LLMOps-arbetsflöden på Azure Databricks
Den här artikeln kompletterar MLOps-arbetsflöden på Databricks genom att lägga till information som är specifik för LLMOps-arbetsflöden. Mer information finns i The Big Book of MLOps.
Hur ändras MLOps-arbetsflödet för LLM:er?
LLM:er är en klass av NLP-modeller (natural language processing) som avsevärt har överskridit sina föregångares storlek och prestanda i en mängd olika uppgifter, till exempel öppen fråga, sammanfattning och körning av instruktioner.
Utveckling och utvärdering av LLM skiljer sig på några viktiga sätt från traditionella ML-modeller. Det här avsnittet sammanfattar kort några av de viktigaste egenskaperna för LLM:er och konsekvenserna för MLOps.
| Viktiga egenskaper för LLM:er | Konsekvenser för MLOps |
|---|---|
| LLM:er är tillgängliga i många former. – Allmänna proprietära modeller och OSS-modeller som används med hjälp av betalda API:er. – Färdiga öppen källkod modeller som varierar från allmänna till specifika program. – Anpassade modeller som har finjusterats för specifika program. – Anpassade förtränade program. |
Utvecklingsprocess: Projekt utvecklas ofta stegvis, från befintliga modeller från tredje part eller öppen källkod och slutar med anpassade finjusterade modeller. |
| Många LLM:er tar allmänna frågor och instruktioner för naturligt språk som indata. Dessa frågor kan innehålla noggrant utformade uppmaningar för att få fram önskade svar. | Utvecklingsprocess: Att utforma textmallar för frågor mot LLM är ofta en viktig del i utvecklingen av nya LLM-pipelines. Paketering av ML-artefakter: Många LLM-pipelines använder befintliga LLM- eller LLM-serverslutpunkter. ML-logiken som utvecklats för dessa pipelines kan fokusera på promptmallar, agenter eller kedjor i stället för själva modellen. ML-artefakterna som paketeras och befordras till produktion kan vara dessa pipelines i stället för modeller. |
| Många LLM:er kan få frågor med exempel, kontext eller annan information som hjälper dig att besvara frågan. | Betjänar infrastruktur: När du utökar LLM-frågor med kontext kan du använda ytterligare verktyg, till exempel vektordatabaser, för att söka efter relevant kontext. |
| API:er från tredje part tillhandahåller proprietära modeller med öppen källkod. | API-styrning: Genom att använda centraliserad API-styrning kan du enkelt växla mellan API-leverantörer. |
| LLM:er är mycket stora djupinlärningsmodeller, som ofta sträcker sig från gigabyte till hundratals gigabyte. | Infrastruktur för servering: LLM:er kan kräva GPU:er för realtidsmodellservering och snabb lagring för modeller som behöver läsas in dynamiskt. Kostnads-/prestandaavvägningar: Eftersom större modeller kräver mer beräkning och är dyrare att hantera kan det krävas tekniker för att minska modellstorleken och beräkningen. |
| LLM:er är svåra att utvärdera med hjälp av traditionella ML-mått eftersom det ofta inte finns något enda "rätt" svar. | Mänsklig feedback: Mänsklig feedback är avgörande för utvärdering och testning av LLM:er. Du bör införliva användarfeedback direkt i MLOps-processen, inklusive för testning, övervakning och framtida finjustering. |
Likheter mellan MLOps och LLMOps
Många aspekter av MLOps-processer ändras inte för LLM:er. Följande riktlinjer gäller till exempel även för LLM:er:
- Använd separata miljöer för utveckling, mellanlagring och produktion.
- Använd Git för versionskontroll.
- Hantera modellutveckling med MLflow och använd Modeller i Unity Catalog för att hantera modellens livscykel.
- Lagra data i en lakehouse-arkitektur med hjälp av Delta-tabeller.
- Din befintliga CI/CD-infrastruktur bör inte kräva några ändringar.
