Fråga grundläggande modeller
I den här artikeln får du lära dig hur du formaterar frågeförfrågningar för grundmodeller och skickar dem till din modell som betjänar slutpunkten. Du kan köra frågor mot grundmodeller som hanteras av Databricks och grundmodeller som finns utanför Databricks.
För traditionella ML- eller Python-modellers frågebegäranden, se Frågeserverslutpunkter för anpassade modeller.
Mosaic AI Model Serving stöder API:er för Foundation-modeller och externa modeller för åtkomst till grundmodeller. Modellservern använder ett enhetligt OpenAI-kompatibelt API och SDK för att köra frågor mot dem. Detta gör det möjligt att experimentera med och anpassa grundmodeller för produktion i moln och leverantörer som stöds.
Mosaic AI Model Serving innehåller följande alternativ för att skicka bedömningsbegäranden till slutpunkter som hanterar grundmodeller eller externa modeller:
| Metod | Details |
|---|---|
| OpenAI-klient | Fråga en modell som hanteras av en Mosaic AI Model Serving-slutpunkt med hjälp av OpenAI-klienten. Ange namnet på den modell som betjänar slutpunkten som model indata. Stöds för chatt-, inbäddnings- och slutförandemodeller som görs tillgängliga av Foundation Model-API:er eller externa modeller. |
| SQL-funktion | Anropa modellinferens direkt från SQL med hjälp av ai_query SQL-funktionen. Se Fråga en hanterad modell med ai_query. |
| Serveringsgränssnitt | Välj Frågeändpunkt på sidan Serverändpunkt. Infoga indata för JSON-formatmodellen och klicka på Skicka begäran. Om modellen har ett indataexempel loggat använder du Visa exempel för att läsa in det. |
| REST-API | Anropa och fråga modellen med hjälp av REST-API:et. Mer information finns i POST /serving-endpoints/{name}/invocations . Information om bedömning av begäranden till slutpunkter som betjänar flera modeller finns i Fråga efter enskilda modeller bakom en slutpunkt. |
| SDK för MLflow-distributioner | Använd SDK:s predict()-funktion för MLflow Deployments för att fråga modellen. |
| Databricks Python SDK | Databricks Python SDK är ett lager ovanpå REST-API:et. Den hanterar information på låg nivå, till exempel autentisering, vilket gör det enklare att interagera med modellerna. |
Krav
- En modell som betjänar slutpunkten.
- En Databricks-arbetsyta i en region som stöds.
- Om du vill skicka en bedömningsbegäran via OpenAI-klienten, REST API eller MLflow Deployment SDK måste du ha en Databricks API-token.
Viktigt!
Som bästa säkerhet för produktionsscenarier rekommenderar Databricks att du använder OAuth-token från dator till dator för autentisering under produktion.
För testning och utveckling rekommenderar Databricks att du använder en personlig åtkomsttoken som tillhör tjänstens huvudnamn i stället för arbetsyteanvändare. Information om hur du skapar token för tjänstens huvudnamn finns i Hantera token för tjänstens huvudnamn.
Installera paket
När du har valt en frågemetod måste du först installera rätt paket i klustret.
OpenAI-klient
Om du vill använda OpenAI-klienten databricks-sdk[openai] måste paketet installeras i klustret. Databricks SDK tillhandahåller en omslutning för att konstruera OpenAI-klienten med auktorisering som automatiskt konfigurerats för att fråga generativa AI-modeller. Kör följande i anteckningsboken eller den lokala terminalen:
!pip install databricks-sdk[openai]>=0.35.0
Följande krävs endast när du installerar paketet på en Databricks Notebook
dbutils.library.restartPython()
REST-API
Åtkomst till SERVERINGs-REST-API:et finns i Databricks Runtime for Machine Learning.
SDK för MLflow-distributioner
!pip install mlflow
Följande krävs endast när du installerar paketet på en Databricks Notebook
dbutils.library.restartPython()
Databricks Python SDK
Databricks SDK för Python är redan installerat på alla Azure Databricks-kluster som använder Databricks Runtime 13.3 LTS eller senare. För Azure Databricks-kluster som använder Databricks Runtime 12.2 LTS och nedan måste du först installera Databricks SDK för Python. Se Databricks SDK för Python.
Fråga efter en modell för chattens slutförande
Följande är exempel på frågor mot en chattmodell. Exemplet gäller frågor mot en chattmodell som görs tillgänglig med hjälp av någon av funktionerna för modellservering: Foundation Model-API:er eller externa modeller.
Ett exempel på batchinferens finns i Utföra batch-LLM-slutsatsdragning med hjälp av ai_query.
OpenAI-klient
Följande är en chattbegäran för DBRX Instruct-modellen som görs tillgänglig av Foundation Model-API:erna betala per token-slutpunkt på databricks-dbrx-instruct din arbetsyta.
Om du vill använda OpenAI-klienten anger du den modell som betjänar slutpunktens namn som model indata.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
response = openai_client.chat.completions.create(
model="databricks-dbrx-instruct",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is a mixture of experts model?",
}
],
max_tokens=256
)
Om du vill köra frågor mot grundmodeller utanför arbetsytan måste du använda OpenAI-klienten direkt. Du behöver också din Databricks-arbetsyteinstans för att ansluta OpenAI-klienten till Databricks. I följande exempel förutsätter vi att du har en Databricks API-token och openai är installerad på din beräkning.
import os
import openai
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.chat.completions.create(
model="databricks-dbrx-instruct",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "What is a mixture of experts model?",
}
],
max_tokens=256
)
REST-API
Viktigt!
I följande exempel används REST API-parametrar för att köra frågor mot serverslutpunkter som hanterar grundmodeller. De här parametrarna är för offentlig förhandsversion och definitionen kan ändras. Se POST /serving-endpoints/{name}/invocations.
Följande är en chattbegäran för DBRX Instruct-modellen som görs tillgänglig av Foundation Model-API:erna betala per token-slutpunkt på databricks-dbrx-instruct din arbetsyta.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": " What is a mixture of experts model?"
}
]
}' \
https://<workspace_host>.databricks.com/serving-endpoints/databricks-dbrx-instruct/invocations \
SDK för MLflow-distributioner
Viktigt!
I följande exempel används API:et predict()från MLflow Deployments SDK.
Följande är en chattbegäran för DBRX Instruct-modellen som görs tillgänglig av Foundation Model-API:erna betala per token-slutpunkt på databricks-dbrx-instruct din arbetsyta.
import mlflow.deployments
# Only required when running this example outside of a Databricks Notebook
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
chat_response = client.predict(
endpoint="databricks-dbrx-instruct",
inputs={
"messages": [
{
"role": "user",
"content": "Hello!"
},
{
"role": "assistant",
"content": "Hello! How can I assist you today?"
},
{
"role": "user",
"content": "What is a mixture of experts model??"
}
],
"temperature": 0.1,
"max_tokens": 20
}
)
Databricks Python SDK
Följande är en chattbegäran för DBRX Instruct-modellen som görs tillgänglig av Foundation Model-API:erna betala per token-slutpunkt på databricks-dbrx-instruct din arbetsyta.
Den här koden måste köras i en notebook-fil på din arbetsyta. Se Använda Databricks SDK för Python från en Azure Databricks-notebook-fil.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="databricks-dbrx-instruct",
messages=[
ChatMessage(
role=ChatMessageRole.SYSTEM, content="You are a helpful assistant."
),
ChatMessage(
role=ChatMessageRole.USER, content="What is a mixture of experts model?"
),
],
max_tokens=128,
)
print(f"RESPONSE:\n{response.choices[0].message.content}")
LangChain
Om du vill köra frågor mot en grundläggande modellslutpunkt med Hjälp av LangChain kan du använda klassen ChatDatabricks ChatModel och ange endpoint.
I följande exempel används ChatDatabricks klassen ChatModel i LangChain för att fråga Foundation Model-API:erna betala per token-slutpunkt, databricks-dbrx-instruct.
%pip install databricks-langchain
from langchain_core.messages import HumanMessage, SystemMessage
from databricks_langchain import ChatDatabricks
messages = [
SystemMessage(content="You're a helpful assistant"),
HumanMessage(content="What is a mixture of experts model?"),
]
llm = ChatDatabricks(endpoint_name="databricks-dbrx-instruct")
llm.invoke(messages)
SQL
Viktigt!
I följande exempel används den inbyggda SQL-funktionen ai_query. Den här funktionen är offentlig förhandsversion och definitionen kan ändras. Se Fråga en hanterad modell med ai_query.
Följande är en chattbegäran som meta-llama-3-1-70b-instruct görs tillgänglig av Foundation Model-API:erna betala per token-slutpunkt databricks-meta-llama-3-1-70b-instruct på din arbetsyta.
Kommentar
Funktionen ai_query() stöder inte frågeslutpunkter som betjänar DBRX- eller DBRX Instruct-modellen.
SELECT ai_query(
"databricks-meta-llama-3-1-70b-instruct",
"Can you explain AI in ten words?"
)
Följande är till exempel det förväntade formatet för begäran för en chattmodell när du använder REST-API:et. För externa modeller kan du inkludera ytterligare parametrar som är giltiga för en viss provider och slutpunktskonfiguration. Se Ytterligare frågeparametrar.
{
"messages": [
{
"role": "user",
"content": "What is a mixture of experts model?"
}
],
"max_tokens": 100,
"temperature": 0.1
}
Följande är ett förväntat svarsformat för en begäran som görs med hjälp av REST-API:et:
{
"model": "databricks-dbrx-instruct",
"choices": [
{
"message": {},
"index": 0,
"finish_reason": null
}
],
"usage": {
"prompt_tokens": 7,
"completion_tokens": 74,
"total_tokens": 81
},
"object": "chat.completion",
"id": null,
"created": 1698824353
}
Fråga en inbäddningsmodell
Följande är en inbäddningsbegäran för modellen gte-large-en som görs tillgänglig av Foundation Model API:er. Exemplet gäller frågor mot en inbäddningsmodell som görs tillgänglig med hjälp av någon av funktionerna för modellservering: Foundation Model-API:er eller externa modeller.
OpenAI-klient
Om du vill använda OpenAI-klienten anger du den modell som betjänar slutpunktens namn som model indata.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
response = openai_client.embeddings.create(
model="databricks-gte-large-en",
input="what is databricks"
)
Om du vill köra frågor mot grundmodeller utanför arbetsytan måste du använda OpenAI-klienten direkt, vilket visas nedan. I följande exempel förutsätter vi att du har en Databricks API-token och openai installerad på din beräkning. Du behöver också din Databricks-arbetsyteinstans för att ansluta OpenAI-klienten till Databricks.
import os
import openai
from openai import OpenAI
client = OpenAI(
api_key="dapi-your-databricks-token",
base_url="https://example.staging.cloud.databricks.com/serving-endpoints"
)
response = client.embeddings.create(
model="databricks-gte-large-en",
input="what is databricks"
)
REST-API
Viktigt!
I följande exempel används REST API-parametrar för att köra frågor mot serverdelsslutpunkter som hanterar grundmodeller eller externa modeller. De här parametrarna är för offentlig förhandsversion och definitionen kan ändras. Se POST /serving-endpoints/{name}/invocations.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{ "input": "Embed this sentence!"}' \
https://<workspace_host>.databricks.com/serving-endpoints/databricks-gte-large-en/invocations
SDK för MLflow-distributioner
Viktigt!
I följande exempel används API:et predict()från MLflow Deployments SDK.
import mlflow.deployments
export DATABRICKS_HOST="https://<workspace_host>.databricks.com"
export DATABRICKS_TOKEN="dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
embeddings_response = client.predict(
endpoint="databricks-gte-large-en",
inputs={
"input": "Here is some text to embed"
}
)
Databricks Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="databricks-gte-large-en",
input="Embed this sentence!"
)
print(response.data[0].embedding)
LangChain
Om du vill använda en Databricks Foundation-modell-API:er i LangChain som en inbäddningsmodell importerar DatabricksEmbeddings du klassen och anger parametern endpoint enligt följande:
%pip install databricks-langchain
from databricks_langchain import DatabricksEmbeddings
embeddings = DatabricksEmbeddings(endpoint="databricks-gte-large-en")
embeddings.embed_query("Can you explain AI in ten words?")
SQL
Viktigt!
I följande exempel används den inbyggda SQL-funktionen ai_query. Den här funktionen är offentlig förhandsversion och definitionen kan ändras. Se Fråga en hanterad modell med ai_query.
SELECT ai_query(
"databricks-gte-large-en",
"Can you explain AI in ten words?"
)
Följande är det förväntade begärandeformatet för en inbäddningsmodell. För externa modeller kan du inkludera ytterligare parametrar som är giltiga för en viss provider och slutpunktskonfiguration. Se Ytterligare frågeparametrar.
{
"input": [
"embedding text"
]
}
Följande är det förväntade svarsformatet:
{
"object": "list",
"data": [
{
"object": "embedding",
"index": 0,
"embedding": []
}
],
"model": "text-embedding-ada-002-v2",
"usage": {
"prompt_tokens": 2,
"total_tokens": 2
}
}
Kontrollera om inbäddningar är normaliserade
Använd följande för att kontrollera om inbäddningarna som genereras av din modell normaliseras.
import numpy as np
def is_normalized(vector: list[float], tol=1e-3) -> bool:
magnitude = np.linalg.norm(vector)
return abs(magnitude - 1) < tol
Fråga efter en modell för textkomplettering
OpenAI-klient
Viktigt!
