Skapa och hantera schemalagda notebook-jobb
Du kan skapa och hantera notebook-jobb direkt i notebook-användargränssnittet. Om en notebook-fil redan har tilldelats ett eller flera jobb kan du skapa och hantera scheman för dessa jobb. Om en notebook-fil inte har tilldelats ett jobb kan du skapa ett jobb och ett schema för att köra anteckningsboken. Mer information om schemaläggning av jobb finns i Köra jobb enligt ett schema.
Schemalägga ett notebook-jobb
Så här schemalägger du ett notebook-jobb så att det körs regelbundet:
Klicka på Schema längst upp till höger i anteckningsboken. Om det inte finns några jobb för den här anteckningsboken visas dialogrutan Schema.
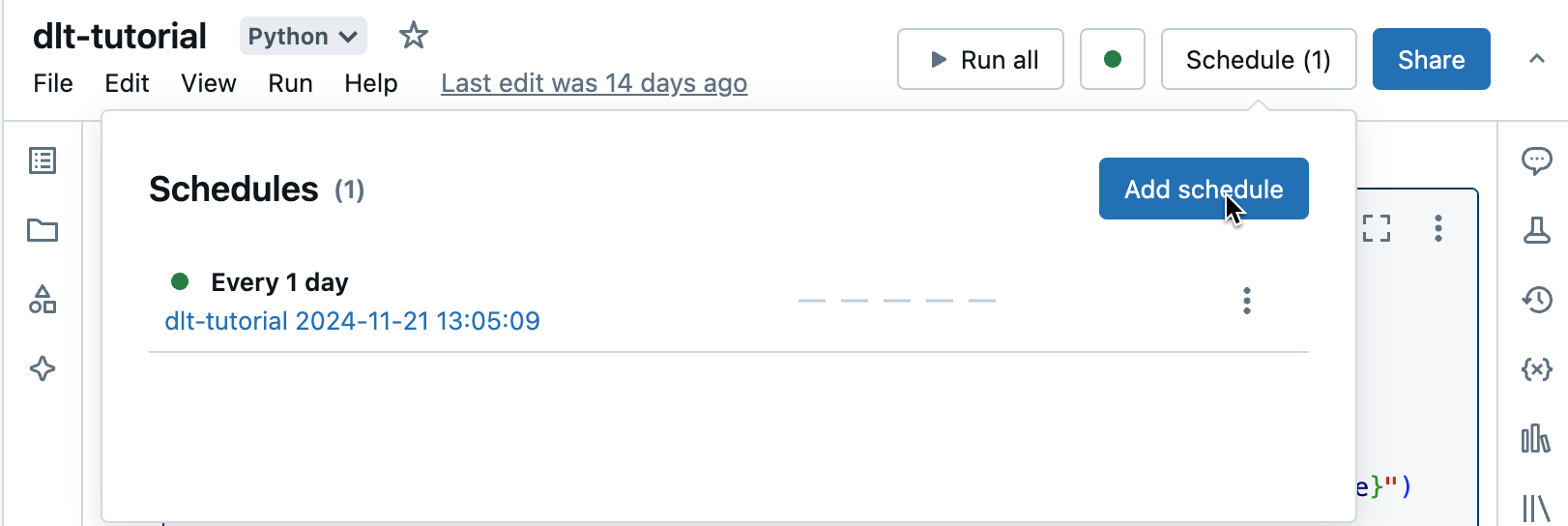
Om det redan finns jobb för anteckningsboken visas dialogrutan Jobb List. Om du vill visa dialogrutan Schema klickar du på Lägg till ett schema.