- MlOps modulära struktur förblir densamma, med pipelines för funktionalisering, modellträning, modellinferens och så vidare.
Referensarkitekturdiagram
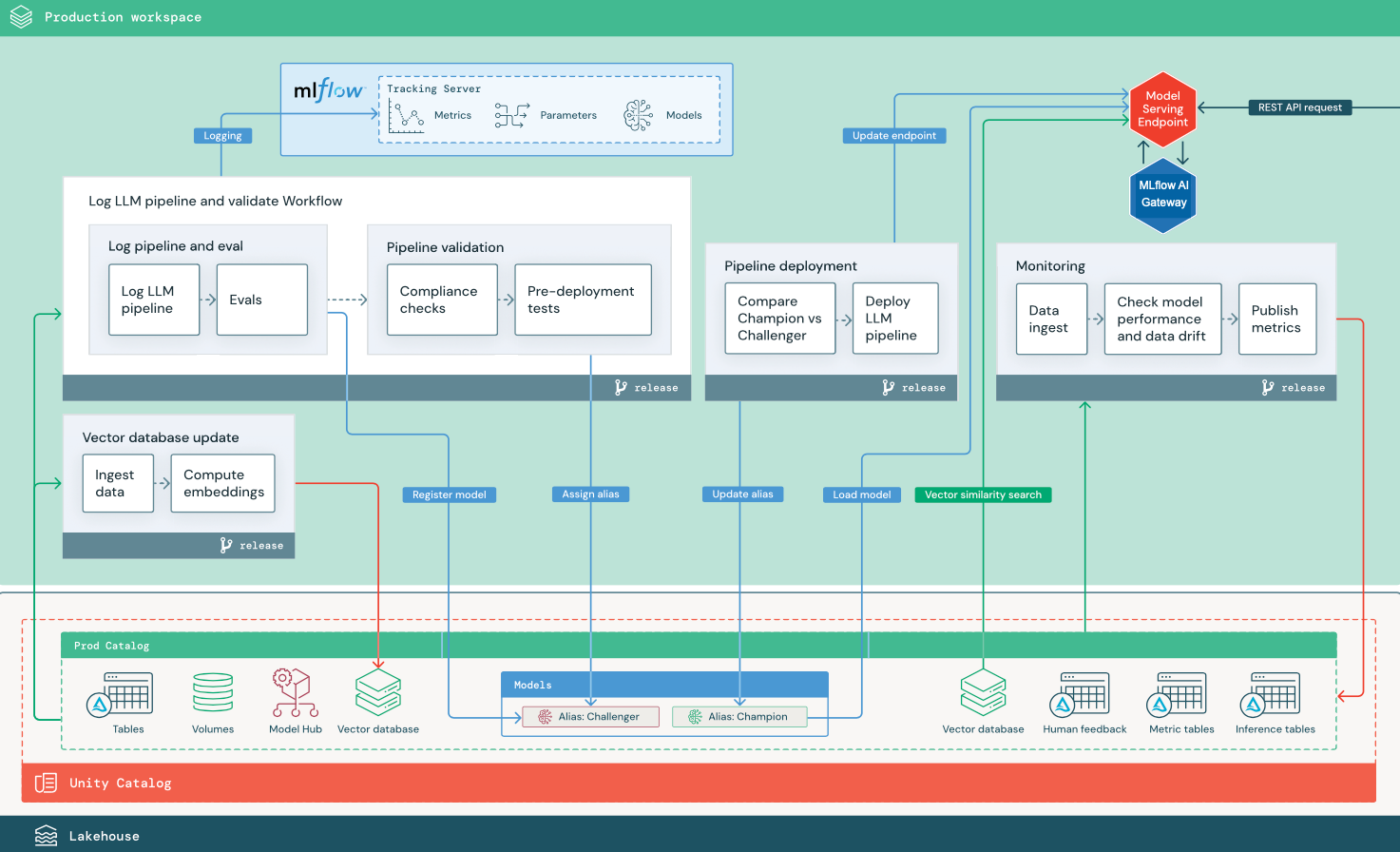
I det här avsnittet används två LLM-baserade program för att illustrera några av justeringarna i referensarkitekturen för traditionella MLOps. Diagrammen visar produktionsarkitekturen för 1) ett RAG-program (retrieval augmented generation) med hjälp av ett API från tredje part och 2) ett RAG-program med hjälp av en finjusterad modell med egen värd. Båda diagrammen visar en valfri vektordatabas – det här objektet kan ersättas genom att fråga LLM direkt via slutpunkten Modellserver.
