Kontinuerlig integration och leverans i Azure Databricks med Azure DevOps
Kommentar
Den här artikeln beskriver Azure DevOps, som har utvecklats av en tredje part. Information om hur du kontaktar leverantören finns i Support för Azure DevOps Services.
Den här artikeln vägleder dig genom att konfigurera Azure DevOps-automatisering för din kod och artefakter som fungerar med Azure Databricks. Mer specifikt konfigurerar du ett CI/CD-arbetsflöde (kontinuerlig integrering och leverans) för att ansluta till en Git-lagringsplats, köra jobb med Hjälp av Azure Pipelines för att skapa och enhetstesta ett Python-hjul (*.whl) och distribuera det för användning i Databricks-notebook-filer.
CI/CD-utvecklingsarbetsflöde
Databricks föreslår följande arbetsflöde för CI/CD-utveckling med Azure DevOps:
- Skapa en lagringsplats eller använd en befintlig lagringsplats med git-providern från tredje part.
- Anslut din lokala utvecklingsdator till samma lagringsplats från tredje part. Anvisningar finns i dokumentationen för git-providern från tredje part.
- Hämta eventuella befintliga uppdaterade artefakter (till exempel notebook-filer, kodfiler och byggskript) till din lokala utvecklingsdator från lagringsplatsen från tredje part.
- Vid behov skapar, uppdaterar och testar du artefakter på den lokala utvecklingsdatorn. Skicka sedan nya och ändrade artefakter från din lokala utvecklingsdator till lagringsplatsen från tredje part. Anvisningar finns i dokumentationen för git-providern från tredje part.
- Upprepa steg 3 och 4 efter behov.
- Använd Azure DevOps regelbundet som en integrerad metod för att automatiskt hämta artefakter från lagringsplatsen från tredje part, skapa, testa och köra kod på din Azure Databricks-arbetsyta och rapportera test- och körningsresultat. Du kan köra Azure DevOps manuellt, men i verkliga implementeringar instruerar du din Git-leverantör från tredje part att köra Azure DevOps varje gång en specifik händelse inträffar, till exempel en pull-begäran för lagringsplats.
Det finns många CI/CD-verktyg som du kan använda för att hantera och köra din pipeline. Den här artikeln visar hur du använder Azure DevOps. CI/CD är ett designmönster, så de steg och steg som beskrivs i den här artikelns exempel bör överföras med några ändringar i pipelinedefinitionsspråket i varje verktyg. Dessutom är mycket av koden i den här exempelpipelinen standard-Python-kod som kan anropas i andra verktyg.
Dricks
Information om hur du använder Jenkins med Azure Databricks i stället för Azure DevOps finns i CI/CD med Jenkins på Azure Databricks.
Resten av den här artikeln beskriver ett par exempelpipelines i Azure DevOps som du kan anpassa efter dina egna behov för Azure Databricks.
Om exemplet
I den här artikelns exempel används två pipelines för att samla in, distribuera och köra exempel på Python-kod och Python-notebook-filer som lagras på en fjärransluten Git-lagringsplats.
Den första pipelinen, som kallas byggpipeline , förbereder byggartefakter för den andra pipelinen, som kallas versionspipeline . Genom att separera bygg-pipelinen från versionspipelinen kan du skapa en byggartefakt utan att distribuera den eller samtidigt distribuera artefakter från flera versioner. Så här konstruerar du bygg- och versionspipelines:
- Skapa en virtuell Azure-dator för bygg-pipelinen.
- Kopiera filerna från git-lagringsplatsen till den virtuella datorn.
- Skapa en gzip'ed tar-fil som innehåller Python-koden, Python-notebook-filer och relaterade filer för att skapa, distribuera och köra inställningar.
- Kopiera filen gzip'ed tar som en zip-fil till en plats där versionspipelinen kan komma åt den.
- Skapa en annan virtuell Azure-dator för versionspipelinen.
- Hämta zip-filen från byggpipelinens plats och packa sedan upp zip-filen för att hämta Python-koden, Python-notebook-filer och relaterade filer för att skapa, distribuera och köra inställningar.
- Distribuera Python-koden, Python-notebook-filer och relaterade filer för att skapa, distribuera och köra inställningar till din fjärranslutna Azure Databricks-arbetsyta.
- Skapa Python-hjulbibliotekets komponentkodfiler i en Python-hjulfil.
- Kör enhetstester på komponentkoden för att kontrollera logiken i Python-hjulfilen.
- Kör Python-notebook-filerna, varav en anropar Python-hjulfilens funktioner.
Om Databricks CLI
Den här artikelns exempel visar hur du använder Databricks CLI i ett icke-interaktivt läge i en pipeline. Den här artikelns exempelpipeline distribuerar kod, skapar ett bibliotek och kör notebook-filer på din Azure Databricks-arbetsyta.
Om du använder Databricks CLI i pipelinen utan att implementera exempelkoden, biblioteket och notebook-filerna från den här artikeln följer du dessa steg:
Förbered din Azure Databricks-arbetsyta för att använda OAuth-M2M-autentisering (machine-to-machine) för autentisering av tjänstens huvudnamn. Innan du börjar kontrollerar du att du har ett Microsoft Entra ID-tjänsthuvudnamn med en Azure Databricks OAuth-hemlighet. Se Auktorisera obevakad åtkomst till Azure Databricks-resurser med en tjänstehuvudman via OAuth.
Installera Databricks CLI i din pipeline. Det gör du genom att lägga till en Bash Script-uppgift i din pipeline som kör följande skript:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | shInformation om hur du lägger till en Bash Script-uppgift i din pipeline finns i Steg 3.6. Installera Verktygen för att skapa Databricks CLI- och Python-hjul.
Konfigurera pipelinen så att det installerade Databricks CLI kan autentisera tjänstens huvudnamn med din arbetsyta. Det gör du genom att läsa Steg 3.1: Definiera miljövariabler för versionspipelinen.
Lägg till fler Bash Script-uppgifter i pipelinen efter behov för att köra dina Databricks CLI-kommandon. Se Databricks CLI-kommandon.
Innan du börjar
Om du vill använda den här artikelns exempel måste du ha:
- Ett befintligt Azure DevOps-projekt . Om du ännu inte har ett projekt skapar du ett projekt i Azure DevOps.
- En befintlig lagringsplats med en Git-provider som Azure DevOps stöder. Du lägger till Python-exempelkoden, python-notebook-filen och relaterade versionsinställningar till den här lagringsplatsen. Om du ännu inte har en lagringsplats skapar du en genom att följa Git-providerns instruktioner. Anslut sedan ditt Azure DevOps-projekt till den här lagringsplatsen om du inte redan har gjort det. Anvisningar finns i länkarna i källlagringsplatser som stöds.
- I den här artikelns exempel används OAuth-M2M-autentisering (machine-to-machine) för att autentisera ett Microsoft Entra ID-tjänsthuvudnamn till en Azure Databricks-arbetsyta. Du måste ha ett Microsoft Entra ID-tjänsthuvudnamn med en Azure Databricks OAuth-hemlighet för tjänstens huvudnamn. Se Auktorisera obevakad åtkomst till Azure Databricks-resurser med ett tjänsthuvudnamn och OAuth.
Steg 1: Lägg till exemplets filer på lagringsplatsen
I det här steget går du till lagringsplatsen med git-providern från tredje part och lägger till alla exempelfiler i den här artikeln som dina Azure DevOps-pipelines skapar, distribuerar och kör på din fjärranslutna Azure Databricks-arbetsyta.
Steg 1.1: Lägg till Python-hjulkomponentfilerna
I den här artikelns exempel skapar och testar dina Azure DevOps-pipelines en Python-hjulfil. En Azure Databricks-notebook-fil anropar sedan den skapade Python-hjulfilens funktioner.
Om du vill definiera logik- och enhetstesterna för Python-hjulfilen som notebook-filerna körs mot skapar du i roten på lagringsplatsen två filer med namnet addcol.py och test_addcol.py, och lägger till dem i en mappstruktur med namnet python/dabdemo/dabdemo i en Libraries mapp, visualiserad på följande sätt:
└── Libraries
└── python
└── dabdemo
└── dabdemo
├── addcol.py
└── test_addcol.py
Filen addcol.py innehåller en biblioteksfunktion som är inbyggd senare i en Python-hjulfil och sedan installeras i Azure Databricks-kluster. Det är en enkel funktion som lägger till en ny kolumn, ifylld med en literal, till en Apache Spark DataFrame:
# Filename: addcol.py
import pyspark.sql.functions as F
def with_status(df):
return df.withColumn("status", F.lit("checked"))
Filen test_addcol.py innehåller tester för att skicka ett falskt DataFrame-objekt till with_status funktionen som definieras i addcol.py. Resultatet jämförs sedan med ett DataFrame-objekt som innehåller de förväntade värdena. Om värdena matchar godkänns testet:
# Filename: test_addcol.py
import pytest
from pyspark.sql import SparkSession
from dabdemo.addcol import *
class TestAppendCol(object):
def test_with_status(self):
spark = SparkSession.builder.getOrCreate()
source_data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
source_df = spark.createDataFrame(
source_data,
["first_name", "last_name", "email"]
)
actual_df = with_status(source_df)
expected_data = [
("paula", "white", "paula.white@example.com", "checked"),
("john", "baer", "john.baer@example.com", "checked")
]
expected_df = spark.createDataFrame(
expected_data,
["first_name", "last_name", "email", "status"]
)
assert(expected_df.collect() == actual_df.collect())
Om du vill att Databricks CLI ska kunna paketera den här bibliotekskoden korrekt i en Python-hjulfil skapar du två filer med namnet __init__.py och __main__.py i samma mapp som de föregående två filerna. Skapa också en fil med namnet setup.py i python/dabdemo mappen, visualiserad på följande sätt:
└── Libraries
└── python
└── dabdemo
├── dabdemo
│ ├── __init__.py
│ ├── __main__.py
│ ├── addcol.py
│ └── test_addcol.py
└── setup.py
Filen __init__.py innehåller bibliotekets versionsnummer och författare. Ersätt <my-author-name> med ditt namn:
# Filename: __init__.py
__version__ = '0.0.1'
__author__ = '<my-author-name>'
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
Filen __main__.py innehåller bibliotekets startpunkt:
# Filename: __main__.py
import sys, os
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from addcol import *
def main():
pass
if __name__ == "__main__":
main()
Filen setup.py innehåller ytterligare inställningar för att skapa biblioteket i en Python-hjulfil. Ersätt <my-url>, <my-author-name>@<my-organization>och <my-package-description> med giltiga värden:
# Filename: setup.py
from setuptools import setup, find_packages
import dabdemo
setup(
name = "dabdemo",
version = dabdemo.__version__,
author = dabdemo.__author__,
url = "https://<my-url>",
author_email = "<my-author-name>@<my-organization>",
description = "<my-package-description>",
packages = find_packages(include = ["dabdemo"]),
entry_points={"group_1": "run=dabdemo.__main__:main"},
install_requires = ["setuptools"]
)
Steg 1.2: Lägg till en enhetstestningsanteckningsbok för Python-hjulfilen
Senare kör Databricks CLI ett notebook-jobb. Det här jobbet kör en Python-anteckningsbok med filnamnet run_unit_tests.py. Den här notebook-filen körs pytest mot Python-hjulbibliotekets logik.
