Begränsningar och vanliga frågor och svar om Git-integrering med Databricks Git-mappar
Databricks Git-mappar och Git-integrering har gränser som anges i följande avsnitt. Allmän information finns i Databricks-gränser.
Hoppa till:
- Fil- och lagringsplatsens gränser
- Tillgångstyper som stöds i Git-mappar
- Vanliga frågor och svar: Konfiguration av Git-mapp
Fil- och lagringsplatsens gränser
Azure Databricks tillämpar ingen gräns för storleken på en lagringsplats. Observera följande:
- Arbetsgrenar är begränsade till 1 GIGABYTE (GB).
- Filer som är större än 10 MB kan inte visas i Azure Databricks-användargränssnittet.
- Enskilda arbetsytefiler omfattas av en separat storleksgräns. Mer information finns i Begränsningar.
Databricks rekommenderar att du gör det på en lagringsplats:
- Det totala antalet arbetsytetillgångar och filer får inte överstiga 20 000.
För alla Git-åtgärder är minnesanvändningen begränsad till 2 GB och diskskrivningar är begränsade till 4 GB. Eftersom gränsen är per åtgärd får du ett fel om du försöker klona en Git-lagringsplats som är 5 GB i aktuell storlek. Men om du klonar en Git-lagringsplats som är 3 GB i storlek i en åtgärd och sedan lägger till 2 GB till den senare, kommer nästa pull-åtgärd att lyckas.
Du kan få ett felmeddelande om lagringsplatsen överskrider dessa gränser. Du kan också få ett timeout-fel när du klonar lagringsplatsen, men åtgärden kan slutföras i bakgrunden.
Om du vill arbeta med lagringsplatser som är större än storleksgränserna kan du prova att checka ut sparsamt.
Om du måste skriva temporära filer som du inte vill behålla när klustret har stängts av skriver du de temporära filerna för att undvika att $TEMPDIR överskrida gränserna för grenstorlek och ger bättre prestanda än att skriva till den aktuella arbetskatalogen (CWD) om CWD finns i arbetsytans filsystem. Mer information finns i Var ska jag skriva temporära filer på Azure Databricks?.
Maximalt antal Git-mappar per arbetsyta
Du kan ha högst 2 000 Git-mappar per arbetsyta. Kontakta Databricks-supporten om du behöver mer.
Återställa filer som tagits bort från Git-mappar på din arbetsyta
Åtgärder för arbetsytor på Git-mappar varierar i filåterställbarhet. Vissa åtgärder tillåter återställning via papperskorgen medan andra inte gör det. Filer som tidigare checkats in och push-överförts till en fjärrgren kan återställas med hjälp av Git-incheckningshistoriken för git-fjärrlagringsplatsen. Den här tabellen beskriver varje åtgärds beteende och återställningsbarhet:
| Åtgärd | Går det att återställa filen? |
|---|---|
| Ta bort fil med arbetsytans webbläsare | Ja, från papperskorgen |
| Ignorera en ny fil med dialogrutan Git-mapp | Ja, från papperskorgen |
| Ignorera en ändrad fil med dialogrutan Git-mapp | Nej, filen är borta |
reset (hårt) för icke-begärda filändringar |
Nej, filändringarna är borta |
reset (hårt) för ogenomförda, nyligen skapade filer |
Nej, filändringarna är borta |
| Växla grenar med dialogrutan Git-mapp | Ja, från en fjärransluten Git-lagringsplats |
| Andra Git-åtgärder (incheckning och push-överföring osv.) från dialogrutan Git-mapp | Ja, från en fjärransluten Git-lagringsplats |
PATCH åtgärder som uppdaterar /repos/id från Repos API |
Ja, från en fjärransluten Git-lagringsplats |
Filer som tas bort från en Git-mapp via Git-åtgärder från arbetsytans användargränssnitt kan återställas från fjärrgrenshistoriken med hjälp av Git-kommandoraden (eller andra Git-verktyg) om dessa filer tidigare har checkats in och push-överförts till fjärrlagringsplatsen. Åtgärder för arbetsytor varierar i filåterställbarhet. Vissa åtgärder tillåter återställning via papperskorgen, medan andra inte gör det. Filer som tidigare checkats in och push-överförts till en fjärrgren kan återställas via Git-incheckningshistoriken. Tabellen nedan beskriver varje åtgärds beteende och återställningsbarhet:
Stöd för monorepo
Databricks rekommenderar att du inte skapar Git-mappar som backas upp av monorepos, där en monorepo är en stor Git-lagringsplats med en enda organisation med tusentals filer i många projekt.
