Samla in och visa data härstamning med hjälp av Unity Catalog
Den här artikeln beskriver hur du samlar in och visualiserar datahärkomst genom att använda Catalog Explorer, systemtabellerna för datahärkomst och REST-API:et.
Du kan använda Unity Catalog för att samla in körningsdata härstamning mellan frågor som körs på Azure Databricks. Linjäritetsstöd finns för alla språk och fångas ner till kolumnnivån. Härkomstdata inkluderar anteckningsböcker, jobb och instrumentpaneler relaterade till frågan. Stamträd kan visualiseras i Catalog Explorer i nära realtid och hämtas via programkod med hjälp av systemtabeller för stamträd och Databricks REST API.
Härkomsten samlas över alla arbetsytor som är kopplade till ett Unity Catalog-metaarkiv. Det innebär att härkomst som samlas in på en arbetsyta visas i vilken annan arbetsyta som helst som delar det metaarkivet. Mer specifikt är tabeller och andra dataobjekt som registrerats i metaarkivet synliga för användare som har minst BROWSE behörigheter för dessa objekt, på alla arbetsytor som är kopplade till metaarkivet. Detaljerad information om objekt på arbetsytenivå som notebook-filer och instrumentpaneler på andra arbetsytor är dock maskerad (se Begränsningar och Härkomstbehörigheter).
Stamdata behålls i ett år.
Följande bild är ett exempel på ett härstamningsdiagram. Specifika funktioner och exempel på data härkomst behandlas senare i den här artikeln.
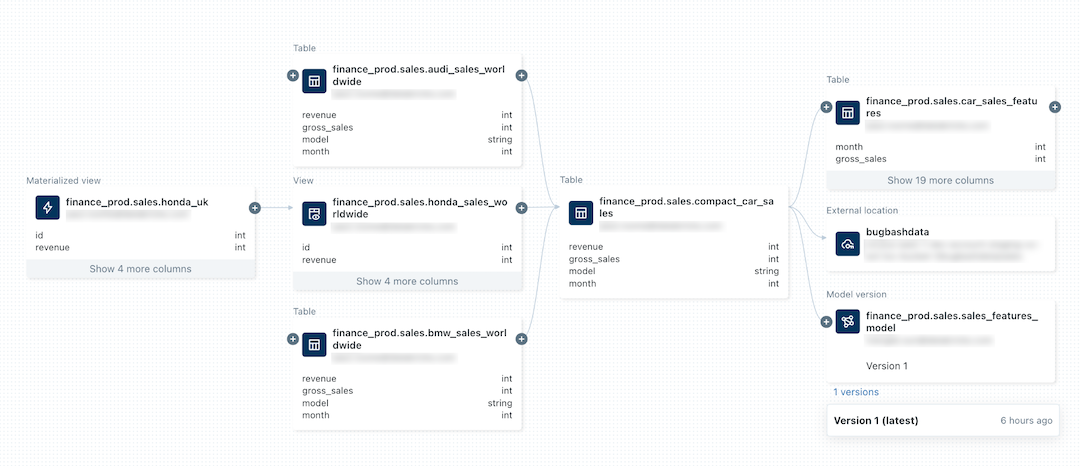
Information om hur du spårar ursprunget för en maskininlärningsmodell finns i Spåra data härstamningen för en modell i Unity Catalog.
Krav
Följande krävs för att samla in dataursprung med hjälp av Unity Catalog:
- Unity Catalog måste vara aktiverat på arbetsytan.
- Tabeller måste registreras i ett Unity Catalog-metaarkiv.
- Frågor måste använda Spark DataFrame (till exempel Spark SQL-funktioner som returnerar en DataFrame) eller Databricks SQL-gränssnitt. Exempel på Databricks SQL- och PySpark-frågor finns i Exempel.
- Om du vill visa härkomsten för en tabell eller en vy måste användarna ha minst behörigheten
BROWSEpå den överordnade katalogen för tabellen eller vyn. Den överordnade katalogen måste också vara tillgänglig från arbetsytan. Se Begränsa katalogåtkomst till specifika arbetsytor. - För att visa härstamningsinformation för notebook-filer, jobb eller instrumentpaneler måste användarna ha behörigheter för dessa objekt som definieras av åtkomstkontrollinställningarna i arbetsytan. Se Härkomstbehörigheter.
- Om du vill visa härkomst för en Unity Catalog-aktiverad pipeline måste du ha
CAN_VIEWför pipelinen. - Släktskaps- eller härstamningsspårning av strömning mellan Delta-tabeller kräver Databricks Runtime 11.3 LTS eller senare.
