RAG (Retrieval Augmented Generation) på Azure Databricks
Agent Framework består av en uppsättning verktyg på Databricks som är utformade för att hjälpa utvecklare att skapa, distribuera och utvärdera produktionskvalitet AI-agenter som RAG-program (Retrieval Augmented Generation).
Den här artikeln beskriver vad RAG är och fördelarna med att utveckla RAG-program på Azure Databricks.
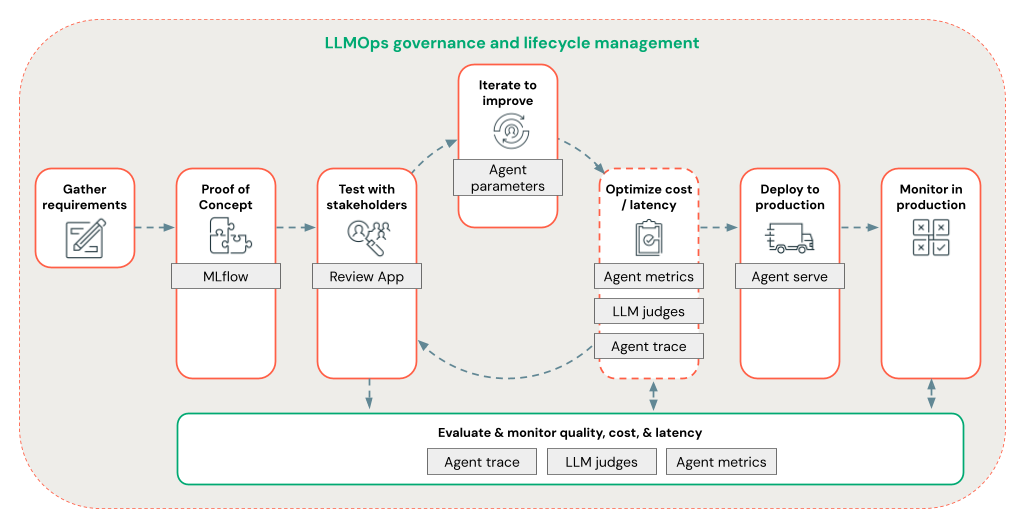
Med Agent Framework kan utvecklare iterera snabbt om alla aspekter av RAG-utveckling med hjälp av ett LLMOps-arbetsflöde från slutpunkt till slutpunkt.
Krav
- Azure AI-baserade AI-hjälpmedelsfunktioner måste vara aktiverade för din arbetsyta.
- Alla komponenter i ett agentiskt program måste finnas på en enda arbetsyta. När det till exempel gäller ett RAG-program måste serveringsmodellen och vektorsökningsinstansen finnas på samma arbetsyta.
Vad är RAG?
RAG är en generativ AI-designteknik som förbättrar stora språkmodeller (LLM) med extern kunskap. Den här tekniken förbättrar LLM:er på följande sätt:
- Patentskyddad kunskap: RAG kan innehålla upphovsrättsskyddad information som inte ursprungligen används för att träna LLM, till exempel pm, e-postmeddelanden och dokument för att besvara domänspecifika frågor.
- Uppdaterad information: Ett RAG-program kan förse LLM med information från uppdaterade datakällor.
- Med hänvisning till källor: RAG gör det möjligt för LLM:er att citera specifika källor, vilket gör det möjligt för användare att kontrollera att svaren är korrekta.
- ACL (Data Security and Access Control Lists): Hämtningssteget kan utformas för att selektivt hämta personlig eller upphovsrättsskyddad information baserat på användarautentiseringsuppgifter.
Sammansatta AI-system
Ett RAG-program är ett exempel på ett sammansatt AI-system: det utökar språkfunktionerna i LLM genom att kombinera det med andra verktyg och procedurer.
I det enklaste formatet gör ett RAG-program följande:
- Hämtning: Användarens begäran används för att fråga ett externt datalager, till exempel ett vektorlager, en textnyckelordssökning eller en SQL-databas. Målet är att få stöddata för LLM:s svar.
- Förstärkning: De hämtade data kombineras med användarens begäran, ofta med hjälp av en mall med ytterligare formatering och instruktioner, för att skapa en uppmaning.