Tillgångstyper som stöds i Git-mappar
Endast vissa Azure Databricks-tillgångstyper stöds av Git-mappar. En tillgångstyp som stöds kan serialiseras, versionskontrolleras och push-överföras till git-lagringsplatsen som stöds.
För närvarande är de tillgångstyper som stöds:
| Tillgångstyp | Details |
|---|---|
| Arkiv | Filer är serialiserade data och kan innehålla allt från bibliotek till binärfiler till kod till bilder. Mer information finns i Vad är arbetsytefiler? |
| Notebook-fil | Notebook-filer är specifikt de filformat för notebook-filer som stöds av Databricks. Notebook-filer anses vara en separat Azure Databricks-tillgångstyp från filer eftersom de inte serialiseras. Git-mappar avgör en notebook-fil med filnamnstillägget (till exempel .ipynb) eller filnamnstillägg som kombineras med en särskild markör i filinnehåll (till exempel en # Databricks notebook source kommentar i början av .py källfilerna). |
| Mapp | En mapp är en Azure Databricks-specifik struktur som representerar serialiserad information om en logisk gruppering av filer i Git. Som förväntat upplever användaren detta som en "mapp" när de visar en Azure Databricks Git-mapp eller kommer åt den med Azure Databricks CLI. |
| DBSQL-fråga | Databricks SQL-frågor (DBSQL) kan sparas som IPYNB-notebookar (tillägg: .dbquery.ipynb). Git-stöd för DBSQL-frågor kräver att du aktiverar nya SQL-redigeraren. Frågeställningar som skapats med den nya SQL-redigerarfunktionen inaktiverad kan placeras i en Git-mapp men kan inte läggas till i fjärrlagringsplatsen. |
Azure Databricks-tillgångstyper som för närvarande inte stöds i Git-mappar innehåller följande:
- Aviseringar
- Instrumentpaneler (inklusive äldre instrumentpaneler)
- Experiment
- Genie-blanksteg
Observera följande begränsningar i filnamngivning när du arbetar med dina tillgångar i Git:
- En mapp får inte innehålla en notebook-fil med samma namn som en annan notebook-fil, fil eller mapp på samma Git-lagringsplats, även om filtillägget skiljer sig åt. (För notebook-filer i källformat gäller
.pytillägget python,.scalaScala,.sqlSQL och.rR. För NOTEBOOK-filer i IPYNB-format är.ipynbtillägget .) Du kan till exempel inte använda en notebook-fil i källformat med namnettest1.pyoch en IPYNB-anteckningsbok med namnettest1i samma Git-mapp eftersom python-notebook-filen (test1.py) i källformat kommer att serialiseras somtest1och en konflikt uppstår. - Tecknet
/stöds inte i filnamn. Du kan till exempel inte ha en fil med namneti/o.pyi din Git-mapp.
Om du försöker utföra Git-åtgärder på filer med namn som har dessa mönster visas meddelandet "Fel vid hämtning av Git-status". Om du får det här felet oväntat granskar du filnamnen för tillgångarna på git-lagringsplatsen. Om du hittar filer med namn som har dessa motstridiga mönster byter du namn på dem och försöker igen.
Kommentar
Du kan flytta befintliga tillgångar som inte stöds till en Git-mapp, men du kan inte checka in några ändringar som gjorts på fjärrlagringsplatsen.
Notebook-format
| Källformat för notebook-fil | Details |
|---|---|
| source | Kan vara valfri kodfil med ett standardfilsuffix som signalerar kodspråket, till exempel .py, .scala.r och .sql. Källnotebook-filer behandlas som textfiler och innehåller inga associerade utdata när de kommitteras till det fjärrlagret. |
| IPYNB (Jupyter) | IPYNB-filer slutar med .ipynb och kan, om de konfigureras, skicka utdata (till exempel visualiseringar) från Databricks Git-mappen till fjärrlagringsplatsen. En IPYNB-notebook-fil kan innehålla kod på valfritt språk som stöds av Databricks-notebook-filer (trots py del av .ipynb). |
Databricks fungerar med två typer av databricks-specifika notebook-format på hög nivå: source och IPYNB (Jupyter). När en användare committerar en notebook-fil i source-format committerar Azure Databricks-plattformen en platt fil med ett språksuffix, till exempel .py, .sql, .scalaeller .r. En notebook-fil i source-format innehåller endast källkod och innehåller inte utdata som tabellvisningar och visualiseringar som är resultatet av att köra notebook-filen.
Formatet IPYNB (Jupyter) har dock utdata som är associerade med det, och dessa artefakter skickas automatiskt till Git-lagringsplatsen som stöder Git-mappen när du pushar .ipynb notebook-filen som genererade dem. Om du vill spara utdata tillsammans med koden använder du IPYNB-notebookformatet och ställer in konfigurationen så att en användare kan spara genererade utdata. Därför stöder IPYNB också en bättre visningsupplevelse i Databricks för notebook-filer som skickas till fjärranslutna Git-lagringsplatser via Git-mappar.