Det går inte att köra frågor mot modeller för slutförande av text som görs tillgängliga med foundation model-API:er för betalning per token med OpenAI-klienten. Det går endast att köra frågor mot externa modeller med OpenAI-klienten, vilket visas i det här avsnittet.
Om du vill använda OpenAI-klienten anger du den modell som betjänar slutpunktens namn som model indata. I följande exempel efterfrågas slutförandemodellen claude-2 som hanteras av Anthropic med hjälp av OpenAI-klienten. Om du vill använda OpenAI-klienten fyller du i model fältet med namnet på den modell som betjänar slutpunkten som är värd för den modell som du vill fråga efter.
I det här exemplet används en tidigare skapad slutpunkt, anthropic-completions-endpoint, som konfigurerats för åtkomst till externa modeller från den antropiska modellprovidern. Se hur du skapar externa modellslutpunkter.
Se stödda modeller för ytterligare modeller du kan fråga och deras leverantörer.
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
openai_client = w.serving_endpoints.get_open_ai_client()
completion = openai_client.completions.create(
model="anthropic-completions-endpoint",
prompt="what is databricks",
temperature=1.0
)
print(completion)
REST-API
Följande är en slutförandebegäran för att köra frågor mot en slutförandemodell som görs tillgänglig med hjälp av externa modeller.
Viktigt!
I följande exempel används REST API-parametrar för att köra frågor mot serverslutpunkter som hanterar externa modeller. De här parametrarna är för offentlig förhandsversion och definitionen kan ändras. Se POST /serving-endpoints/{name}/invocations.
curl \
-u token:$DATABRICKS_TOKEN \
-X POST \
-H "Content-Type: application/json" \
-d '{"prompt": "What is a quoll?", "max_tokens": 64}' \
https://<workspace_host>.databricks.com/serving-endpoints/<completions-model-endpoint>/invocations
SDK för MLflow-distributioner
Följande är en slutförandebegäran för att köra frågor mot en slutförandemodell som görs tillgänglig med hjälp av externa modeller.
Viktigt!
I följande exempel används API:et predict()från MLflow Deployments SDK.
import os
import mlflow.deployments
# Only required when running this example outside of a Databricks Notebook
os.environ['DATABRICKS_HOST'] = "https://<workspace_host>.databricks.com"
os.environ['DATABRICKS_TOKEN'] = "dapi-your-databricks-token"
client = mlflow.deployments.get_deploy_client("databricks")
completions_response = client.predict(
endpoint="<completions-model-endpoint>",
inputs={
"prompt": "What is the capital of France?",
"temperature": 0.1,
"max_tokens": 10,
"n": 2
}
)
# Print the response
print(completions_response)
Databricks Python SDK
Följande är en slutförandebegäran för att köra frågor mot en slutförandemodell som görs tillgänglig med hjälp av externa modeller.
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import ChatMessage, ChatMessageRole
w = WorkspaceClient()
response = w.serving_endpoints.query(
name="<completions-model-endpoint>",
prompt="Write 3 reasons why you should train an AI model on domain specific data sets."
)
print(response.choices[0].text)
SQL
Viktigt!
I följande exempel används den inbyggda SQL-funktionen ai_query. Den här funktionen är offentlig förhandsversion och definitionen kan ändras. Se Fråga en hanterad modell med ai_query.
SELECT ai_query(
"<completions-model-endpoint>",
"Can you explain AI in ten words?"
)
Följande är det förväntade begärandeformatet för en slutförandemodell. För externa modeller kan du inkludera ytterligare parametrar som är giltiga för en viss provider och slutpunktskonfiguration. Se Ytterligare frågeparametrar.
