Skapa Spark-kluster i HDInsight på AKS (förhandsversion)
Viktig
Azure HDInsight på AKS drogs tillbaka den 31 januari 2025. Lär dig mer genom det här meddelandet.
Du måste migrera dina arbetsbelastningar till Microsoft Fabric- eller en motsvarande Azure-produkt för att undvika plötsliga uppsägningar av dina arbetsbelastningar.
Viktig
Den här funktionen är för närvarande i förhandsversion. De kompletterande användningsvillkoren för Förhandsversioner av Microsoft Azure innehåller fler juridiska villkor som gäller för Azure-funktioner som är i betaversion, förhandsversion eller på annat sätt ännu inte har släppts i allmän tillgänglighet. Information om den här specifika förhandsversionen finns i Azure HDInsight på AKS-förhandsversionsinformation. För frågor eller funktionsförslag, skicka en begäran på AskHDInsight med detaljerna och följ oss för fler uppdateringar i Azure HDInsight Community.
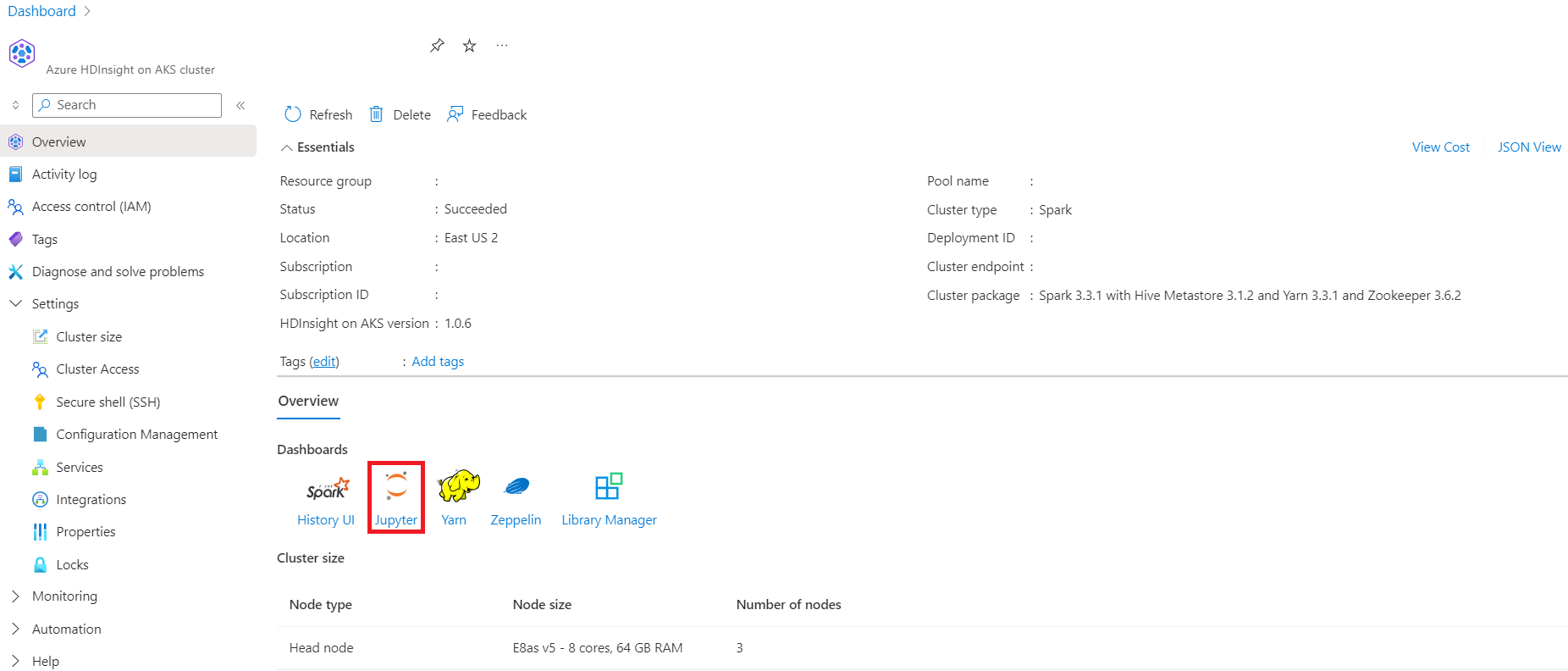
När prenumerationskrav och resurskrav steg har slutförts och du har distribuerat en klusterpool fortsätter du att använda Azure-portalen för att skapa ett Spark-kluster. Du kan använda Azure-portalen för att skapa ett Apache Spark-kluster i klusterpoolen. Du kan sedan skapa en Jupyter Notebook och använda den för att köra Spark SQL-frågor mot Apache Hive-tabeller.