- Spårning av kolumnursprung för arbetsbelastningar för DLT kräver Databricks Runtime 13.3 LTS eller senare.
- Du kan behöva uppdatera dina regler för utgående brandvägg för att tillåta anslutning till Event Hubs-slutpunkten i Azure Databricks-kontrollplanet. Detta gäller vanligtvis om din Azure Databricks-arbetsyta distribueras i ditt eget virtuella nätverk (även kallat VNet-inmatning). Information om hur du hämtar Event Hubs-slutpunkten för din arbetsyteregion finns i IP-adresser för metaarkiv, bloblagring för artefakter, systemtabeller, loggbloblagring och Event Hubs-slutpunkt. Information om hur du konfigurerar användardefinierade vägar (UDR) för Azure Databricks finns i Användardefinierade routningsinställningar för Azure Databricks.
Exempel
Anteckning
I följande exempel används katalognamnet
lineage_dataoch schemanamnetlineagedemo. Om du vill använda en annan katalog och ett annat schema ändrar du namnen som används i exemplen.För att kunna slutföra det här exemplet måste du ha
CREATEochUSE SCHEMAbehörigheter för ett schema. En metaarkivadministratör, katalogägare, schemaägare eller användare medMANAGEbehörighet i schemat kan bevilja dessa privilegier. Om du till exempel vill ge alla användare i gruppen "data_engineers" behörighet att skapa tabeller ilineagedemoschemat ilineage_datakatalogen kan en användare med någon av ovanstående behörigheter eller roller köra följande frågor:CREATE SCHEMA lineage_data.lineagedemo; GRANT USE SCHEMA, CREATE on SCHEMA lineage_data.lineagedemo to `data_engineers`;
Fånga och utforska ursprung
Så här samlar du in ursprungsdata:
Gå till din Azure Databricks-landningssida, klicka på
 Nytt i sidofältet och välj Notebook på menyn.
Nytt i sidofältet och välj Notebook på menyn.Ange ett namn på notebook-filen och välj SQL i Standardspråk.
I Kluster väljer du ett kluster med åtkomst till Unity Catalog.
Klicka på Skapa.
I den första notebook-cellen anger du följande frågor:
CREATE TABLE IF NOT EXISTS lineage_data.lineagedemo.menu ( recipe_id INT, app string, main string, dessert string ); INSERT INTO lineage_data.lineagedemo.menu (recipe_id, app, main, dessert) VALUES (1,"Ceviche", "Tacos", "Flan"), (2,"Tomato Soup", "Souffle", "Creme Brulee"), (3,"Chips","Grilled Cheese","Cheesecake"); CREATE TABLE lineage_data.lineagedemo.dinner AS SELECT recipe_id, concat(app," + ", main," + ",dessert) AS full_menu FROM lineage_data.lineagedemo.menuOm du vill köra frågorna klickar du i cellen och trycker på skift+retur eller klickar
 och väljer Kör cell.
och väljer Kör cell.
Så här använder du Katalogutforskaren för att visa härledningen som genereras av dessa frågor:
I rutan Sök i det övre fältet på Azure Databricks-arbetsytan söker du efter tabellen och väljer den
lineage_data.lineagedemo.dinner.Välj fliken Ursprung . Ursprungspanelen visas och visar relaterade tabeller (i det här exemplet är
menudet tabellen).Om du vill visa ett interaktivt diagram över data härstamningen klickar du på Visa ursprungsdiagram. Som standard visas en nivå i diagrammet.
 Klicka på ikonen på en nod för att visa fler anslutningar om de är tillgängliga.
Klicka på ikonen på en nod för att visa fler anslutningar om de är tillgängliga.Klicka på en pil som ansluter noder i ursprungsdiagrammet för att öppna panelen för Linjeanslutningar. Panelen Linjeanslutning visar information om anslutningen, däribland käll- och måltabeller, anteckningsböcker och jobb.
