Skicka och hantera jobb i ett Apache Spark-kluster™ i HDInsight på AKS
Viktig
Azure HDInsight på AKS drogs tillbaka den 31 januari 2025. Läs mer med det här meddelandet.
Du måste migrera dina arbetsbelastningar till Microsoft Fabric- eller en motsvarande Azure-produkt för att undvika plötsliga uppsägningar av dina arbetsbelastningar.
Viktig
Den här funktionen är för närvarande i förhandsversion. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för Azure-funktioner som är i betaversion, förhandsversion eller på annat sätt ännu inte är allmänt tillgängliga. Information om den här specifika förhandsversionen finns i Azure HDInsight på AKS-förhandsversionsinformation. För frågor eller funktionsförslag, vänligen skicka en begäran på AskHDInsight med detaljerna och följ oss för fler uppdateringar om Azure HDInsight Community.
När klustret har skapats kan användaren använda olika gränssnitt för att skicka och hantera jobb genom att
- använda Jupyter
- använda Zeppelin
- använda ssh (spark-submit)
Att använda Jupyter
Förutsättningar
Ett Apache Spark-kluster™ i HDInsight på AKS. Mer information finns i Skapa ett Apache Spark-kluster.
Jupyter Notebook är en interaktiv notebook-miljö som stöder olika programmeringsspråk.
Skapa en Jupyter Notebook
Gå till apache Spark-klustersidan™ och öppna fliken Översikt. Klicka på Jupyter, den ber dig att autentisera och öppna Jupyter-webbsidan.

På Jupyter-webbsidan väljer du Ny > PySpark för att skapa en notebook-fil.
En ny notebook-fil har skapats och öppnats med namnet
Untitled(Untitled.ipynb).Anteckning
Genom att använda PySpark eller Python 3-kerneln för att skapa en notebook-fil skapas spark-sessionen automatiskt åt dig när du kör den första kodcellen. Du behöver inte uttryckligen skapa sessionen.
Klistra in följande kod i en tom cell i Jupyter Notebook och tryck sedan på SKIFT + RETUR för att köra koden. Se här för fler kontroller på Jupyter.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Rita ett diagram med Lön och ålder som X- och Y-axlarna
I samma notebook-fil klistrar du in följande kod i en tom cell i Jupyter Notebook och trycker sedan på SKIFT + RETUR för att köra koden.
%matplotlib inline import pandas as pd import matplotlib.pyplot as plt plt.plot(age_series,salary_series) plt.show()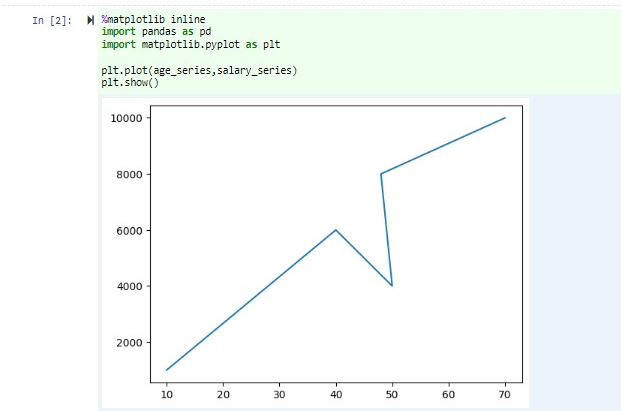




Spara anteckningsboken
Gå från menyraden för notebooken till Arkiv > Spara och Kontrollpunkt.
Stäng anteckningsboken för att frigöra klusterresurserna: gå till Arkiv > Stäng och Stoppa från menyraden för notebook-filer. Du kan också köra någon av notebook-filerna under exempelmappen.


Använda Apache Zeppelin-anteckningsböcker
Apache Spark-kluster i HDInsight på AKS inkluderar Apache Zeppelin-notebooks. Använd notebook-filerna för att köra Apache Spark-jobb. I den här artikeln får du lära dig hur du använder Zeppelin-notebooken i en HDInsight på ett AKS-kluster.
Förutsättningar
Ett Apache Spark-kluster i HDInsight på AKS. Anvisningar finns i Skapa ett Apache Spark-kluster.
Starta en Apache Zeppelin-anteckningsbok
Gå till översiktssidan för Apache Spark-klustret och välj Zeppelin notebook från klusterpaneler. Den uppmanar till att autentisera och öppna Zeppelin-sidan.
Skapa en ny notebook-fil. Gå till Notebook > Skapa ny anteckning i rubrikfönstret. Kontrollera att anteckningsbokens huvud visar att den är ansluten. Den anger en grön punkt i det övre högra hörnet.
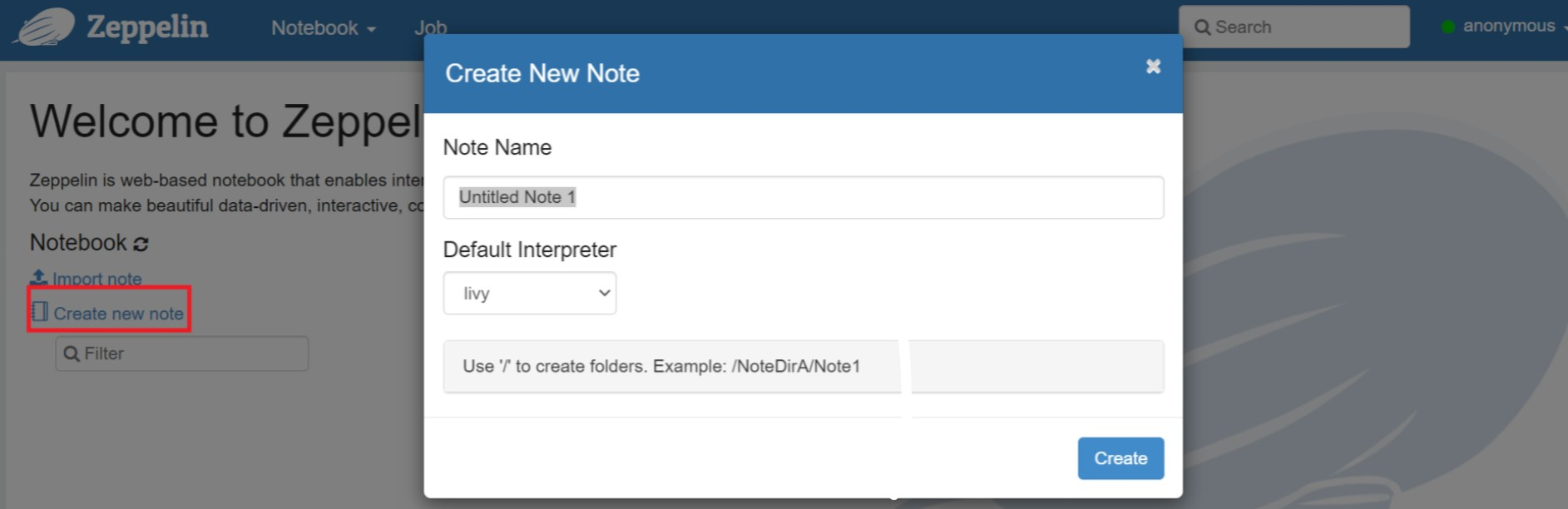
Kör följande kod i Zeppelin Notebook:
%livy.pyspark import pandas as pd import matplotlib.pyplot as plt data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Välj knappen Spela upp för stycket för att köra kodfragmentet. Statusen till höger i stycket ska gå från KLAR, VÄNTAR, KÖRS till KLAR. Utdata visas längst ned i samma stycke. Skärmbilden ser ut som följande bild:
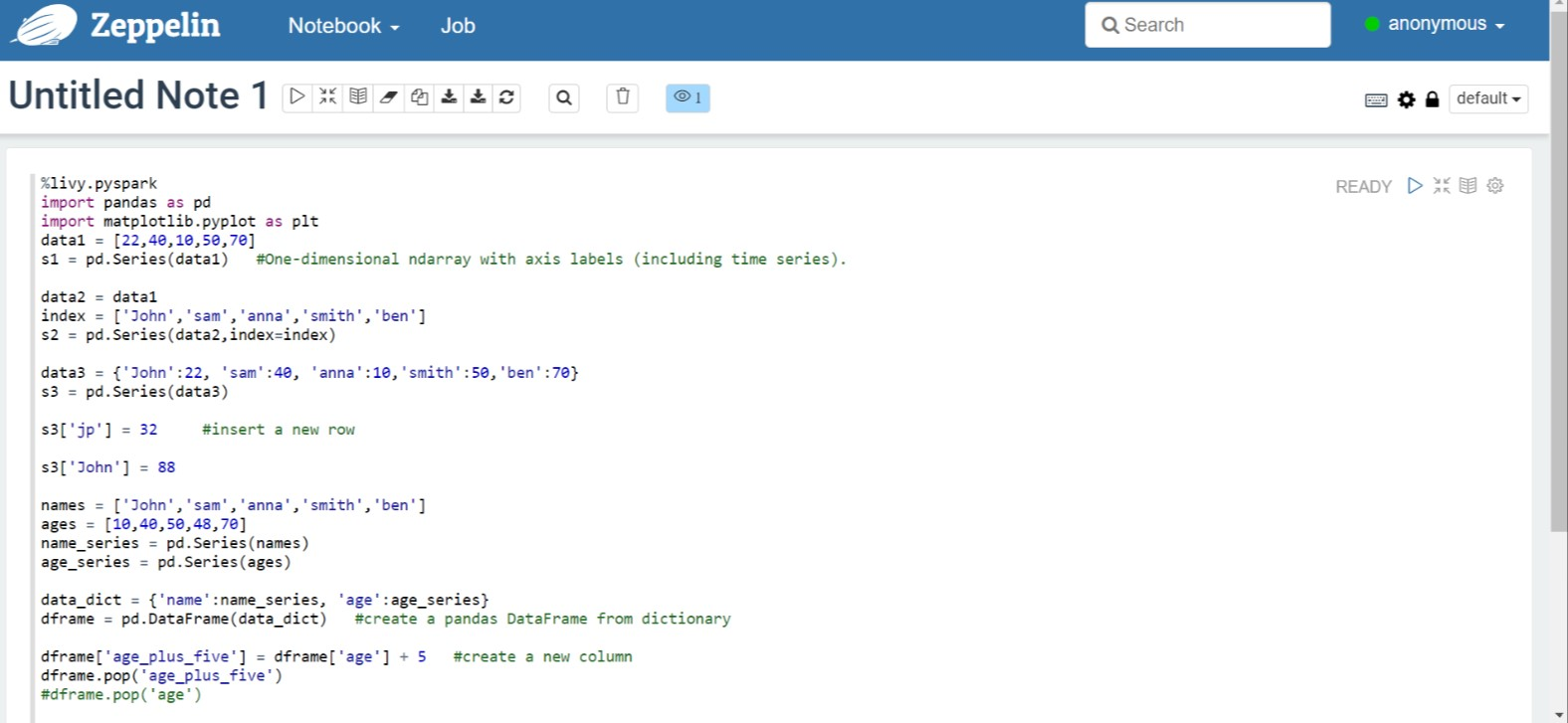
Utdata:





