Vad innebär intervall för antal token per sekund i tillhandahållet dataflöde?
Den här artikeln beskriver hur och varför Databricks mäter token per sekund för etablerade dataflödesarbetsbelastningar för Foundation Model-API:er.
Prestanda för stora språkmodeller mäts ofta i termer av token per sekund. När du konfigurerar produktionsmodell som betjänar slutpunkter är det viktigt att tänka på antalet begäranden som programmet skickar till slutpunkten. Det hjälper dig att förstå om slutpunkten behöver konfigureras för skalning för att inte påverka svarstiden.
När man konfigurerar utskalningsintervallen för slutpunkter som distribuerats med tilldelad genomströmning fann Databricks att det var lättare att resonera om indata som gick in i systemet med hjälp av tokens.
Vad är token?
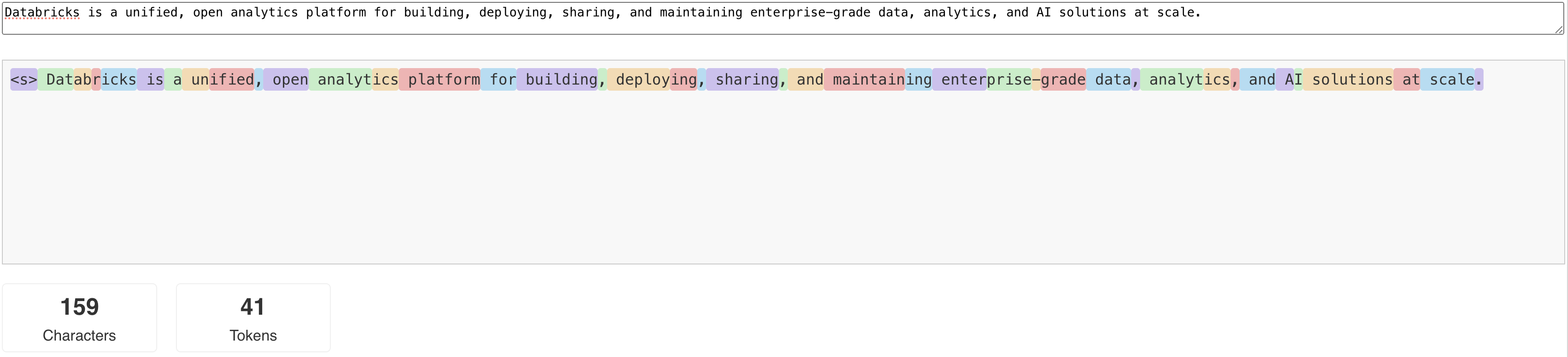
LLM:er läser och genererar text när det gäller vad som kallas en token. Token kan vara ord eller underord, och de exakta reglerna för att dela upp text i token varierar från modell till modell. Du kan till exempel använda onlineverktyg för att se hur Llamas tokenizer konverterar ord till token.
Följande diagram visar ett exempel på hur Llama-tokeniseraren delar upp text:
Varför mäta LLM-prestanda när det gäller token per sekund?
Traditionellt konfigureras serverslutpunkter baserat på antalet samtidiga begäranden per sekund (RPS). En LLM-slutsatsdragningsbegäran tar dock en annan tid baserat på hur många token som skickas in och hur många som genereras, vilket kan vara obalanserat mellan begäranden. För att avgöra hur mycket din slutpunkt behöver skalas ut, måste du i själva verket mäta detta i förhållande till innehållet i din begäran – poletter.
Olika användningsfall har olika nyckeltal för in- och utdatatoken:
- Varierande längd på indatakontexter: Även om vissa begäranden bara omfattar några få indatatoken, till exempel en kort fråga, kan andra omfatta hundratals eller till och med tusentals token, som ett långt dokument för sammanfattning. Den här variabiliteten gör det bara svårt att konfigurera en serverslutpunkt baserat på RPS eftersom den inte tar hänsyn till de olika bearbetningskraven för de olika begärandena.
- Varierande längd på utdata beroende på användningsfall: Olika användningsfall för LLM:er kan leda till mycket olika utdatatokens längd. Att generera utdatatoken är den mest tidsintensiva delen av LLM-slutsatsdragningen, så detta kan påverka dataflödet dramatiskt. Sammanfattning innebär till exempel kortare och slagkraftiga svar, medan textgenerering, som att skriva artiklar eller produktbeskrivningar, kan generera mycket längre svar.