- Generation: Uppmaningen skickas till LLM, som sedan genererar ett svar på frågan.
Ostrukturerade jämfört med strukturerade RAG-data
RAG-arkitekturen kan fungera med antingen ostrukturerade eller strukturerade stöddata. Vilka data du använder med RAG beror på ditt användningsfall.
Ostrukturerade data: Data utan en specifik struktur eller organisation. Dokument som innehåller text och bilder eller multimediainnehåll som ljud eller videor.
- PDF-filer
- Google/Office-dokument
- Wikis
- Avbildningar
- Videor
Strukturerade data: Tabelldata ordnade i rader och kolumner med ett specifikt schema, till exempel tabeller i en databas.
- Kundposter i ett BI- eller datalagersystem
- Transaktionsdata från en SQL-databas
- Data från program-API:er (t.ex. SAP, Salesforce osv.)
I följande avsnitt beskrivs ett RAG-program för ostrukturerade data.
RAG-datapipeline
RAG-datapipelinen förprocessar och indexerar dokument för snabb och korrekt hämtning.
Diagrammet nedan visar en exempeldatapipeline för en ostrukturerad datauppsättning med hjälp av en semantisk sökalgoritm. Databricks Jobs samordnar varje steg.
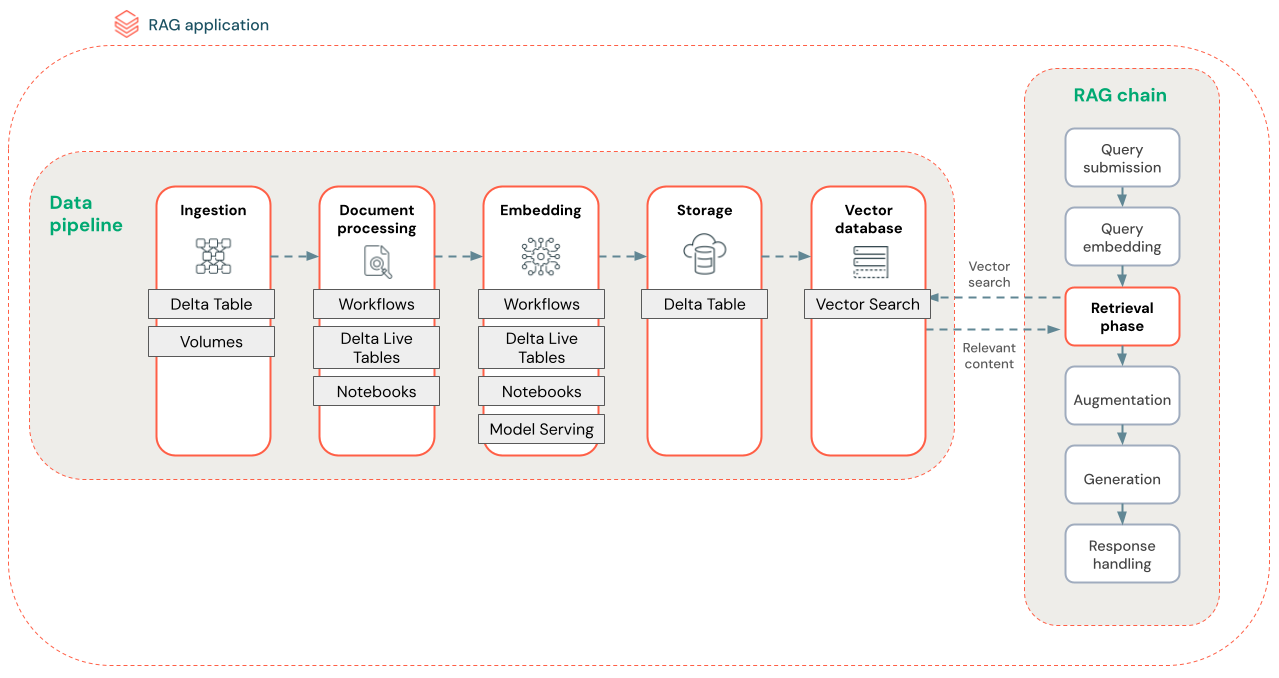
- Datainmatning – Mata in data från din egenutvecklade källa. Lagra dessa data i en Delta-tabell eller Unity-katalogvolym.
-
Dokumentbearbetning: Du kan utföra dessa uppgifter med hjälp av Databricks-jobb, Databricks Notebooks och DLT.
- Parsa rådata: Omvandla rådata till ett användbart format. Du kan till exempel extrahera text, tabeller och bilder från en samling PDF-filer eller använda optiska teckenigenkänningstekniker för att extrahera text från bilder.
- Extrahera metadata: Extrahera dokumentmetadata, till exempel dokumentrubriker, sidnummer och URL:er, så att hämtningsstegsfrågan blir mer korrekt.
- Segmentdokument: Dela upp data i segment som passar in i LLM-kontextfönstret. Genom att hämta dessa fokuserade segment, i stället för hela dokument, får LLM mer målinriktat innehåll för att generera svar.
- Inbäddningssegment – En inbäddningsmodell använder segmenten för att skapa numeriska representationer av informationen som kallas vektorinbäddningar. Vektorer representerar textens semantiska betydelse, inte bara nyckelord på ytnivå. I det här scenariot beräknar du inbäddningarna och använder Modellservering för att hantera inbäddningsmodellen.
- Inbäddningslagring – Lagra vektorinbäddningar och segmenttexten i en Delta-tabell som synkroniserats med Vector Search.
- Vektordatabas – Som en del av Vector Search indexeras inbäddningar och metadata i en vektordatabas för enkel frågekörning av RAG-agenten. När en användare gör en fråga bäddas deras begäran in i en vektor. Databasen använder sedan vektorindexet för att hitta och returnera de mest liknande segmenten.
Varje steg omfattar tekniska beslut som påverkar RAG-programmets kvalitet. Om du till exempel väljer rätt segmentstorlek i steg (3) ser du till att LLM tar emot specifik men sammanhangsberoende information, samtidigt som du väljer en lämplig inbäddningsmodell i steg (4) avgör noggrannheten för de segment som returneras under hämtningen.
Databricks-vektorsökning
Databehandlingslikheter är ofta beräkningsmässigt dyra, men vektorindex som Databricks Vector Search optimerar detta genom att effektivt organisera inbäddningar. Vektorsökningar rangordnar snabbt de mest relevanta resultaten utan att jämföra varje inbäddning med användarens fråga individuellt.
Vektorsökning synkroniserar automatiskt nya inbäddningar som lagts till i deltatabellen och uppdaterar vektorsökningsindexet.
Vad är en RAG-agent?
En RAG-agent (Retrieval Augmented Generation) är en viktig del av ett RAG-program som förbättrar funktionerna i stora språkmodeller (LLM) genom att integrera extern datahämtning. RAG-agenten bearbetar användarfrågor, hämtar relevanta data från en vektordatabas och skickar dessa data till en LLM för att generera ett svar.
Verktyg som LangChain eller Pyfunc länkar dessa steg genom att ansluta deras indata och utdata.
Diagrammet nedan visar en RAG-agent för en chattrobot och de Databricks-funktioner som används för att skapa varje agent.
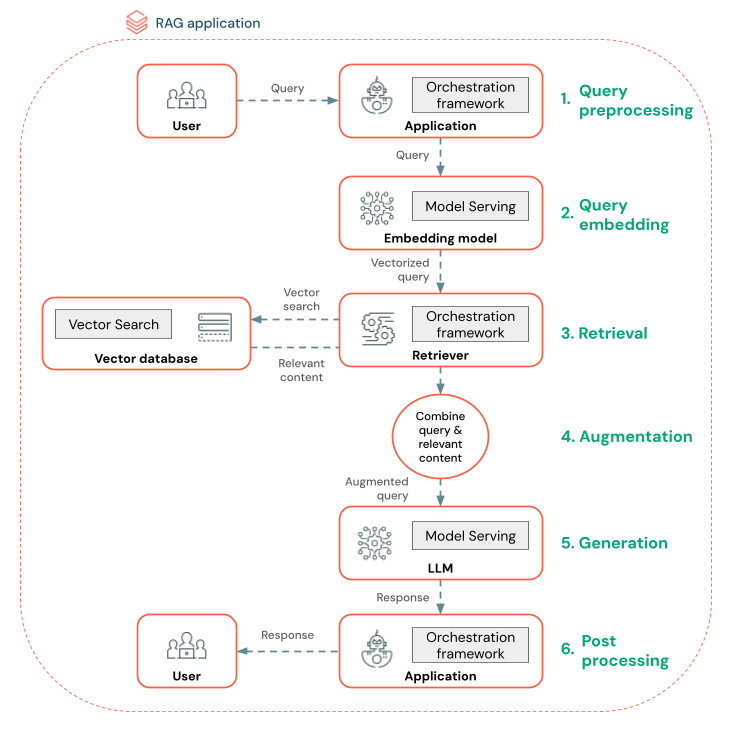
- Förbearbetning av frågor – En användare skickar en fråga, som sedan förbearbetas för att göra den lämplig för att köra frågor mot vektordatabasen. Det kan handla om att placera begäran i en mall eller extrahera nyckelord.
- Frågevektorisering – Använd modellservern för att bädda in begäran med samma inbäddningsmodell som används för att bädda in segmenten i datapipelinen. Med de här inbäddningarna kan du jämföra den semantiska likheten mellan begäran och de förbearbetade segmenten.
- Hämtningsfas – Retriever, ett program som ansvarar för att hämta relevant information, tar den vektoriserade frågan och utför en vektorlikhetssökning med vektorsökning. De mest relevanta datasegmenten rangordnas och hämtas baserat på deras likhet med frågan.
- Prompt augmentation – Retriever kombinerar de hämtade datasegmenten med den ursprungliga frågan för att ge ytterligare kontext till LLM. Uppmaningen är noggrant strukturerad för att säkerställa att LLM förstår frågans kontext. Ofta har LLM en mall för att formatera svaret. Den här processen med att justera prompten kallas "prompt engineering" (promptteknik).
- LLM-genereringsfasen – LLM genererar ett svar med hjälp av den förhöjda frågan som berikas av hämtningsresultatet. LLM kan vara en anpassad modell eller en grundmodell.
- Efterbearbetning – LLM:s svar kan bearbetas för att tillämpa ytterligare affärslogik, lägga till citat eller på annat sätt förfina den genererade texten baserat på fördefinierade regler eller begränsningar
Olika skyddsräcken kan tillämpas under hela den här processen för att säkerställa efterlevnad av företagsprinciper. Detta kan innebära filtrering av lämpliga begäranden, kontroll av användarbehörigheter innan man får åtkomst till datakällor och användning av innehållsmodereringstekniker på de genererade svaren.
Utveckling av RAG-agent på produktionsnivå
Iterera snabbt agentutveckling med hjälp av följande funktioner:
Skapa och logga agenter med valfritt bibliotek och MLflow. Parametrisera dina agenter för att experimentera och iterera agentutveckling snabbt.
Distribuera agenter till produktion med inbyggt stöd för tokenströmmar och loggning av förfrågningar och svar, plus en inbyggd granskningsapp för att få användarfeedback för din agent.
Med agentspårning kan du logga, analysera och jämföra spårningar i agentkoden för att felsöka och förstå hur din agent svarar på begäranden.
Utvärdering och övervakning
Utvärdering och övervakning hjälper dig att avgöra om DITT RAG-program uppfyller kraven på kvalitet, kostnad och svarstid. Utvärderingen sker under utvecklingen, medan övervakning sker när programmet har distribuerats till produktion.
RAG över ostrukturerade data har många komponenter som påverkar kvaliteten. Dataformateringsändringar kan till exempel påverka de hämtade segmenten och LLM:s möjlighet att generera relevanta svar. Därför är det viktigt att utvärdera enskilda komponenter utöver det övergripande programmet.
Mer information finns i Vad är Mosaic AI Agent Evaluation?.
Region tillgänglighet
För information om regional tillgänglighet av Agent Framework, se Funktioner med begränsad regional tillgänglighet