I Azure-portalen skriver du klusterpooler och väljer klusterpooler för att gå till sidan klusterpooler. På sidan klusterpooler väljer du den klusterpool där du kan lägga till ett nytt Spark-kluster.
På sidan för den specifika klusterpoolen klickar du på + Nytt kluster.
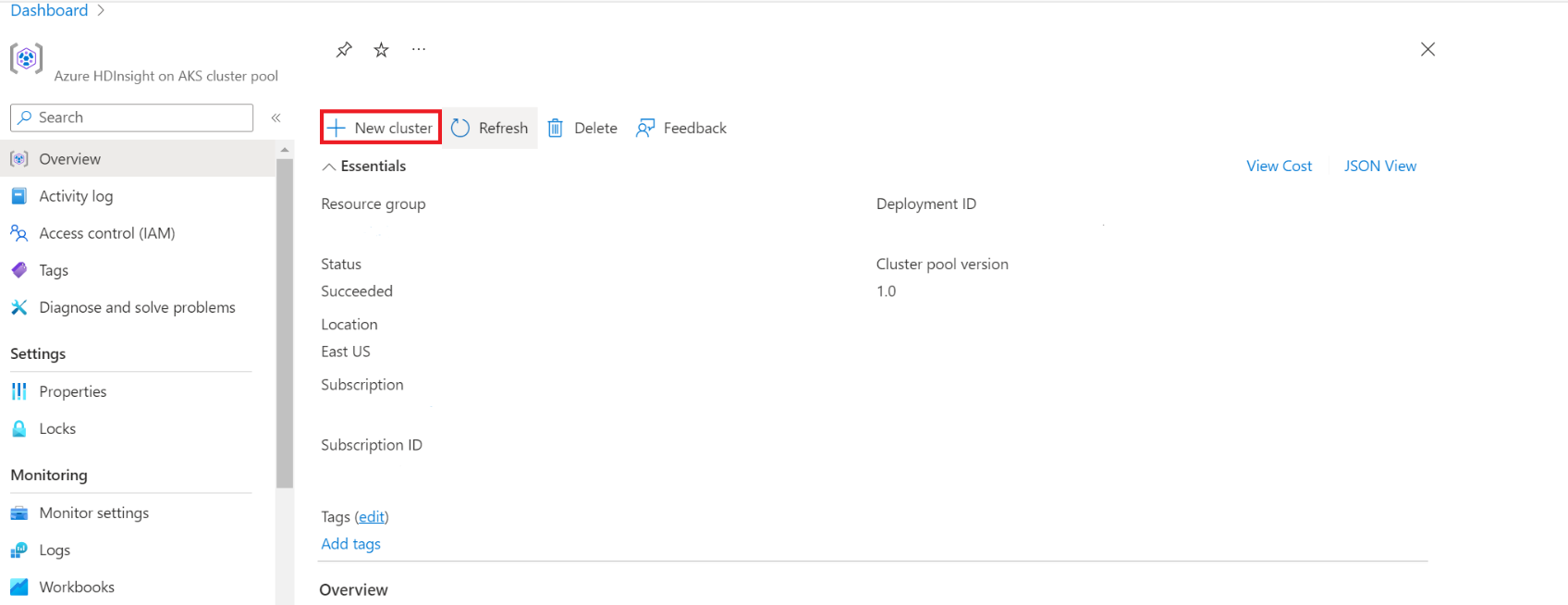
Det här steget öppnar sidan skapa kluster.