Om du vill köra enhetstesterna för den här artikelns exempel lägger du till i roten på lagringsplatsen en notebook-fil med namnet run_unit_tests.py med följande innehåll:
# Databricks notebook source
# COMMAND ----------
# MAGIC %sh
# MAGIC
# MAGIC mkdir -p "/Workspace${WORKSPACEBUNDLEPATH}/Validation/reports/junit/test-reports"
# COMMAND ----------
# Prepare to run pytest.
import sys, pytest, os
# Skip writing pyc files on a readonly filesystem.
sys.dont_write_bytecode = True
# Run pytest.
retcode = pytest.main(["--junit-xml", f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/Validation/reports/junit/test-reports/TEST-libout.xml",
f"/Workspace{os.getenv('WORKSPACEBUNDLEPATH')}/files/Libraries/python/dabdemo/dabdemo/"])
# Fail the cell execution if there are any test failures.
assert retcode == 0, "The pytest invocation failed. See the log for details."
Steg 1.3: Lägg till en notebook-fil som anropar Python-hjulfilen
Senare kör Databricks CLI ett annat notebook-jobb. Den här notebook-filen skapar ett DataFrame-objekt, skickar det till Python-hjulbibliotekets with_status funktion, skriver ut resultatet och rapporterar jobbets körningsresultat. Skapa roten för lagringsplatsen med en notebook-fil med namnet dabdemo_notebook.py med följande innehåll:
# Databricks notebook source
# COMMAND ----------
# Restart Python after installing the Python wheel.
dbutils.library.restartPython()
# COMMAND ----------
from dabdemo.addcol import with_status
df = (spark.createDataFrame(
schema = ["first_name", "last_name", "email"],
data = [
("paula", "white", "paula.white@example.com"),
("john", "baer", "john.baer@example.com")
]
))
new_df = with_status(df)
display(new_df)
# Expected output:
#
# +------------+-----------+-------------------------+---------+
# │ first_name │ last_name │ email │ status │
# +============+===========+=========================+=========+
# │ paula │ white │ paula.white@example.com │ checked │
# +------------+-----------+-------------------------+---------+
# │ john │ baer │ john.baer@example.com │ checked │
# +------------+-----------+-------------------------+---------+
Steg 1.4: Skapa paketkonfigurationen
I den här artikelns exempel används Databricks-tillgångspaket för att definiera inställningar och beteenden för att skapa, distribuera och köra Python-hjulfilen, de två notebook-filerna och Python-kodfilen. Databricks-tillgångspaket, som bara kallas paket, gör det möjligt att uttrycka fullständiga data-, analys- och ML-projekt som en samling källfiler. Se Vad är Databricks-tillgångspaket?.
Om du vill konfigurera paketet för den här artikelns exempel skapar du i roten på lagringsplatsen en fil med namnet databricks.yml. I den här exempelfilen databricks.yml ersätter du följande platshållare:
- Ersätt
<bundle-name>med ett unikt programmatiskt namn för paketet. Exempel:azure-devops-demo - Ersätt
<job-prefix-name>med en sträng som hjälper dig att unikt identifiera jobben som skapas på din Azure Databricks-arbetsyta för det här exemplet. Exempel:azure-devops-demo - Ersätt
<spark-version-id>med Databricks Runtime-versions-ID:t för dina jobbkluster, till exempel13.3.x-scala2.12. - Ersätt
<cluster-node-type-id>med klusternodens typ-ID för dina jobbkluster, till exempelStandard_DS3_v2. - Observera att
devi mappningentargetsanges värden och de relaterade distributionsbeteendena. I verkliga implementeringar kan du ge det här målet ett annat namn i dina egna paket.
Här är innehållet i det här exemplets databricks.yml fil:
# Filename: databricks.yml
bundle:
name: <bundle-name>
variables:
job_prefix:
description: A unifying prefix for this bundle's job and task names.
default: <job-prefix-name>
spark_version:
description: The cluster's Spark version ID.
default: <spark-version-id>
node_type_id:
description: The cluster's node type ID.
default: <cluster-node-type-id>
artifacts:
dabdemo-wheel:
type: whl
path: ./Libraries/python/dabdemo
resources:
jobs:
run-unit-tests:
name: ${var.job_prefix}-run-unit-tests
tasks:
- task_key: ${var.job_prefix}-run-unit-tests-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./run_unit_tests.py
source: WORKSPACE
libraries:
- pypi:
package: pytest
run-dabdemo-notebook:
name: ${var.job_prefix}-run-dabdemo-notebook
tasks:
- task_key: ${var.job_prefix}-run-dabdemo-notebook-task
new_cluster:
spark_version: ${var.spark_version}
node_type_id: ${var.node_type_id}
num_workers: 1
spark_env_vars:
WORKSPACEBUNDLEPATH: ${workspace.root_path}
notebook_task:
notebook_path: ./dabdemo_notebook.py
source: WORKSPACE
libraries:
- whl: "/Workspace${workspace.root_path}/files/Libraries/python/dabdemo/dist/dabdemo-0.0.1-py3-none-any.whl"
targets:
dev:
mode: development
Mer information om filens syntax finns i databricks.ymlDatabricks Asset Bundle-konfiguration.
Steg 2: Definiera bygg-pipelinen
Azure DevOps tillhandahåller ett molnbaserat användargränssnitt för att definiera faserna i din CI/CD-pipeline med YAML. Mer information om Azure DevOps och pipelines finns i Azure DevOps-dokumentationen.
I det här steget använder du YAML-markering för att definiera bygg-pipelinen, som skapar en distributionsartefakt. Om du vill distribuera koden till en Azure Databricks-arbetsyta anger du pipelinens byggartefakt som indata till en versionspipeline. Du definierar den här versionspipelinen senare.