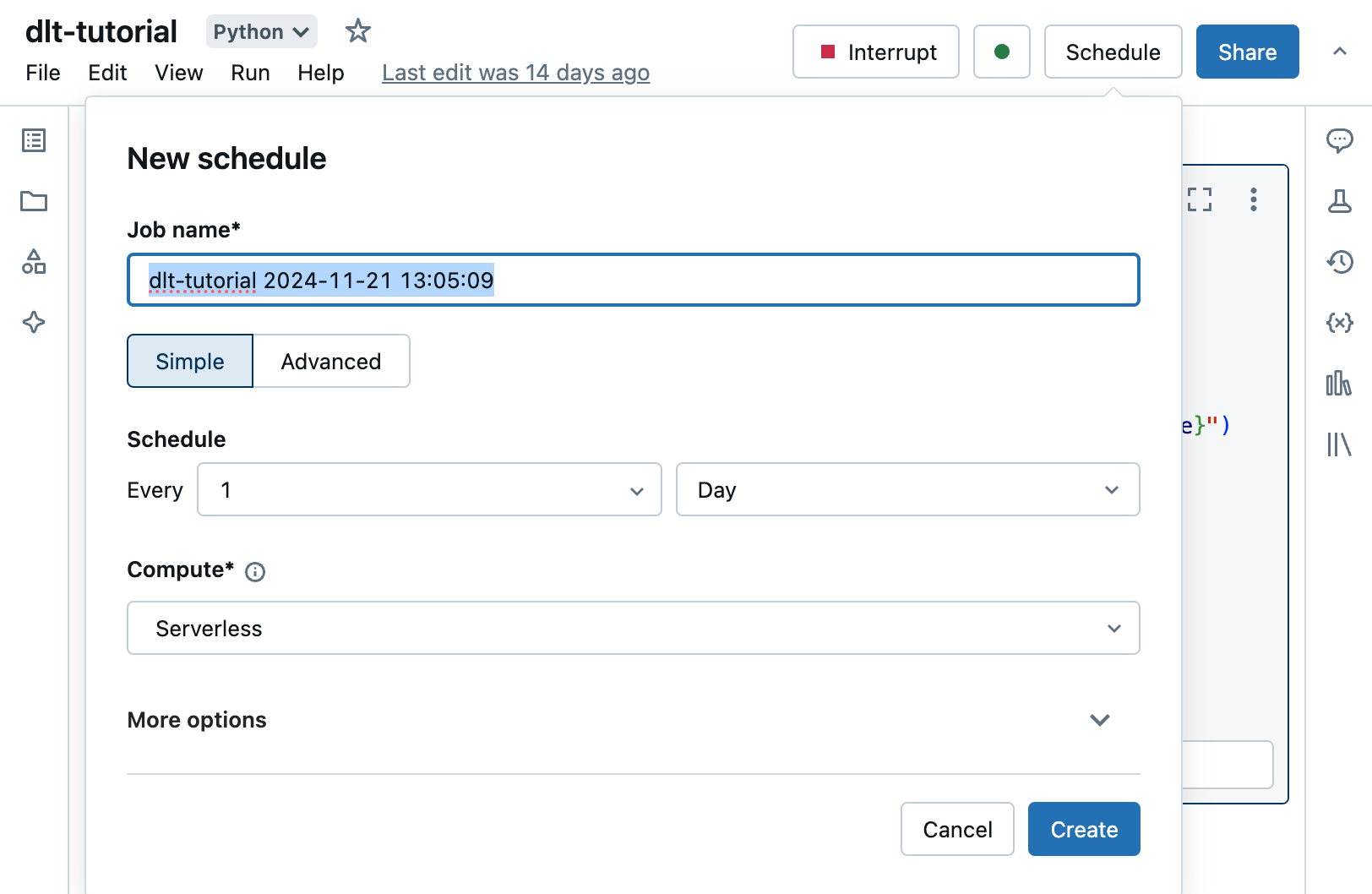
I dialogrutan Schema kan du ange ett namn för jobbet. Standardnamnet är namnet på anteckningsboken.
Select Enkel för att köra jobbet enligt ett enkelt schema, till exempel varje dag, eller Avancerat för att definiera ett anpassat schema för att köra jobbet, till exempel en viss tid varje dag. Använd listrutorna för att ange frekvensen. Om du väljer Avancerat kan du också använda cron-syntax för att ange frekvensen.
I listrutan Compute välj select beräkningsresursen för att köra uppgiften.
Om notebook-filen är kopplad till ett SQL-lager är standardberäkningen samma SQL-lager.
Om din arbetsyta är Unity Catalog-enabled och Serverless Jobs är aktiverat körs jobbet på serverlös beräkning som standard.
Annars, om du har Behörighet att skapa kluster , körs jobbet på ett nytt jobbkluster som standard. Om du vill redigera konfigurationen av standardjobbklustret klickar du på Redigera till höger om fältet för att visa dialogrutan för klusterkonfiguration. Om du inte har behörighet att skapa kluster körs jobbet på det kluster som notebook-filen är kopplad till som standard. Om notebook-filen inte är ansluten till ett kluster måste du select ett kluster från listrutan Kluster.
Under Fler alternativ kan du också ange e-postadresser för att ta emot aviseringar om jobbhändelser. Se Lägg till meddelanden på ett jobb.
Valfritt, under Fler alternativ, kan du ange vilka Parameters som ska skickas till jobbet. Klicka på Lägg till och ange nyckeln och värdet för varje parameter. Parameters set värdet för notebook-widgeten som anges av parameterns nyckel. Använd dynamiska värdereferenser för att skicka en begränsad set av dynamiska values som en del av ett parametervärde.
Klicka på Skapa.
Köra ett notebook-jobb
Så här kör du ett notebook-jobb manuellt:
- Klicka på Schema längst upp till höger i anteckningsboken.
- Klicka
 bredvid det schemalagda jobbet och klicka sedan på Kör nu.
bredvid det schemalagda jobbet och klicka sedan på Kör nu. - Om du vill visa information om jobbkörningen klickar du på jobbnamnet.
