Vad är Databricks-funktionsserver?
Databricks-funktionsservern gör data på Databricks-plattformen tillgängliga för modeller eller program som distribueras utanför Azure Databricks. Funktionsserverslutpunkter skalas automatiskt för att anpassa sig till realtidstrafik och tillhandahålla en tjänst med hög tillgänglighet och låg svarstid för serveringsfunktioner. På den här sidan beskrivs hur du konfigurerar och använder funktionsservering. En stegvis självstudiekurs finns i Distribuera och fråga efter en funktion som betjänar slutpunkten.
När du använder Mosaic AI Model Serving för att hantera en modell som har skapats med funktioner från Databricks, söker modellen automatiskt upp och transformerar funktioner för slutsatsdragningsbegäranden. Med Databricks-funktionsservering kan du hantera strukturerade data för hämtning av program för utökad generering (RAG) samt funktioner som krävs för andra program, till exempel modeller som hanteras utanför Databricks eller andra program som kräver funktioner baserade på data i Unity Catalog.
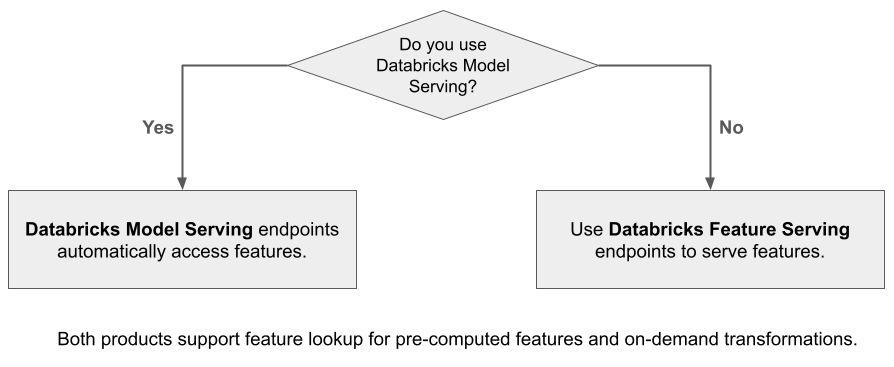
Varför ska jag använda funktionsservering?
Databricks-funktionsservern tillhandahåller ett enda gränssnitt som hanterar förmaterialiserade och på begäran-funktioner. Den innehåller även följande fördelar:
- Enkelhet. Databricks hanterar infrastrukturen. Med ett enda API-anrop skapar Databricks en produktionsklar servermiljö.
- Hög tillgänglighet och skalbarhet. Funktionsserverslutpunkter skalas automatiskt upp och ned för att justeras till mängden serveringsbegäranden.
- Säkerhet. Slutpunkter distribueras i en säker nätverksgräns och använder dedikerad beräkning som avslutas när slutpunkten tas bort eller skalas till noll.
Krav
- Databricks Runtime 14.2 ML eller senare.
- För att kunna använda Python-API:et kräver
databricks-feature-engineeringfunktionsservering version 0.1.2 eller senare, som är inbyggd i Databricks Runtime 14.2 ML. För tidigare Databricks Runtime ML-versioner installerar du den version som krävs manuellt med .%pip install databricks-feature-engineering>=0.1.2Om du använder en Databricks-notebook-fil måste du starta om Python-kerneln genom att köra det här kommandot i en ny cell:dbutils.library.restartPython(). - För att kunna använda Databricks SDK kräver
databricks-sdkfunktionsservering version 0.18.0 eller senare. Om du vill installera den version som krävs manuellt använder du%pip install databricks-sdk>=0.18.0. Om du använder en Databricks-notebook-fil måste du starta om Python-kerneln genom att köra det här kommandot i en ny cell:dbutils.library.restartPython().
Databricks-funktionsservern innehåller ett användargränssnitt och flera programmatiska alternativ för att skapa, uppdatera, fråga och ta bort slutpunkter. Den här artikeln innehåller instruktioner för vart och ett av följande alternativ:
- Databricks-användargränssnitt
- REST-API
- Python API
- Databricks SDK
Om du vill använda REST API eller MLflow Deployments SDK måste du ha en Databricks API-token.
Viktigt!
Som bästa säkerhet för produktionsscenarier rekommenderar Databricks att du använder OAuth-token från dator till dator för autentisering under produktion.
För testning och utveckling rekommenderar Databricks att du använder en personlig åtkomsttoken som tillhör tjänstens huvudnamn i stället för arbetsyteanvändare. Information om hur du skapar token för tjänstens huvudnamn finns i Hantera token för tjänstens huvudnamn.
Autentisering för funktionsservering
Information om autentisering finns i Auktorisera åtkomst till Azure Databricks-resurser.
Skapa en FeatureSpec
En FeatureSpec är en användardefinierad uppsättning funktioner. Du kan kombinera funktioner i en FeatureSpec.
FeatureSpecs lagras i och hanteras av Unity Catalog och visas i Katalogutforskaren.
Tabellerna som anges i en FeatureSpec måste publiceras till en onlinetabell eller en tredjeparts onlinebutik. Se Använda onlinetabeller för realtidsfunktioner som betjänar eller onlinebutiker från tredje part.
Du måste använda databricks-feature-engineering paketet för att skapa en FeatureSpec.
from databricks.feature_engineering import (
FeatureFunction,
FeatureLookup,
FeatureEngineeringClient,
)
fe = FeatureEngineeringClient()
features = [
# Lookup column `average_yearly_spend` and `country` from a table in UC by the input `user_id`.
FeatureLookup(
table_name="main.default.customer_profile",
lookup_key="user_id",
feature_names=["average_yearly_spend", "country"]
),
# Calculate a new feature called `spending_gap` - the difference between `ytd_spend` and `average_yearly_spend`.
FeatureFunction(
udf_name="main.default.difference",
output_name="spending_gap",
# Bind the function parameter with input from other features or from request.
# The function calculates a - b.
input_bindings={"a": "ytd_spend", "b": "average_yearly_spend"},
),
]
# Create a `FeatureSpec` with the features defined above.
# The `FeatureSpec` can be accessed in Unity Catalog as a function.
fe.create_feature_spec(
name="main.default.customer_features",
features=features,
)
Skapa en slutpunkt
Definierar FeatureSpec slutpunkten. Mer information finns i Skapa anpassade modellserverslutpunkter, Python API-dokumentationen eller Dokumentationen om Databricks SDK för mer information.
Kommentar
För arbetsbelastningar som är svarstidskänsliga eller kräver höga frågor per sekund erbjuder Modellservern routningsoptimering på anpassade modellserverslutpunkter i Konfigurera routningsoptimering på serverdelsslutpunkter.
REST-API
curl -X POST -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints \
-H 'Content-Type: application/json' \
-d '"name": "customer-features",
"config": {
"served_entities": [
{
"entity_name": "main.default.customer_features",
"workload_size": "Small",
"scale_to_zero_enabled": true
}
]
}'
Databricks SDK – Python
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.serving import EndpointCoreConfigInput, ServedEntityInput
workspace = WorkspaceClient()
# Create endpoint
workspace.serving_endpoints.create(
name="my-serving-endpoint",
config = EndpointCoreConfigInput(
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
)
Python API
from databricks.feature_engineering.entities.feature_serving_endpoint import (
ServedEntity,
EndpointCoreConfig,
)
fe.create_feature_serving_endpoint(
name="customer-features",
config=EndpointCoreConfig(
served_entities=ServedEntity(
feature_spec_name="main.default.customer_features",
workload_size="Small",
scale_to_zero_enabled=True,
instance_profile_arn=None,
)
)
)
Om du vill se slutpunkten klickar du på Servering i det vänstra sidofältet i Databricks-användargränssnittet. När tillståndet är Klart är slutpunkten redo att svara på frågor. Mer information om ai-modellservering för mosaik finns i Mosaic AI Model Serving.
Hämta en slutpunkt
Du kan använda Databricks SDK eller Python-API:et för att hämta metadata och status för en slutpunkt.
Databricks SDK – Python
endpoint = workspace.serving_endpoints.get(name="customer-features")
# print(endpoint)
Python API
endpoint = fe.get_feature_serving_endpoint(name="customer-features")
# print(endpoint)
Hämta schemat för en slutpunkt
Du kan använda REST-API:et för att hämta schemat för en slutpunkt. Mer information om slutpunktsschemat finns i Hämta en modell som betjänar slutpunktsschemat.
