Utför din egen LLM-slutpunktsmätning
Den här artikeln innehåller ett Databricks-rekommenderat notebook-exempel för benchmarking av en LLM-slutpunkt. Den innehåller också en kort introduktion till hur Databricks utför LLM-slutsatsdragning och beräknar svarstid och dataflöde som slutpunktsprestandamått.
LLM-slutsatsdragning på Databricks mäter token per sekund för etablerat dataflödesläge för Foundation Model-API:er. Se Vad innebär intervallet av token per sekund inom etablerad dataflöde?.
Exempelanteckningsbok för benchmarking
Du kan importera följande notebook-fil till Din Databricks-miljö och ange namnet på LLM-slutpunkten för att köra ett belastningstest.
Prestandatest av en LLM-endpoint
introduktion till LLM-slutsatsdragning
LLM:er utför slutsatsdragning i en tvåstegsprocess:
- Prefillbearbetas where token i indataprompten parallellt.
- Avkodning, where text skapas en token i taget på ett autoregressivt sätt. Varje genererad token läggs till i indata och matas tillbaka till modellen för att generate nästa token. Genereringen stoppas när LLM matar ut en särskild stopptoken eller när ett användardefinierat villkor uppfylls.
De flesta produktionsprogram har en svarstidsbudget och Databricks rekommenderar att du maximerar dataflödet med tanke på svarstidsbudgeten.
- Antalet indatatoken har en betydande inverkan på det minne som krävs för att bearbeta begäranden.
- Antalet utdatatoken dominerar den övergripande svarsfördröjningen.
Databricks delar in LLM-slutsatsdragningen i följande undermått:
- Time to first token (TTFT): Så här snabbt kan användarna börja se modellens resultat när de har angett sin fråga. Låga väntetider för ett svar är viktiga i realtidsinteraktioner, men mindre viktiga i offlinearbetsbelastningar. Det här måttet bestäms av den tid som krävs för att bearbeta uppmaningen och sedan generate den första utgångstoken.
- Tid per utdatatoken (TPOT): Tid för att generate en utdatatoken för varje användare som ställer frågor till systemet. Det här måttet motsvarar hur varje användare uppfattar modellens "hastighet". En TPOT på 100 millisekunder per token skulle till exempel vara 10 token per sekund eller ~450 ord per minut, vilket är snabbare än en vanlig person kan läsa.
Baserat på dessa mått kan total svarstid och dataflöde definieras på följande sätt:
- Svarstid = TTFT + (TPOT) * (antalet token som ska genereras)
- Dataflöde = antal utdatatoken per sekund för alla samtidighetsbegäranden
I Databricks kan LLM-serverslutpunkter skalas så att de matchar belastningen som skickas av klienter med flera samtidiga begäranden. Det finns en kompromiss mellan svarstid och dataflöde. Det beror på att samtidiga begäranden kan behandlas samtidigt på slutpunkter för LLM-server. Vid låga samtidiga begärandebelastningar är svarstiden den lägsta möjliga. Men om du ökar belastningen på begäran kan svarstiden öka, men dataflödet ökar sannolikt också. Det beror på att två begäranden med token per sekund kan bearbetas på mindre än dubbelt så lång tid.
Därför är det grundläggande att kontrollera antalet parallella begäranden i systemet för att balansera svarstid med dataflöde. Om du har ett användningsfall med låg svarstid vill du skicka färre samtidiga begäranden till slutpunkten för att hålla svarstiden låg. Om du har ett användningsfall med högt dataflöde vill du mätta slutpunkten med många samtidighetsbegäranden, eftersom högre dataflöde är värt det även på bekostnad av svarstiden.
- Användningsfall med högt dataflöde kan omfatta batchinferenser och andra icke-användarinriktade uppgifter.
- Användningsfall med låg svarstid kan innehålla realtidsprogram som kräver omedelbara svar.
Databricks benchmarking-verktyg
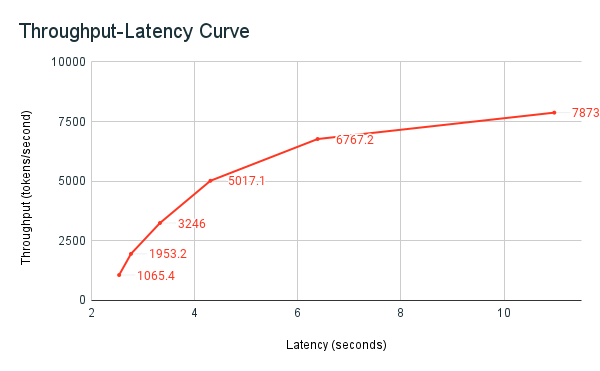
Den tidigare delade benchmark-exempelboken är Databricks benchmarking-verktyg. Notebook-filen visar totala svarstid för alla begäranden och genomströmningsmått och diagrammerar kurvan för genomströmning kontra svarstid över olika antal parallella begäranden. Databricks-slutpunktens strategi för automatisk skalning balanserar mellan svarstid och dataflöde. I notebook-filen ser du att svarstiden och dataflödet ökar när fler samtidiga användare frågar efter slutpunkten.
Men du börjar också se att när antalet parallella begäranden ökar börjar dataflödet plana ut och når en limit på cirka 8000 tokens per sekund. Den här platån beror på att det etablerade dataflödet för slutpunkten begränsar antalet arbetare och parallella begäranden som kan göras. När fler begäranden görs utöver vad slutpunkten kan hantera samtidigt fortsätter den totala svarstiden att öka när ytterligare begäranden väntar i kön.
Mer information om Databricks-filosofin kring prestandajämförelser för LLM beskrivs i bloggen LLM Inference Performance Engineering: Best Practices.