Träna rekommenderade modeller
Den här artikeln innehåller två exempel på djupinlärningsbaserade rekommendationsmodeller i Azure Databricks. Jämfört med traditionella rekommendationsmodeller kan djupinlärningsmodeller uppnå resultat av högre kvalitet och skala till större mängder data. När dessa modeller fortsätter att utvecklas tillhandahåller Databricks ett ramverk för att effektivt träna storskaliga rekommendationsmodeller som kan hantera hundratals miljoner användare.
Ett allmänt rekommendationssystem kan ses som en tratt med de steg som visas i diagrammet.
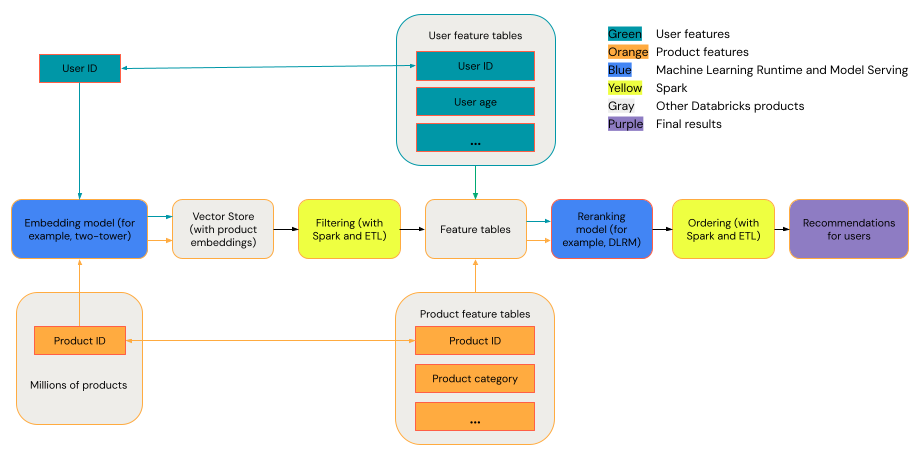
Vissa modeller, till exempel tvåtornsmodellen, fungerar bättre som hämtningsmodeller. Dessa modeller är mindre och kan effektivt användas på miljontals datapunkter. Andra modeller, till exempel DLRM eller DeepFM, presterar bättre som omrankningsmodeller. Dessa modeller kan ta in mer data, är större och kan ge detaljerade rekommendationer.
Krav
Databricks Runtime 14.3 LTS ML
Verktyg
Exemplen i den här artikeln illustrerar följande verktyg:
- TorchDistributor: TorchDistributor är ett ramverk som gör att du kan köra storskalig PyTorch-modellträning på Databricks. Den använder Spark för orkestrering och kan skalas till så många GPU:er som är tillgängliga i klustret.
- Mosaic StreamingDataset: StreamingDataset förbättrar prestanda och skalbarhet för träning på stora datamängder på Databricks med funktioner som förinläsning och interfoliering.
- MLflow: Med Mlflow kan du spåra parametrar, mått och modellkontrollpunkter.
- TorchRec: Moderna rekommenderade system använder inbäddning av uppslagstabeller för att hantera miljontals användare och objekt för att generera rekommendationer av hög kvalitet. Större inbäddningsstorlekar förbättrar modellens prestanda men kräver betydande GPU-minne och installationer för flera GPU:er. TorchRec tillhandahåller ett ramverk för att skala rekommendationsmodeller och uppslagstabeller över flera GPU:er, vilket gör det idealiskt för stora inbäddningar.
Exempel: Filmrekommendationer med hjälp av en tvåtornsmodellarkitektur
Modellen med två torn är utformad för att hantera storskaliga anpassningsuppgifter genom att bearbeta användar- och objektdata separat innan de kombineras. Det kan effektivt generera hundratals eller tusentals anständiga kvalitetsrekommendationer. Modellen förväntar sig vanligtvis tre indata: En user_id funktion, en product_id-funktion och en binär etikett som definierar om <användaren, produktinteraktion> var positiv (användaren köpte produkten) eller negativ (användaren gav produkten ett stjärnklassificering). Modellens utdata är inbäddningar för både användare och objekt, som sedan kombineras (ofta med hjälp av en punktprodukt eller cosinnalikhet) för att förutsäga interaktion med användarobjekt.