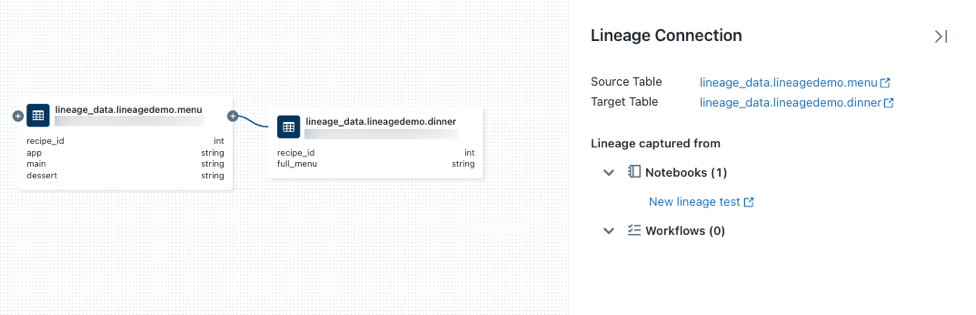
Om du vill visa anteckningsboken som är associerad med
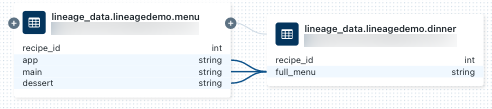
dinner-tabellen, väljer du anteckningsboken i Lineage connection-panelen, eller så stänger du ursprungsdiagrammet och klickar på Anteckningsböcker. Om du vill öppna anteckningsboken på en ny flik klickar du på anteckningsbokens namn.Om du vill visa ursprunget på kolumnnivå klickar du på en kolumn i diagrammet för att visa länkar till relaterade kolumner. Om du till exempel klickar på kolumnen "full_menu" visas de överordnade kolumner som kolumnen härleddes från:
Om du vill visa ursprung med ett annat språk, till exempel Python:
Öppna anteckningsboken som du skapade tidigare, skapa en ny cell och ange följande Python-kod:
%python from pyspark.sql.functions import rand, round df = spark.range(3).withColumn("price", round(10*rand(seed=42),2)).withColumnRenamed("id","recipe_id") df.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.price") dinner = spark.read.table("lineage_data.lineagedemo.dinner") price = spark.read.table("lineage_data.lineagedemo.price") dinner_price = dinner.join(price, on="recipe_id") dinner_price.write.mode("overwrite").saveAsTable("lineage_data.lineagedemo.dinner_price")Kör cellen genom att klicka i cellen och trycka på Skift+Retur eller klicka
och välja Kör cell.I rutan Sök i det övre fältet på Azure Databricks-arbetsytan söker du efter tabellen och väljer den
lineage_data.lineagedemo.price.Gå till fliken Ursprung och klicka på Visa ursprungsdiagram. Klicka på ikonerna
för att utforska datalinjen som frågorna genererar.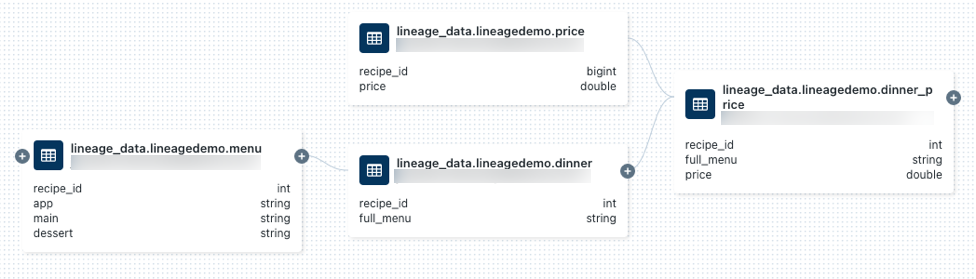
Klicka på en pil som ansluter noder i härledningsgrafen för att öppna härledningsanslutningspanelen. Anslutningspanelen Ursprung visar information om anslutningen, inklusive käll- och måltabeller, notebook-filer och jobb.
Fånga och visa arbetsflödets släktträd
Ursprung samlas också in för alla arbetsflöden som läser eller skriver till Unity Catalog. Visa härkomst för ett Azure Databricks-arbetsflöde:
Klicka på
Nytt i sidopanelen och välj Anteckningsbok på menyn.Ange ett namn på notebook-filen och välj SQL i Standardspråk.
Klicka på Skapa.
I den första notebook-cellen anger du följande fråga:
SELECT * FROM lineage_data.lineagedemo.menuKlicka på Schemalägg i det övre fältet. I schemadialogrutan väljer du Manuell, väljer ett kluster med åtkomst till Unity Catalog och klickar på Skapa.
Klicka på Kör nu.
I rutan Sök i det övre fältet på Azure Databricks-arbetsytan söker du efter tabellen och väljer den
lineage_data.lineagedemo.menu.På fliken Härstamning klickar du på Arbetsflöden och väljer fliken Nedströms. Jobbnamnet visas under Jobbnamn som en konsument av
menutabellen.
Fånga och visa instrumentpanelens historik
För att skapa en instrumentpanel och visa dess dataursprung:
Gå till azure Databricks-landningssidan och öppna Katalogutforskaren genom att klicka på Katalog i sidofältet.
Klicka på katalognamnet, klicka på lineagedemo och välj
menutabellen. Du kan också använda sökrutan i det övre fältet för att sökamenuefter tabellen.Klicka på Öppna i en instrumentpanel.
Välj de kolumner som du vill lägga till på instrumentpanelen och klicka på Skapa.
Publicera instrumentpanelen.
Endast publicerade instrumentpaneler spåras i datahärledning.
I rutan Sök i det övre fältet söker du efter tabellen och väljer den
lineage_data.lineagedemo.menu.På fliken Linje klickar du på Dashboardar. Instrumentpanelen visas under Instrumentpanelens namn som en användare av menytabellen.
Härkomstbehörigheter
Härstamningsdiagram delar samma behörighetsmodell som Unity Catalog. Tabeller och andra dataobjekt som registrerats i Unity Catalog-metaarkivet är endast synliga för användare som har minst BROWSE behörigheter för dessa objekt. Om en användare inte har BROWSE eller SELECT behörighet på en tabell kan de inte utforska dess ursprung. Linjediagram visar Unity Catalog-objekt över alla arbetsytor som är kopplade till metaarkivet, så länge användaren har tillräckliga objektbehörigheter.
Kör till exempel följande kommandon för userA:
GRANT USE SCHEMA on lineage_data.lineagedemo to `userA@company.com`;
GRANT SELECT on lineage_data.lineagedemo.menu to `userA@company.com`;
När userA visar ursprungsdiagrammet för tabellen lineage_data.lineagedemo.menu, visas tabellen menu. De kommer inte att kunna se information om associerade tabeller, till exempel den underordnade lineage_data.lineagedemo.dinner tabellen. Tabellen dinner visas som en masked nod i visningen till userAoch userA kan inte expandera diagrammet för att visa underordnade tabeller från tabeller som de inte har behörighet att komma åt.
Om du kör följande kommando för att ge BROWSE behörighet till userB, kan den användaren visa ursprungsdiagrammet för vilken tabell som helst i lineage_data-schemat.
GRANT BROWSE on lineage_data to `userB@company.com`;
På samma sätt måste genealogianvändare ha specifika behörigheter för att visa arbetsytans objekt som anteckningsböcker, jobb och instrumentpaneler. Dessutom kan de bara se detaljerad information om arbetsyteobjekt när de är inloggade på arbetsytan där objekten skapades. Detaljerad information om objekt på arbetsplatsnivå i andra arbetsplatser döljs i släktdiagrammet.
Mer information om hur du hanterar åtkomst till skyddsbara objekt i Unity Catalog finns i Hantera privilegier i Unity Catalog. Mer information om hur du hanterar åtkomst till arbetsyteobjekt som notebook-filer, jobb och instrumentpaneler finns i Åtkomstkontrollistor.
Ta bort ursprungsdata
Varning
Följande instruktioner tar bort alla objekt som lagras i Unity Catalog. Använd endast dessa instruktioner om det behövs. Till exempel för att uppfylla efterlevnadskraven.
Om du vill ta bort ursprungsdata måste du ta bort metaarkivet som hanterar Unity Catalog-objekten. Mer information om hur du tar bort metaarkivet finns i Ta bort ett metaarkiv. Data tas bort inom 90 dagar.
Hämta tabellsläktskap med hjälp av Databricks Assistant
Databricks Assistant innehåller detaljerad information om tabellers ursprung och insikter.
Så här hämtar du ursprungsinformation med hjälp av Assistent:
- Gå till azure Databricks-landningssidan och öppna Katalogutforskaren genom att klicka på
 Catalog i sidofältet.
Catalog i sidofältet. - Klicka på katalognamnet och klicka sedan på ikonen
 Assistant-ikonen i det övre högra hörnet.
Assistant-ikonen i det övre högra hörnet. - I assistentens prompt skriver du:
- /getTableLineages för att visa uppströms- och nedströmsberoenden.
- /getTableInsights för åtkomst till metadatadrivna insikter, till exempel användaraktivitet och frågemönster.
Med de här frågorna kan assistenten svara på frågor som "visa mig underordnade ursprung" eller "vem som frågar den här tabellen oftast".

Fråga efter ursprungsdata med hjälp av systemtabeller
Du kan använda ursprungssystemtabellerna för att programmatiskt fråga efter ursprungsdata. Detaljerade anvisningar finns i Övervaka kontoaktivitet med systemtabeller och referens för ursprungssystemtabeller.
Om din arbetsyta finns i en region som inte har stöd för linjediagramssystemtabeller kan du också använda Data Lineage REST-API:et för att hämta linjediagramdata programmerbart.
Hämta ursprung med hjälp av REST-API:et för data härkomst
Med API:et för datahärledning kan du hämta tabell- och kolumnhärledning. Men om din arbetsyta finns i en region som stöder ursprungssystemtabellerna bör du använda systemtabellfrågor i stället för REST-API:et. Systemtabeller är ett bättre alternativ för programmatisk hämtning av ursprungsdata. De flesta regioner stöder ursprungssystemtabellerna.
Viktigt!
För att få åtkomst till Databricks REST API:er måste du autentisera.
Hämta tabelllinjalinje
Det här exemplet hämtar ursprungsdata för dinner tabellen.
Förfrågan
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/table-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "include_entity_lineage": true}'
Ersätt <workspace-instance>.
I det här exemplet används en .netrc-fil .
Svar
{
"upstreams": [
{
"tableInfo": {
"name": "menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
],
"downstreams": [
{
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
},
{
"tableInfo": {
"name": "dinner_price",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_type": "TABLE"
},
"notebookInfos": [
{
"workspace_id": 4169371664718798,
"notebook_id": 1111169262439324
}
]
}
]
}
Hämta kolumn ursprung
Det här exemplet hämtar kolumndata för dinner tabellen.
Förfrågan
curl --netrc -X GET \
-H 'Content-Type: application/json' \
https://<workspace-instance>/api/2.0/lineage-tracking/column-lineage \
-d '{"table_name": "lineage_data.lineagedemo.dinner", "column_name": "dessert"}'
Ersätt <workspace-instance>.
I det här exemplet används en .netrc-fil .
Svar
{
"upstream_cols": [
{
"name": "dessert",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "main",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
},
{
"name": "app",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "menu",
"table_type": "TABLE"
}
],
"downstream_cols": [
{
"name": "full_menu",
"catalog_name": "lineage_data",
"schema_name": "lineagedemo",
"table_name": "dinner_price",
"table_type": "TABLE"
}
]
}
Begränsningar
Även om härledningen aggregeras för alla arbetsytor som är kopplade till samma Unity Catalog-metakatalog, är detaljer för arbetsyteobjekt som anteckningsböcker och instrumentpaneler synliga endast i arbetsytan där de skapades.
Eftersom ursprung beräknas i ett rullande ettårsfönster visas inte ursprung som samlats in för mer än ett år sedan. Om till exempel ett jobb eller en fråga läser data från tabell A och skriver till tabell B, visas länken mellan tabell A och tabell B endast i ett år. Du kan filtrera ursprungsdata efter tidsram inom ettårsfönstret.
Jobb som använder begäran från Jobs API
runs submitär inte tillgängliga vid visning av härstamning. Ursprung på tabell- och kolumnnivå registreras fortfarande när du använderruns submit-begäran, men länken till körningen tas inte med.Unity Catalog samlar in härledning till kolumnnivån i så stor utsträckning som möjligt. Det finns dock vissa fall då det inte går att samla in ursprung på kolumnnivå.
Kolumnhärkomst stöds endast när både källan och målet refereras till med tabellnamnet (exempel:
select * from <catalog>.<schema>.<table>). Det går inte att avbilda kolumnsamband om källan eller destinationen adresseras via sökväg (exempel:select * from delta."s3://<bucket>/<path>").Om en tabell eller vy har bytt namn registreras inte ursprung för den omdöpta tabellen eller vyn.
Om ett schema eller en katalog har bytt namn registreras inte ursprung för tabeller och vyer under den omdöpta katalogen eller schemat.
Om du använder kontrollpunkter för Spark SQL-dataset sparas inte datahistoriken.
Unity Catalog samlar in släktskap från DLT-pipelines i de flesta fall. I vissa fall kan dock fullständig härkomsttäckning inte garanteras, till exempel när pipelines använder API:et APPLY CHANGES eller TEMPORÄRA tabeller.
Härkomst fångar inte Stackfunktioner.
Globala temporära vyer fångas inte upp i härkomsten.
Tabeller under
system.information_schemafångas inte upp i datahärkomsten.Fullständig härkomst på kolumnnivå samlas inte in som standard för
MERGEåtgärder.Du kan aktivera ursprungsinsamling för
MERGEåtgärder genom att ställa in Spark-egenskapenspark.databricks.dataLineage.mergeIntoV2Enabledtilltrue. Om du aktiverar den här flaggan kan frågeprestandan försämras, särskilt i arbetsbelastningar som omfattar mycket breda tabeller.