Kör en fil i ett kluster eller en fil eller notebook-fil som ett jobb i Azure Databricks med hjälp av Databricks-tillägget för Visual Studio Code
Med Databricks-tillägget för Visual Studio Code kan du köra Din Python-kod på ett kluster eller din Python-, R-, Scala- eller SQL-kod eller en notebook-fil som ett jobb i Azure Databricks.
Den här informationen förutsätter att du redan har installerat och konfigurerat Databricks-tillägget för Visual Studio Code. Se Installera Databricks-tillägget för Visual Studio Code.
Kommentar
Om du vill felsöka kod eller notebook-filer från Visual Studio Code använder du Databricks Connect. Se Felsöka kod med Databricks Connect för Databricks-tillägget för Visual Studio Code och Kör och felsöka notebook-celler med Databricks Connect med hjälp av Databricks-tillägget för Visual Studio Code.
Köra en Python-fil i ett kluster
Så här kör du en Python-fil i ett Azure Databricks-kluster med hjälp av Databricks-tillägget för Visual Studio Code med tillägget och projektet öppnat:
- Öppna Den Python-fil som du vill köra i klustret.
- Gör något av följande:
I filredigerarens namnlist klickar du på ikonen Kör på Databricks och klickar sedan på Ladda upp och kör fil.
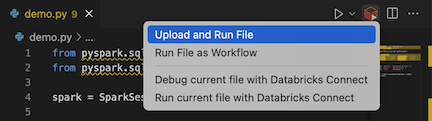
I Utforskarvyn (Visa utforskaren>
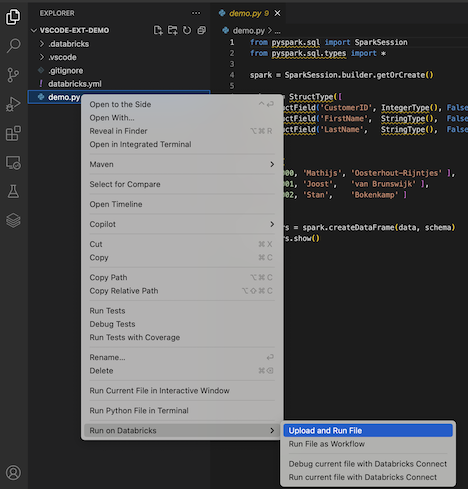
Filen körs i klustret och utdata är tillgängliga i felsökningskonsolen (Visa > felsökningskonsol).
Köra en Python-fil som ett jobb
Så här kör du en Python-fil som ett Azure Databricks-jobb med hjälp av Databricks-tillägget för Visual Studio Code med tillägget och projektet öppnat:
- Öppna Den Python-fil som du vill köra som ett jobb.
- Gör något av följande:
I filredigerarens namnlist klickar du på ikonen Kör på Databricks och klickar sedan på Kör fil som arbetsflöde.
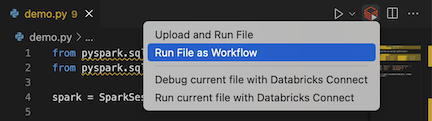
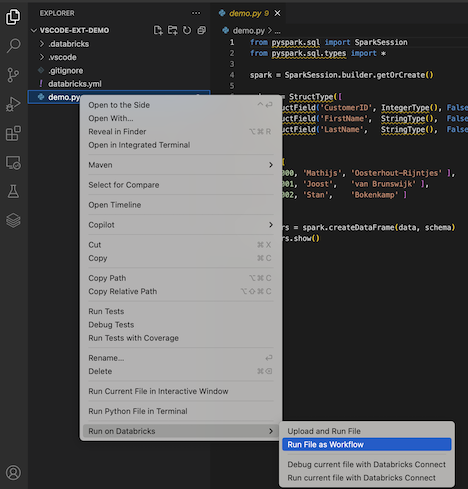
I Explorer-vyn (Visa utforskaren>
En ny redigeringsflik visas med titeln Databricks Job Run. Filen körs som ett jobb på arbetsytan och eventuella utdata skrivs ut till den nya redigerarflikens utdataområde .
Om du vill visa information om jobbkörningen klickar du på länken Aktivitetskörnings-ID i den nya redigeraren för Databricks-jobbkörning . Arbetsytan öppnas och jobbkörningens information visas på arbetsytan.
Kör en Python-, R-, Scala- eller SQL-notebook-fil som ett jobb
Så här kör du en notebook-fil som ett Azure Databricks-jobb med hjälp av Databricks-tillägget för Visual Studio Code med tillägget och projektet öppnat:
Öppna anteckningsboken som du vill köra som ett jobb.
Dricks
Om du vill omvandla en Python-, R-, Scala- eller SQL-fil till en Azure Databricks-notebook-fil lägger du till kommentaren
# Databricks notebook sourcei början av filen och lägger till kommentaren# COMMAND ----------före varje cell. Mer information finns i Importera en fil och konvertera den till en notebook-fil.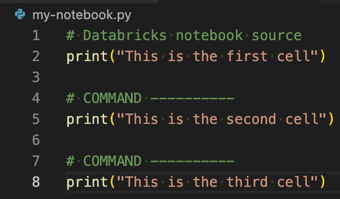
Gör något av följande:
- I namnlisten för anteckningsboksfilen klickar du på ikonen Kör på Databricks och klickar sedan på Kör fil som arbetsflöde.
Kommentar
Om Kör på Databricks som arbetsflöde inte är tillgängligt kan du läsa Skapa en anpassad körningskonfiguration.
- I Utforskarvyn>
En ny redigeringsflik visas med titeln Databricks Job Run. Anteckningsboken körs som ett jobb på arbetsytan. Anteckningsboken och dess utdata visas i den nya redigerarflikens utdataområde .
Om du vill visa information om jobbkörningen klickar du på länken Aktivitetskörnings-ID på fliken Databricks-jobbkörningsredigeraren . Arbetsytan öppnas och jobbkörningens information visas på arbetsytan.
Skapa en anpassad körningskonfiguration
Med en anpassad körningskonfiguration för Databricks-tillägget för Visual Studio Code kan du skicka anpassade argument till ett jobb eller en notebook-fil eller skapa olika körningsinställningar för olika filer.
Om du vill skapa en anpassad körningskonfiguration klickar du på Kör > Lägg till konfiguration från huvudmenyn i Visual Studio Code. Välj sedan Antingen Databricks för en klusterbaserad körningskonfiguration eller Databricks: Arbetsflöde för en jobbbaserad körningskonfiguration.
Följande anpassade körningskonfiguration ändrar till exempel kommandot Kör fil som arbetsflödesstart för att skicka --prod argumentet till jobbet:
{
"version": "0.2.0",
"configurations": [
{
"type": "databricks-workflow",
"request": "launch",
"name": "Run on Databricks as Workflow",
"program": "${file}",
"parameters": {},
"args": ["--prod"]
}
]
}
Dricks
Lägg till "databricks": true i konfigurationen "type": "python" om du vill använda Python-konfiguration men dra nytta av Den Databricks Connect-autentisering som ingår i tilläggskonfigurationen.
Med hjälp av anpassade körningskonfigurationer kan du även skicka in kommandoradsargument och köra koden bara genom att trycka på F5. Mer information finns i Starta konfigurationer i Visual Studio Code-dokumentationen.