Eftersom tvåtornsmodellen innehåller inbäddningar för både användare och produkter kan du placera dessa inbäddningar i en vektordatabas, till exempel Databricks Vector Store, och utföra liknande sökliknande åtgärder på användare och objekt. Du kan till exempel placera alla objekt i ett vektorlager, och för varje användare kan du fråga vektorarkivet för att hitta de översta hundra objekten vars inbäddningar liknar användarens.
Följande exempelanteckningsbok implementerar tvåtornsmodellträningen med datauppsättningen "Learning from Sets of Items" för att förutsäga sannolikheten för att en användare kommer att betygsätta en viss film högt. Den använder Mosaic StreamingDataset för distribuerad datainläsning, TorchDistributor för distribuerad modellträning och Mlflow för modellspårning och loggning.
Modellanteckningsbok med två torn
Den här notebook-filen är också tillgänglig på Databricks Marketplace: Notebook-modellen med två torn
Kommentar
- Indata för tvåtornsmodellen är oftast de kategoriska funktionerna user_id och product_id. Modellen kan ändras för att stödja flera funktionsvektorer för både användare och produkter.
- Utdata för modellen med två torn är vanligtvis binära värden som anger om användaren kommer att ha en positiv eller negativ interaktion med produkten. Modellen kan ändras för andra program, till exempel regression, klassificering av flera klasser och sannolikheter för flera användaråtgärder (till exempel avvisa eller köpa). Komplexa utdata bör implementeras noggrant eftersom konkurrerande mål kan försämra kvaliteten på de inbäddningar som genereras av modellen.
Exempel: Träna en DLRM-arkitektur med hjälp av en syntetisk datauppsättning
DLRM är en toppmodern arkitektur för neurala nätverk som utformats specifikt för anpassnings- och rekommendationssystem. Den kombinerar kategoriska och numeriska indata för att effektivt modellera användarobjektinteraktioner och förutsäga användarinställningar. DLL:er förväntar sig vanligtvis indata som innehåller både glesa funktioner (till exempel användar-ID, objekt-ID, geografisk plats eller produktkategori) och täta funktioner (till exempel användarålder eller artikelpris). Utdata från en DLRM är vanligtvis en förutsägelse av användarengagemang, till exempel klickfrekvenser eller sannolikhet för köp.
DDLRM:er erbjuder ett mycket anpassningsbart ramverk som kan hantera storskaliga data, vilket gör det lämpligt för komplexa rekommendationsuppgifter i olika domäner. Eftersom det är en större modell än arkitekturen med två torn används den här modellen ofta i den nya fasen.
I följande exempel notebook-fil skapas en DLRM-modell för att förutsäga binära etiketter med hjälp av kompakta (numeriska) funktioner och glesa (kategoriska) funktioner. Den använder en syntetisk datamängd för att träna modellen, Mosaic StreamingDataset för distribuerad datainläsning, TorchDistributor för distribuerad modellträning och Mlflow för modellspårning och loggning.
DLRM-notebook-fil
Den här notebook-filen är också tillgänglig på Databricks Marketplace: DLRM Notebook.
Jämförelse av tvåtorns- och DLRM-modeller
Tabellen visar några riktlinjer för att välja vilken rekommenderande modell som ska användas.
| Modelltyp | Datamängdsstorlek som behövs för träning | Modellstorlek | Indatatyper som stöds | Utdatatyper som stöds | Användningsfall |
|---|---|---|---|---|---|
| Tvåtorn | Mindre | Mindre | Vanligtvis två funktioner (user_id, product_id) | Huvudsakligen generering av binär klassificering och inbäddning | Generera hundratals eller tusentals möjliga rekommendationer |
| DLRM | Större | Större | Olika kategoriska och kompakta funktioner (user_id, kön, geographic_location, product_id, product_category, ...) | Klassificering av flera klasser, regression, andra | Detaljerad hämtning (rekommenderar tiotals mycket relevanta objekt) |
Sammanfattningsvis används modellen med två torn bäst för att generera tusentals rekommendationer av god kvalitet mycket effektivt. Ett exempel kan vara filmrekommendationer från en kabelleverantör. DLRM-modellen används bäst för att generera mycket specifika rekommendationer baserat på mer data. Ett exempel kan vara en återförsäljare som vill presentera ett mindre antal artiklar för en kund som de är mycket benägna att köpa.