CI/CD med Jenkins på Azure Databricks
Kommentar
Den här artikeln beskriver Jenkins, som har utvecklats av en tredje part. Information om hur du kontaktar providern finns i Jenkins-hjälpen.
Det finns många CI/CD-verktyg som du kan använda för att hantera och köra DINA CI/CD-pipelines. Den här artikeln visar hur du använder Jenkins automation-servern. CI/CD är ett designmönster, så de steg och steg som beskrivs i den här artikeln bör överföras med några ändringar i pipelinedefinitionsspråket i varje verktyg. Dessutom kör mycket av koden i den här exempelpipelinen python-standardkod, som du kan anropa i andra verktyg. En översikt över CI/CD på Azure Databricks finns i Vad är CI/CD på Azure Databricks?.
Information om hur du använder Azure DevOps med Azure Databricks i stället finns i Kontinuerlig integrering och leverans på Azure Databricks med Azure DevOps.
CI/CD-utvecklingsarbetsflöde
Databricks föreslår följande arbetsflöde för CI/CD-utveckling med Jenkins:
- Skapa en lagringsplats eller använd en befintlig lagringsplats med git-providern från tredje part.
- Anslut din lokala utvecklingsdator till samma lagringsplats från tredje part. Anvisningar finns i dokumentationen för git-providern från tredje part.
- Hämta befintliga uppdaterade artefakter (till exempel notebook-filer, kodfiler och byggskript) från lagringsplatsen från tredje part till din lokala utvecklingsdator.
- Som du vill skapar, uppdaterar och testar du artefakter på din lokala utvecklingsdator. Skicka sedan alla nya och ändrade artefakter från din lokala utvecklingsdator till lagringsplatsen från tredje part. Instruktioner finns i git-providerns documenation från tredje part.
- Upprepa steg 3 och 4 efter behov.
- Använd Jenkins regelbundet som en integrerad metod för att automatiskt hämta artefakter från lagringsplatsen från tredje part till din lokala utvecklingsdator eller Azure Databricks-arbetsyta. skapa, testa och köra kod på din lokala utvecklingsdator eller Azure Databricks-arbetsyta. och rapportera test- och körningsresultat. Du kan köra Jenkins manuellt, men i verkliga implementeringar instruerar du git-providern från tredje part att köra Jenkins varje gång en specifik händelse inträffar, till exempel en pull-begäran för lagringsplats.
Resten av den här artikeln använder ett exempelprojekt för att beskriva ett sätt att använda Jenkins för att implementera föregående CI/CD-utvecklingsarbetsflöde.
Information om hur du använder Azure DevOps i stället för Jenkins finns i Kontinuerlig integrering och leverans på Azure Databricks med Hjälp av Azure DevOps.
Datorkonfiguration för lokal utveckling
I den här artikelns exempel används Jenkins för att instruera Databricks CLI - och Databricks-tillgångspaketen att göra följande:
- Skapa en Python-hjulfil på din lokala utvecklingsdator.
- Distribuera den byggda Python-hjulfilen tillsammans med ytterligare Python-filer och Python-notebook-filer från din lokala utvecklingsdator till en Azure Databricks-arbetsyta.
- Testa och kör den uppladdade Python-hjulfilen och notebook-filerna på den arbetsytan.
Gör följande på din lokala utvecklingsdator för att instruera din Azure Databricks-arbetsyta att utföra bygg- och uppladdningsstegen för det här exemplet:
Steg 1: Installera nödvändiga verktyg
I det här steget installerar du verktygen Databricks CLI, Jenkins, jqoch Python wheel build på din lokala utvecklingsdator. Dessa verktyg krävs för att köra det här exemplet.
Installera Databricks CLI version 0.205 eller senare, om du inte redan har gjort det. Jenkins använder Databricks CLI för att skicka det här exemplets test- och körningsinstruktioner till din arbetsyta. Se Installera eller uppdatera Databricks CLI-.
Installera och starta Jenkins om du inte redan har gjort det. Se Installera Jenkins för Linux, macOS eller Windows.
Installera jq. Det här exemplet används
jqför att parsa vissa JSON-formaterade kommandoutdata.Använd
pipför att installera Python wheel build-verktygen med följande kommando (vissa system kan kräva att du använderpip3i ställetpipför ):pip install --upgrade wheel
Steg 2: Skapa en Jenkins-pipeline
I det här steget använder du Jenkins för att skapa en Jenkins-pipeline för den här artikelns exempel. Jenkins tillhandahåller några olika projekttyper för att skapa CI/CD-pipelines. Jenkins Pipelines tillhandahåller ett gränssnitt för att definiera faser i en Jenkins-pipeline med hjälp av Groovy-kod för att anropa och konfigurera Jenkins-plugin-program.
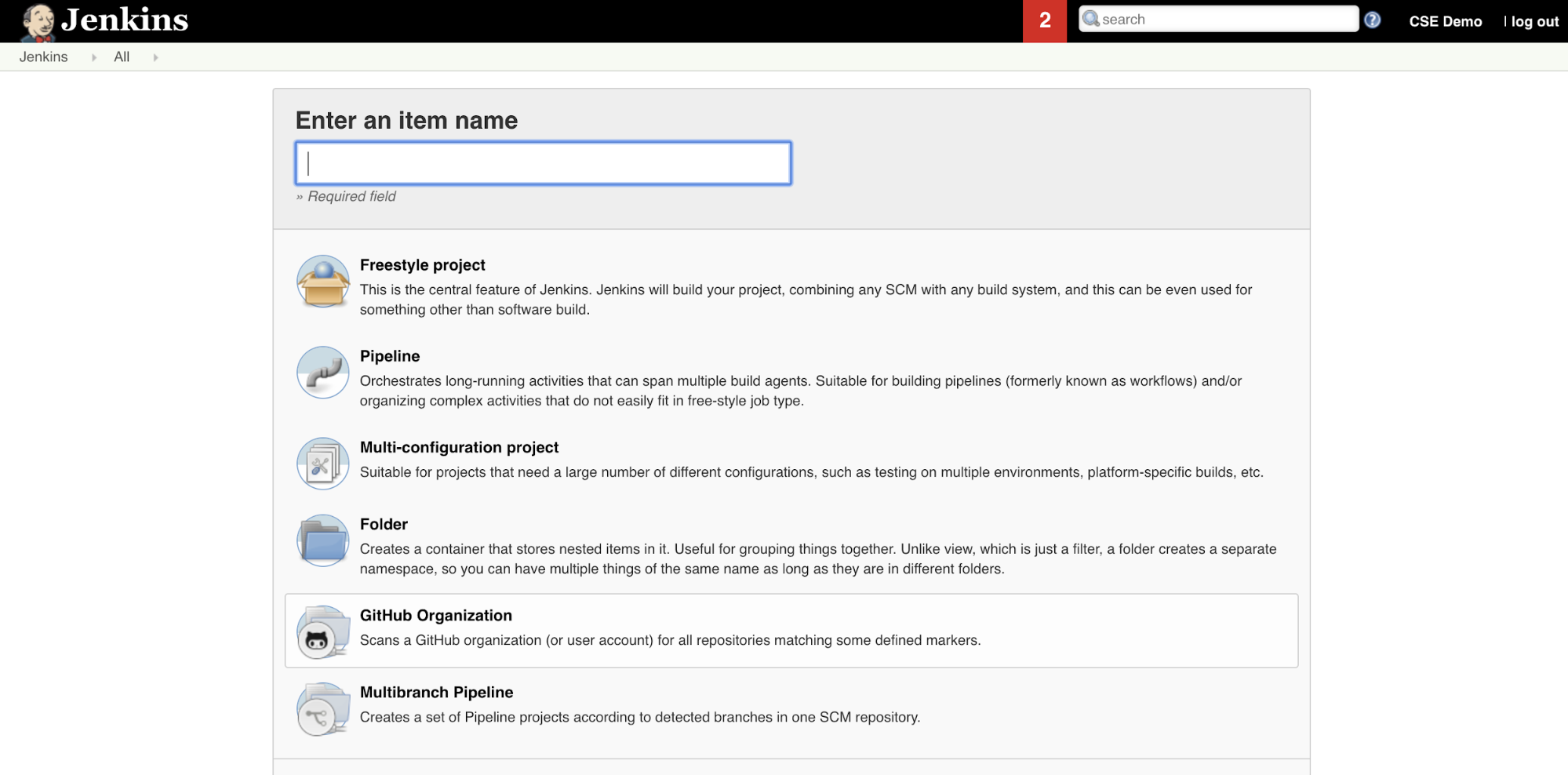
Så här skapar du Jenkins-pipelinen i Jenkins:
- När du har startat Jenkins klickar du på Nytt objekt från Jenkins-instrumentpanelen.
- För Ange ett objektnamn skriver du ett namn för Jenkins-pipelinen, till exempel
jenkins-demo. - Klicka på ikonen Typ av pipelineprojekt.
- Klicka på OK. Sidan Konfigurera i Jenkins-pipelinen visas.
- I listrutan Pipeline i listrutan Definiera väljer du Pipeline-skript från SCM.
- I listrutan SCM väljer du Git.
- För Lagringsplats-URL anger du URL:en till den lagringsplats som hanteras av git-providern i tredje delen.
- För Grenspecificerare
- För Skriptsökväg skriver du
Jenkinsfile, om den inte redan har angetts. Du skapar senare i denJenkinsfilehär artikeln. - Avmarkera kryssrutan Lightweight om den redan är markerad.
- Klicka på Spara.
Steg 3: Lägg till globala miljövariabler i Jenkins
I det här steget lägger du till tre globala miljövariabler till Jenkins. Jenkins skickar dessa miljövariabler vidare till Databricks CLI. Databricks CLI behöver värdena för dessa miljövariabler för att autentisera med din Azure Databricks-arbetsyta. I det här exemplet används OAuth-autentisering från dator till dator (M2M) för tjänstens huvudnamn (även om andra autentiseringstyper också är tillgängliga). Information om hur du konfigurerar OAuth M2M-autentisering för din Azure Databricks-arbetsyta finns i Auktorisera obevakad åtkomst till Azure Databricks-resurser med tjänstens huvudnamn med OAuth.
De tre globala miljövariablerna för det här exemplet är:
-
DATABRICKS_HOSTanger du till url:en för din Azure Databricks-arbetsyta, från och medhttps://. Se Namn på arbetsyteinstanser, URL:er och ID:er. -
DATABRICKS_CLIENT_ID, inställt på tjänstens huvudnamns klient-ID, som även kallas dess program-ID. -
DATABRICKS_CLIENT_SECRET, inställt på tjänstens huvudnamns Azure Databricks OAuth-hemlighet.
Så här anger du globala miljövariabler i Jenkins från Jenkins-instrumentpanelen:
- I sidofältet klickar du på Hantera Jenkins.
- I avsnittet Systemkonfiguration klickar du på System.
- I avsnittet Globala egenskaper markerar du kryssrutan med tillagda miljövariabler.
- Klicka på Lägg till och ange sedan miljövariabelns namn och värde. Upprepa detta för varje ytterligare miljövariabel.
- När du är klar med att lägga till miljövariabler klickar du på Spara för att återgå till Jenkins-instrumentpanelen.
Utforma Jenkins-pipelinen
Jenkins tillhandahåller några olika projekttyper för att skapa CI/CD-pipelines. Det här exemplet implementerar en Jenkins-pipeline. Jenkins Pipelines tillhandahåller ett gränssnitt för att definiera faser i en Jenkins-pipeline med hjälp av Groovy-kod för att anropa och konfigurera Jenkins-plugin-program.
Du skriver en Jenkins Pipeline-definition i en textfil med namnet Jenkinsfile, som i sin tur är incheckad i ett projekts källkontrolllagringsplats. Mer information finns i Jenkins Pipeline. Här är Jenkins-pipelinen för den här artikelns exempel. I det här exemplet Jenkinsfileersätter du följande platshållare:
- Ersätt
<user-name>och<repo-name>med användarnamnet och lagringsplatsens namn för din git-provider i tredje delen. I den här artikeln används en GitHub-URL som exempel. - Ersätt
<release-branch-name>med namnet på versionsgrenen på lagringsplatsen. Det kan till exempel varamain. - Ersätt
<databricks-cli-installation-path>med sökvägen på den lokala utvecklingsdatorn där Databricks CLI är installerat. I macOS kan det till exempel vara/usr/local/bin. - Ersätt
<jq-installation-path>med sökvägen på din lokala utvecklingsdator därjqär installerad. I macOS kan det till exempel vara/usr/local/bin. - Ersätt
<job-prefix-name>med en sträng som hjälper dig att unikt identifiera de Azure Databricks-jobb som skapas på din arbetsyta för det här exemplet. Det kan till exempel varajenkins-demo. - Observera att
BUNDLETARGETär inställt pådev, vilket är namnet på Databricks Asset Bundle-målet som definieras senare i den här artikeln. I verkliga implementeringar ändrar du detta till namnet på ditt eget paketmål. Mer information om paketmål finns senare i den här artikeln.
Här är Jenkinsfile, som måste läggas till i roten på lagringsplatsen:
// Filename: Jenkinsfile
node {
def GITREPOREMOTE = "https://github.com/<user-name>/<repo-name>.git"
def GITBRANCH = "<release-branch-name>"
def DBCLIPATH = "<databricks-cli-installation-path>"
def JQPATH = "<jq-installation-path>"
def JOBPREFIX = "<job-prefix-name>"
def BUNDLETARGET = "dev"
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_ROOT_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
-t ${BUNDLETARGET} \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
}
Resten av den här artikeln beskriver varje steg i den här Jenkins-pipelinen och hur du konfigurerar artefakter och kommandon för Jenkins som ska köras i det skedet.
Hämta de senaste artefakterna från lagringsplatsen från tredje part
Den första fasen i jenkinspipelinen, Checkout fasen, definieras på följande sätt:
stage('Checkout') {
git branch: GITBRANCH, url: GITREPOREMOTE
}
I det här steget ser du till att arbetskatalogen som Jenkins använder på din lokala utvecklingsdator har de senaste artefakterna från git-lagringsplatsen från tredje part. Normalt anger Jenkins den här arbetskatalogen till <your-user-home-directory>/.jenkins/workspace/<pipeline-name>. På så sätt kan du på samma lokala utvecklingsdator hålla din egen kopia av artefakter under utveckling separat från artefakterna som Jenkins använder från git-lagringsplatsen från tredje part.
Verifiera Databricks-tillgångspaketet
Den andra fasen i den här Jenkins-pipelinen Validate Bundle , fasen, definieras på följande sätt:
stage('Validate Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET}
"""
}
I det här steget ser du till att Databricks Asset Bundle, som definierar arbetsflödena för testning och körning av artefakter, är syntaktiskt korrekt. Databricks-tillgångspaket, som bara kallas paket, gör det möjligt att uttrycka fullständiga data-, analys- och ML-projekt som en samling källfiler. Se Vad är Databricks-tillgångspaket?.
Om du vill definiera paketet för den här artikeln skapar du en fil med namnet databricks.yml i roten på den klonade lagringsplatsen på den lokala datorn. I den här exempelfilen databricks.yml ersätter du följande platshållare:
- Ersätt
<bundle-name>med ett unikt programmatiskt namn för paketet. Det kan till exempel varajenkins-demo. - Ersätt
<job-prefix-name>med en sträng som hjälper dig att unikt identifiera de Azure Databricks-jobb som skapas på din arbetsyta för det här exemplet. Det kan till exempel varajenkins-demo. Det bör matchaJOBPREFIXvärdet i Jenkinsfile. - Ersätt
<spark-version-id>med Databricks Runtime-versions-ID:t för dina jobbkluster, till exempel13.3.x-scala2.12. - Ersätt
<cluster-node-type-id>med nodtyps-ID:t för dina jobbkluster, till exempelStandard_DS3_v2. - Observera att
devi mappningentargetsär samma somBUNDLETARGETi jenkinsfilen. Ett paketmål anger värden och de relaterade distributionsbeteendena.
Här är databricks.yml filen som måste läggas till i roten på lagringsplatsen för att det här exemplet ska fungera korrekt:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
data_security_mode: SINGLE_USER
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: '/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl'
evaluate-notebook-runs:
name: ${var.job_prefix}-evaluate-notebook-runs
tasks:
- task_key: ${var.job_prefix}-evaluate-notebook-runs-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
spark_python_task:
python_file: ./evaluate_notebook_runs.py
source: WORKSPACE
libraries:
- pypi:
package: unittest-xml-reporting
targets:
dev:
mode: development
Mer information om filen finns i databricks.yml Databricks Asset Bundle-konfiguration.
Distribuera paketet till din arbetsyta
Jenkins Pipelines tredje fas, med titeln Deploy Bundle, definieras på följande sätt:
stage('Deploy Bundle') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle deploy -t ${BUNDLETARGET}
"""
}
Det här steget gör två saker:
- Eftersom mappningen
artifactidatabricks.ymlfilen är inställdwhlpå instruerar detta Databricks CLI att skapa Python-hjulfilen med hjälp avsetup.pyfilen på den angivna platsen. - När Python-hjulfilen har byggts på din lokala utvecklingsdator distribuerar Databricks CLI den byggda Python-hjulfilen tillsammans med de angivna Python-filerna och notebook-filerna till din Azure Databricks-arbetsyta. Som standard distribuerar Databricks Asset Bundles Python-hjulfilen och andra filer till
/Workspace/Users/<your-username>/.bundle/<bundle-name>/<target-name>.