Hur väljer jag tokens per sekund-intervall för min slutpunkt?
Etablerade dataflödesserverslutpunkter konfigureras i termer av ett intervall med token per sekund som du kan skicka till slutpunkten. Slutpunkten skalas upp och ned för att hantera belastningen på ditt produktionsprogram. Du debiteras per timme baserat på det intervall med token per sekund som slutpunkten skalas till.
Det bästa sättet att veta vilka token per sekund-intervall på ditt etablerade dataflöde som betjänar slutpunkten fungerar för ditt användningsfall är att utföra ett belastningstest med en representativ datauppsättning. Se Utför din egna LLM-slutpunktsmätning.
Det finns två viktiga faktorer att tänka på:
- Hur Databricks mäter LLM:s prestanda i antal tokens per sekund.
- Så här fungerar autoskalning.
Hur Databricks mäter prestanda för token per sekund för LLM
Databricks mäter prestandan hos slutpunkter mot en jobb som representerar sammanfattningsuppgifter, vilka är vanliga i användningsfall för generering med förstärkt sökning. Mer specifikt består arbetsbelastningen av:
- 2048-indatatoken
- 256 utdatatoken
De tokenintervall som visas kombinera dataflöde för indata- och utdatatoken och som standard optimera för att balansera dataflöde och svarstid.
Databricks-benchmarkar visar att användarna kan skicka det antalet tokens per sekund samtidigt till den specifika slutpunkten med en batchstorlek på 1 för varje begäran. Detta simulerar flera begäranden som når slutpunkten samtidigt, vilket mer exakt representerar hur du faktiskt skulle använda slutpunkten i produktionen.
- Om till exempel ett etablerat dataflöde som betjänar slutpunkten har en fast frekvens på 2 304 token per sekund (2048 + 256), förväntas det ta ungefär en sekund att köra en enskild begäran med indata på 2 048 token och förväntade utdata på 256 token.
- Om frekvensen är inställd på 5600 kan du på samma sätt förvänta dig att en enskild begäran, med antalet indata- och utdatatoken ovan, tar cirka 0,5 sekunder att köra . Det är slutpunkten som kan bearbeta två liknande begäranden på ungefär en sekund.
Om din arbetsbelastning varierar från ovanstående kan du förvänta dig att svarstiden varierar med avseende på den angivna etablerade dataflödeshastigheten. Som tidigare nämnts är det mer tidsintensivt att generera fler utdatatoken än att inkludera fler indatatoken. Om du utför batchinferens och vill uppskatta hur lång tid det tar att slutföra kan du beräkna det genomsnittliga antalet indata- och utdatatoken och jämföra med Databricks benchmark-arbetsbelastningen ovan.
- Om du till exempel har 1 000 rader, med ett genomsnittligt antal indatatoken på 3 000 och ett genomsnittligt antal utdatatoken på 500 och ett etablerat dataflöde på 3 500 token per sekund, kan det ta längre än totalt 1 000 sekunder (en sekund per rad) på grund av att dina genomsnittliga tokenantal är större än Databricks-riktmärket.
- Om du har 1 000 rader, en genomsnittlig inmatning på 1 500 token, ett genomsnittligt utdata på 100 token och ett etablerat dataflöde på 1 600 token per sekund kan det ta färre än 1 000 sekunder totalt (en sekund per rad) på grund av att dina genomsnittliga tokenantal är mindre än Databricks-riktmärket.