För att köra byggpipelines tillhandahåller Azure DevOps molnbaserade körningsagenter på begäran som stöder distributioner till Kubernetes, virtuella datorer, Azure Functions, Azure Web Apps och många fler mål. I det här exemplet använder du en agent på begäran för att automatisera skapandet av distributionsartefakten.
Definiera den här artikelns exempel på bygg-pipeline enligt följande:
Logga in på Azure DevOps och klicka sedan på länken Logga in för att öppna ditt Azure DevOps-projekt.
Kommentar
Om Azure Portal visas i stället för ditt Azure DevOps-projekt klickar du på Fler tjänster > Azure DevOps-organisationer > Mina Azure DevOps-organisationer och öppnar sedan ditt Azure DevOps-projekt.
Klicka på Pipelines i sidofältet och klicka sedan på Pipelines på menyn Pipelines.
Klicka på knappen Ny pipeline och följ anvisningarna på skärmen. (Om du redan har pipelines klickar du på Skapa pipeline i stället.) I slutet av dessa instruktioner öppnas pipelineredigeraren. Här definierar du bygg-pipelineskriptet
azure-pipelines.ymli filen som visas. Om pipelineredigeraren inte visas i slutet av anvisningarna väljer du bygg-pipelinens namn och klickar sedan på Redigera.Du kan använda Git-grenväljaren
 för att anpassa byggprocessen för varje gren i Git-lagringsplatsen. Det är en CI/CD-metod att inte göra produktion direkt i lagringsplatsens
för att anpassa byggprocessen för varje gren i Git-lagringsplatsen. Det är en CI/CD-metod att inte göra produktion direkt i lagringsplatsens maingren. Det här exemplet förutsätter att en gren med namnetreleasefinns på lagringsplatsen som ska användas i ställetmainför .
Skriptet
azure-pipelines.ymlför bygg-pipeline lagras som standard i roten på den fjärranslutna Git-lagringsplats som du associerar med pipelinen.Skriv över pipelinens
azure-pipelines.ymlfils startinnehåll med följande definition och klicka sedan på Spara.# Specify the trigger event to start the build pipeline. # In this case, new code merged into the release branch initiates a new build. trigger: - release # Specify the operating system for the agent that runs on the Azure virtual # machine for the build pipeline (known as the build agent). The virtual # machine image in this example uses the Ubuntu 22.04 virtual machine # image in the Azure Pipeline agent pool. See # https://learn.microsoft.com/azure/devops/pipelines/agents/hosted#software pool: vmImage: ubuntu-22.04 # Download the files from the designated branch in the remote Git repository # onto the build agent. steps: - checkout: self persistCredentials: true clean: true # Generate the deployment artifact. To do this, the build agent gathers # all the new or updated code to be given to the release pipeline, # including the sample Python code, the Python notebooks, # the Python wheel library component files, and the related Databricks asset # bundle settings. # Use git diff to flag files that were added in the most recent Git merge. # Then add the files to be used by the release pipeline. # The implementation in your pipeline will likely be different. # The objective here is to add all files intended for the current release. - script: | git diff --name-only --diff-filter=AMR HEAD^1 HEAD | xargs -I '{}' cp --parents -r '{}' $(Build.BinariesDirectory) mkdir -p $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/dabdemo/*.* $(Build.BinariesDirectory)/Libraries/python/dabdemo/dabdemo cp $(Build.Repository.LocalPath)/Libraries/python/dabdemo/setup.py $(Build.BinariesDirectory)/Libraries/python/dabdemo cp $(Build.Repository.LocalPath)/*.* $(Build.BinariesDirectory) displayName: 'Get Changes' # Create the deployment artifact and then publish it to the # artifact repository. - task: ArchiveFiles@2 inputs: rootFolderOrFile: '$(Build.BinariesDirectory)' includeRootFolder: false archiveType: 'zip' archiveFile: '$(Build.ArtifactStagingDirectory)/$(Build.BuildId).zip' replaceExistingArchive: true - task: PublishBuildArtifacts@1 inputs: ArtifactName: 'DatabricksBuild'
Steg 3: Definiera versionspipelinen
Versionspipelinen distribuerar byggartefakterna från bygg-pipelinen till en Azure Databricks-miljö. Genom att separera versionspipelinen i det här steget från bygg-pipelinen i föregående steg kan du skapa en version utan att distribuera den eller distribuera artefakter från flera versioner samtidigt.
I ditt Azure DevOps-projekt går du till menyn Pipelines i sidofältet och klickar på Versioner.
Klicka på Ny > ny versionspipeline. (Om du redan har pipelines klickar du på Ny pipeline i stället.)
På sidan av skärmen finns en lista över aktuella mallar för vanliga distributionsmönster. I det här exemplet på versionspipelinen klickar du på
 .
.
I rutan AddArtefakter på sidan av skärmen klickar du på . I fönstret Lägg till en artefakt för Källa (bygg-pipeline) väljer du den byggpipeline som du skapade tidigare. Klicka sedan på Lägg till.
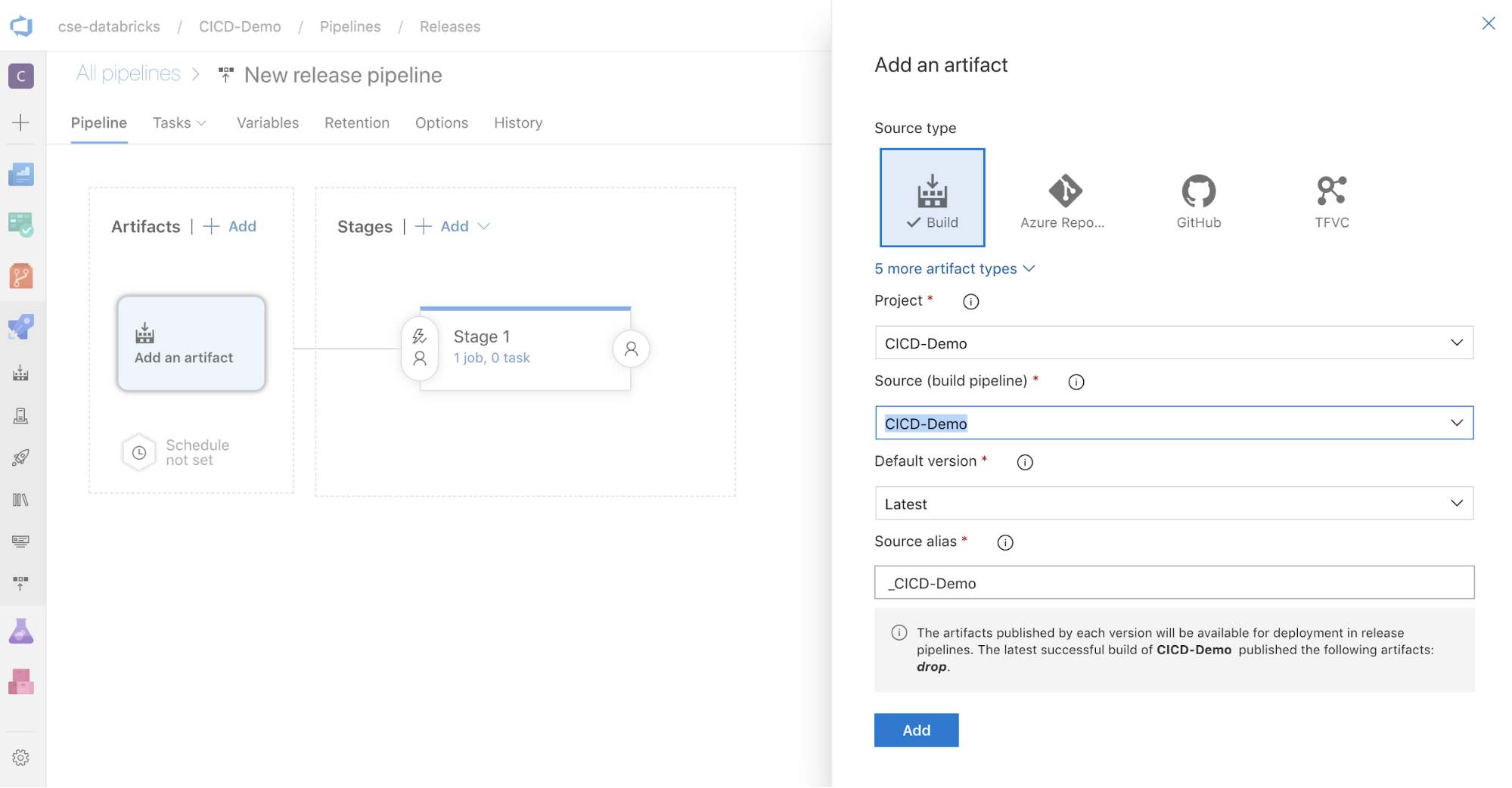
Du kan konfigurera hur pipelinen utlöses genom att
 klicka för att visa utlösande alternativ på sidan av skärmen. Om du vill att en version ska initieras automatiskt baserat på tillgänglighet för byggartefakter eller efter ett arbetsflöde för pull-begäran aktiverar du lämplig utlösare. I det här exemplet i det sista steget i den här artikeln utlöser du bygg-pipelinen manuellt och sedan versionspipelinen.
klicka för att visa utlösande alternativ på sidan av skärmen. Om du vill att en version ska initieras automatiskt baserat på tillgänglighet för byggartefakter eller efter ett arbetsflöde för pull-begäran aktiverar du lämplig utlösare. I det här exemplet i det sista steget i den här artikeln utlöser du bygg-pipelinen manuellt och sedan versionspipelinen.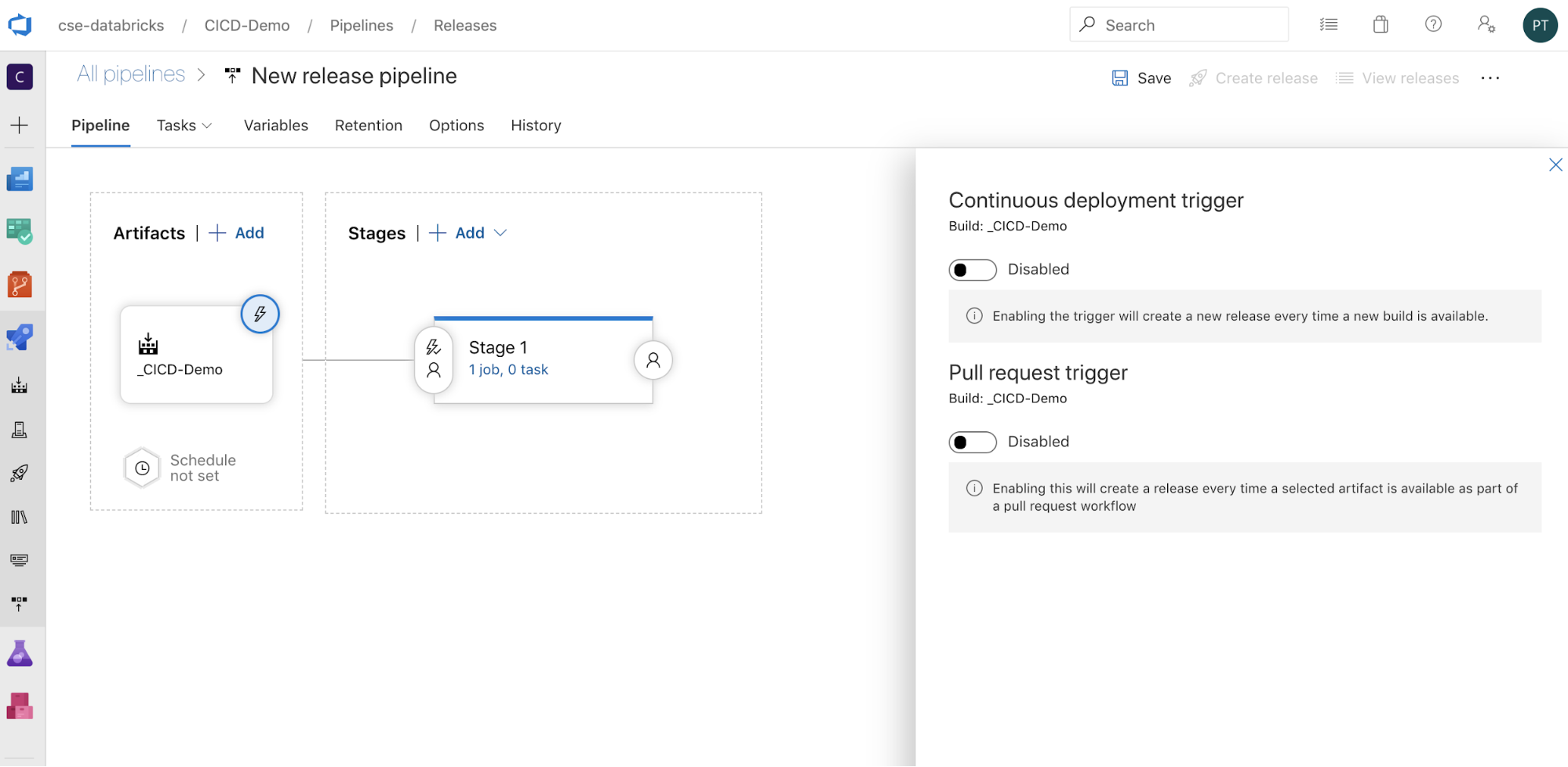
Klicka på Spara > OK.
Steg 3.1: Definiera miljövariabler för versionspipelinen
Det här exemplets versionspipeline förlitar sig på följande miljövariabler, som du kan lägga till genom att klicka på Lägg till i avsnittet Pipelinevariabler på fliken Variabler med omfånget Steg 1:
-
BUNDLE_TARGET, som ska matchatargetnamnet idatabricks.ymlfilen. I den här artikelns exempel ärdevdetta . -
DATABRICKS_HOST, som representerar URL:en per arbetsyta för din Azure Databricks-arbetsyta, som börjar medhttps://, till exempelhttps://adb-<workspace-id>.<random-number>.azuredatabricks.net. Ta inte med efterföljande/efter.net. -