Hantera schemalagda notebook-jobb
Om du vill visa jobb som är associerade med den här anteckningsboken klickar du på knappen Schema . Dialogrutan jobb list visas som visar alla jobb som för närvarande har definierats för den här notebook-filen. Om du vill hantera jobb klickar du på menyn ![]() till höger om ett jobb i list.
till höger om ett jobb i list.
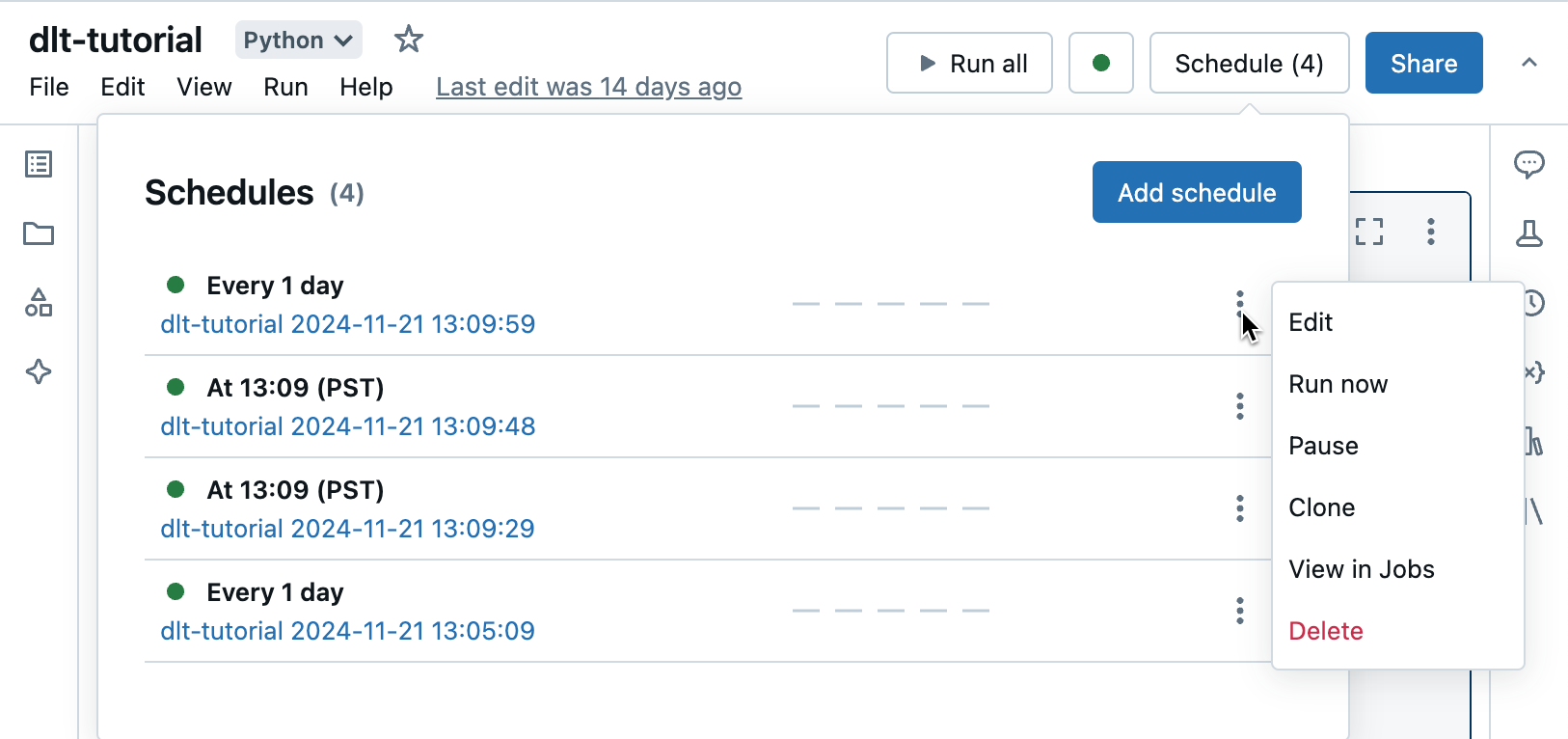
På den här menyn kan du redigera schemat, klona jobbet, visa jobbkörningsinformation, pausa jobbet, återuppta jobbet eller ta bort ett schemalagt jobb.
När du klonar ett schemalagt jobb skapas ett nytt jobb med samma parameters som originalet. Det nya jobbet visas i list med namnet Clone of <initial job name>.
Hur du redigerar ett jobb beror på komplexiteten i jobbets schema. Antingen visas dialogrutan Schema eller panelen jobbinformation så att du kan redigera schemat, klustret, parametersoch så vidare. Se Automatisering av jobb med scheman och händelseutlösare.