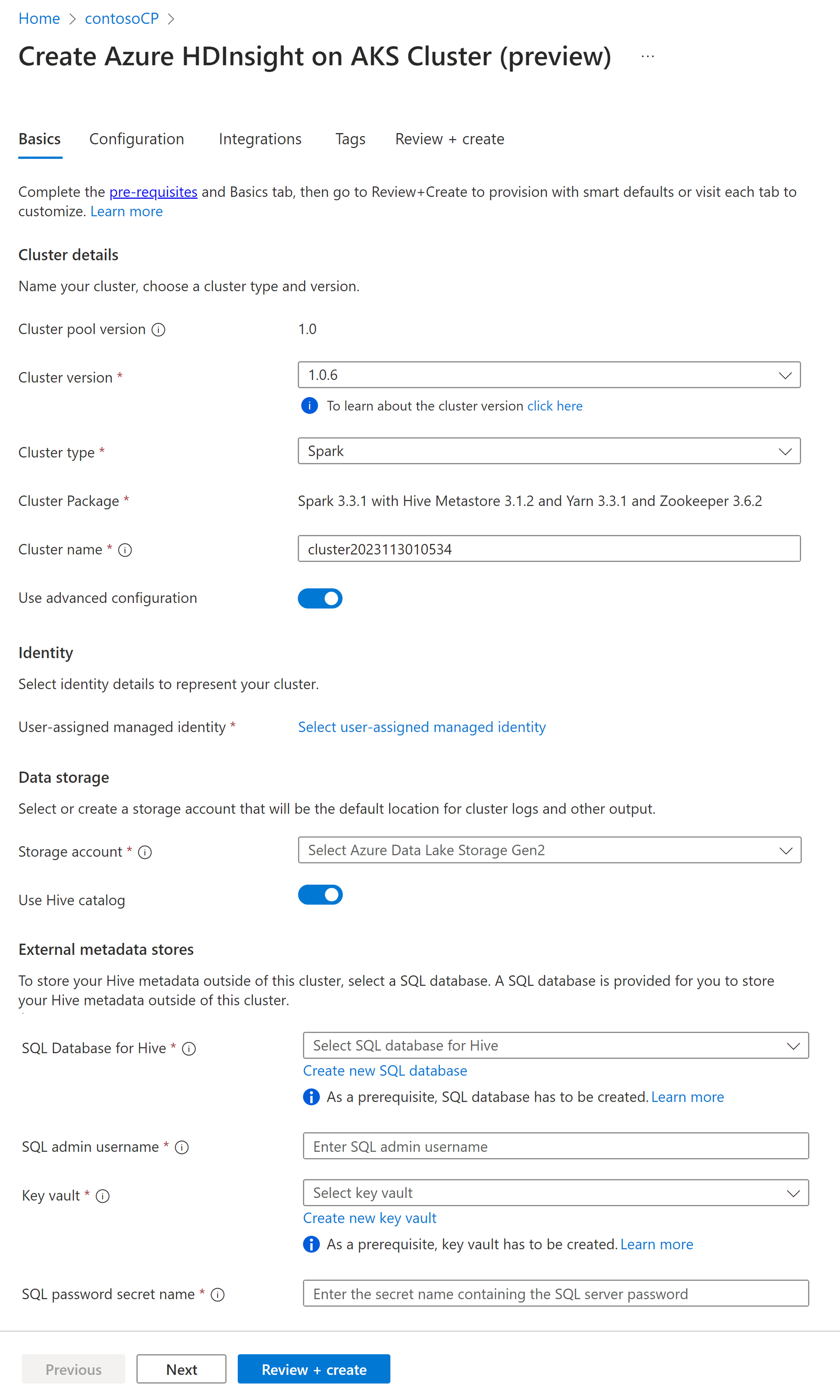
Egenskap Beskrivning Abonnemang Det Azure-abonnemang som har registrerats för användning med HDInsight på AKS i avsnittet Förutsättningar kommer att vara förifyllt Resursgrupp Samma resursgrupp som klusterpoolen fylls i i förväg Region Samma region som klusterpoolen och den virtuella kommer att fyllas i i förväg Klusterpool Namnet på klusterpoolen fylls i i förväg HDInsight-poolversion Klusterpoolversionen förifylls från valet för poolskapandet HDInsight på AKS-version Ange HDI på AKS-versionen Klustertyp I listrutan väljer du Spark Klusterversion Välj vilken version av avbildningsversionen som ska användas Klusternamn Ange namnet på det nya klustret Användartilldelad hanterad identitet Välj den användartilldelade hanterade identiteten som ska fungera som en anslutningssträng med lagringen Lagringskonto Välj det förskapade lagringskontot som ska användas som primär lagring för klustret Containernamn Välj containernamnet (unikt) om det skapas i förväg eller skapar en ny container Hive-katalog (valfritt) Välj det i förväg skapade Hive-metaarkivet (Azure SQL DB) SQL-databas för Hive I listrutan väljer du den SQL Database där du vill lägga till hive-metaarkivtabeller. ANVÄNDARNAMN för SQL-administratör Ange användarnamnet för SQL-administratören Nyckelvalv I listrutan väljer du Key Vault, som innehåller en hemlighet med lösenord för SQL-administratörens användarnamn Namn på SQL-lösenordshemlighet Ange det hemliga namnet från Key Vault där SQL DB-lösenordet lagras Not
- För närvarande stöder HDInsight endast MS SQL Server-databaser.