IPYNB-notebook-filer är standardformatet när du skapar en ny notebook-fil på Databricks. Om du vill ändra standardvärdet till Databricks-källformatet loggar du in på din Azure Databricks-arbetsyta, klickar på din profil längst upp till höger på sidan och klickar sedan på Inställningar och navigerar till Developer. Ändra standardformatet för notebook under inställningarna för Editor rubrik.
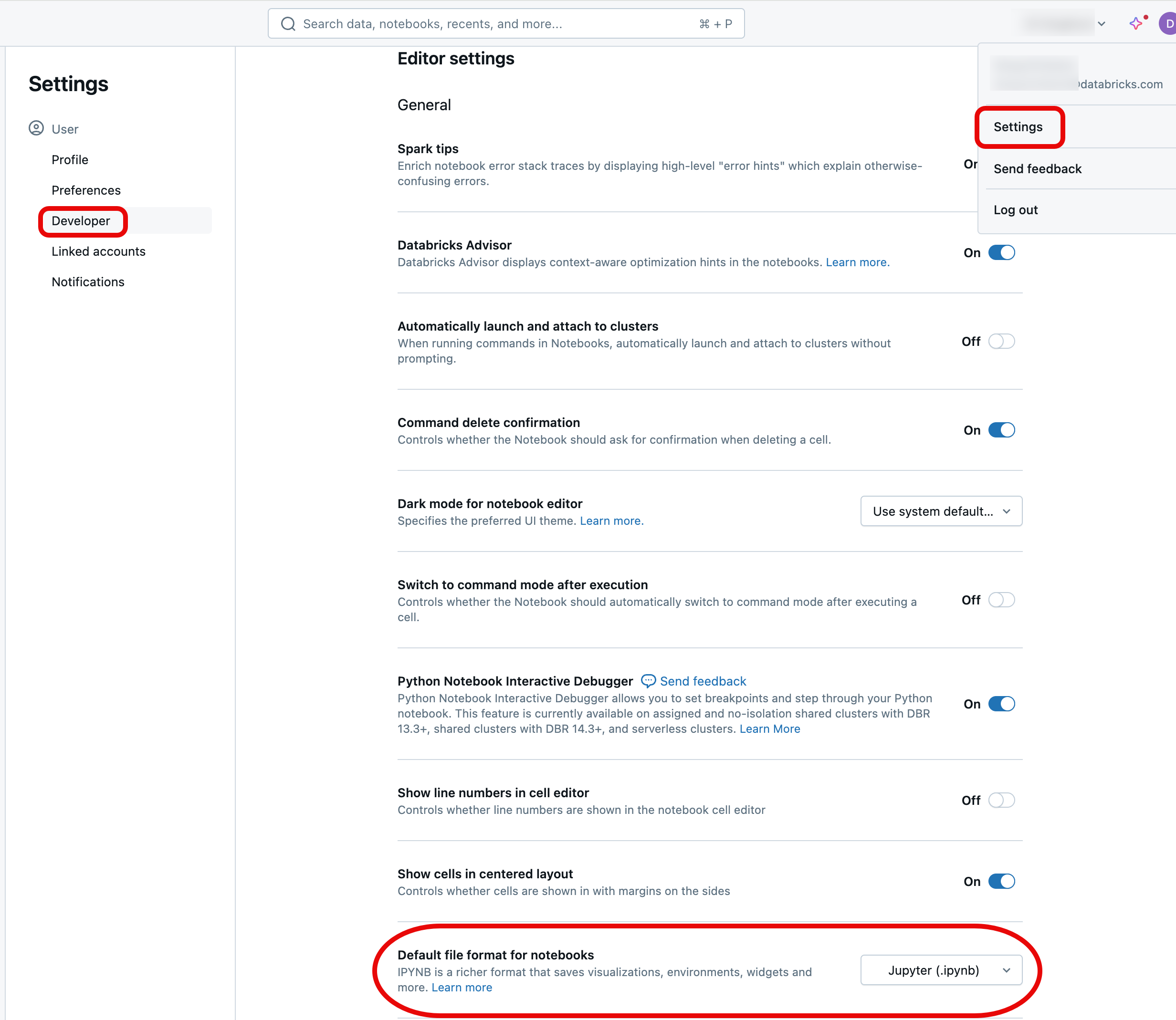
Om du vill att utdata ska skickas tillbaka till ditt repo efter att du har kört en Jupyter-notebook, använder du en IPYNB-fil. Om du bara vill köra anteckningsboken och hantera den i Git använder du ett source format som .py.
Mer information om notebook-format som stöds finns i Exportera och importera Databricks-notebook-filer.
Kommentar
Vad är "utdata"?
Utdata är resultatet av att köra en notebook-fil på Databricks-plattformen, inklusive tabellvisningar och visualiseringar.
Tillåt incheckning av notebook-utdata .ipynb
Utdata kan bara checkas in om en arbetsyteadministratör har aktiverat den här funktionen. Som standardinställning tillåter inte den administrativa inställningen för Git-mappar att .ipynb notebook-utdata committas. Om du har administratörsbehörighet för arbetsytan kan du ändra den här inställningen:
Gå till Administratörsinställningar>Arbetsyteinställningar i Azure Databricks-administratörskonsolen.
Under Git-mapparväljer du Tillåt Att Git-mappar exporterar IPYNB-utdata och väljer sedan Tillåt: IPYNB-utdata kan växlas på.

Viktigt!
När utdata ingår, är visualiserings- och instrumentpanelsinställningarna inkluderade i de.ipynb notebook-filer som du skapar.
Kontrollera artefaktincheckningar för IPYNB-notebook-utdata
När du checkar in en .ipynb fil skapar Databricks en konfigurationsfil som låter dig styra hur du checkar in utdata: .databricks/commit_outputs.
Om du har en
.ipynbnotebook-fil men ingen konfigurationsfil på fjärrlagringsplatsen går du till dialogrutan Git-status.I meddelandedialogrutan väljer du Skapa commit_outputs-fil.
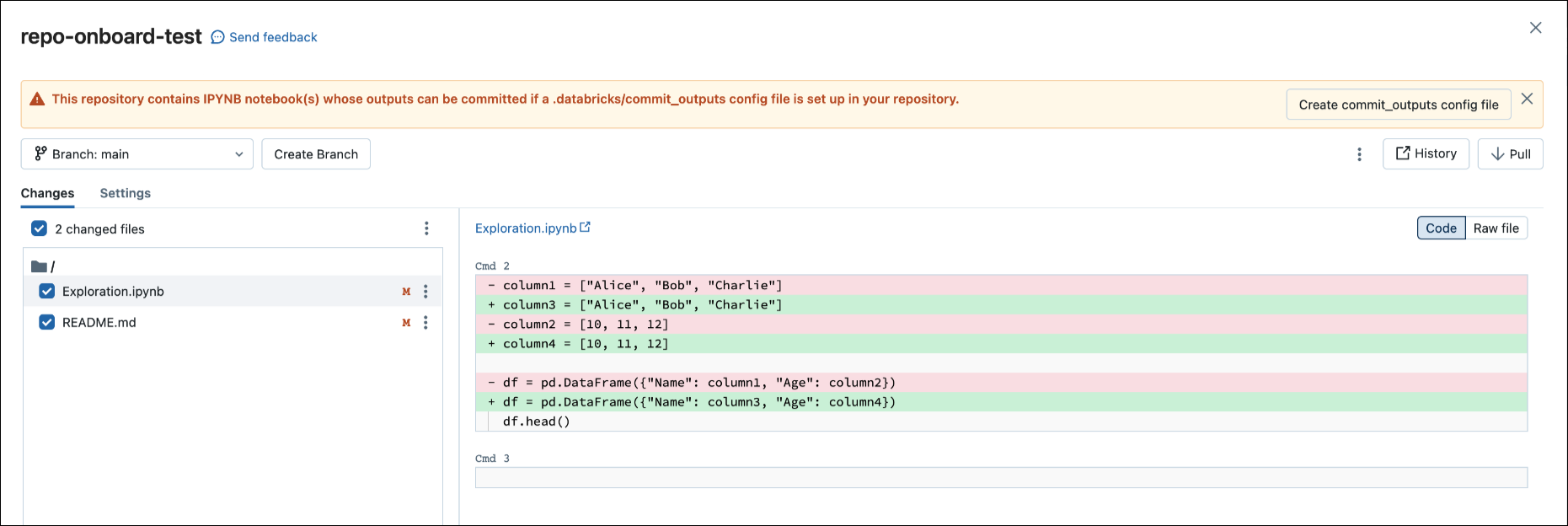
Du kan också generera konfigurationsfiler från menyn File. Menyn File har en kontroll för att automatiskt uppdatera konfigurationsfilen där du kan ange inkludering eller exkludering av utdata för en specifik IPYNB-notebook-fil.
I menyn Arkiv väljer du Checka in notebook-filer.
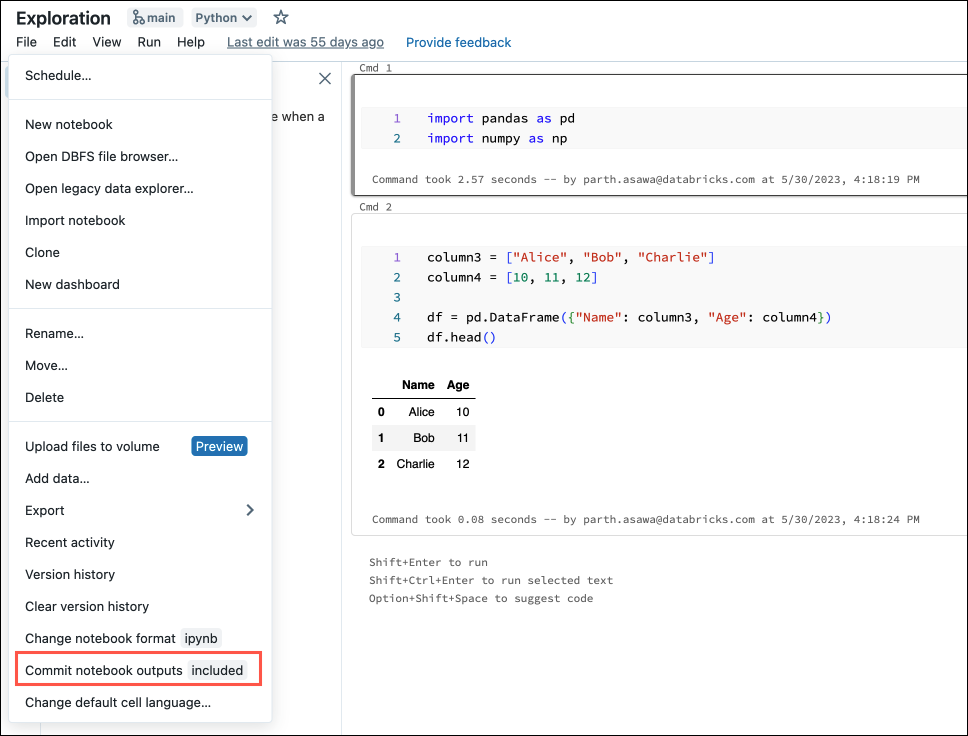
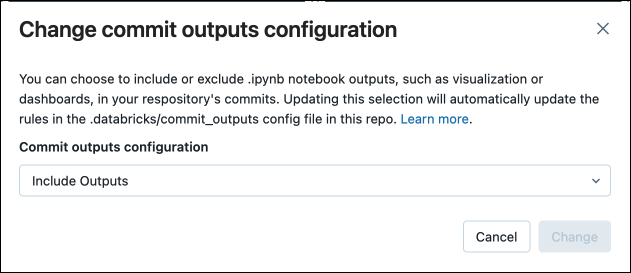
I dialogrutan bekräftar du ditt val att checka in notebook-utdata.
Konvertera en källanteckningsbok till IPYNB
Du kan konvertera en befintlig källanteckningsbok i en Git-mapp till en IPYNB-notebook-fil via Azure Databricks-användargränssnittet.
Öppna en källanteckningsbok på arbetsytan.
Välj Arkiv på arbetsytans meny och välj sedan Ändra notebook-format [källa]. Om notebook-filen redan är i IPYNB-format är [källa] [ipynb] i menyelementet.
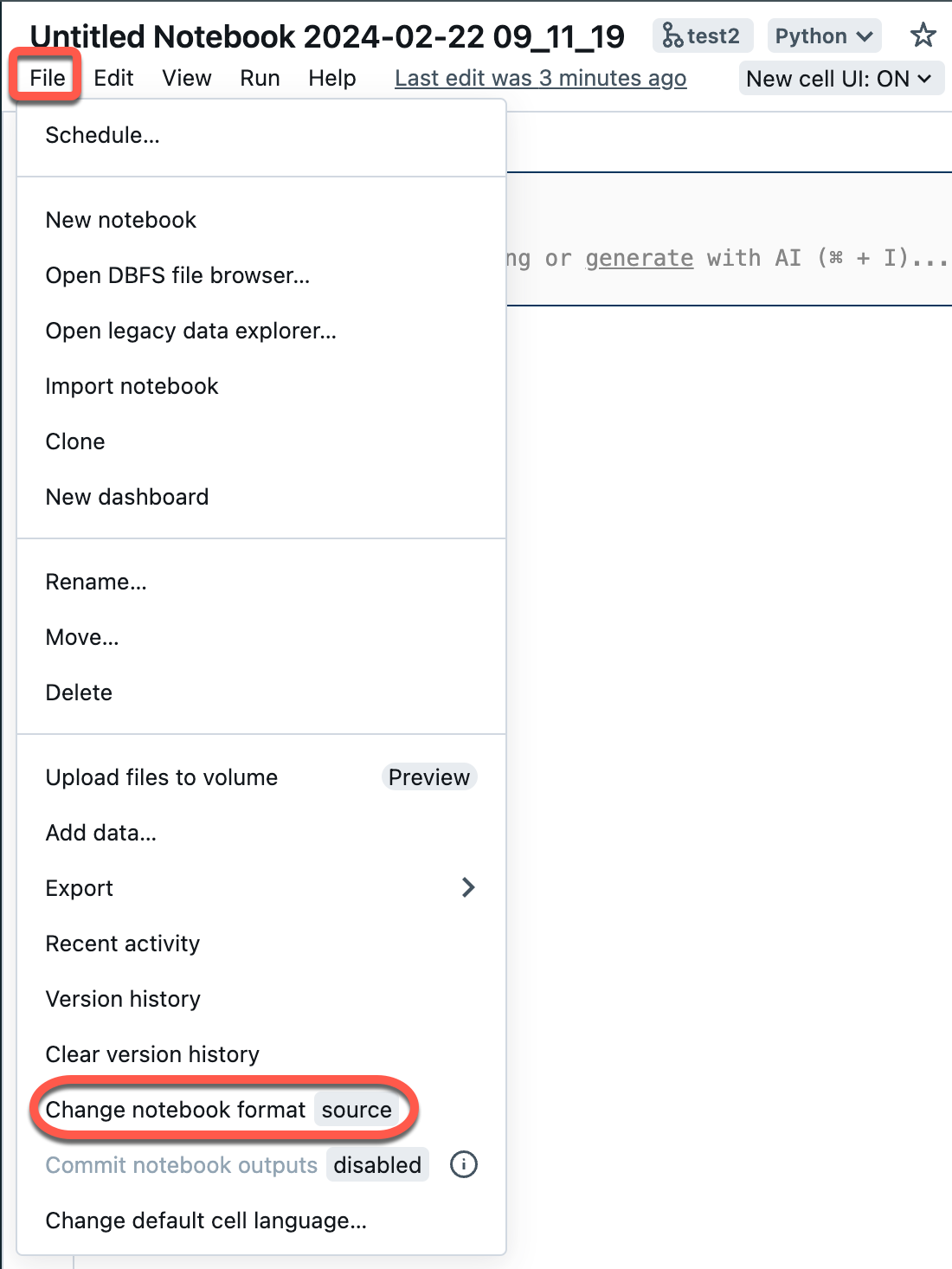
I den modala dialogrutan väljer du "Jupyter Notebook-format (.ipynb)" och klickar på Ändra.
Du kan även:
- Skapa nya
.ipynbnotebook-filer. - Visa diff som koddiff (kodändringar i celler) eller rå-diff (kodändringar visas som JSON-syntax, som innehåller notebook-utdata som metadata).
Mer information om vilka typer av notebook-filer som stöds i Azure Databricks finns i Exportera och importera Databricks-notebook-filer.
Vanliga frågor och svar: Konfiguration av Git-mapp
Var lagras Azure Databricks-lagringsplatsens innehåll?
Innehållet i en lagringsplats klonas tillfälligt på disken i kontrollplanet. Azure Databricks Notebook-filer lagras i kontrollplansdatabasen precis som notebook-filer på huvudarbetsytan. Filer som inte är notebook-filer lagras på disken i upp till 30 dagar.
Stöder Git-mappar lokala eller lokalt installerade Git-servrar?
Databricks Git-mappar stöder GitHub Enterprise, Bitbucket Server, Azure DevOps Server och Självhanterad GitLab-integrering om servern är tillgänglig via Internet. Mer information om hur du integrerar Git-mappar med en lokal Git-server finns i Git Proxy Server för Git-mappar.
Om du vill integrera med en Bitbucket Server, GitHub Enterprise Server eller en självhanterad GitLab-prenumerationsinstans som inte är internettillgänglig kan du kontakta ditt Azure Databricks-kontoteam.
Vilka Databricks-tillgångstyper stöds av Git-mappar?
Mer information om tillgångstyper som stöds finns i Tillgångstyper som stöds i Git-mappar.
Stöder Git-mappar .gitignore filer?
Ja. Om du lägger till en fil på lagringsplatsen och inte vill att den ska spåras av Git skapar du en fil eller använder en .gitignore klonad från fjärrlagringsplatsen och lägger till filnamnet, inklusive tillägget.
.gitignore fungerar bara för filer som inte redan spåras av Git. Om du lägger till en fil som redan spåras av Git i en .gitignore fil spåras filen fortfarande av Git.
Kan jag skapa mappar på den översta nivån som inte är användarmappar?
Ja, administratörer kan skapa mappar på den översta nivån till ett enda djup. Git-mappar stöder inte ytterligare mappnivåer.
Stöder Git-mappar Git-undermoduler?
Nej. Du kan klona en lagringsplats som innehåller Git-undermoduler, men undermodulen klonas inte.
Har Azure Data Factory (ADF) stöd för Git-mappar?
Ja.
Källhantering
Varför försvinner instrumentpaneler för notebook-filer när jag hämtar eller checkar ut en annan gren?
Detta är för närvarande en begränsning eftersom Azure Databricks notebook-källfiler inte lagrar information om instrumentpanelen för notebook-filer.
Om du vill bevara instrumentpaneler i Git-lagringsplatsen ändrar du notebook-formatet till .ipynb (Jupyter Notebook-format). Som standard .ipynb stöder instrumentpanels- och visualiseringsdefinitioner. Om du vill bevara grafdata (datapunkter) måste du checka in anteckningsboken med utdata.
Mer information om hur .ipynb du checkar in notebook-utdata finns i Tillåt incheckning av .ipynb notebook-utdata.
Stöder Git-mappar sammanslagning av grenar?
Ja. Du kan också skapa en pull-begäran och slå samman via git-providern.
Kan jag ta bort en gren från en Azure Databricks-lagringsplats?
Nej. Om du vill ta bort en gren måste du arbeta i git-providern.
Om ett bibliotek är installerat på ett kluster och ett bibliotek med samma namn ingår i en mapp i en lagringsplats, vilket bibliotek importeras?
Biblioteket på lagringsplatsen importeras. Mer information om bibliotekspriorens i Python finns i Prioritet för Python-bibliotek.
Kan jag hämta den senaste versionen av en lagringsplats från Git innan jag kör ett jobb utan att förlita mig på ett externt orkestreringsverktyg?
Nej. Vanligtvis kan du integrera detta som en förhandsincheckning på Git-servern så att varje push-överföring till en gren (main/prod) uppdaterar lagringsplatsen Produktion.
Kan jag exportera en lagringsplats?
Du kan exportera notebook-filer, mappar eller en hel lagringsplats. Du kan inte exportera filer som inte är notebook-filer. Om du exporterar en hel lagringsplats ingår inte filer som inte är notebook-filer. Om du vill exportera använder du workspace export kommandot i Databricks CLI eller använder API:et För arbetsyta.
Säkerhet, autentisering och token
Problem med en princip för villkorlig åtkomst (CAP) för Microsoft Entra-ID
När du försöker klona en lagringsplats kan du få felmeddelandet "nekad åtkomst" när:
- Azure Databricks är konfigurerat för att använda Azure DevOps med Microsoft Entra ID-autentisering.
- Du har aktiverat en princip för villkorlig åtkomst i Azure DevOps och en princip för villkorsstyrd åtkomst för Microsoft Entra-ID.
Lös problemet genom att lägga till ett undantag i principen för villkorsstyrd åtkomst (CAP) för IP-adressen eller användare av Azure Databricks.
Mer information finns i Principer för villkorsstyrd åtkomst.
Tillåt lista med Azure AD-token
Om du använder Azure Active Directory (AAD) för att autentisera med Azure DevOps begränsar listan över tillåtna git-url:er till:
dev.azure.comvisualstudio.com
Mer information finns i Tillåt listor som begränsar fjärr lagringsplatsens användning.
Krypteras innehållet i Azure Databricks Git-mappar?
Innehållet i Azure Databricks Git-mappar krypteras av Azure Databricks med hjälp av en standardnyckel. Kryptering med kundhanterade nycklar stöds inte förutom när du krypterar dina Git-autentiseringsuppgifter.
Hur och var lagras GitHub-token i Azure Databricks? Vem skulle ha åtkomst från Azure Databricks?
- Autentiseringstoken lagras i Azure Databricks-kontrollplanet och en Azure Databricks-anställd kan bara få åtkomst via en tillfällig autentiseringsuppgift som granskas.
- Azure Databricks loggar skapandet och borttagningen av dessa token, men inte deras användning. Azure Databricks har loggning som spårar Git-åtgärder som kan användas för att granska användningen av token från Azure Databricks-programmet.
- GitHub Enterprise granskar tokenanvändning. Andra Git-tjänster kan också ha Git-servergranskning.
Stöder Git-mappar GPG-signering av incheckningar?
Nej.
Stöder Git-mappar SSH?
Nej, bara HTTPS.
