan snarare på en gräns som har införts av lagringstjänsten enligt ett serviceavtal (SLA). Den här gränsen säkerställer att ingen enskild klient eller klientorganisation kan monopolisera tjänsten. Serviceavtalet begränsar antalet IOPS per sekund (IOPS) för Azure Storage – mer information finns i Skalbarhets- och prestandamål för standardlagringskonton.
Om du använder Azure Storage finns information om övervakning av lagringsrelaterade problem, inklusive begränsning, i Övervaka, diagnostisera och felsöka Microsoft Azure Storage.
Om ditt klusters lagringsplats är Azure Data Lake Storage (ADLS) beror begränsningen troligen på bandbreddsbegränsningar. Begränsningar i det här fallet kan identifieras genom att observera begränsningsfel i aktivitetsloggar. För ADLS, se avsnittet begränsning för lämplig tjänst i dessa artiklar:
- Vägledning för prestandajustering för Apache Hive i HDInsight och Azure Data Lake Storage
- Vägledning för prestandajustering för MapReduce i HDInsight och Azure Data Lake Storage
Felsöka långsamma nodprestanda
I vissa fall kan det gå långsammare på grund av att det finns för lite diskutrymme i klustret. Undersök med följande steg:
Använd ssh-kommandot för att ansluta till var och en av noderna.
Kontrollera diskanvändningen genom att köra något av följande kommandon:
df -h du -h --max-depth=1 / | sort -hGranska utdata och kontrollera om det finns stora filer i
mntmappen eller andra mappar. Vanligtvis innehåller mapparnausercache, ochappcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) stora filer.Om det finns stora filer kan antingen ett aktuellt jobb orsaka filtillväxt eller ett misslyckat tidigare jobb kan ha bidragit till det här problemet. Du kan kontrollera om problemet beror på ett pågående jobb genom att köra följande kommando:
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/Om det här kommandot anger ett specifikt jobb kan du välja att avsluta jobbet genom att köra följande eller ett liknande kommando:
yarn application -kill -applicationId <application_id>Ersätt
application_idmed program-ID:t. Om inga specifika jobb anges går du till nästa steg.När kommandot ovan har slutförts, eller om inga specifika jobb anges, tar du bort de stora filer som du har identifierat genom att köra ett kommando som liknar följande:
rm -rf filecache usercache
Mer information om diskutrymmesproblem finns i Slut på diskutrymme.
Kommentar
Om du har stora filer som du vill behålla men bidrar till problemet med lågt diskutrymme måste du skala upp HDInsight-klustret och starta om dina tjänster. När du har slutfört den här proceduren och väntat i några minuter kommer du att märka att lagringen frigörs och att nodens vanliga prestanda återställs.
Nästa steg
Gå till följande länkar för mer information om felsökning och övervakning av dina kluster: