MLflow-spårning för agenter
Viktigt!
Den här funktionen finns som allmänt tillgänglig förhandsversion.
Den här artikeln beskriver MLflow Tracing på Databricks och hur du använder den för att lägga till observerbarhet i dina generativa AI-program.
Vad är MLflow-spårning?
MLflow Tracing samlar in detaljerad information om genomförandet av generativa AI-applikationer. Spårningsloggar registrerar indata, utdata och metadata som är associerade med varje mellanliggande steg i en begäran, så att du kan hitta källan till fel och oväntat beteende. Om din modell till exempel hallucinerar kan du snabbt inspektera varje steg som ledde till hallucinationen.
MLflow Tracing är integrerat med Databricks-verktyg och infrastruktur, så att du kan lagra och visa spårningar i Databricks-notebook-filer eller MLflow-experimentgränssnittet.
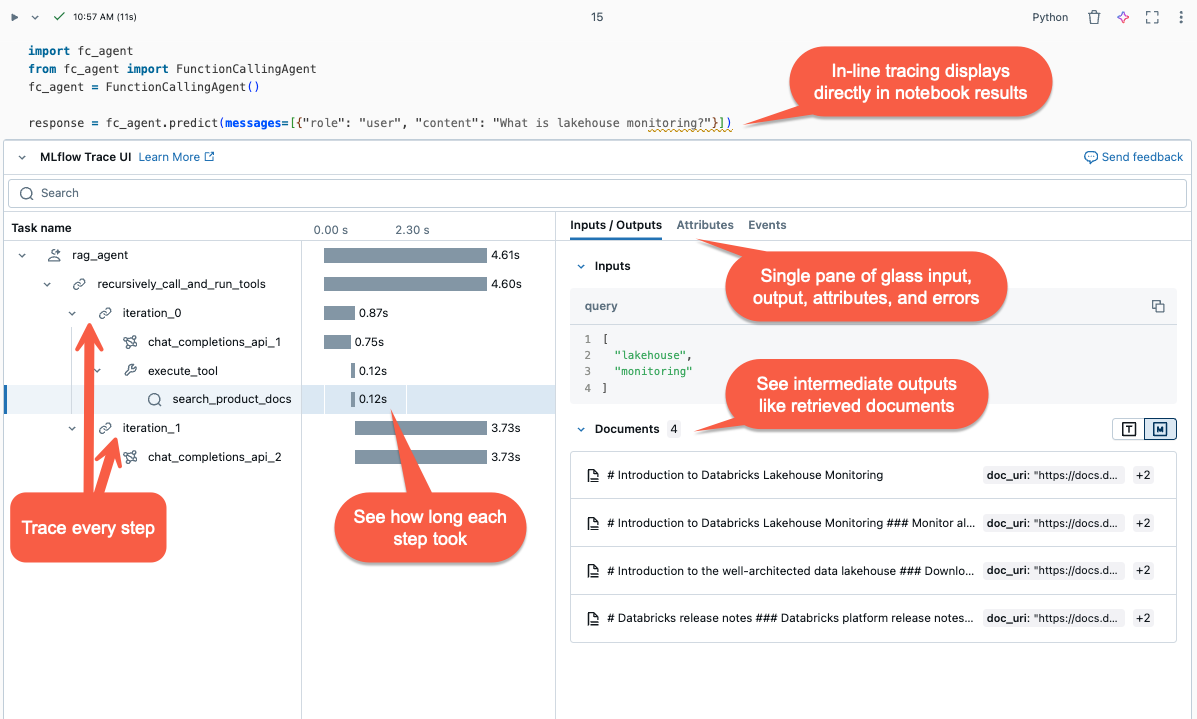
Varför ska jag använda MLflow-spårning?
MLflow Tracing ger flera fördelar:
- Granska en interaktiv spårningsvisualisering och använd undersökningsverktyget för att diagnostisera problem.
- Kontrollera att promptmallar och skyddsräcken ger rimliga resultat.
- Analysera svarstiden för olika ramverk, modeller och segmentstorlekar.
- Beräkna programkostnader genom att mäta tokenanvändning i olika modeller.
- Upprätta "gyllene" benchmark-datauppsättningar för att utvärdera prestanda för olika versioner.
- Lagra spårningar från produktionsmodellslutpunkter för att felsöka problem och utföra offlinegranskning och utvärdering.
Lägga till spårningar i din agent
MLflow Tracing stöder tre metoder för att lägga till spårningar i dina generativa AI-program. Information om API-referens finns i MLflow-dokumentationen.
| API | Rekommenderat användningsfall | beskrivning |
|---|---|---|
| automatisk MLflow-loggning | Utveckling med integrerade GenAI-bibliotek | Automatisk loggning loggar automatiskt spårningar för ramverk med öppen källkod som stöds, till exempel LangChain, LlamaIndex och OpenAI. |
| Api:er för Fluent | Anpassad agent med Pyfunc | API:er med låg kod för att lägga till spårningar utan att behöva bekymra dig om att hantera spårningens trädstruktur. MLflow bestämmer lämpliga överordnade och underordnade span-relationer automatiskt med hjälp av Python-stacken. |
| MLflow-klient-API:er | Avancerade användningsfall som flera trådar |
MLflowClient tillhandahåller detaljerade, trådsäkra API:er för avancerade användningsfall. Du måste hantera relationen mellan överordnad och underordnad manuellt för intervall. Detta ger bättre kontroll över spårningslivscykeln, särskilt för användningsfall med flera trådar. |
Installera MLflow-spårning
MLflow Tracing är tillgängligt i MLflow version 2.13.0 och senare, som är förinstallerad i <DBR< 15.4 LTS ML och senare. Installera MLflow med följande kod om det behövs:
%pip install mlflow>=2.13.0 -qqqU
%restart_python
Du kan också installera den senaste versionen av databricks-agents, som innehåller en kompatibel MLflow-version:
%pip install databricks-agents
Använda automatisk loggning för att lägga till spårningar till dina agenter
Om ditt GenAI-bibliotek stöder spårning, till exempel LangChain eller OpenAI, aktiverar du automatisk loggning genom att lägga till mlflow.<library>.autolog() i koden. Till exempel:
mlflow.langchain.autolog()
Kommentar
Från och med Databricks Runtime 15.4 LTS ML aktiveras MLflow-spårning som standard i notebook-filer. Om du till exempel vill inaktivera spårning med LangChain kan du köra mlflow.langchain.autolog(log_traces=False) i notebook-filen.
MLflow stöder ytterligare bibliotek för automatisk spårningsloggning. För en fullständig list av integrerade bibliotek, se dokumentationen MLflow Tracing.
Använda Fluent-API:er för att manuellt lägga till spårningar i din agent
Fluent API:er i MLflow skapar automatiskt spårningshierarkier baserat på kodens körningsflöde.
Dekorera din funktion
För att skapa ett intervall för omfånget för den dekorerade funktionen, använd @mlflow.trace-dekoratören.
Objektet MLflow Span organiserar spårningssteg. Spans samlar in information om enskilda åtgärder eller steg, till exempel API-anrop eller vektorlagringsfrågor, i ett arbetsflöde.
Intervallet startar när funktionen anropas och slutar när den returneras. MLflow registrerar indata och utdata för funktionen och eventuella undantag som genereras från funktionen.
Följande kod skapar till exempel ett spann med namnet my_function som samlar in indataargument x och y och utdata.
@mlflow.trace(name="agent", span_type="TYPE", attributes={"key": "value"})
def my_function(x, y):
return x + y
Använda spårningskontexthanteraren
Om du vill skapa ett intervall för ett godtyckligt kodblock, inte bara en funktion, kan du använda mlflow.start_span() som en kontexthanterare som omsluter kodblocket. Intervallet börjar när kontexten anges och slutar när kontexten avslutas. Span-indata och utdata ska anges manuellt med hjälp av settermetoder för span-objektet som genereras av kontexthanteraren.
with mlflow.start_span("my_span") as span:
span.set_inputs({"x": x, "y": y})
result = x + y
span.set_outputs(result)
span.set_attribute("key", "value")
Omsluta en extern funktion
Om du vill spåra externa biblioteksfunktioner omsluter du funktionen med mlflow.trace.
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
traced_accuracy_score = mlflow.trace(accuracy_score)
traced_accuracy_score(y_true, y_pred)
### Fluent API example
The following example shows how to use the Fluent APIs `mlflow.trace` and `mlflow.start_span` to trace the `quickstart-agent`:
```python
import mlflow
from mlflow.deployments import get_deploy_client
class QAChain(mlflow.pyfunc.PythonModel):
def __init__(self):
self.client = get_deploy_client("databricks")
@mlflow.trace(name="quickstart-agent")
def predict(self, model_input, system_prompt, params):
messages = [
{
"role": "system",
"content": system_prompt,
},
{
"role": "user",
"content": model_input[0]["query"]
}
]
traced_predict = mlflow.trace(self.client.predict)
output = traced_predict(
endpoint=params["model_name"],
inputs={
"temperature": params["temperature"],
"max_tokens": params["max_tokens"],
"messages": messages,
},
)
with mlflow.start_span(name="_final_answer") as span:
# Initiate another span generation
span.set_inputs({"query": model_input[0]["query"]})
answer = output["choices"][0]["message"]["content"]
span.set_outputs({"generated_text": answer})
# Attributes computed at runtime can be set using the set_attributes() method.
span.set_attributes({
"model_name": params["model_name"],
"prompt_tokens": output["usage"]["prompt_tokens"],
"completion_tokens": output["usage"]["completion_tokens"],
"total_tokens": output["usage"]["total_tokens"]
})
return answer
När du har lagt till spårningen kör du funktionen. Följande fortsätter exemplet med funktionen predict() i föregående avsnitt. Spårningarna visas automatiskt när du kör anropsmetoden predict().
SYSTEM_PROMPT = """
You are an assistant for Databricks users. You answer Python, coding, SQL, data engineering, spark, data science, DW and platform, API, or infrastructure administration questions related to Databricks. If the question is unrelated to one of these topics, kindly decline to answer. If you don't know the answer, say that you don't know; don't try to make up an answer. Keep the answer as concise as possible. Use the following pieces of context to answer the question at the end:
"""
model = QAChain()
prediction = model.predict(
[
{"query": "What is in MLflow 5.0"},
],
SYSTEM_PROMPT,
{
# Using Databricks Foundation Model for easier testing, feel free to replace it.
"model_name": "databricks-dbrx-instruct",
"temperature": 0.1,
"max_tokens": 1000,
}
)
MLflow-klient-APIer
MlflowClient exponerar detaljerade, trådsäkra API:er för att starta och avsluta spårningar, hantera intervall och set intervallfält. Den ger fullständig kontroll över spårningens livscykel och struktur. Dessa API:er är användbara när Fluent-API:erna inte är tillräckliga för dina krav, till exempel program med flera trådar och återanrop.
Följande är steg för att skapa en fullständig spårning med hjälp av MLflow-klienten.
Skapa en instans av MLflowClient av
client = MlflowClient().Starta en spårning med hjälp av metoden
client.start_trace(). Detta initierar spårningskontexten, startar ett absolut rotintervall och returnerar ett rotintervallobjekt. Den här metoden måste köras förestart_span()-API:et.-
Set dina attribut, indata och utdata för spåret i
client.start_trace().
Kommentar
Det finns inte en motsvarighet till metoden
start_trace()i Fluent-API:erna. Det beror på att Fluent-API:erna automatiskt initierar spårningskontexten och avgör om det är rotintervallet baserat på det hanterade tillståndet.-
Set dina attribut, indata och utdata för spåret i
API:et start_trace() returnerar ett spann. Get begärande-ID:t, en unik identifier av spårningen som även kallas
trace_idoch ID för det returnerade intervallet med hjälp avspan.request_idochspan.span_id.Starta ett underordnat segment med hjälp av
client.start_span(request_id, parent_id=span_id)till set för dina attribut, indata och utdata för segmentet.- Den här metoden kräver
request_idochparent_idför att associera intervallet med rätt position i spårningshierarkin. Den returnerar ett annat span-objekt.
- Den här metoden kräver
Avsluta barnintervallen genom att anropa
client.end_span(request_id, span_id).Upprepa steg 3–5 för alla underordnade intervall som du vill skapa.
När alla barnomfång har slutat, anropar du
client.end_trace(request_id)för att avsluta spårningen och registrera den.
from mlflow.client import MlflowClient
mlflow_client = MlflowClient()
root_span = mlflow_client.start_trace(
name="simple-rag-agent",
inputs={
"query": "Demo",
"model_name": "DBRX",
"temperature": 0,
"max_tokens": 200
}
)
request_id = root_span.request_id
# Retrieve documents that are similar to the query
similarity_search_input = dict(query_text="demo", num_results=3)
span_ss = mlflow_client.start_span(
"search",
# Specify request_id and parent_id to create the span at the right position in the trace
request_id=request_id,
parent_id=root_span.span_id,
inputs=similarity_search_input
)
retrieved = ["Test Result"]
# You must explicitly end the span
mlflow_client.end_span(request_id, span_id=span_ss.span_id, outputs=retrieved)
root_span.end_trace(request_id, outputs={"output": retrieved})
Granska spårningar
Om du vill granska spårningar när agenten har körts använder du något av följande alternativ:
- Spårningsvisualiseringen återges infogad i cellutdata.
- Spårningarna loggas till MLflow-experimentet. Du kan granska och söka i hela list med historiska spårningar på fliken Traces på sidan Experiment. När agenten körs under en aktiv MLflow-körning visas spårningar på sidan Kör.
- Hämta spårningar programmatiskt med hjälp av API:et search_traces().
Använda MLflow-spårning i produktion
MLflow Tracing är också integrerat med Mosaic AI Model Serving, så att du kan felsöka problem effektivt, övervaka prestanda och skapa en gyllene datauppsättning för offlineutvärdering. När MLflow Tracing är aktiverat för din server slutpunkt registreras spårningar i en inference table under responsecolumn.
Om du vill aktivera MLflow-spårning för serverns slutpunkt måste du setENABLE_MLFLOW_TRACING miljövariabeln i slutpunktskonfigurationen till True. Information om hur du distribuerar en slutpunkt med anpassade miljövariabler finns i Lägg till miljövariabler för oformaterad text. Om du distribuerade din agent med hjälp av deploy()-API:et loggas spårningar automatiskt till en slutsats table. Se Distribuera en agent för generativ AI-program.
Kommentar
Att skriva spårningar till en slutsatsdragning table görs asynkront, så det lägger inte till samma omkostnader som i notebook-miljön under utvecklingen. Det kan dock fortfarande medföra vissa omkostnader för slutpunktens svarshastighet, särskilt när spårningsstorleken för varje slutsatsdragningsbegäran är stor. Databricks garanterar inte något serviceavtal (SLA) för den faktiska svarstidens inverkan på modellslutpunkten, eftersom det är mycket beroende av miljön och modellimplementeringen. Databricks rekommenderar att du testar slutpunktsprestanda och får insikter om spårningskostnaderna innan du distribuerar till ett produktionsprogram.
Följande table ger en grov indikation på effekten på slutsatsdragningsfördröjning för olika spårningsstorlekar.
| Spårningsstorlek per begäran | Påverkan på svarstid (ms) |
|---|---|
| ~10 KB | ~ 1 ms |
| ~ 1 MB | 50 ~ 100 ms |
| 10 MB | 150 ms ~ |
Begränsningar
- MLflow Tracing är tillgängligt i Databricks-notebook-filer, notebook-jobb och modellservering.
LangChain-automatisk loggning kanske inte stöder alla API:er för LangChain-förutsägelse. Fullständig list av API:er som stöds finns i MLflow-dokumentationen.