Skapa AI-agenter i kod
Den här artikeln visar hur du skapar en AI-agent i Python med hjälp av Mosaic AI Agent Framework och populära agentredigeringsbibliotek som LangGraph, PyFunc och OpenAI.
Krav
Databricks rekommenderar att du installerar den senaste versionen av MLflow Python-klienten när du utvecklar agenter.
Om du vill skapa och distribuera agenter med hjälp av metoden i den här artikeln måste du ha följande lägsta paketversioner:
-
databricks-agentsversion 0.16.0 och senare -
mlflowversion 2.20.2 och senare - Python 3.10 eller senare. Du kan använda serverlös beräkning eller Databricks Runtime 13.3 LTS och senare för att uppfylla detta krav.
%pip install -U -qqqq databricks-agents>=0.16.0 mlflow>=2.20.2
Databricks rekommenderar också att du installerar Databricks AI Bridge integreringspaket när du redigerar agenter. Dessa integreringspaket (till exempel databricks-langchain, databricks-openai) tillhandahåller ett delat lager med API:er för att interagera med Databricks AI-funktioner, till exempel Databricks AI/BI Genie och Vector Search, mellan agentredigeringsramverk och SDK:er.
LangChain/LangGraph
%pip install -U -qqqq databricks-langchain
OpenAI
%pip install -U -qqqq databricks-openai
Rena Python-agenter
%pip install -U -qqqq databricks-ai-bridge
Använd ChatAgent för att skapa agenter
Databricks rekommenderar att du använder MLflows ChatAgent-gränssnitt för att skapa agenter i produktionsklass. Den här specifikationen av chattschemat är utformad för agentscenarier och liknar, men inte strikt kompatibel med, OpenAI-ChatCompletion schema.
ChatAgent lägger också till funktionalitet för agenter som hanterar flera interaktioner och verktygsanrop.
Att redigera din agent med hjälp av ChatAgent ger följande fördelar:
Avancerade agentfunktioner
- Strömmande utdata: Aktivera interaktiva användarupplevelser genom att strömma utdata i mindre segment.
- Omfattande meddelandehistorik för verktygssamtal: Returnera flera meddelanden, inklusive mellanliggande verktygssamtalsmeddelanden, för bättre kvalitet och konversationshantering.
- Stöd för bekräftelse av verktygsanrop
- systemstöd för flera agenter
Effektiviserad utveckling, distribution och övervakning
- Framework-agnostisk Databricks-funktionsintegrering: Skriv din agent i valfria ramverk och få en komplett kompatibilitet med AI Playground, AgentUtvärdering och Agentövervakning.
- Typed authoring interfaces: Skriv agentkod med typade Python-klasser och dra nytta av IDE och notebook-autocomplete.
-
Automatisk signaturinferens: MLflow härleder automatiskt
ChatAgentsignaturer när agenten loggas, vilket förenklar registreringen och distributionen. Se Kontrollera modellsignatur under loggning. - AI Gateway-förbättrade slutsatsdragningstabeller: AI Gateway-slutsatsdragningstabeller aktiveras automatiskt för distribuerade agenter, vilket ger åtkomst till detaljerade metadata för begärandeloggar.
Information om hur du skapar en ChatAgentfinns i exemplen i följande avsnitt och MLflow-dokumentation – Vad är ChatAgent-gränssnittet.
ChatAgent exempel
Följande notebooks visar hur du skapar både strömmande och icke-strömmande innehåll med hjälp av de populära biblioteken OpenAI och LangGraph.
LangGraph verktygsanropsagent
Agent för OpenAI-verktygsanrop
OpenAI-chattagent
Information om hur du utökar funktionerna för dessa agenter genom att lägga till verktyg finns i AI-agentverktyg.
Exempel på system med flera agenter ChatAgent
Information om hur du skapar ett system med flera agenter med Genie finns i Använda Genie i system med flera agenter.
Skapa distributionsklara ChatAgent för Databricks modellhantering
Databricks distribuerar ChatAgenti en distribuerad miljö på Databricks Model Serving, vilket innebär att samma serveringsreplik kanske inte hanterar alla begäranden under en konversation med flera turer. Var uppmärksam på följande konsekvenser för att hantera agenttillstånd:
Undvik lokal cachelagring: När du distribuerar en
ChatAgentantar du inte att samma replik hanterar alla begäranden i en konversation med flera turer. Rekonstruera det interna tillståndet med hjälp av ett ordboksschemaChatAgentRequestför varje omgång.trådsäkert tillstånd: Utforma agenttillståndet så att det är trådsäkert, vilket förhindrar konflikter i miljöer med flera trådar.