RAG med ett LLM-API från tredje part
Diagrammet visar en produktionsarkitektur för ett RAG-program som ansluter till ett LLM-API från tredje part med databricks externa modeller.
RAG med en finjusterad öppen källkod modell
Diagrammet visar en produktionsarkitektur för ett RAG-program som finjusterar en öppen källkod modell.
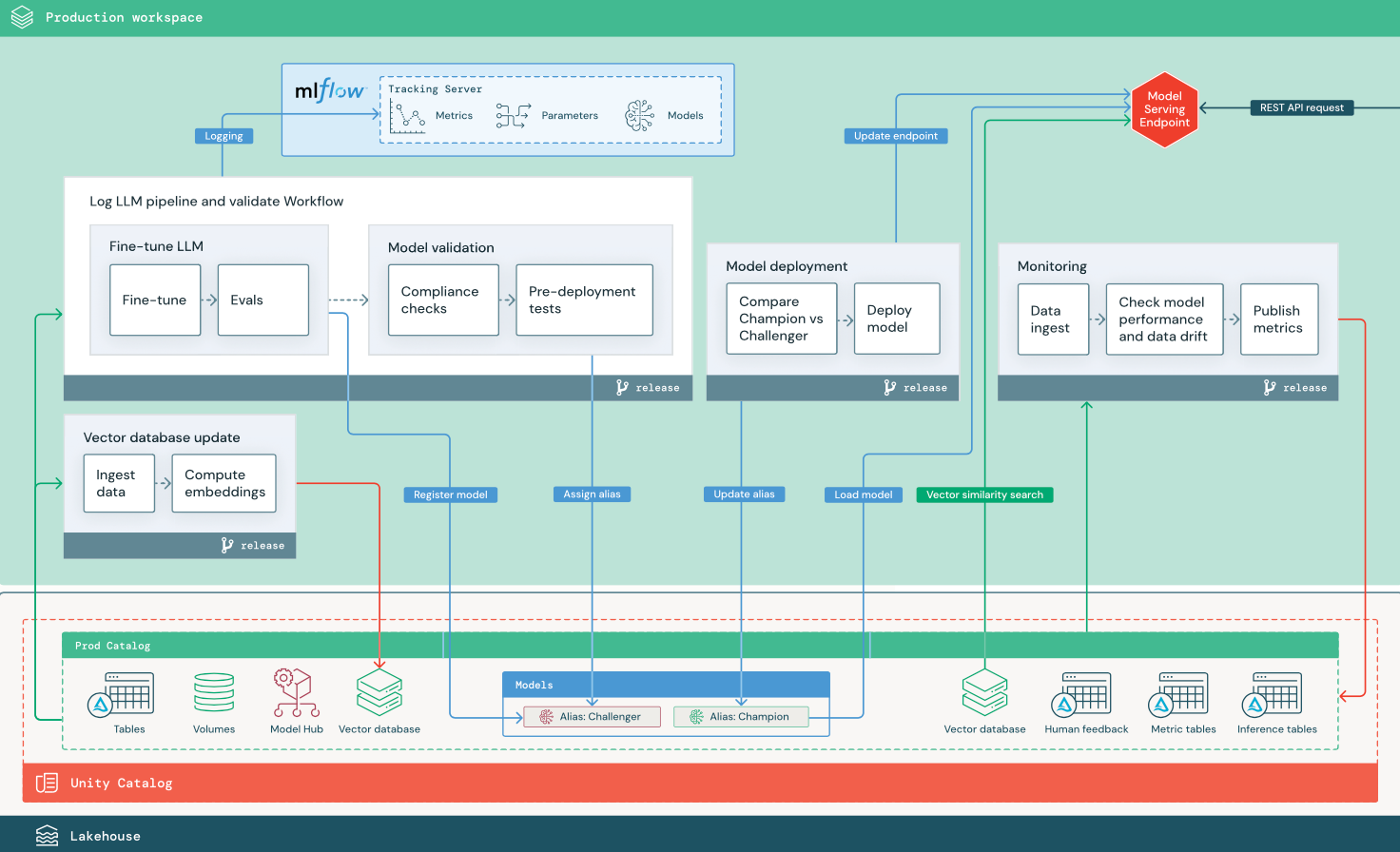
LLMOps-ändringar i MLOps-produktionsarkitektur
I det här avsnittet beskrivs de viktigaste ändringarna i MLOps-referensarkitekturen för LLMOps-program.
