Räckvidden av lakehouse-plattformen
Ett modernt data- och AI-plattformsramverk
För att diskutera omfånget för Databricks Data Intelligence Platform är det bra att först definiera ett grundläggande ramverk för den moderna data- och AI-plattformen:
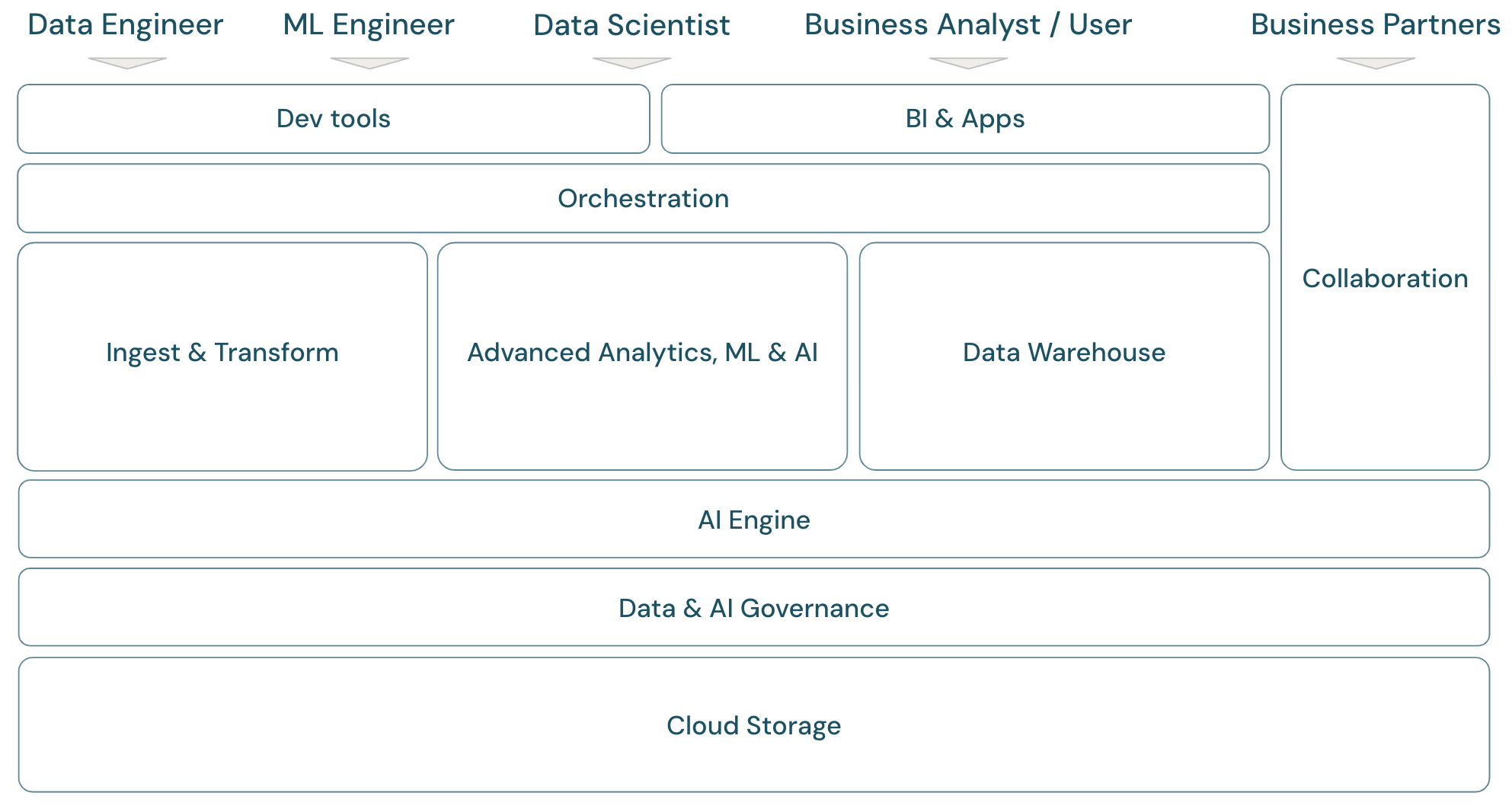
Översikt över lakehouse-omfånget
Databricks Data Intelligence Platform täcker det fullständiga moderna dataplattformsramverket. Den bygger på lakehouse-arkitekturen och drivs av en dataintelligensmotor som förstår de unika egenskaperna hos dina data. Det är en öppen och enhetlig grund för ETL-, ML/AI- och DWH/BI-arbetsbelastningar och har Unity Catalog som central data- och AI-styrningslösning.