Initiera tillstånd i funktionen
predict: Initiera tillstånd varje gång funktionenpredictanropas, inte underChatAgentinitiering. Lagra tillstånd påChatAgent-nivå kan läcka information mellan samtal och orsaka konflikter eftersom en endaChatAgent-kopia kan hantera begäranden från flera samtal.
Anpassade indata och utdata
Vissa scenarier kan kräva ytterligare agentindata, till exempel client_type och session_id, eller utdata som hämtning av källlänkar som inte ska ingå i chatthistoriken för framtida interaktioner.
I dessa scenarier stöder MLflow ChatAgent inbyggt fälten custom_inputs och custom_outputs.
Varning
Granskningsappen Agentutvärdering stöder för närvarande inte återgivning av spårningar för agenter med ytterligare indatafält.
Se följande exempel för att lära dig hur du anger anpassade indata och utdata för OpenAI/PyFunc- och LangGraph-agenter.
OpenAI + PyFunc– anpassad schemaagentanteckningsbok
Anpassad schemagentsanteckningsbok för LangGraph
Tillhandahåll custom_inputs i AI Playground- och agentrecensionsappen
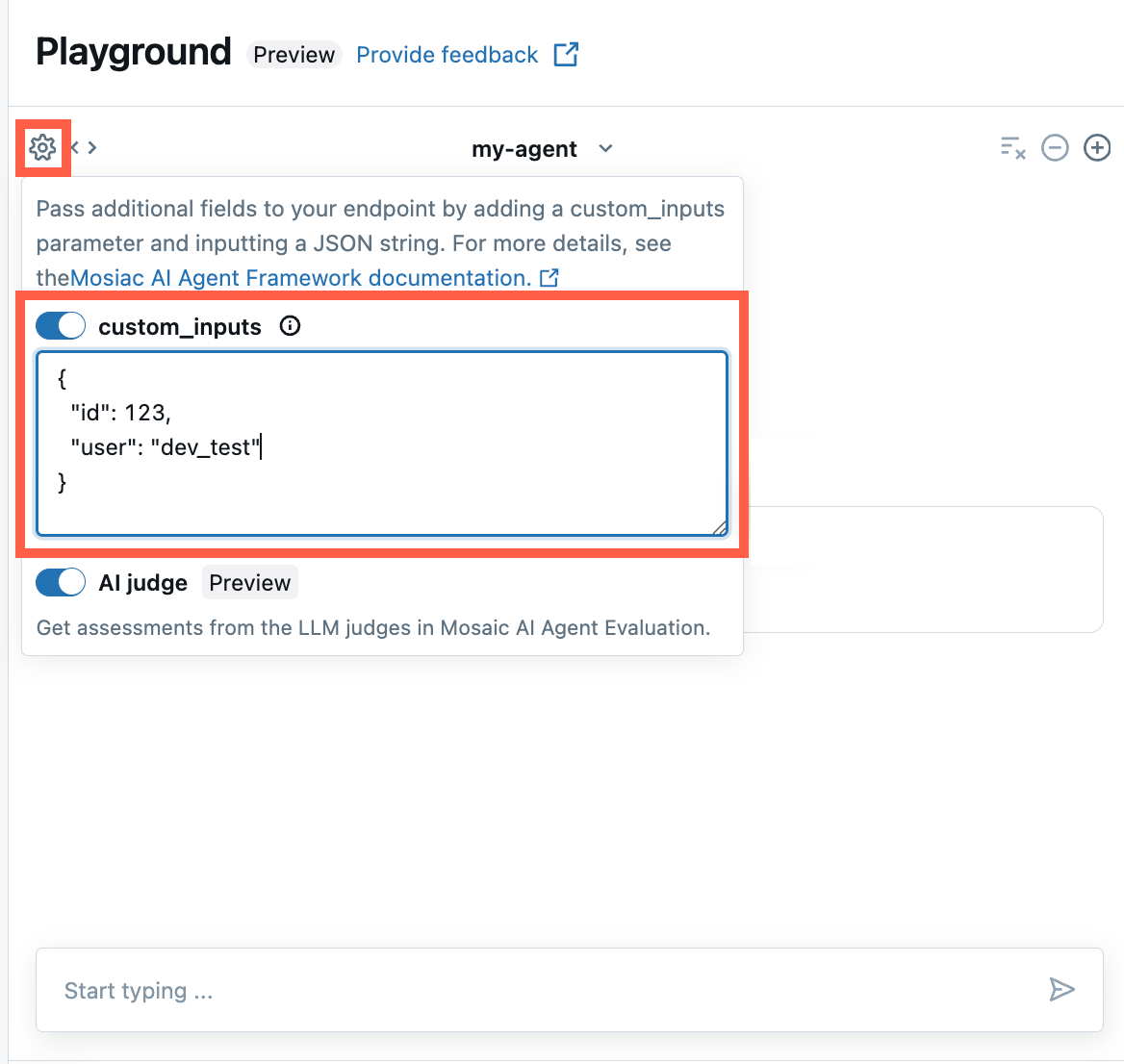
Om din agent accepterar ytterligare indata med hjälp av fältet custom_inputs kan du manuellt ange dessa indata i både AI Playground- och agentgranskningsappen.