{
"prompt": "What is mlflow?",
"max_tokens": 100,
"temperature": 0.1,
"stop": [
"Human:"
],
"n": 1,
"stream": false,
"extra_params":
{
"top_p": 0.9
}
}
Följande är det förväntade svarsformatet:
{
"id": "cmpl-8FwDGc22M13XMnRuessZ15dG622BH",
"object": "text_completion",
"created": 1698809382,
"model": "gpt-3.5-turbo-instruct",
"choices": [
{
"text": "MLflow is an open-source platform for managing the end-to-end machine learning lifecycle. It provides tools for tracking experiments, managing and deploying models, and collaborating on projects. MLflow also supports various machine learning frameworks and languages, making it easier to work with different tools and environments. It is designed to help data scientists and machine learning engineers streamline their workflows and improve the reproducibility and scalability of their models.",
"index": 0,
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 5,
"completion_tokens": 83,
"total_tokens": 88
}
}
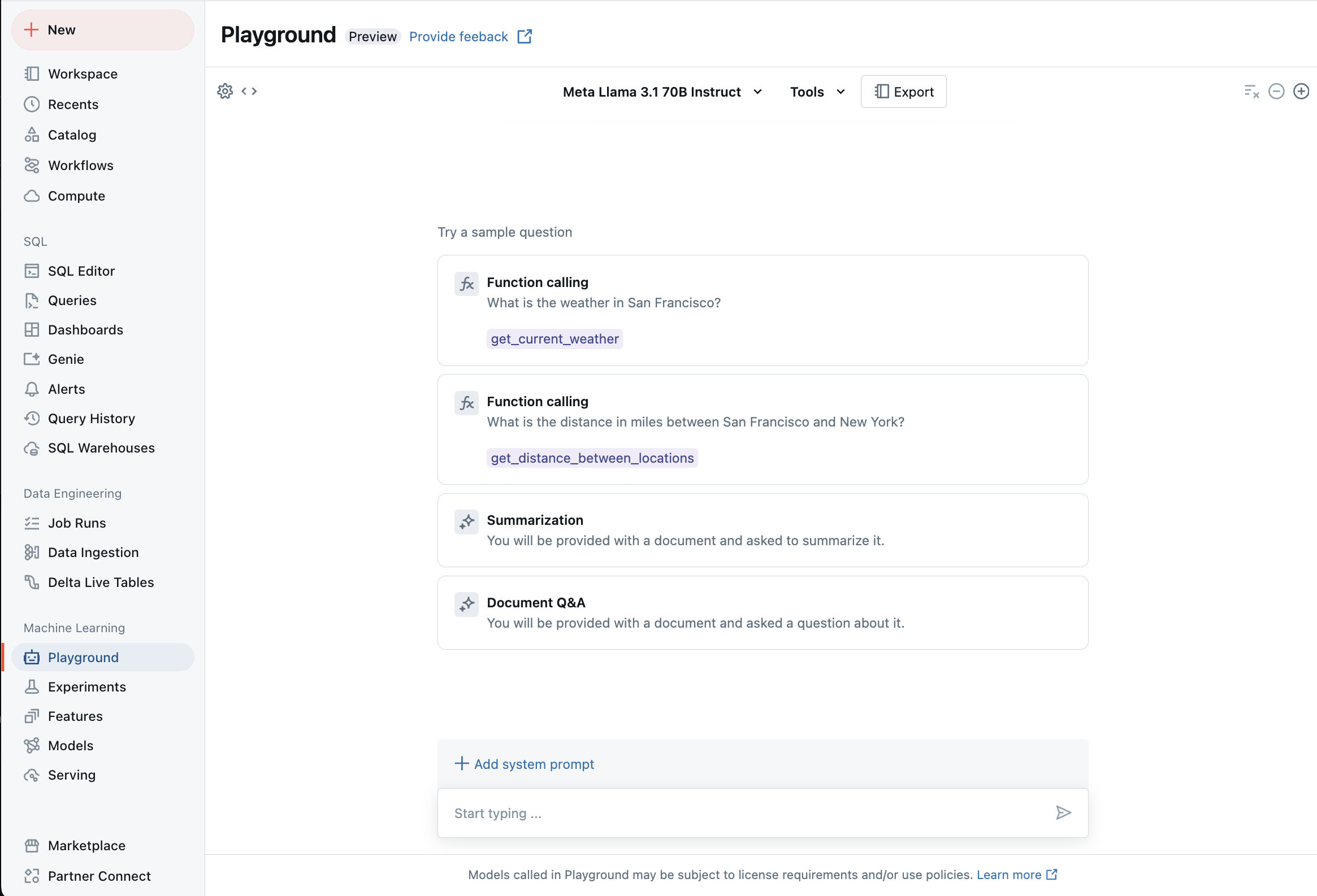
Chatta med LLM:er som stöds med AI Playground
Du kan interagera med stora språkmodeller som stöds med hjälp av AI Playground. AI Playground är en chattliknande miljö där du kan testa, fråga och jämföra LLM:er från din Azure Databricks-arbetsyta.
Ytterligare resurser
- Övervaka hanterade modeller med hjälp av AI Gateway-aktiverade slutsatsdragningstabeller
- Utföra batch-LLM-slutsatsdragning med hjälp av ai_query
- Grundmodell-API:er för Databricks
- Externa modeller i Mosaic AI Model Serving
- Självstudie: Skapa externa modellslutpunkter för att fråga OpenAI-modeller
- Modeller som stöds för pay-per-token
- Rest API-referens för foundation-modell