Så här skapar och frågar du ett vektorsökningsindex
Den här artikeln beskriver hur du skapar och frågar ett vektorsökningsindex med hjälp av Mosaic AI Vector Search.
Du kan skapa och hantera vektorsökningskomponenter, till exempel en slutpunkt för vektorsökning och vektorsökningsindex, med hjälp av användargränssnittet, Python SDKeller REST API.
Krav
- Unity Catalog-aktiverad arbetsyta.
- Serverlös beräkning aktiverad. Anvisningar finns i Anslut till serverlös beräkning.
- Källtabellen måste ha Ändringsdataflöde aktiverat. Anvisningar finns i Använda Delta Lake-ändringsdataflöde i Azure Databricks.
- Om du vill skapa ett vektorsökningsindex måste du ha CREATE TABLE behörigheter i katalogschemat där indexet skapas.
- Om du vill köra frågor mot ett index som ägs av en annan användare måste du ha ytterligare behörigheter. Se Förfråga en endpunkt för vektorsökning.
Behörighet att skapa och hantera slutpunkter för vektorsökning konfigureras med hjälp av åtkomstkontrollistor. Se ACL för vektorsökningsslutpunkten.
Installation
Om du vill använda SDK för vektorsökning måste du installera det i din notebook. Använd följande kod för att installera paketet:
%pip install databricks-vectorsearch
dbutils.library.restartPython()
Använd sedan följande kommando för att importera VectorSearchClient:
from databricks.vector_search.client import VectorSearchClient
Autentisering
Se Dataskydd och autentisering.
Skapa en slutpunkt för vektorsökning
Du kan skapa en slutpunkt för vektorsökning med hjälp av Databricks-användargränssnittet, Python SDK eller API:et.
Skapa en slutpunkt för vektorsökning med hjälp av användargränssnittet
Följ de här stegen för att skapa en slutpunkt för vektorsökning med hjälp av användargränssnittet.
I det vänstra sidofältet klickar du på Compute.
Klicka på fliken Vector Search och klicka på Skapa.

Formuläret för att skapa slutpunkt öppnas. Ange ett namn för den här slutpunkten.
Klicka på Bekräfta.
Skapa en slutpunkt för vektorsökning med hjälp av Python SDK
I följande exempel används funktionen create_endpoint() SDK för att skapa en slutpunkt för vektorsökning.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearch(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD"
)
Skapa en slutpunkt för vektorsökning med hjälp av REST-API:et
Se REST API-referensdokumentation: POST /api/2.0/vector-search/endpoints.
(Valfritt) Skapa och konfigurera en slutpunkt för att hantera inbäddningsmodellen
Om du väljer att låta Databricks beräkna inbäddningarna kan du använda en förkonfigurerad FOUNDATION Model-API:er-slutpunkt eller skapa en modell som betjänar slutpunkten för att hantera den inbäddningsmodell du väljer. För instruktioner, se API:er för betalt per token-grundmodell eller Skapa slutpunkter för betjäning av grundmodeller. Exempel på notebook-filer finns i Notebook-exempel för att anropa en inbäddningsmodell.
När du konfigurerar en inbäddningsslutpunkt rekommenderar Databricks att du tar bort standardvalet för Skala till noll. Det kan ta några minuter för att värma upp slutpunkterna, och den första frågan i ett index med en nedskalad slutpunkt kan leda till timeout.
Notera
Initialiseringen av vektorsökningsindexet kan ta slut om inbäddningstjänsten inte är korrekt konfigurerad för datauppsättningen. Du bör bara använda CPU-slutpunkter för små datamängder och tester. För större datamängder använder du en GPU-slutpunkt för optimala prestanda.
Skapa ett vektorsökningsindex
Du kan skapa ett vektorsökningsindex med hjälp av användargränssnittet, Python SDK eller REST-API:et. Användargränssnittet är den enklaste metoden.
Det finns två typer av index:
- Delta Sync Index synkroniseras automatiskt med en deltatabell för källan, och uppdaterar indexet automatiskt när underliggande data i deltatabellen ändras.
- Direct Vector Access Index stöder direkt läsning och skrivning av vektorer och metadata. Användaren ansvarar för att uppdatera den här tabellen med hjälp av REST API eller Python SDK. Det går inte att skapa den här typen av index med hjälp av användargränssnittet. Du måste använda REST-API:et eller SDK:n.
Skapa index med hjälp av användargränssnittet
I det vänstra sidofältet klickar du på Catalog för att öppna katalogutforskarens användargränssnitt.