Använda Spark-skicka jobb
Skapa en fil med hjälp av följande kommando "#vim samplefile.py"
Det här kommandot öppnar vim-filen
Klistra in följande kod i vim-filen
import pandas as pd import matplotlib.pyplot as plt From pyspark.sql import SparkSession Spark = SparkSession.builder.master('yarn').appName('SparkSampleCode').getOrCreate() # Initialize spark context data1 = [22,40,10,50,70] s1 = pd.Series(data1) #One-dimensional ndarray with axis labels (including time series). data2 = data1 index = ['John','sam','anna','smith','ben'] s2 = pd.Series(data2,index=index) data3 = {'John':22, 'sam':40, 'anna':10,'smith':50,'ben':70} s3 = pd.Series(data3) s3['jp'] = 32 #insert a new row s3['John'] = 88 names = ['John','sam','anna','smith','ben'] ages = [10,40,50,48,70] name_series = pd.Series(names) age_series = pd.Series(ages) data_dict = {'name':name_series, 'age':age_series} dframe = pd.DataFrame(data_dict) #create a pandas DataFrame from dictionary dframe['age_plus_five'] = dframe['age'] + 5 #create a new column dframe.pop('age_plus_five') #dframe.pop('age') salary = [1000,6000,4000,8000,10000] salary_series = pd.Series(salary) new_data_dict = {'name':name_series, 'age':age_series,'salary':salary_series} new_dframe = pd.DataFrame(new_data_dict) new_dframe['average_salary'] = new_dframe['age']*90 new_dframe.index = new_dframe['name'] print(new_dframe.loc['sam'])Spara filen med följande metod.
- Tryck på Escape-knappen
- Ange kommandot
:wq
Kör följande kommando för att köra jobbet.
/spark-submit --master yarn --deploy-mode cluster <filepath>/samplefile.py

Övervaka frågor på ett Apache Spark-kluster i HDInsight på AKS
Användargränssnitt för Spark-historik
Klicka på Användargränssnittet för Spark-historikservern från översiktsfliken.