- På grund av Hive-begränsning stöds inte "-" (bindestreck) i metaarkivdatabasens namn.
Välj Nästa: Konfiguration + prissättning för att fortsätta.
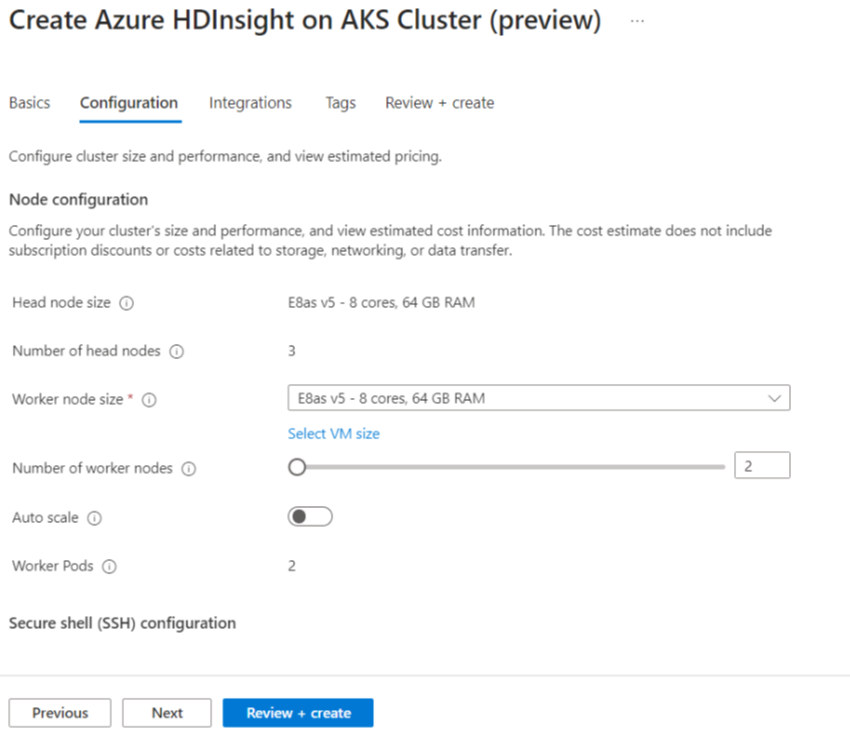
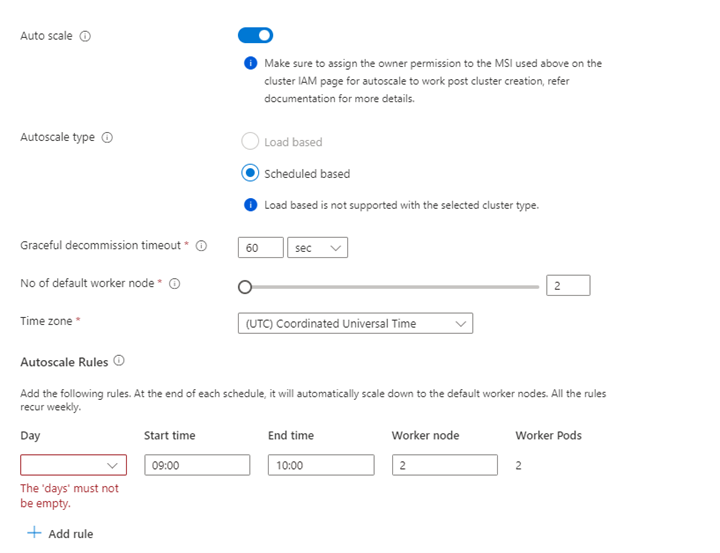
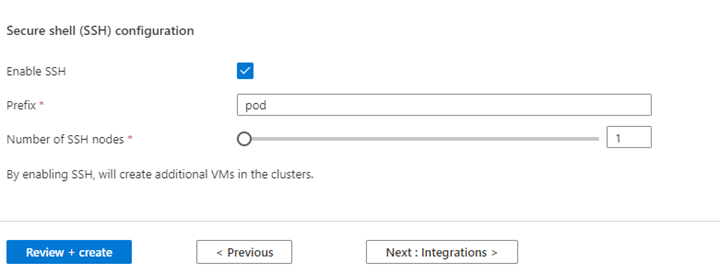
Egenskap Beskrivning Nodstorlek Välj den nodstorlek som ska användas för Spark-noderna Antal arbetsnoder Välj antalet noder för Spark-kluster. Av dessa är tre noder reserverade för koordinator- och systemtjänster, återstående noder är dedikerade till Spark-arbetare, en arbetare per nod. I ett kluster med fem noder finns det till exempel två arbetare Automatisk skalning Klicka på växlingsknappen för att aktivera autoskalning Autoskalningstyp Välj från antingen belastningsbaserad eller schemabaserad autoskalning Smidig timeout för avaktivering Ange en respitfri timeout för avaktivering Antal standardarbetarnoder Välj antalet noder för autoskalning Tidszon Välj tidszonen Regler för autoskalning Välj dag, starttid, sluttid, antal arbetsnoder Aktivera SSH Om det är aktiverat kan du definiera prefix och antal SSH-noder Klicka på Nästa: Integreringar för att aktivera och välja Log Analytics för loggning.