Skapa följande mappar och filer i roten på den klonade lagringsplatsen på den databricks.yml lokala datorn för att göra det möjligt att skapa Python-hjulfilen enligt vad som anges i filen.
Om du vill definiera logiken och enhetstesterna för Python-hjulfilen som notebook-filen ska köras mot skapar du två filer med namnet addcol.py och test_addcol.py, och lägger till dem i en mappstruktur med namnet python/dabdemo/dabdemo i lagringsplatsens Libraries mapp, visualiserad enligt följande (ellipser anger utelämnade mappar på lagringsplatsen, för korthet):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ └── dabdemo
│ ├── addcol.py
│ └── test_addcol.py
├── ...
Filen addcol.py innehåller en biblioteksfunktion som är inbyggd senare i en Python-hjulfil och sedan installeras på ett Azure Databricks-kluster. Det är en enkel funktion som lägger till en ny kolumn, ifylld med en literal, till en Apache Spark DataFrame:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Filen test_addcol.py innehåller tester för att skicka ett falskt DataFrame-objekt till with_status funktionen som definieras i addcol.py. Resultatet jämförs sedan med ett DataFrame-objekt som innehåller de förväntade värdena. Om värdena matchar, vilket de gör i det här fallet, godkänns testet:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Om du vill att Databricks CLI ska kunna paketera den här bibliotekskoden korrekt i en Python-hjulfil skapar du två filer med namnet __init__.py och __main__.py i samma mapp som de föregående två filerna. Skapa också en fil med namnet setup.py i python/dabdemo mappen, visualiserad enligt följande (ellipser anger utelämnade mappar, för korthet):
├── ...
├── Libraries
│ └── python
│ └── dabdemo
│ ├── dabdemo
│ │ ├── __init__.py
│ │ ├── __main__.py
│ │ ├── addcol.py
│ │ └── test_addcol.py
│ └── setup.py
├── ...
Filen __init__.py innehåller bibliotekets versionsnummer och författare. Ersätt <my-author-name> med ditt namn:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Filen __main__.py innehåller bibliotekets startpunkt:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Filen setup.py innehåller ytterligare inställningar för att skapa biblioteket i en Python-hjulfil. Ersätt <my-url>, <my-author-name>@<my-organization>och <my-package-description> med meningsfulla värden:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Testa Python-hjulets komponentlogik
Run Unit Tests Fasen, den fjärde fasen i den här Jenkins-pipelinen, använder pytest för att testa ett biblioteks logik för att se till att den fungerar som den är byggd. Den här fasen definieras på följande sätt:
stage('Run Unit Tests') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-unit-tests
"""
}
I den här fasen används Databricks CLI för att köra ett notebook-jobb. Det här jobbet kör Python-notebook-filen med filnamnet run-unit-test.py. Den här notebook-filen körs pytest mot bibliotekets logik.
Om du vill köra enhetstesterna för det här exemplet lägger du till en Python-notebook-fil med namnet run_unit_tests.py med följande innehåll i roten på den klonade lagringsplatsen på den lokala datorn:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Använda det byggda Python-hjulet
Den femte fasen i jenkinspipelinen, med titeln Run Notebook, kör en Python-notebook-fil som anropar logiken i den inbyggda Python-hjulfilen enligt följande:
stage('Run Notebook') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} run-dabdemo-notebook
"""
}
Den här fasen kör Databricks CLI, som i sin tur instruerar din arbetsyta att köra ett notebook-jobb. Den här notebook-filen skapar ett DataFrame-objekt, skickar det till bibliotekets with_status funktion, skriver ut resultatet och rapporterar jobbets körningsresultat. Skapa notebook-filen genom att lägga till en Python Notebook-fil med namnet dabdaddemo_notebook.py med följande innehåll i roten på den klonade lagringsplatsen på den lokala utvecklingsdatorn:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │first_name │last_name │email │status |
# +============+===========+=========================+=========+
# │paula │white │paula.white@example.com │checked |
# +------------+-----------+-------------------------+---------+
# │john │baer │john.baer@example.com │checked |
# +------------+-----------+-------------------------+---------+
Utvärdera körningsresultat för notebook-jobb
Evaluate Notebook Runs Fasen, den sjätte fasen i den här Jenkins-pipelinen, utvärderar resultatet av den föregående notebook-jobbkörningen. Den här fasen definieras på följande sätt:
stage('Evaluate Notebook Runs') {
sh """#!/bin/bash
${DBCLIPATH}/databricks bundle run -t ${BUNDLETARGET} evaluate-notebook-runs
"""
}
Den här fasen kör Databricks CLI, som i sin tur instruerar din arbetsyta att köra ett Python-filjobb. Den här Python-filen bestämmer fel- och framgångskriterierna för körningen av notebook-jobbet och rapporterar det här felet eller framgångsresultatet. Skapa en fil med namnet evaluate_notebook_runs.py med följande innehåll i roten på den klonade lagringsplatsen på den lokala utvecklingsdatorn:
import unittest
import xmlrunner
import json
import glob
import os
class TestJobOutput(unittest.TestCase):
test_output_path = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output"
def test_performance(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
duration = data['tasks'][0]['execution_duration']
if duration > 100000:
status = 'FAILED'
else:
status = 'SUCCESS'
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
def test_job_run(self):
path = self.test_output_path
statuses = []
for filename in glob.glob(os.path.join(path, '*.json')):
print('Evaluating: ' + filename)
with open(filename) as f:
data = json.load(f)
status = data['state']['result_state']
statuses.append(status)
f.close()
self.assertFalse('FAILED' in statuses)
if __name__ == '__main__':
unittest.main(
testRunner = xmlrunner.XMLTestRunner(
output = f"/Workspace${os.getenv('WORKSPACEBUNDLEPATH')}/Validation/Output/test-results",
),
failfast = False,
buffer = False,
catchbreak = False,
exit = False
)
Importera och rapportera testresultat
Det sjunde steget i den här Jenkins-pipelinen, med titeln Import Test Results, använder Databricks CLI för att skicka testresultaten från din arbetsyta till din lokala utvecklingsdator. Det åttonde och sista steget, med titeln Publish Test Results, publicerar testresultaten till Jenkins med hjälp av Jenkins-plugin-programmet junit . På så sätt kan du visualisera rapporter och instrumentpaneler relaterade till testresultatens status. Dessa steg definieras på följande sätt:
stage('Import Test Results') {
def DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH
def getPath = "${DBCLIPATH}/databricks bundle validate -t ${BUNDLETARGET} | ${JQPATH}/jq -r .workspace.file_path"
def output = sh(script: getPath, returnStdout: true).trim()
if (output) {
DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH = "${output}"
} else {
error "Failed to capture output or command execution failed: ${getPath}"
}
sh """#!/bin/bash
${DBCLIPATH}/databricks workspace export-dir \
${DATABRICKS_BUNDLE_WORKSPACE_FILE_PATH}/Validation/Output/test-results \
${WORKSPACE}/Validation/Output/test-results \
--overwrite
"""
}
stage('Publish Test Results') {
junit allowEmptyResults: true, testResults: '**/test-results/*.xml', skipPublishingChecks: true
}
Skicka alla kodändringar till lagringsplatsen från tredje part
Nu bör du skicka innehållet i den klonade lagringsplatsen på den lokala utvecklingsdatorn till lagringsplatsen från tredje part. Innan du push-överför bör du först lägga till .gitignore följande poster i filen i den klonade lagringsplatsen, eftersom du förmodligen inte bör skicka interna Databricks Asset Bundle-arbetsfiler, valideringsrapporter, Python-byggfiler och Python-cacheminnen till lagringsplatsen från tredje part. Vanligtvis vill du återskapa nya valideringsrapporter och de senaste Python-hjulbyggena på din Azure Databricks-arbetsyta i stället för att använda potentiellt inaktuella valideringsrapporter och Python-hjulversioner:
.databricks/
.vscode/
Libraries/python/dabdemo/build/
Libraries/python/dabdemo/__pycache__/
Libraries/python/dabdemo/dabdemo.egg-info/
Validation/
Kör Jenkins-pipelinen
Nu är du redo att köra Jenkins-pipelinen manuellt. Så här gör du från Jenkins-instrumentpanelen:
- Klicka på namnet på jenkins-pipelinen.
- Klicka på Skapa nu i sidopanelen.
- Om du vill se resultatet klickar du på den senaste pipelinekörningen (till exempel
#1) och klickar sedan på Konsolutdata.
Nu har CI/CD-pipelinen slutfört en integrerings- och distributionscykel. Genom att automatisera den här processen kan du se till att koden har testats och distribuerats av en effektiv, konsekvent och repeterbar process. Information om hur du instruerar git-providern från tredje part att köra Jenkins varje gång en viss händelse inträffar, till exempel en pull-begäran för lagringsplats, finns i dokumentationen för git-providern från tredje part.