Det gick inte att ansluta Azure Databricks till en Azure DevOps-lagringsplats i en annan klientorganisation
När du försöker ansluta till DevOps i en separat klientorganisation kan du få meddelandet Unable to parse credentials from Azure Active Directory account. Om Azure DevOps-projektet har ett annat Microsoft Entra-ID än Azure Databricks måste du använda en åtkomsttoken från Azure DevOps. Se Ansluta till Azure DevOps med en DevOps-token.
CI/CD och MLOps
Inkommande ändringar rensar notebook-tillståndet
Git-åtgärder som ändrar källkoden för notebook-filen resulterar i förlust av notebook-tillstånd, inklusive cellutdata, kommentarer, versionshistorik och widgetar. Kan till exempel git pull ändra källkoden för en notebook-fil. I det här fallet måste Databricks Git-mappar skriva över den befintliga notebook-filen för att importera ändringarna.
git commit och push eller att skapa en ny gren påverkar inte notebook-källkoden, så notebook-tillståndet bevaras i dessa åtgärder.
Viktigt!
MLflow-experiment fungerar inte i Git-mappar med DBR 14.x eller lägre versioner.
Kan jag skapa ett MLflow-experiment i en lagringsplats?
Det finns två typer av MLflow-experiment: arbetsyta och notebook-fil. Mer information om de två typerna av MLflow-experiment finns i Ordna träningskörningar med MLflow-experiment.
I Git-mappar kan du anropa mlflow.set_experiment("/path/to/experiment") ett MLflow-experiment av någon av typerna och loggkörningar till det, men experimentet och de associerade körningarna checkas inte in i källkontrollen.
MLflow-experiment för arbetsyta
Du kan inte skapa MLflow-experiment för arbetsytan i en Databricks Git-mapp (Git-mapp). Om flera användare använder separata Git-mappar för att samarbeta med samma ML-kod körs MLflow-loggen till ett MLflow-experiment som skapats i en vanlig arbetsytemapp.
MLflow-experiment för notebook-filer
Du kan skapa notebook-experiment i en Databricks Git-mapp. Om du checkar in anteckningsboken i källkontrollen som en .ipynb fil kan du logga MLflow-körningar till ett automatiskt skapat och associerat MLflow-experiment. Mer information finns i skapa notebook-experiment.
Förhindra dataförlust i MLflow-experiment
MLflow-experiment för notebook-filer som skapats med Databricks-jobb med källkod på en fjärrlagringsplats lagras på en tillfällig lagringsplats. De här experimenten bevaras först efter arbetsflödets körning men riskerar att tas bort senare under schemalagd borttagning av filer i tillfällig lagring. Databricks rekommenderar att du använder MLflow-experiment för arbetsytor med jobb och fjärranslutna Git-källor.
Varning
Varje gång du växlar till en gren som inte innehåller notebook-filen riskerar du att förlora associerade MLflow-experimentdata. Den här förlusten blir permnanent om den tidigare grenen inte nås inom 30 dagar.
Om du vill återställa saknade experimentdata innan 30 dagar går ut byter du namn på anteckningsboken tillbaka till det ursprungliga namnet, öppnar anteckningsboken, klickar på "experiment"-ikonen till höger (detta anropar även API:et mlflow.get_experiment_by_name() ) och du kommer att kunna se det återställda experimentet och körningarna. Efter 30 dagar rensas alla överblivna MLflow-experiment för att uppfylla GDPR-efterlevnadsprinciper.
För att förhindra den här situationen rekommenderar Databricks att du antingen undviker att byta namn på anteckningsböcker helt och hållet, eller om du byter namn på en anteckningsbok klickar du på ikonen "experiment" till höger direkt efter att du har bytt namn på en notebook-fil.
Vad händer om ett notebook-jobb körs på en arbetsyta medan en Git-åtgärd pågår?
När som helst medan en Git-åtgärd pågår kan vissa notebook-filer på lagringsplatsen ha uppdaterats medan andra inte har gjort det. Det kan leda till ett oväntat beteende.
Anta till exempel att notebook A anrop notebook Z använder ett %run kommando. Om ett jobb som körs under en Git-åtgärd startar den senaste versionen av , men notebook A ännu inte har uppdaterats, notebook Z kan kommandot i notebook A starta den äldre versionen av %run.notebook Z
Under Git-åtgärden är notebook-tillstånden inte förutsägbara och jobbet kan misslyckas eller köras notebook A och notebook Z från olika incheckningar.
Undvik den här situationen genom att använda Git-baserade jobb (där källan är en Git-provider och inte en arbetsytesökväg) i stället. Mer information finns i Använda Git med jobb.
Resurser
Mer information om Databricks-arbetsytefiler finns i Vad är arbetsytefiler?.