Azure Prometheus för övervakning och mått kan aktiveras när klustret har skapats.
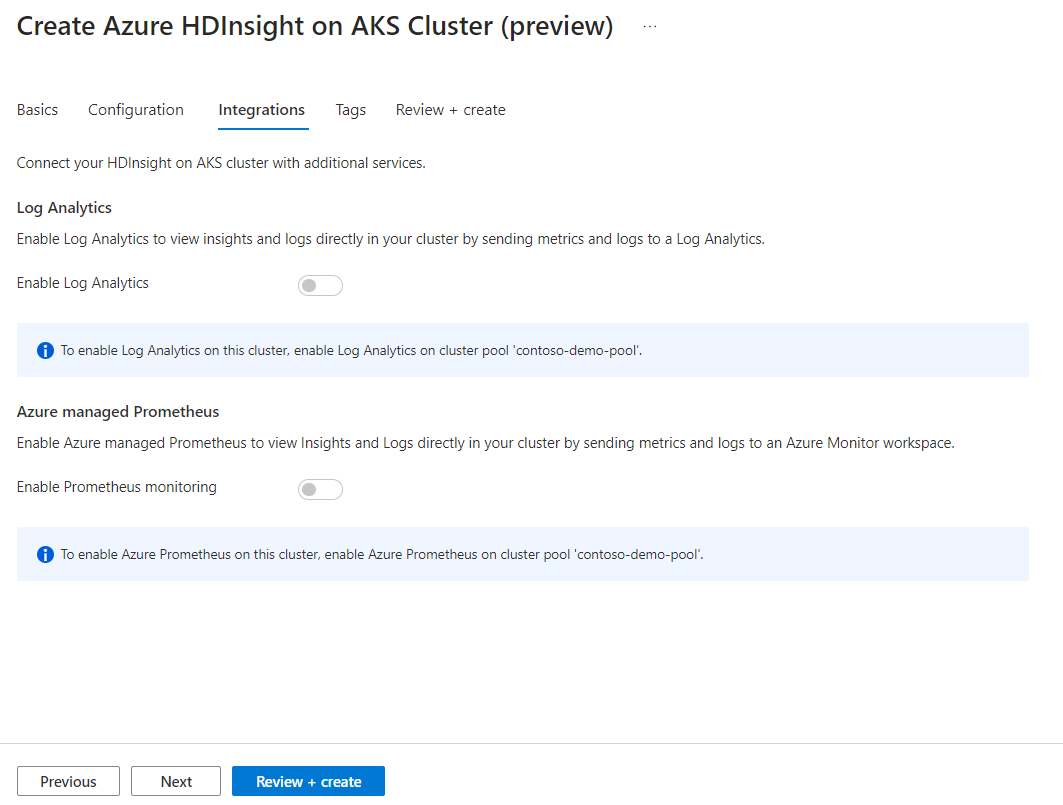
Klicka på Nästa: Taggar för att gå vidare till nästa sida.

På sidan Taggar anger du eventuella taggar som du vill lägga till i resursen.
Egenskap Beskrivning Namn Valfri. Ange ett namn som HDInsight på AKS Private Preview för att enkelt identifiera alla resurser som är associerade med dina resurser Värde Lämna det här tomt Resurs Välj Alla resurser har valts Klicka på Nästa: Granska och skapa.
På sidan Granska + skapaletar du efter meddelandet Validering lyckades överst på sidan och klickar sedan på Skapa.
Distribution pågår sidan visas som klustret skapas. Det tar 5–10 minuter att skapa klustret. När klustret har skapats visas meddelandet Din distribution är klar. Om du navigerar bort från sidan kan du kontrollera statusen för dina meddelanden.
Gå till -klusteröversiktssidan. Du kan se slutpunktslänkar där.