Självstudie: Distribuera och genomföra en förfrågan på en anpassad modell
Den här artikeln innehåller de grundläggande stegen för att distribuera och köra frågor mot en anpassad modell, som är en traditionell ML-modell, med hjälp av Mosaic AI Model Serving. Modellen måste vara registrerad i Unity Catalog eller i arbetsytemodellregistret.
Mer information om hur du betjänar och distribuerar generativa AI-modeller i stället finns i följande artiklar:
Steg 1: Logga modellen
Det finns olika sätt att registrera din modell för modellservering:
| Loggningsteknik | beskrivning |
|---|---|
| Automatisk loggning | Detta aktiveras automatiskt när du använder Databricks Runtime för maskininlärning. Det är det enklaste sättet men ger dig mindre kontroll. |
| Loggning med MLflows inbyggda funktioner | Du kan logga modellen manuellt med MLflows inbyggda modellsmaker. |
Anpassad loggning med pyfunc |
Använd detta om du har en anpassad modell eller om du behöver extra steg före eller efter slutsatsdragning. |
I följande exempel visas hur du loggar din MLflow-modell med hjälp av transformer-smaken och anger parametrar som du behöver för din modell.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
När modellen har loggats kontrollerar du att din modell har registrerats i antingen Unity Catalog eller MLflow Model Registry.
Steg 2: Skapa slutpunkt med hjälp av användargränssnittet för servering
När din registrerade modell har loggats och du är redo att hantera den kan du skapa en modell som betjänar slutpunkten med hjälp av användargränssnittet för servering .
Klicka på Servering i sidopanelen för att visa användargränssnittet för servering .
Klicka på Skapa tjänsteslutpunkt.
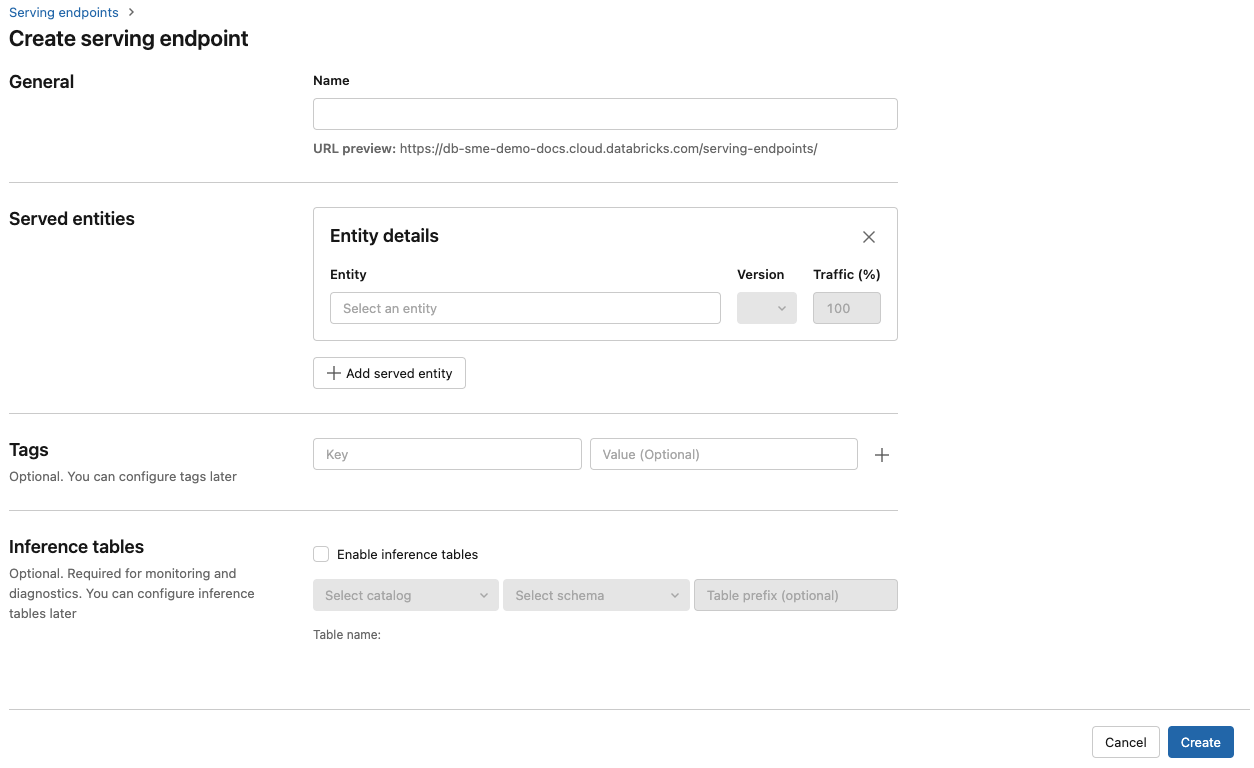
Ange ett namn för slutpunkten i fältet Namn .
I avsnittet Serverade entiteter
- Klicka i fältet Entitet för att öppna formuläret Välj hanterad entitet.
- Välj den typ av modell som du vill hantera. Formuläret uppdateras dynamiskt baserat på ditt val.
- Välj vilken modell och modellversion du vill tillhandahålla.
- Välj procentandelen trafik som ska dirigeras till din betjänade modell.
- Välj vilken storleksberäkning som ska användas.
- Under Beräkna utskalning, välj storleken på beräkningsskalningen som motsvarar antalet förfrågningar som den hanterade modellen kan bearbeta samtidigt. Detta tal bör vara ungefär lika med QPS multiplicerat med körningstiden för modellen.
- Tillgängliga storlekar är Små för 0–4 begäranden, Mellan 8–16 begäranden och Stor för 16–64 begäranden.
- Ange om slutpunkten ska skalas till noll när den inte används.
Klicka på Skapa. Sidan Serveringsslutpunkter visas med Serveringsslutpunktsstatus som Inte redo.
Om du föredrar att skapa en slutpunkt programmatiskt med Databricks-server-API:et kan du läsa Skapa anpassade modell som betjänar slutpunkter.
Steg 3: Fråga slutpunkten
Det enklaste och snabbaste sättet att testa och skicka poängförfrågningar till modellen som betjänas är att använda användargränssnittet för servering.
På sidan Serverslutpunkt väljer du Frågeslutpunkt.
Infoga modellens indata i JSON-format och klicka på Skicka begäran. Om modellen har loggats med ett indataexempel klickar du på Visa exempel för att läsa in indataexemplet.
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
Om du vill skicka bedömningsbegäranden skapar du en JSON med en av de nycklar som stöds och ett JSON-objekt som motsvarar indataformatet. Se Frågeserverslutpunkter för anpassade modeller för format som stöds och vägledning om hur du skickar bedömningsbegäranden med hjälp av API:et.
Om du planerar att komma åt din tjänsteslutpunkt utanför gränssnittet för Azure Databricks-tjänster behöver du en DATABRICKS_API_TOKEN.
Viktigt!
Som bästa säkerhet för produktionsscenarier rekommenderar Databricks att du använder OAuth-token från dator till dator för autentisering under produktion.
För testning och utveckling rekommenderar Databricks att du använder en personlig åtkomsttoken som tillhör tjänstens huvudnamn i stället för arbetsyteanvändare. Information om hur du skapar token för tjänstens huvudnamn finns i Hantera token för tjänstens huvudnamn.
Exempelanteckningsböcker
Se följande notebook-fil för att hantera en MLflow-modell transformers med modellservering.
Distribuera en notebook-modell för huggande ansiktstransformatorer
Se följande notebook-fil för att hantera en MLflow-modell pyfunc med modellservering. Mer information om hur du anpassar dina modelldistributioner finns i Distribuera Python-kod med modellservering.