Välj den senaste körningen från användargränssnittet med samma program-ID.
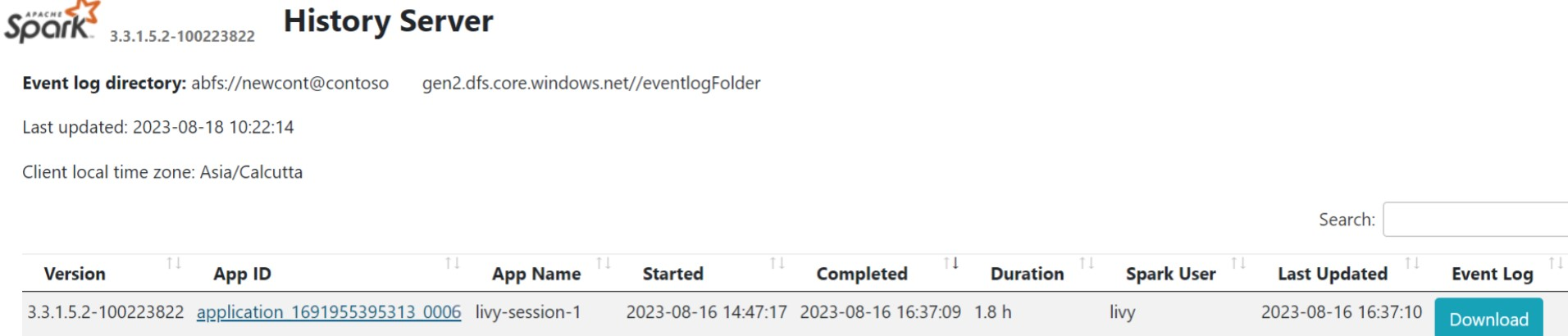
Visa de riktade Acyclic Graph-cyklerna och stegen i jobbet i Spark-historikserverns användargränssnitt.
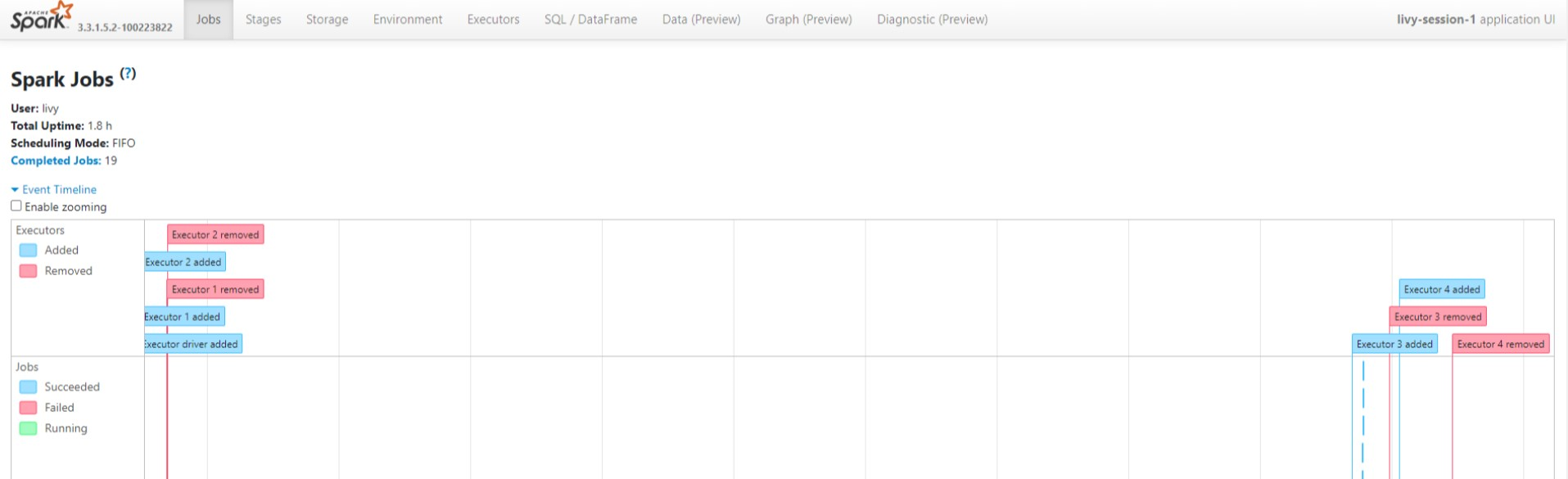



Livy-sessionsgränssnittet
Om du vill öppna användargränssnittet för Livy-sessionen skriver du följande kommando i webbläsaren
https://<CLUSTERNAME>.<CLUSTERPOOLNAME>.<REGION>.projecthilo.net/p/livy/ui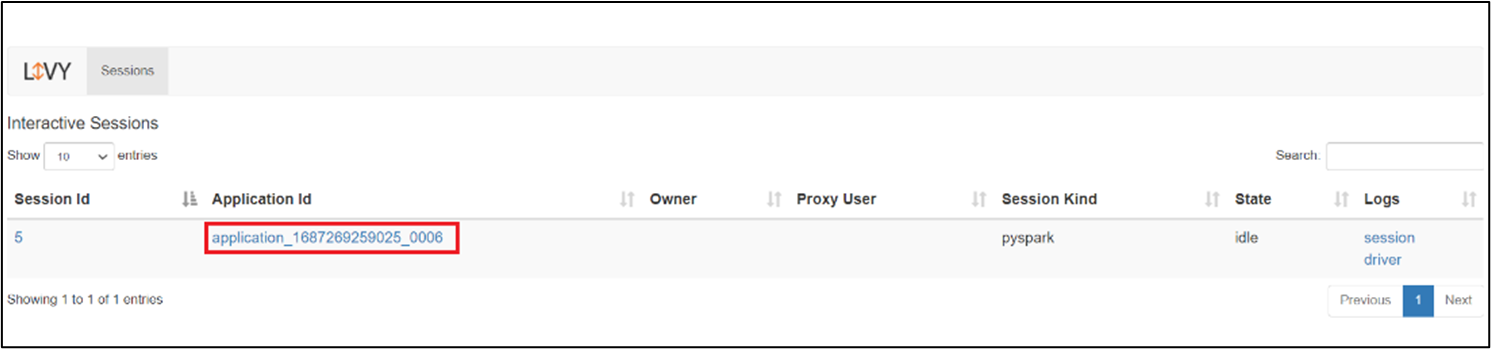
Visa drivrutinsloggarna genom att klicka på drivrutinsalternativet under loggar.

Yarn UI
På fliken Översikt klickar du på Yarn och öppnar yarn-användargränssnittet.
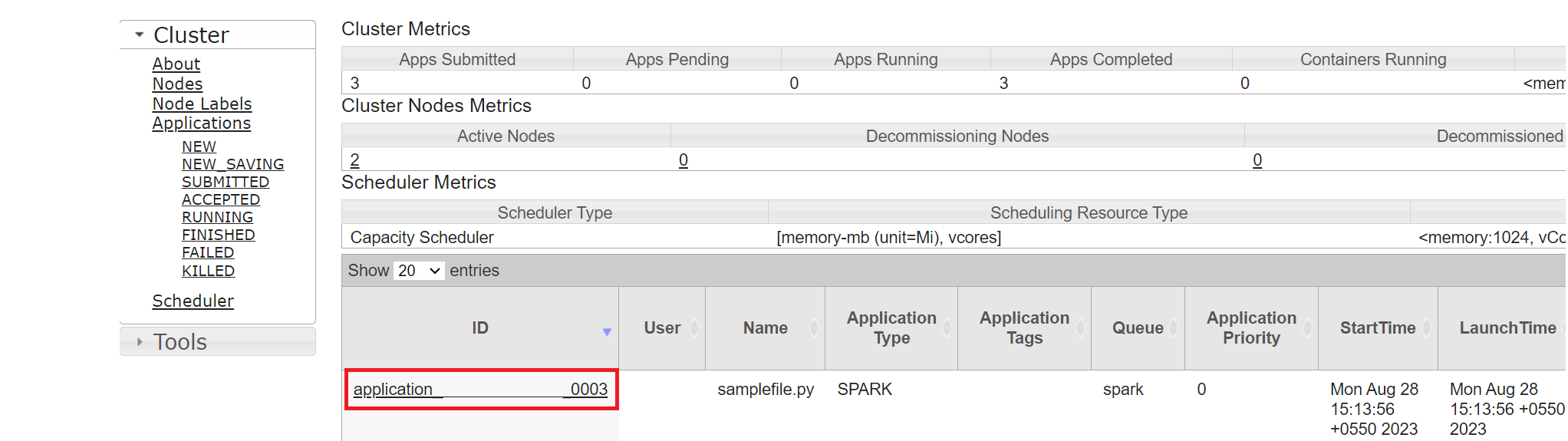
Du kan spåra jobbet som du nyligen körde med samma program-ID.
Klicka på program-ID:t i Yarn för att visa detaljerade loggar för jobbet.


Hänvisning
- Apache, Apache Spark, Spark och associerade projektnamn med öppen källkod är varumärken av Apache Software Foundation (ASF).