DATABRICKS_CLIENT_ID, som representerar program-ID för Tjänstens huvudnamn för Microsoft Entra-ID. -
DATABRICKS_CLIENT_SECRET, som representerar Azure Databricks OAuth-hemligheten för Tjänstens huvudnamn för Microsoft Entra ID.
Steg 3.2: Konfigurera versionsagenten för versionspipelinen
Klicka på länken 1 jobb, 0 aktivitet i objektet Steg 1.
På fliken Uppgifter klickar du på Agentjobb.
I avsnittet Agentval för Agentpool väljer du Azure Pipelines.
För Agentspecifikation väljer du samma agent som du angav för byggagenten tidigare, i det här exemplet ubuntu-22.04.
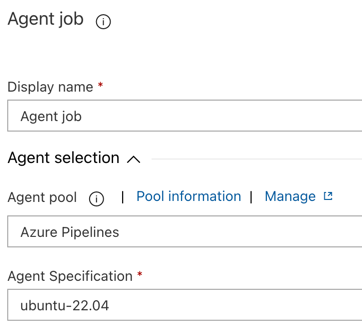
Klicka på Spara > OK.
Steg 3.3: Ange Python-versionen för versionsagenten
Klicka på plustecknet i avsnittet Agentjobb , som visas med den röda pilen i följande bild. En sökbar lista över tillgängliga aktiviteter visas. Det finns också en Marketplace-flik för plugin-program från tredje part som kan användas för att komplettera standarduppgifterna för Azure DevOps. Du kommer att lägga till flera uppgifter i versionsagenten under de kommande stegen.
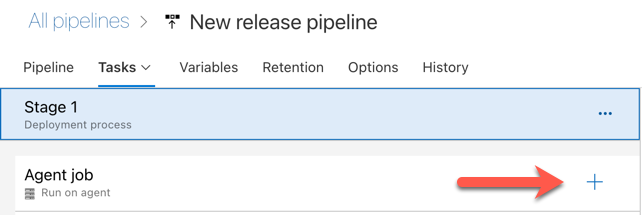
Den första uppgiften du lägger till är Använd Python-version, som finns på fliken Verktyg. Om du inte hittar den här uppgiften använder du sökrutan för att leta efter den. När du hittar den väljer du den och klickar sedan på knappen Lägg till bredvid uppgiften Använd Python-version .