Om du vill beräkna det ideala etablerade dataflödet som behövs för att slutföra batchslutsatsens slutsatsdragning kan du använda notebook-filen i Utföra batch-LLM-slutsatsdragning med hjälp av ai_query
Så här fungerar automatisk skalning
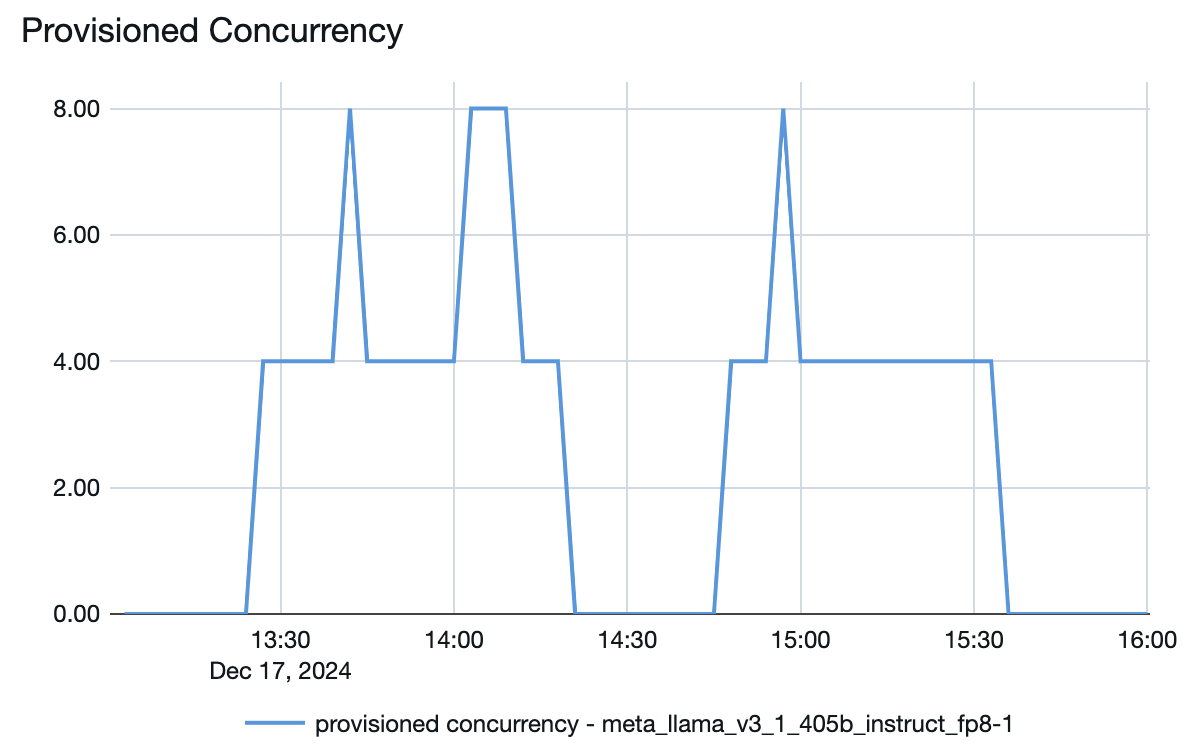
Modellserving har ett snabbt autoskalningssystem som skalar de underliggande beräkningsresurserna för att möta din applikations tokens per sekund-behov. Databricks skalar upp etablerat dataflöde i segment med token per sekund, så du debiteras endast för ytterligare enheter med etablerat dataflöde när du använder dem.
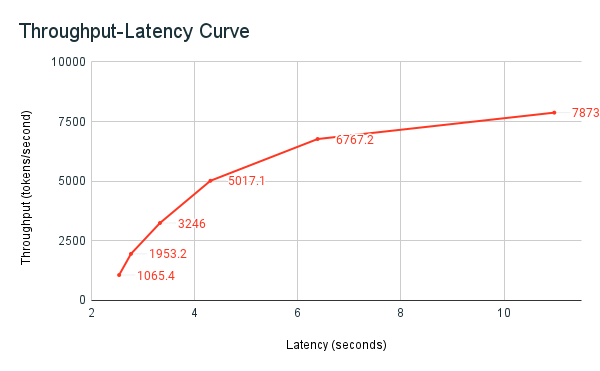
Följande diagram med svarstid för dataflöde visar en testad etablerad dataflödesslutpunkt med ett ökande antal parallella begäranden. Den första punkten representerar en begäran, den andra, två parallella begäranden, den tredje, fyra parallella begäranden och så vidare. När antalet begäranden ökar, och i sin tur token per sekund, ser du att även den tilldelade genomströmningen ökar. Den här ökningen anger att automatisk skalning ökar den tillgängliga beräkningen. Du kan dock börja se att dataflödet börjar plana ut och når en gräns på ~8 000 token per sekund när fler parallella begäranden läggs till. Den totala svarstiden ökar eftersom fler begäranden måste vänta i kön innan de bearbetas eftersom den tilldelade beräkningen används samtidigt.
Not
Du kan hålla genomströmningen konsekvent genom att stänga av automatisk nedskalning till noll och konfigurera en minimal genomströmning på tjänstslutpunkten. På så sätt undviker du behovet av att vänta tills slutpunkten ska skalas upp.
Du kan också se från modellens serverslutpunkt hur resurserna spunnits upp eller ned beroende på efterfrågan: