Använda dbt-transformeringar i ett Azure Databricks-jobb
Du kan köra dina dbt Core-projekt som en uppgift i ett Azure Databricks-jobb. Genom att köra dbt Core-projektet som en jobbuppgift kan du dra nytta av följande Funktioner i Azure Databricks-jobb:
- Automatisera dina dbt-uppgifter och schemalägg arbetsflöden som innehåller dbt-uppgifter.
- Övervaka dina dbt-transformeringar och skicka meddelanden om omvandlingarnas status.
- Inkludera ditt dbt-projekt i ett arbetsflöde med andra uppgifter. Ditt arbetsflöde kan till exempel mata in data med Auto Loader, transformera data med dbt och analysera data med en notebook-uppgift.
- Automatisk arkivering av artefakter från jobbkörningar, inklusive loggar, resultat, manifest och konfiguration.
Mer information om dbt Core finns i dbt-dokumentationen.
Arbetsflöde för utveckling och produktion
Databricks rekommenderar att du utvecklar dina dbt-projekt mot ett Databricks SQL-lager. Genom att använda ett Databricks SQL-lager kan du testa SQL som genererats av dbt och använda frågehistorik för SQL-lager för att felsöka de frågor som genereras av dbt.
Databricks rekommenderar att du använder dbt-aktiviteten i ett Databricks-jobb för att köra dina dbt-transformeringar i produktion. Som standard kör dbt-aktiviteten dbt Python-processen med Hjälp av Azure Databricks-beräkning och dbt-genererad SQL mot det valda SQL-lagret.
Du kan köra dbt-transformeringar på ett serverlöst SQL-lager eller ett pro SQL-lager, Azure Databricks-beräkning eller något annat dbt-lager som stöds. I den här artikeln beskrivs de två första alternativen med exempel.
Om din arbetsyta är Unity Catalog-aktiverad och Serverlösa jobb är aktiverat körs jobbet som standard på serverlös beräkning.
Kommentar
Att utveckla dbt-modeller mot ett SQL-lager och köra dem i produktion på Azure Databricks-beräkning kan leda till subtila skillnader i prestanda och SQL-språkstöd. Databricks rekommenderar att du använder samma Databricks Runtime-version för beräkningen och SQL-lagret.
Krav
Information om hur du använder dbt Core och
dbt-databrickspaketet för att skapa och köra dbt-projekt i utvecklingsmiljön finns i Ansluta till dbt Core.Databricks rekommenderar dbt-databricks-paketet , inte dbt-spark-paketet. Dbt-databricks-paketet är en förgrening av dbt-spark som optimerats för Databricks.
Om du vill använda dbt-projekt i ett Azure Databricks-jobb måste du konfigurera Git-integrering för Databricks Git-mappar. Du kan inte köra ett dbt-projekt från DBFS.
Du måste ha serverlösa eller pro SQL-lager aktiverade.
Skapa och kör ditt första dbt-jobb
I följande exempel används projektet jaffle_shop , ett exempelprojekt som demonstrerar grundläggande dbt-begrepp. Utför följande steg för att skapa ett jobb som kör jaffle shop-projektet.
Gå till din Azure Databricks-landningssida och gör något av följande:
- Klicka på
 Arbetsflöden i sidofältet och klicka på .
Arbetsflöden i sidofältet och klicka på .
- I sidofältet klickar du på
 Ny och väljer Jobb.
Ny och väljer Jobb.
- Klicka på
I textrutan Aktivitet på fliken Aktiviteter ersätter du Lägg till ett namn för jobbet... med jobbets namn.
I Uppgiftsnamn anger du ett namn för aktiviteten.
I Typväljer du dbt aktivitetstyp.
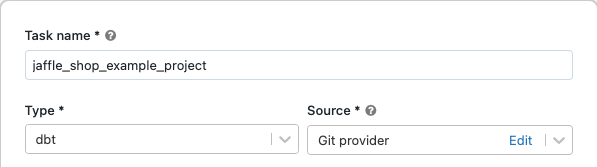
I listrutan Source kan du välja Arbetsyta för att använda ett dbt-projekt som finns i en Azure Databricks-arbetsytemapp eller Git-provider för ett projekt som finns på en fjärransluten Git-lagringsplats. Eftersom det här exemplet använder jaffle shop-projektet som finns på en Git-lagringsplats väljer du Git-provider, klickar Redigeraoch anger informationen för GitHub-lagringsplatsen jaffle shop.
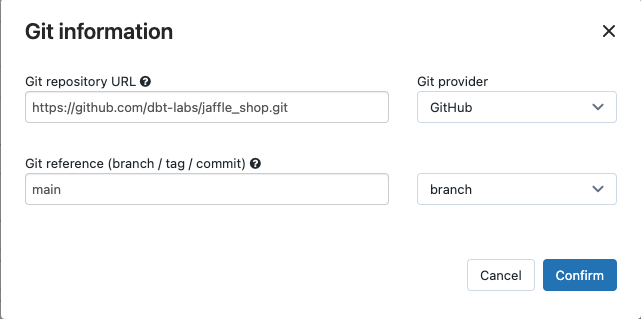
- I Git-lagringsplatsens URL anger du URL:en för jaffle shop-projektet.
- I Git-referens (gren/tagg/incheckning)anger du
main. Du kan också använda en tagg eller SHA.
Klicka på Bekräfta.
I textrutorna för dbt-kommandon anger du de dbt-kommandon som ska köras (deps, seed och run). Du måste prefixa varje kommando med
dbt. Kommandon körs i den angivna ordningen.
I SQL-lagerväljer du ett SQL-lager för att köra SQL som genereras av dbt. Den nedrullningsbara menyn i SQL-lagret visar endast serverlösa och pro SQL-lager.
(Valfritt) Du kan ange ett schema för aktivitetsutdata. Som standard används schemat
default.(Valfritt) Om du vill ändra beräkningskonfigurationen som kör dbt Core klickar du på dbt CLI-beräkning.
(Valfritt) Du kan ange en dbt-databricks-version för uppgiften. Om du till exempel vill fästa din dbt-uppgift på en specifik version för utveckling och produktion:
- Under Beroende bibliotek klickar du
 bredvid den aktuella dbt-databricks-versionen.
bredvid den aktuella dbt-databricks-versionen. - Klicka på Lägg till.
- I dialogrutan Lägg till beroende bibliotek väljer du PyPI- och anger dbt-package-versionen i textrutan Package (till exempel
dbt-databricks==1.6.0). - Klicka på Lägg till.

Kommentar
Databricks rekommenderar att du fäster dina dbt-uppgifter på en specifik version av dbt-databricks-paketet för att säkerställa att samma version används för utvecklings- och produktionskörningar. Databricks rekommenderar version 1.6.0 eller senare av dbt-databricks-paketet.
- Under Beroende bibliotek klickar du
Klicka på Skapa.
Om du vill köra jobbet nu klickar du på
 .
.
Visa resultatet av din dbt-jobbaktivitet
När jobbet är klart kan du testa resultatet genom att köra SQL-frågor från en notebook-fil eller genom att köra frågor i ditt Databricks-lager. Se till exempel följande exempelfrågor:
SHOW tables IN <schema>;
SELECT * from <schema>.customers LIMIT 10;
Ersätt <schema> med det schemanamn som konfigurerats i aktivitetskonfigurationen.
API-exempel
Du kan också använda JOBB-API:et för att skapa och hantera jobb som innehåller dbt-uppgifter. I följande exempel skapas ett jobb med en enda dbt-uppgift:
{
"name": "jaffle_shop dbt job",
"max_concurrent_runs": 1,
"git_source": {
"git_url": "https://github.com/dbt-labs/jaffle_shop",
"git_provider": "gitHub",
"git_branch": "main"
},
"job_clusters": [
{
"job_cluster_key": "dbt_CLI",
"new_cluster": {
"spark_version": "10.4.x-photon-scala2.12",
"node_type_id": "Standard_DS3_v2",
"num_workers": 0,
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode"
},
"custom_tags": {
"ResourceClass": "SingleNode"
}
}
}
],
"tasks": [
{
"task_key": "transform",
"job_cluster_key": "dbt_CLI",
"dbt_task": {
"commands": [
"dbt deps",
"dbt seed",
"dbt run"
],
"warehouse_id": "1a234b567c8de912"
},
"libraries": [
{
"pypi": {
"package": "dbt-databricks>=1.0.0,<2.0.0"
}
}
]
}
]
}
(Avancerat) Kör dbt med en anpassad profil
Om du vill köra din dbt-uppgift med ett SQL-lager (rekommenderas) eller all-purpose compute använder du en anpassad profiles.yml definition av lagret eller Azure Databricks-beräkningen för att ansluta till. Utför följande steg för att skapa ett jobb som kör jaffle shop-projektet med ett lager eller all-purpose compute.
Kommentar
Endast ett SQL-lager eller all-purpose compute kan användas som mål för en dbt-uppgift. Du kan inte använda jobbberäkning som mål för dbt.
Skapa en förgrening av den jaffle_shop lagringsplatsen.
Klona den förgrenade lagringsplatsen till skrivbordet. Du kan till exempel köra ett kommando som liknar följande:
git clone https://github.com/<username>/jaffle_shop.gitErsätt
<username>med ditt GitHub-handtag.Skapa en ny fil med namnet
profiles.ymlijaffle_shopkatalogen med följande innehåll:jaffle_shop: target: databricks_job outputs: databricks_job: type: databricks method: http schema: "<schema>" host: "<http-host>" http_path: "<http-path>" token: "{{ env_var('DBT_ACCESS_TOKEN') }}"- Ersätt
<schema>med ett schemanamn för projekttabellerna. - Om du vill köra din dbt-uppgift med ett SQL-lager ersätter du
<http-host>med värdet Servervärdnamn från fliken Anslutningsinformation för DITT SQL-lager. Om du vill köra din dbt-uppgift med all-purpose compute ersätter<http-host>du med värdet servervärdnamn från fliken Avancerade alternativ, JDBC/ODBC för din Azure Databricks-beräkning. - Om du vill köra din dbt-uppgift med ett SQL-lager ersätter du
<http-path>med VÄRDET HTTP-sökväg från fliken Anslutningsinformation för DITT SQL-lager. Om du vill köra din dbt-uppgift med all-purpose compute ersätter<http-path>du med HTTP Path-värdet från fliken Avancerade alternativ, JDBC/ODBC för din Azure Databricks-beräkning.
Du anger inte hemligheter, till exempel åtkomsttoken, i filen eftersom du kontrollerar filen i källkontrollen. I stället använder den här filen dbt-mallfunktionen för att infoga referenser dynamiskt under körning.
Kommentar
De genererade autentiseringsuppgifterna är giltiga under hela körningen, upp till högst 30 dagar, och återkallas automatiskt efter slutförandet.
- Ersätt
Kontrollera den här filen till Git och skicka den till din förgrenade lagringsplats. Du kan till exempel köra kommandon som följande:
git add profiles.yml git commit -m "adding profiles.yml for my Databricks job" git pushKlicka på
Arbetsflöden i sidofältet i Databricks-användargränssnittet.Välj DBT-jobbet och klicka på fliken Uppgifter.
I Källa klickar du på Redigera och anger din förgrenade jaffle shop GitHub-lagringsplatsinformation.
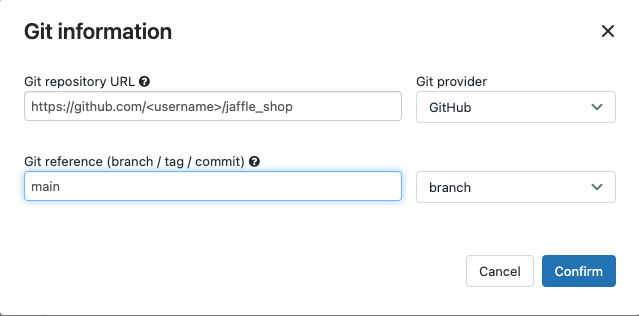
I SQL Warehouseväljer du Ingen (manuell).
I Profilkatalog anger du den relativa sökvägen till katalogen som innehåller
profiles.ymlfilen. Lämna sökvägsvärdet tomt om du vill använda standardvärdet för lagringsplatsens rot.
(Avancerat) Använda dbt Python-modeller i ett arbetsflöde
Kommentar
dbt-stöd för Python-modeller är i betaversion och kräver dbt 1.3 eller senare.
dbt stöder nu Python-modeller på specifika informationslager, inklusive Databricks. Med dbt Python-modeller kan du använda verktyg från Python-ekosystemet för att implementera transformeringar som är svåra att implementera med SQL. Du kan skapa ett Azure Databricks-jobb för att köra en enda uppgift med din dbt Python-modell, eller så kan du inkludera dbt-uppgiften som en del av ett arbetsflöde som innehåller flera uppgifter.
Du kan inte köra Python-modeller i en dbt-uppgift med hjälp av ett SQL-lager. Mer information om hur du använder dbt Python-modeller med Azure Databricks finns i Specifika informationslager i dbt-dokumentationen.
Fel och felsökning
Profilfilen finns inte
Felmeddelande:
dbt looked for a profiles.yml file in /tmp/.../profiles.yml but did not find one.
Möjliga orsaker:
Filen profiles.yml hittades inte i den angivna $PATH. Kontrollera att roten för dbt-projektet innehåller filen profiles.yml.