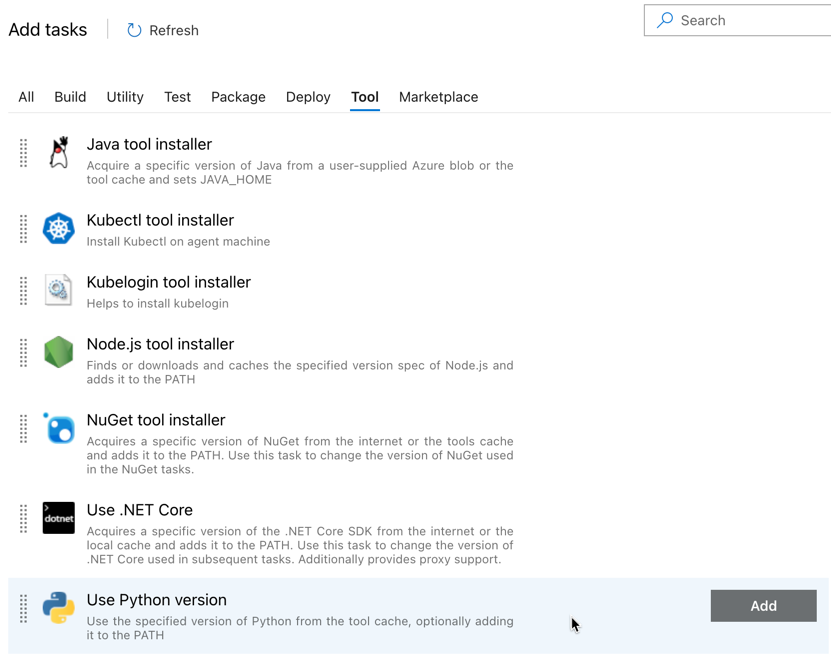
Precis som med bygg-pipelinen vill du se till att Python-versionen är kompatibel med skripten som anropas i efterföljande uppgifter. I det här fallet klickar du på aktiviteten Använd Python 3.x bredvid Agentjobb och anger sedan Versionsspecifikation till
3.10. Ange även Visningsnamn tillUse Python 3.10. Den här pipelinen förutsätter att du använder Databricks Runtime 13.3 LTS i klustren, som har Python 3.10.12 installerat.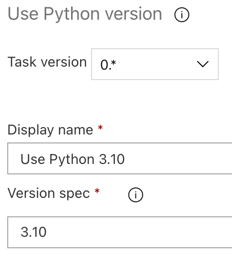
Klicka på Spara > OK.
Steg 3.4: Packa upp byggartefakten från bygg-pipelinen
Låt sedan versionsagenten extrahera Python-hjulfilen, relaterade versionsinställningar, notebook-filerna och Python-kodfilen från zip-filen med hjälp av aktiviteten Extrahera filer : klicka på plustecknet i avsnittet Agentjobb , välj aktiviteten Extrahera filer på fliken Verktyg och klicka sedan på Lägg till.
Klicka på aktiviteten Extrahera filer bredvid Agentjobb, ange Arkivfilmönster till
**/*.zipoch ange målmappen till systemvariabeln$(Release.PrimaryArtifactSourceAlias)/Databricks. Ange även Visningsnamn tillExtract build pipeline artifact.Kommentar
$(Release.PrimaryArtifactSourceAlias)representerar ett Azure DevOps-genererat alias för att identifiera den primära platsen för artefaktkällan i versionsagenten, till exempel_<your-github-alias>.<your-github-repo-name>. Versionspipelinen anger det här värdet som miljövariabel iRELEASE_PRIMARYARTIFACTSOURCEALIASfasen Initiera jobb för versionsagenten. Se variabler för klassisk version och artefakter.Ange Visningsnamn till
Extract build pipeline artifact.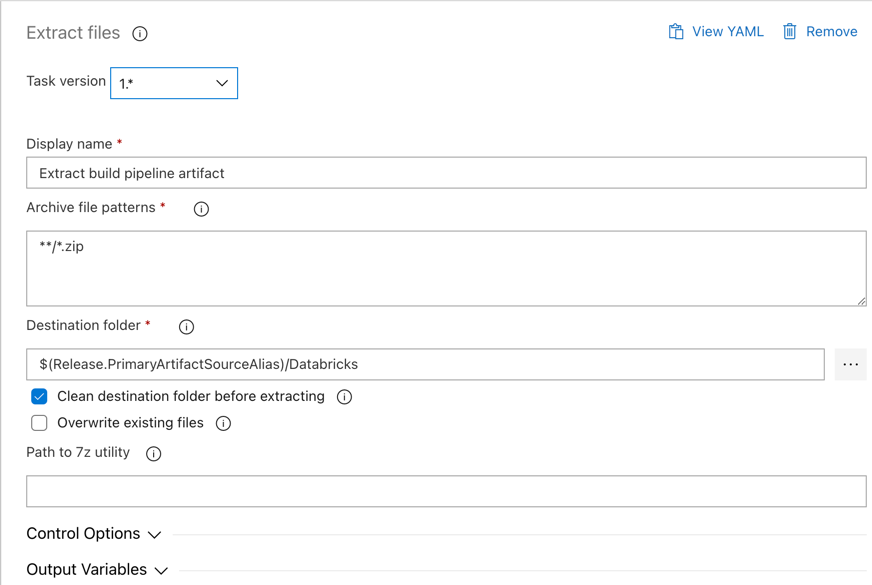
Klicka på Spara > OK.
Steg 3.5: Ange miljövariabeln BUNDLE_ROOT
För att den här artikelns exempel ska fungera som förväntat måste du ange en miljövariabel med namnet BUNDLE_ROOT i versionspipelinen. Databricks Asset Bundles använder den här miljövariabeln för att avgöra var databricks.yml filen finns. Så här anger du den här miljövariabeln:
Använd aktiviteten Miljövariabler: klicka på plustecknet igen i avsnittet Agentjobb, välj aktiviteten Miljövariabler på fliken Verktyg och klicka sedan på Lägg till.
