Självstudie: Köra Python i ett kluster och som ett jobb med databricks-tillägget för Visual Studio Code
Den här självstudien beskriver hur du konfigurerar Databricks-tillägget för Visual Studio Code och sedan kör Python på ett Azure Databricks-kluster och som ett Azure Databricks-jobb på din fjärranslutna arbetsyta. Se Vad är Databricks-tillägget för Visual Studio Code?.
Krav
Den här självstudien kräver att:
- Du har installerat Databricks-tillägget för Visual Studio Code. Se Installera Databricks-tillägget för Visual Studio Code.
- Du har ett Fjärranslutet Azure Databricks-kluster att använda. Anteckna klustrets namn. Om du vill visa dina tillgängliga kluster går du till sidofältet för Azure Databricks-arbetsytan och klickar på Beräkning. Se Beräkning.
Steg 1: Skapa ett nytt Databricks-projekt
I det här steget skapar du ett nytt Databricks-projekt och konfigurerar anslutningen till din fjärranslutna Azure Databricks-arbetsyta.
- Starta Visual Studio Code och klicka sedan på Öppna > mapp och öppna en tom mapp på din lokala utvecklingsdator.
- Klicka på ikonen för Databricks-logotypen i sidopanelen. Då öppnas Databricks-tillägget.
- I vyn Konfiguration klickar du på Skapa konfiguration.
- Kommandopaletten för att konfigurera databricks-arbetsytan öppnas. För Databricks Host anger eller väljer du url:en per arbetsyta, till exempel
https://adb-1234567890123456.7.azuredatabricks.net. - Välj en autentiseringsprofil för projektet. Se Konfigurera auktorisering för Databricks-tillägget för Visual Studio Code.
Steg 2: Lägg till klusterinformation i Databricks-tillägget och starta klustret
När konfigurationsvyn redan är öppen klickar du på Välj ett kluster eller klickar på kugghjulsikonen (Konfigurera kluster).
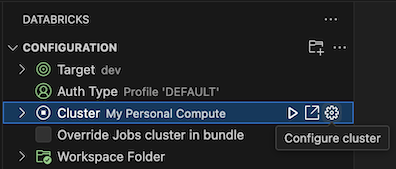
I kommandopaletten väljer du namnet på klustret som du skapade tidigare.
Klicka på uppspelningsikonen (Starta kluster) om den inte redan har startats.
Steg 3: Skapa och köra Python-kod
Skapa en lokal Python-kodfil: I sidofältet klickar du på mappikonen (Explorer).
På huvudmenyn klickar du på Arkiv > Ny fil och väljer en Python-fil. Ge filen namnet demo.py och spara den i projektets rot.
Lägg till följande kod i filen och spara den sedan. Den här koden skapar och visar innehållet i en grundläggande PySpark DataFrame:
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show()# +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+Klicka på ikonen Kör på Databricks bredvid listan med redigeringsflikar och klicka sedan på Ladda upp och kör fil. Utdata visas i felsökningskonsolvyn.
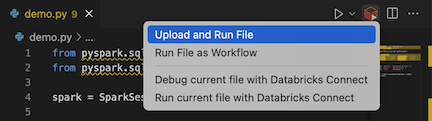
Du kan också högerklicka på filen i utforskarvyn och sedan klicka
demo.py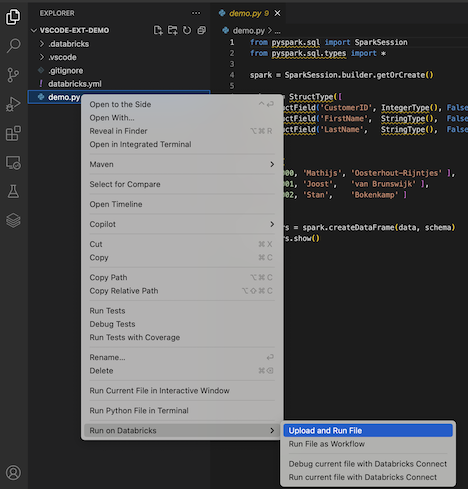
Steg 4: Kör koden som ett jobb
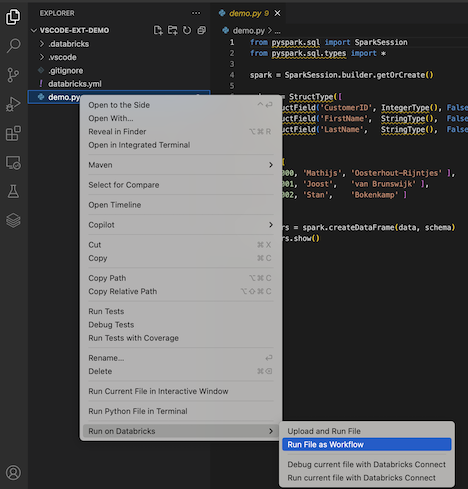
Om du vill köra demo.py som ett jobb klickar du på ikonen Kör på Databricks bredvid listan över redigeringsflikar och klickar sedan på Kör fil som arbetsflöde. Utdata visas på en separat redigeringsflik bredvid demo.py filredigeraren.
![]()
Du kan också högerklicka på demo.py filen i utforskarpanelenoch sedan välja Kör på Databricks>Kör fil som arbetsflöde.
Nästa steg
Nu när du har använt Databricks-tillägget för Visual Studio Code för att ladda upp en lokal Python-fil och köra den via fjärranslutning kan du också:
- Utforska Databricks Asset Bundles-resurser och variabler med hjälp av tilläggsgränssnittet. Se Tilläggsfunktionerna för Databricks Asset Bundles.
- Kör eller felsöka Python-kod med Databricks Connect. Se Felsöka kod med Databricks Connect för Databricks-tillägget för Visual Studio Code.
- Kör en fil eller en notebook-fil som ett Azure Databricks-jobb. Se Köra en fil i ett kluster eller en fil eller notebook-fil som ett jobb i Azure Databricks med hjälp av Databricks-tillägget för Visual Studio Code.
- Kör tester med
pytest. Se Köra tester med pytest med Databricks-tillägget för Visual Studio Code.