Modellhubben
LLM-program använder ofta befintliga, förträade modeller som valts från en intern eller extern modellhubb. Modellen kan användas som den är eller finjusteras.
Databricks innehåller ett urval av högkvalitativa, förtränade grundmodeller i Unity Catalog och På Databricks Marketplace. Du kan använda dessa förtränade modeller för att få åtkomst till toppmoderna AI-funktioner, vilket sparar tid och kostnader för att skapa egna anpassade modeller. Mer information finns i Förtränade modeller i Unity Catalog och Marketplace.
Vektordatabas
Vissa LLM-program använder vektordatabaser för snabba likhetssökningar, till exempel för att ge kontext- eller domänkunskap i LLM-frågor. Databricks tillhandahåller en integrerad vektorsökningsfunktion som gör att du kan använda alla Delta-tabeller i Unity Catalog som en vektordatabas. Vektorsökningsindexet synkroniseras automatiskt med Delta-tabellen. Mer information finns i Vektorsökning.
Du kan skapa en modellartefakt som kapslar in logiken för att hämta information från en vektordatabas och tillhandahåller returnerade data som kontext till LLM. Du kan sedan logga modellen med modellsmaken MLflow LangChain eller PyFunc.
Finjustera LLM
Eftersom LLM-modeller är dyra och tidskrävande att skapa från grunden finjusterar LLM-program ofta en befintlig modell för att förbättra dess prestanda i ett visst scenario. I referensarkitekturen representeras finjustering och modelldistribution som distinkta Databricks-jobb. Att verifiera en finjusterad modell innan du distribuerar är ofta en manuell process.
Databricks tillhandahåller grundläggande modell finjustering, vilket gör att du kan använda dina egna data för att anpassa en befintlig LLM för att optimera dess prestanda för ditt specifika program. Mer information finns i Finjustering av grundmodell.
Modellservering
I RAG med hjälp av ett API-scenario från tredje part är en viktig arkitekturändring att LLM-pipelinen gör externa API-anrop, från slutpunkten modellserver till interna ELLER externa LLM-API:er. Detta lägger till komplexitet, potentiell svarstid och ytterligare hantering av autentiseringsuppgifter.
Databricks tillhandahåller Mosaic AI Model Serving, som tillhandahåller ett enhetligt gränssnitt för att distribuera, styra och fråga AI-modeller. Mer information finns i Mosaik AI-modellservering.
Mänsklig feedback vid övervakning och utvärdering
Mänskliga feedbackslingor är viktiga i de flesta LLM-program. Mänsklig feedback bör hanteras som andra data, helst införlivade i övervakning baserat på direktuppspelning i nära realtid.
Granskningsappen Mosaic AI Agent Framework hjälper dig att samla in feedback från mänskliga granskare. Mer information finns i Få feedback om kvaliteten på ett agentiskt program.