Gå till den Delta-tabell som du vill använda.
Klicka på knappen Skapa längst upp till höger och välj Vector-sökindex från den nedrullningsbara menyn.
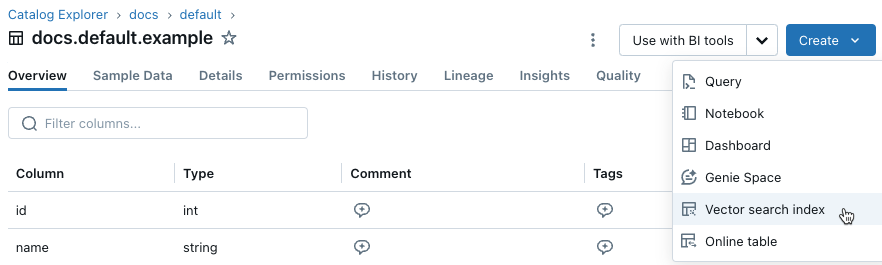
Använd väljarna i dialogrutan för att konfigurera indexet.
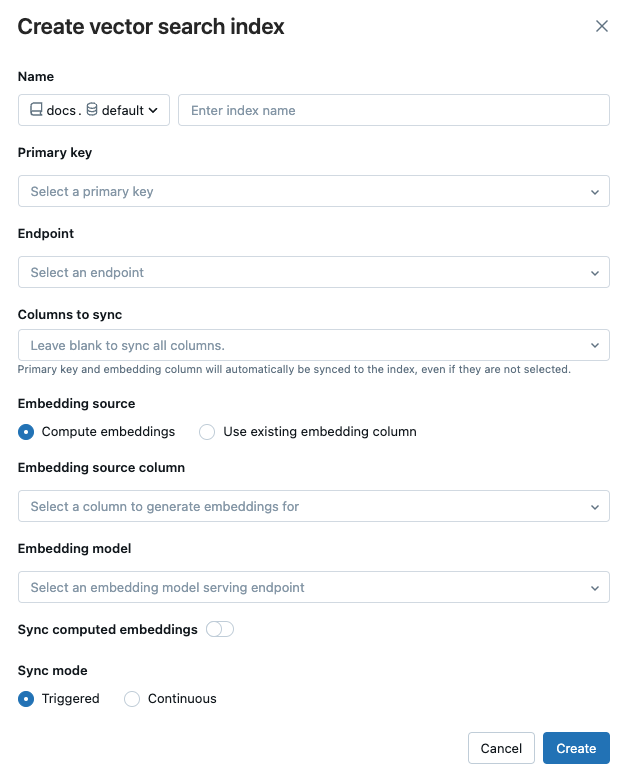
Namn: Namn som ska användas för onlinetabellen i Unity Catalog. Namnet kräver ett namnområde på tre nivåer,
<catalog>.<schema>.<name>. Endast alfanumeriska tecken och understreck tillåts.Primärnyckel: Kolumn som ska användas som primärnyckel.
Slutpunkt: Välj den slutpunkt för vektorsökning som du vill använda.
kolumner som ska synkroniseras: Välj de kolumner som ska synkroniseras med vektorindexet. Om du lämnar det här fältet tomt synkroniseras alla kolumner från källtabellen med indexet. Den primära nyckelkolumnen och den inbäddade källkolumnen eller vektorkolumnen för inbäddning synkroniseras alltid.
Inbäddningskälla: Ange om du vill att Databricks ska beräkna inbäddningar för en textkolumn i Delta-tabellen (Compute-inbäddningar), eller om deltatabellen innehåller förkomputerade inbäddningar (Använd befintlig inbäddningskolumn).
- Om du har valt Compute-inbäddningarväljer du den kolumn som du vill att inbäddningar ska beräknas för och slutpunkten som betjänar inbäddningsmodellen. Endast textkolumner stöds.
- Om du har valt Använd befintlig inbäddningskolumnväljer du den kolumn som innehåller de förberäknade inbäddningarna och inbäddningsdimensionen. Formatet för den förberäknade inbäddningskolumnen ska vara
array[float].
Synkronisera beräknade inbäddningar: Växla den här inställningen för att spara de genererade inbäddningarna i en Unity Catalog-tabell. Mer information finns i Spara genererad inbäddningstabell.
Synkroniseringsläge: Kontinuerlig håller indexet synkroniserat med sekunder av svarstid. Dock är det förenat med högre kostnader eftersom ett beräkningskluster tillhandahålls för att köra den kontinuerliga synkroniseringsströmningsprocessen. För både Continuous och Triggeredär uppdateringen inkrementell – endast data som har ändrats sedan den senaste synkroniseringen bearbetas.
Med utlöst synkroniseringsläge använder du Python SDK eller REST API för att starta synkroniseringen. Se Uppdatera ett deltasynkroniseringsindex.
När du har konfigurerat indexet klickar du på Skapa.
Skapa index med Python SDK
I följande exempel skapas ett Delta Sync-index med inbäddningar som beräknas av Databricks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2"
)
I följande exempel skapas ett Delta Sync-index med självhanterade inbäddningar. Det här exemplet visar också användningen av den valfria parametern columns_to_sync för att endast välja en delmängd av kolumner som ska användas i indexet.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Som standard synkroniseras alla kolumner från källtabellen med indexet. Om du bara vill synkronisera en delmängd kolumner använder du columns_to_sync. Primärnyckeln och inbäddningskolumnerna ingår alltid i indexet.
Om du bara vill synkronisera primärnyckeln och inbäddningskolumnen måste du ange dem i columns_to_sync enligt följande:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Om du vill synkronisera ytterligare kolumner anger du dem som visas. Du behöver inte inkludera primärnyckeln och inbäddningskolumnen eftersom de alltid synkroniseras.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
I följande exempel skapas ett direktvektoråtkomstindex.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name="{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Skapa index med hjälp av REST-API:et
Se dokumentationen för REST API-referensen: POST /api/2.0/vector-search/indexes.
Spara genererad inbäddningstabell
Om Databricks genererar inbäddningarna kan du spara de genererade inbäddningarna i en tabell i Unity Catalog. Den här tabellen skapas i samma schema som vektorindexet och länkas från vektorindexsidan.
Namnet på tabellen är namnet på vektorsökningsindexet, som läggs till av _writeback_table. Namnet kan inte redigeras.
Du kan komma åt och köra frågor mot tabellen på samma sätt som andra tabeller i Unity Catalog. Du bör dock inte släppa eller ändra tabellen eftersom den inte är avsedd att uppdateras manuellt. Tabellen tas bort automatiskt om indexet tas bort.
Uppdatera ett vektorsökningsindex
Uppdatera ett deltasynkroniseringsindex
Index som skapats med läget kontinuerlig synkronisering uppdateras automatiskt när Delta-källtabellen ändras. Om du använder utlöst synkroniseringsläge använder du Python SDK eller REST API för att starta synkroniseringen.
Python SDK
index.sync()
REST API
Se dokumentationen för REST API-referensen: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Uppdatera ett direktvektoråtkomstindex
Du kan använda Python SDK eller REST API för att infoga, uppdatera eller ta bort data från ett Direct Vector Access Index.
Python SDK
index.upsert([{"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0, 2.0, 3.0]
},
{"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1, 2.1, 3.0]
}
])
REST API
Se dokumentationen för REST API-referensen: POST /api/2.0/vector-search/indexes.
I följande kodexempel visas hur du uppdaterar ett index med hjälp av en personlig åtkomsttoken (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
I följande kodexempel visas hur du uppdaterar ett index med hjälp av tjänstens huvudnamn.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into Vector Search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from Vector Search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Fråga en slutpunkt för vektorsökning
Du kan bara köra frågor mot slutpunkten för vektorsökning med hjälp av Python SDK, REST API eller funktionen SQL vector_search() AI.
Notera
Om användaren som frågar slutpunkten inte är ägare till vektorsökningsindexet måste användaren ha följande UC-behörigheter:
- USE CATALOG i katalogen som innehåller vektorsökningsindexet.
- USE SCHEMA i schemat som innehåller vektorsökningsindexet.
- SELECT på vektorsökningsindexet.
Om du vill utföra en hybridsökning med nyckelordslikhet anger du parametern query_type till hybrid. Standardvärdet är ann (ungefärlig närmaste granne).
Python SDK
# Delta Sync Index with embeddings computed by Databricks
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2
)
# Delta Sync Index using hybrid search, with embeddings computed by Databricks
results3 = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
num_results=2,
query_type="hybrid"
)
# Delta Sync Index with pre-calculated embeddings
results2 = index.similarity_search(
query_vector=[0.2, 0.33, 0.19, 0.52],
columns=["id", "text"],
num_results=2
)
REST API
Se REST API-referensdokumentationen: POST /api/2.0/vector-search/indexes/{index_name}/query.
I följande kodexempel visas hur du kör frågor mot ett index med hjälp av en personlig åtkomsttoken (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Query Vector Search index with `query_vector`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index with `query_text`
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
Följande kodexempel illustrerar hur du gör förfrågningar mot ett index med hjälp av en tjänstprincip.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "ReadVectorIndex"}'
# If you are using an route_optimized embedding model endpoint (TODO: link), then you need to have additional authorization details to invoke the serving endpoint
# export EMBEDDING_MODEL_SERVING_ENDPOINT_ID=...
# export AUTHORIZATION_DETAILS="$AUTHORIZATION_DETAILS"',{"type":"workspace_permission","object_type":"serving-endpoints","object_path":"/serving-endpoints/'"$EMBEDDING_MODEL_SERVING_ENDPOINT_ID"'","actions": ["query_inference_endpoint"]}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_vector": [...], "columns": [...], "debug_level": 1}'
# Query Vector Search index.
curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/query --data '{"num_results": 3, "query_text": "...", "columns": [...], "debug_level": 1}'
SQL
Viktig
Funktionen vector_search() AI finns i offentlig förhandsversion.
Om du vill använda den här AI-funktionenkan du se vector_search-funktion.
Använda filter på frågor
En fråga kan definiera filter baserat på valfri kolumn i Delta-tabellen.
similarity_search returnerar endast rader som matchar de angivna filtren. Följande filter stöds:
| Filteroperatorn | Uppförande | Exempel |
|---|---|---|
NOT |
Negerar filtret. Nyckeln måste sluta med "NOT". Till exempel matchar "color NOT" med värdet "red" dokument där färgen inte är röd. |
{"id NOT": 2}
{“color NOT”: “red”}
|
< |
Kontrollerar om fältvärdet är mindre än filtervärdet. Nyckeln måste sluta med " <". Till exempel matchar "pris <" med värdet 200 dokument där priset är mindre än 200. | {"id <": 200} |
<= |
Kontrollerar om fältvärdet är mindre än eller lika med filtervärdet. Nyckeln måste sluta med " <=". Till exempel matchar "pris <=" med värdet 200 dokument där priset är mindre än eller lika med 200. | {"id <=": 200} |
> |
Kontrollerar om fältvärdet är större än filtervärdet. Nyckeln måste sluta med " >". Till exempel matchar "pris >" med värdet 200 dokument där priset är större än 200. | {"id >": 200} |
>= |
Kontrollerar om fältvärdet är större än eller lika med filtervärdet. Nyckeln måste sluta med " >=". Till exempel matchar "pris >=" med värdet 200 dokument där priset är större än eller lika med 200. | {"id >=": 200} |
OR |
Kontrollerar om fältvärdet matchar något av filtervärdena. Nyckeln måste innehålla OR för att avgränsa flera undernycklar. Till exempel matchar color1 OR color2 med värdet ["red", "blue"] dokument där antingen color1 är red eller color2blue. |
{"color1 OR color2": ["red", "blue"]} |
LIKE |
Matchar partiella strängar. | {"column LIKE": "hello"} |
| Ingen filteroperator är angiven. | Filtret söker efter en exakt matchning. Om flera värden anges matchar det något av värdena. |
{"id": 200}
{"id": [200, 300]}
|
Se följande kodexempel:
Python SDK
# Match rows where `title` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title": ["Ares", "Athena"]},
num_results=2
)
# Match rows where `title` or `id` exactly matches `Athena` or `Ares`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title OR id": ["Ares", "Athena"]},
num_results=2
)
# Match only rows where `title` is not `Hercules`
results = index.similarity_search(
query_text="Greek myths",
columns=["id", "text"],
filters={"title NOT": "Hercules"},
num_results=2
)
REST API
Se POST /api/2.0/vector-search/indexes/{index_name}/query.
Exempel på notebook-filer
Exemplen i det här avsnittet visar användningen av Python SDK för vektorsökning.
LangChain-exempel
Se Hur man använder LangChain med Mosaic AI Vector Search för att använda Mosaic AI Vector Search i samverkan med LangChain-paket.
Följande notebook-fil visar hur du konverterar sökresultat för likhet till LangChain-dokument.
Vektorsökning med Python SDK-notebooken
Notebook-exempel för att anropa en inbäddningsmodell
Följande anteckningsböcker visar hur du konfigurerar en endpoint för Mosaic AI Model Serving för generering av inbäddningar.