Personas i plattformsramverket
Ramverket omfattar de primära datateammedlemmar (personas) som arbetar med programmen i ramverket:
- Datatekniker ger dataexperter och affärsanalytiker korrekta och reproducerbara data för snabba beslut och insikter i realtid. De implementerar mycket konsekventa och tillförlitliga ETL-processer för att öka användarnas förtroende för data. De säkerställer att data är väl integrerade med de olika grundpelarna i verksamheten och följer vanligtvis bästa praxis för programvaruteknik.
- Dataforskare blandar analytisk expertis och affärsförstedelse för att omvandla data till strategiska insikter och förutsägelsemodeller. De är skickliga på att översätta affärsutmaningar till datadrivna lösningar, vare sig det gäller retrospektiva analytiska insikter eller framåtblickande förutsägelsemodellering. Med hjälp av datamodellering och maskininlärningstekniker utformar, utvecklar och distribuerar de modeller som presenterar mönster, trender och prognoser från data. De fungerar som en brygga och konverterar komplexa databerättelser till begripliga berättelser, vilket säkerställer att affärsintressenter inte bara förstår utan också kan agera på de datadrivna rekommendationerna, vilket i sin tur driver en datacentrerad metod för problemlösning inom en organisation.
- ML-tekniker (maskininlärningstekniker) leder den praktiska tillämpningen av datavetenskap i produkter och lösningar genom att skapa, distribuera och underhålla maskininlärningsmodeller. Deras primära fokus riktas mot den tekniska aspekten av modellutveckling och distribution. ML-tekniker säkerställer robusthet, tillförlitlighet och skalbarhet för maskininlärningssystem i realtidsmiljöer och hanterar utmaningar som rör datakvalitet, infrastruktur och prestanda. Genom att integrera AI- och ML-modeller i operativa affärsprocesser och användarinriktade produkter underlättar de användningen av datavetenskap för att lösa affärsutmaningar, vilket säkerställer att modeller inte bara stannar inom forskningen utan driver konkreta affärsvärde.
- Affärsanalytiker och företagsanvändare: Affärsanalytiker ger intressenter och affärsteam användbara data. De tolkar ofta data och skapar rapporter eller annan dokumentation för hantering med hjälp av STANDARD BI-verktyg. De är vanligtvis den första kontaktpunkten för icke-tekniska företagsanvändare och driftskollegor för snabba analysfrågor. Instrumentpaneler och affärsappar som levereras på Databricks-plattformen kan användas direkt av företagsanvändare.
- Affärspartner är viktiga intressenter i en alltmer nätverkskonsluten affärsvärld. De definieras som ett företag eller individer med vilka ett företag har en formell relation för att uppnå ett gemensamt mål, och kan omfatta leverantörer, leverantörer, distributörer och andra tredjepartspartner. Datadelning är en viktig aspekt av affärssamarbeten, eftersom det gör det möjligt att överföra och utbyta data för att förbättra samarbetet och det datadrivna beslutsfattandet.
Domäner för plattformsramverket
Plattformen består av flera domäner:
- Storage: I molnet lagras data huvudsakligen i skalbar, effektiv och elastisk objektlagring på molnleverantörer.