ACCESS_TOKEN=<token>
ENDPOINT_NAME=<endpoint name>
curl "https://example.databricks.com/api/2.0/serving-endpoints/$ENDPOINT_NAME/openapi" -H "Authorization: Bearer $ACCESS_TOKEN" -H "Content-Type: application/json"
Fråga en slutpunkt
Du kan använda REST-API:et, SDK:n för MLflow-distributioner eller servergränssnittet för att fråga en slutpunkt.
Följande kod visar hur du konfigurerar autentiseringsuppgifter och skapar klienten när du använder MLflow Deployments SDK.
# Set up credentials
export DATABRICKS_HOST=...
export DATABRICKS_TOKEN=...
# Set up the client
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
Kommentar
När du autentiserar med automatiserade verktyg, system, skript och appar rekommenderar Databricks att du använder personliga åtkomsttoken som tillhör tjänstens huvudnamn i stället för arbetsyteanvändare. Information om hur du skapar token för tjänstens huvudnamn finns i Hantera token för tjänstens huvudnamn.
Fråga en slutpunkt med API:er
Det här avsnittet innehåller exempel på frågor mot en slutpunkt med hjälp av REST-API:et eller SDK:n för MLflow-distributioner.
REST-API
curl -X POST -u token:$DATABRICKS_API_TOKEN $ENDPOINT_INVOCATION_URL \
-H 'Content-Type: application/json' \
-d '{"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]}'
SDK för MLflow-distributioner
Viktigt!
I följande exempel används API:et predict()från MLflow Deployments SDK. Det här API:et är experimentellt och API-definitionen kan ändras.
import mlflow.deployments
client = mlflow.deployments.get_deploy_client("databricks")
response = client.predict(
endpoint="test-feature-endpoint",
inputs={
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280},
]
},
)
Fråga en slutpunkt med hjälp av användargränssnittet
Du kan fråga en serverdelsslutpunkt direkt från användargränssnittet för servering. Användargränssnittet innehåller genererade kodexempel som du kan använda för att fråga slutpunkten.
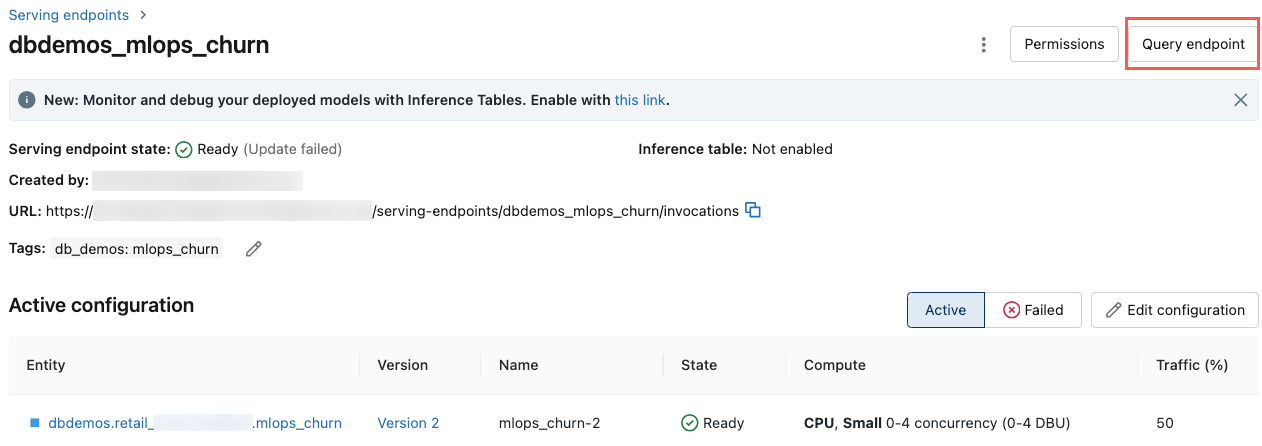
I det vänstra sidofältet på Azure Databricks-arbetsytan klickar du på Servering.
Klicka på den slutpunkt som du vill fråga efter.
Klicka på Frågeslutpunkt längst upp till höger på skärmen.