I antingen AI Playground eller Agent Review App väljer du kugghjulsikonen
 .
.Aktivera custom_inputs.
Ange ett JSON-objekt som matchar agentens definierade indataschema.
Ange anpassade retriever-scheman
AI-agenter använder ofta hämtare för att hitta och ställa frågor mot ostrukturerade data från vektorindex. Exempel på verktyg för hämtning finns i Ai-agentverktyg för ostrukturerad hämtning.
Spåra dessa sökmotorer i din agent med MLflow RETRIEVER-span för att aktivera Databricks produktfunktioner, inklusive:
- Visa länkar automatiskt till hämtade källdokument i AI Playground-användargränssnittet
- Automatiskt köra hämtningens grundlighet och relevansbedömare i agentutvärdering
Anteckning
Databricks rekommenderar att du använder hämtningsverktyg som tillhandahålls av Databricks AI Bridge-paket som databricks_langchain.VectorSearchRetrieverTool och databricks_openai.VectorSearchRetrieverTool eftersom de redan överensstämmer med MLflow retriever-schemat. Se utveckla verktyg för vektorsökning lokalt med AI Bridge.
Om din agent innehåller hämtningsintervall med ett anpassat schema anropar du mlflow.models.set_retriever_schema när du definierar din agent i kod. Detta mappar utdatakolumnerna för din hämtare till MLflows förväntade fält (primary_key, text_column, doc_uri).
import mlflow
# Define the retriever's schema by providing your column names
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="chunk_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="text_column",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
)
Anteckning
Kolumnen doc_uri är särskilt viktig när du utvärderar retrievarens prestanda.
doc_uri är huvudidentifieraren för dokument som returneras av hämtaren, så att du kan jämföra dem med utvärderingsuppsättningar för grundsanning. Se Utvärderingssatser.
Parametrize-agentkod för distribution i olika miljöer
Du kan parametrisera agentkod för att återanvända samma agentkod i olika miljöer.
Parametrar är nyckel/värde-par som du definierar i en Python-ordlista eller en .yaml fil.
Om du vill konfigurera koden skapar du en ModelConfig med antingen en Python-ordlista eller en .yaml fil.
ModelConfig är en uppsättning nyckel/värde-parametrar som möjliggör flexibel konfigurationshantering. Du kan till exempel använda en ordlista under utvecklingen och sedan konvertera den till en .yaml fil för produktionsdistribution och CI/CD.
Mer information om ModelConfigfinns i MLflow-dokumentationen.
Ett exempel ModelConfig visas nedan:
llm_parameters:
max_tokens: 500
temperature: 0.01
model_serving_endpoint: databricks-dbrx-instruct
vector_search_index: ml.docs.databricks_docs_index
prompt_template: 'You are a hello world bot. Respond with a reply to the user''s
question that indicates your prompt template came from a YAML file. Your response
must use the word "YAML" somewhere. User''s question: {question}'
prompt_template_input_vars:
- question
I din agentkod kan du referera till en standardkonfiguration (utveckling) från .yaml fil eller ordlista:
import mlflow
# Example for loading from a .yml file
config_file = "configs/hello_world_config.yml"
model_config = mlflow.models.ModelConfig(development_config=config_file)
# Example of using a dictionary
config_dict = {
"prompt_template": "You are a hello world bot. Respond with a reply to the user's question that is fun and interesting to the user. User's question: {question}",
"prompt_template_input_vars": ["question"],
"model_serving_endpoint": "databricks-dbrx-instruct",
"llm_parameters": {"temperature": 0.01, "max_tokens": 500},
}
model_config = mlflow.models.ModelConfig(development_config=config_dict)
# Use model_config.get() to retrieve a parameter value
# You can also use model_config.to_dict() to convert the loaded config object
# into a dictionary
value = model_config.get('sample_param')
När du loggar agenten, ange sedan parametern model_config till log_model för att definiera en anpassad uppsättning parametrar som ska användas vid inläsning av den loggade agenten. Se MLflow-dokumentation – ModelConfig.
Spridning av streamingfel
Mosaic AI vidarebefordrar alla fel som upptäcks vid dataströmning med den sista token under databricks_output.error. Det är upp till den anropande klienten att hantera och rapportera det här felet korrekt.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}