- Styrning: Funktioner kring datastyrning, till exempel åtkomstkontroll, granskning, metadatahantering, ursprungsspårning och övervakning för alla data och AI-tillgångar.
- AI-motor: AI-motorn tillhandahåller generativa AI-funktioner för hela plattformen.
- Mata in och transformera: Funktionerna för ETL-arbetsbelastningar.
- Avancerad analys, ML och AI: Alla funktioner kring maskininlärning, AI, Generativ AI och även strömmande analys.
- Informationslager: Domänen som stöder DWH- och BI-användningsfall.
- Automation: Arbetsflödeshantering för databearbetning, maskininlärning, analyspipelines, inklusive stöd för CI/CD och MLOps.
- ETL- och DS-verktyg: De klientdelsverktyg som datatekniker, dataforskare och ML-tekniker främst använder för arbete.
- BI-verktyg: De klientdelsverktyg som BI-analytiker främst använder för arbete.
- Samarbete: Funktioner för datadelning mellan två eller flera parter.
Databricks-plattformens omfång
Databricks Data Intelligence Platform och dess komponenter kan mappas till ramverket på följande sätt:
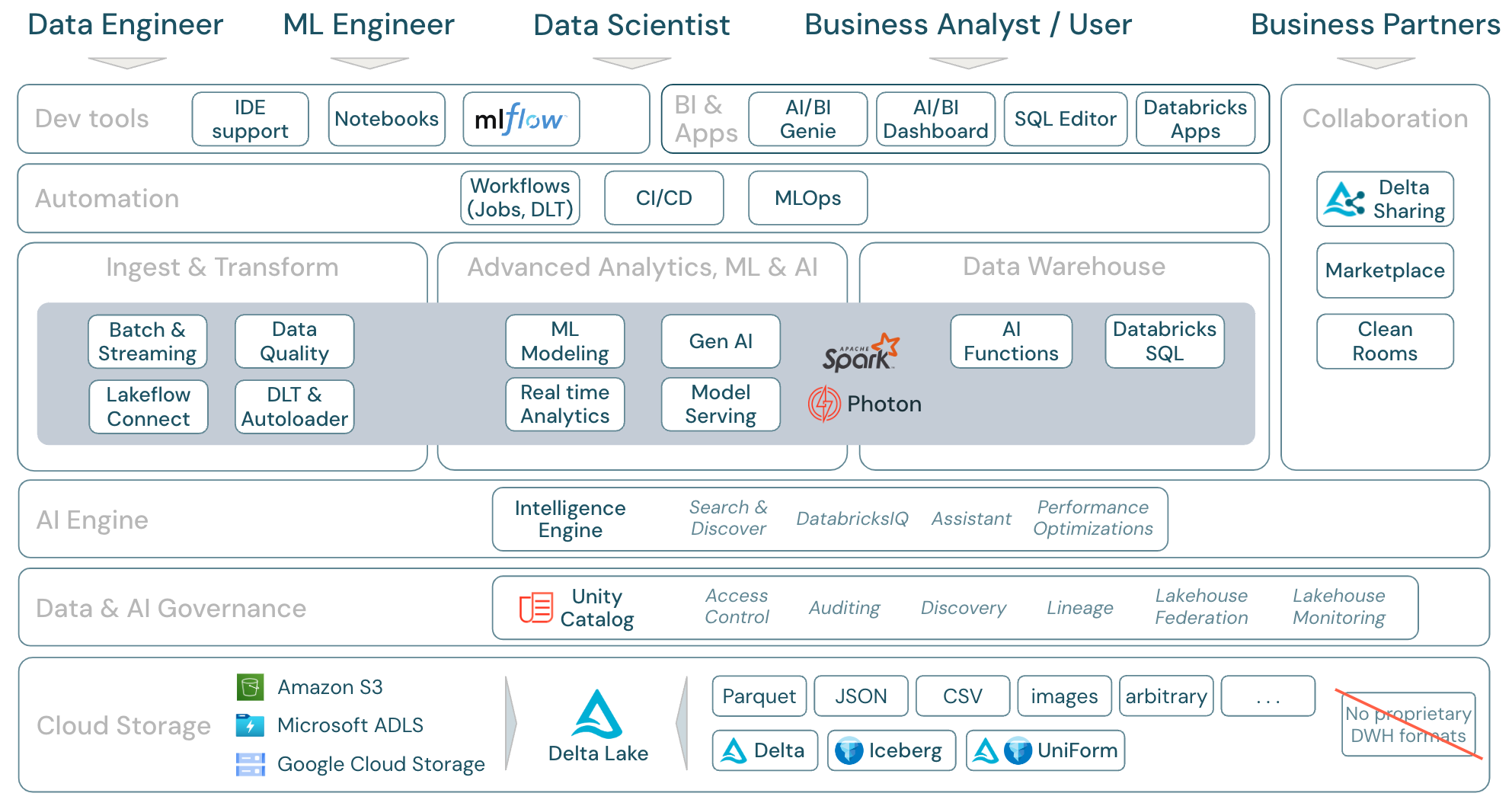 Ladda ner: Omfattning av lakehouse – Databricks-komponenter
Ladda ner: Omfattning av lakehouse – Databricks-komponenter
Dataarbetsbelastningar i Azure Databricks
Viktigast av allt är att Databricks Data Intelligence Platform täcker alla relevanta arbetsbelastningar för datadomänen på en plattform, med Apache Spark/Photon som motor:
Inmata och transformera
Databricks erbjuder flera olika sätt att mata in data:
- Databricks Lakeflow Connect erbjuder inbyggda anslutningar för inmatning från företagsprogram och databaser. Den resulterande inmatningspipelinen styrs av Unity Catalog och drivs av serverlös beräkning och DLT.
- Auto Loader inkrementellt och automatiskt bearbetar filer som landar i molnlagring i schemalagda eller kontinuerliga jobb – utan att behöva hantera tillståndsinformation. När rådata har matats in måste de transformeras så att de är redo för BI och ML/AI. Databricks tillhandahåller kraftfulla ETL-funktioner för datatekniker, dataforskare och analytiker.
DLT (DLT) gör det möjligt att skriva ETL-jobb på ett deklarativt sätt, vilket förenklar hela implementeringsprocessen. Datakvaliteten kan förbättras genom att definiera dataförväntningarna.
Avancerad analys, ML och AI
Plattformen innehåller Databricks Mosaic AI, en uppsättning helt integrerade maskininlärnings- och AI-verktyg för klassisk maskin och djupinlärning, samt generativ AI och stora språkmodeller (LLMs). Det omfattar hela arbetsflödet från att förbereda data till att skapa maskininlärnings- och djupinlärningsmodeller , till Mosaic AI Model Serving.
Spark Structured Streaming och DLT aktiverar realtidsanalys.
Informationslager
Databricks Data Intelligence Platform har också en komplett informationslagerlösning med Databricks SQL, centralt styrd av Unity Catalog med detaljerad åtkomstkontroll.
AI-funktioner är inbyggda SQL-funktioner som gör att du kan använda AI på dina data direkt från SQL. Integrering av AI i analysarbetsflöden ger åtkomst till information som tidigare inte var tillgänglig för analytiker och ger dem möjlighet att fatta mer välgrundade beslut, hantera risker och upprätthålla en konkurrensfördel genom datadriven innovation och effektivitet.
Översikt över funktionsområden i Azure Databricks
Det här är en mappning av Databricks Data Intelligence Platform-funktionerna till de andra lagren i ramverket, nedifrån och upp:
Molnlagring
Alla data för lakehouse lagras i molnleverantörens objektlagring. Databricks stöder tre molnleverantörer: AWS, Azure och GCP. Filer i olika strukturerade och halvstrukturerade format (till exempel Parquet, CSV, JSON och Avro) samt ostrukturerade format (till exempel bilder och dokument) matas in och transformeras med antingen batch- eller strömningsprocesser.
Delta Lake är det rekommenderade dataformatet för lakehouse (filtransaktioner, tillförlitlighet, konsekvens, uppdateringar och så vidare) och är helt öppen källkod för att undvika inlåsning. Och Delta Universal Format (UniForm) kan du läsa Delta-tabeller med Iceberg-läsarklienter.
Inga egna dataformat används i Databricks Data Intelligence Platform.
data- och AI-styrning
Utöver lagringslagret erbjuder Unity Catalog en mängd olika funktioner för data- och AI-styrning, inklusive metadatahantering i metaarkivet, åtkomstkontroll, granskning, dataidentifieringoch .
Lakehouse-övervakning tillhandahåller färdiga kvalitetsmått för data och AI-tillgångar samt automatiskt genererade dashboardar för att visualisera dessa mått.
Externa SQL-källor kan integreras i Lakehouse och Unity Catalog via lakehouse federation.
AI-motor
Data Intelligence Platform bygger på lakehouse-arkitekturen och förbättras av dataintelligensmotorn DatabricksIQ. DatabricksIQ kombinerar generativ AI med fördelarna med lakehouse-arkitekturen för att förstå den unika semantiken i dina data. Intelligent sökning och Databricks Assistant är exempel på AI-baserade tjänster som förenklar arbetet med plattformen för varje användare.
Orkestrering
Med Databricks-jobb kan du köra olika arbetsbelastningar för fullständig data- och AI-livscykel i alla moln. De gör att du kan orkestrera jobb samt DLT för SQL, Spark, notebook-filer, DBT- och ML-modeller med mera.
ETL- och DS-verktyg
På förbrukningsnivå arbetar datatekniker och ML-tekniker vanligtvis med plattformen med hjälp av IDE:er. Dataexperter föredrar ofta notebooks och använder ML- och AI-körmiljöerna samt systemet för maskininlärningsarbetsflöde MLflow för att spåra experiment och hantera modellens livscykel.
BI-verktyg
Affärsanalytiker använder vanligtvis sitt föredragna BI-verktyg för att få åtkomst till Databricks-informationslagret. Databricks SQL kan efterfrågas av olika analys- och BI-verktyg, se BI och visualisering
Dessutom erbjuder plattformen fråge- och analysverktyg direkt:
- AI/BI-instrumentpaneler för att dra och släppa datavisualiseringar och dela insikter.
- Domänexperter, till exempel dataanalytiker, konfigurerar AI/BI Genie-utrymmen med datauppsättningar, exempelfrågor och textriktlinjer för att hjälpa Genie att översätta affärsfrågor till analysfrågor. Efter konfigurationen kan företagsanvändare ställa frågor och generera visualiseringar för att förstå driftdata.
- Databricks Apps låter utvecklare skapa säkra data- och AI-program på Databricks-plattformen och dela dessa appar med användare.
- SQL-redigerare för SQL-analytiker för att analysera data.
Samarbete
Deltadelning är ett öppet protokoll som utvecklats av Databricks för säker datadelning med andra organisationer oavsett vilka beräkningsplattformar de använder.
Databricks Marketplace är ett öppet forum för utbyte av dataprodukter. Den drar nytta av Delta Sharing för att ge både dataleverantörerna verktyg för att dela dataprodukter på ett säkert sätt och datakonsumenter möjligheten att utforska och utöka sin åtkomst till de data och datatjänster de behöver.
Clean Rooms använder Delta Sharing och serverlös datorkraft för att erbjuda en säker och sekretessskyddande miljö där flera parter kan samarbeta med känsliga företagsdata utan att ha direkt åtkomst till varandras data.