I rutan Begäran skriver du begärandetexten i JSON-format.
Klicka på Skicka begäran.
// Example of a request body.
{
"dataframe_records": [
{"user_id": 1, "ytd_spend": 598},
{"user_id": 2, "ytd_spend": 280}
]
}
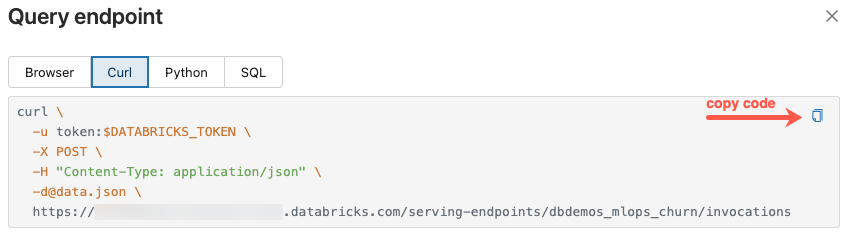
Dialogrutan Frågeslutpunkt innehåller genererad exempelkod i curl, Python och SQL. Klicka på flikarna för att visa och kopiera exempelkoden.
Om du vill kopiera koden klickar du på kopieringsikonen längst upp till höger i textrutan.
Uppdatera en ändpunkt
Du kan uppdatera en slutpunkt med hjälp av REST API, Databricks SDK eller serveringsgränssnittet.
Uppdatera en slutpunkt med hjälp av API:er
REST-API
curl -X PUT -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>/config \
-H 'Content-Type: application/json' \
-d '"served_entities": [
{
"name": "customer-features",
"entity_name": "main.default.customer_features_new",
"workload_size": "Small",
"scale_to_zero_enabled": True
}
]'
Databricks SDK – Python
workspace.serving_endpoints.update_config(
name="my-serving-endpoint",
served_entities=[
ServedEntityInput(
entity_name="main.default.customer_features",
scale_to_zero_enabled=True,
workload_size="Small"
)
]
)
Uppdatera en slutpunkt med hjälp av användargränssnittet
Följ de här stegen för att använda användargränssnittet för servering:
- I det vänstra sidofältet på Azure Databricks-arbetsytan klickar du på Servering.
- I tabellen klickar du på namnet på den slutpunkt som du vill uppdatera. Slutpunktsskärmen visas.
- Klicka på Redigera slutpunkt längst upp till höger på skärmen.
- I dialogrutan Redigera serverdelsslutpunkt redigerar du slutpunktsinställningarna efter behov.
- Klicka på Uppdatera för att spara ändringarna.

Ta bort en slutpunkt
Varning
Den här åtgärden kan inte ångras.
Du kan ta bort en slutpunkt med hjälp av REST-API:et, Databricks SDK, Python-API:et eller användargränssnittet för servering.
Ta bort en slutpunkt med API:er
REST-API
curl -X DELETE -u token:$DATABRICKS_API_TOKEN ${WORKSPACE_URL}/api/2.0/serving-endpoints/<endpoint_name>
Databricks SDK – Python
workspace.serving_endpoints.delete(name="customer-features")
Python API
fe.delete_feature_serving_endpoint(name="customer-features")
Ta bort en slutpunkt med hjälp av användargränssnittet
Följ de här stegen för att ta bort en slutpunkt med hjälp av användargränssnittet för servering:
- I det vänstra sidofältet på Azure Databricks-arbetsytan klickar du på Servering.
- I tabellen klickar du på namnet på den slutpunkt som du vill ta bort. Slutpunktsskärmen visas.
- Längst upp till höger på skärmen klickar du på menyn för kebab
 och väljer Ta bort.
och väljer Ta bort.

Övervaka hälsotillståndet för en slutpunkt
Information om de loggar och mått som är tillgängliga för funktionsserveringsslutpunkter finns i Övervaka modellkvalitet och slutpunktshälsa.
Åtkomstkontroll
Information om behörigheter för funktionsserverslutpunkter finns i Hantera behörigheter för din modell som betjänar slutpunkten.
Exempelnotebook-fil
Den här notebook-filen visar hur du använder Databricks SDK för att skapa en funktionsserverslutpunkt med databricks onlinetabeller.