Kommentar
Om aktiviteten Miljövariabler inte visas på fliken Verktyg anger du
Environment Variablesi sökrutan och följer anvisningarna på skärmen för att lägga till uppgiften på fliken Verktyg. Detta kan kräva att du lämnar Azure DevOps och sedan kommer tillbaka till den här platsen där du slutade.För Miljövariabler (kommaavgränsade) anger du följande definition:
BUNDLE_ROOT=$(Agent.ReleaseDirectory)/$(Release.PrimaryArtifactSourceAlias)/Databricks.Kommentar
$(Agent.ReleaseDirectory)representerar ett Azure DevOps-genererat alias för att identifiera platsen för versionskatalogen på versionsagenten, till exempel/home/vsts/work/r1/a. Versionspipelinen anger det här värdet som miljövariabel iAGENT_RELEASEDIRECTORYfasen Initiera jobb för versionsagenten. Se variabler för klassisk version och artefakter. Mer information om$(Release.PrimaryArtifactSourceAlias)finns i anteckningen i föregående steg.Ange Visningsnamn till
Set BUNDLE_ROOT environment variable.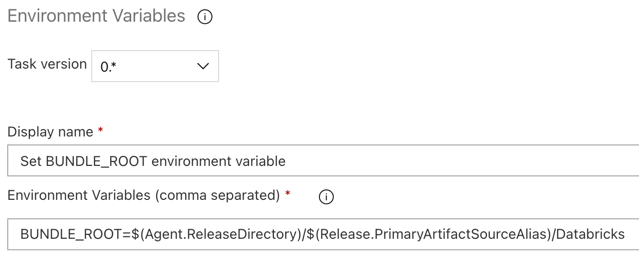
Klicka på Spara > OK.
Steg 3.6. Installera Verktyg för att bygga Databricks CLI- och Python-hjul
Installera sedan verktygen Databricks CLI och Python Wheel Build på versionsagenten. Versionsagenten anropar Verktygen för att skapa Databricks CLI- och Python-hjul i de närmaste uppgifterna. Det gör du genom att använda Bash-aktiviteten : klicka på plustecknet igen i avsnittet Agentjobb , välj Bash-aktiviteten på fliken Verktyg och klicka sedan på Lägg till.
Klicka på bash-skriptaktiviteten bredvid Agentjobb.
För Typ väljer du Infogat.
Ersätt innehållet i Script med följande kommando, som installerar verktygen Databricks CLI och Python Wheel Build:
curl -fsSL https://raw.githubusercontent.com/databricks/setup-cli/main/install.sh | sh pip install wheelAnge Visningsnamn till
Install Databricks CLI and Python wheel build tools.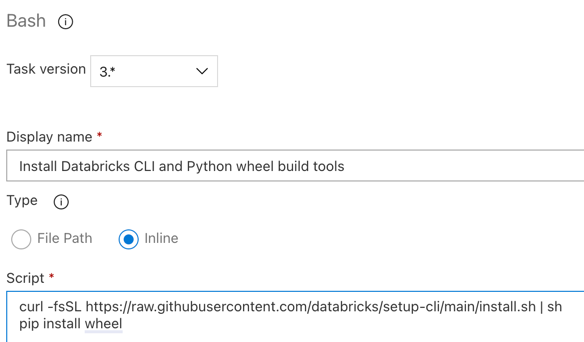
Klicka på Spara > OK.
Steg 3.7: Verifiera Databricks-tillgångspaketet
I det här steget ser du till att databricks.yml filen är syntaktiskt korrekt.
Använd Bash-aktiviteten: klicka på plustecknet igen i avsnittet Agentjobb, välj Bash-aktiviteten på fliken Verktyg och klicka sedan på Lägg till.
Klicka på bash-skriptaktiviteten bredvid Agentjobb.
För Typ väljer du Infogat.
Ersätt innehållet i Script med följande kommando, som använder Databricks CLI för att kontrollera om
databricks.ymlfilen är syntaktiskt korrekt:databricks bundle validate -t $(BUNDLE_TARGET)Ange Visningsnamn till
Validate bundle.Klicka på Spara > OK.
Steg 3.8: Distribuera paketet
I det här steget skapar du Python-hjulfilen och distribuerar den byggda Python-hjulfilen, de två Python-notebook-filerna och Python-filen från versionspipelinen till din Azure Databricks-arbetsyta.
Använd Bash-aktiviteten: klicka på plustecknet igen i avsnittet Agentjobb, välj Bash-aktiviteten på fliken Verktyg och klicka sedan på Lägg till.
Klicka på bash-skriptaktiviteten bredvid Agentjobb.
För Typ väljer du Infogat.
Ersätt innehållet i Script med följande kommando, som använder Databricks CLI för att skapa Python-hjulfilen och distribuera den här artikelns exempelfiler från versionspipelinen till din Azure Databricks-arbetsyta:
databricks bundle deploy -t $(BUNDLE_TARGET)Ange Visningsnamn till
Deploy bundle.Klicka på Spara > OK.
Steg 3.9: Kör enhetstestanteckningsboken för Python-hjulet
I det här steget kör du ett jobb som kör enhetstestanteckningsboken på din Azure Databricks-arbetsyta. Den här notebook-filen kör enhetstester mot Python-hjulbibliotekets logik.
Använd Bash-aktiviteten: klicka på plustecknet igen i avsnittet Agentjobb, välj Bash-aktiviteten på fliken Verktyg och klicka sedan på Lägg till.
Klicka på bash-skriptaktiviteten bredvid Agentjobb.
För Typ väljer du Infogat.
Ersätt innehållet i Skript med följande kommando, som använder Databricks CLI för att köra jobbet på din Azure Databricks-arbetsyta:
databricks bundle run -t $(BUNDLE_TARGET) run-unit-testsAnge Visningsnamn till
Run unit tests.Klicka på Spara > OK.
Steg 3.10: Kör anteckningsboken som anropar Python-hjulet
I det här steget kör du ett jobb som kör en annan notebook-fil på din Azure Databricks-arbetsyta. Den här notebook-filen anropar Python-hjulbiblioteket.
Använd Bash-aktiviteten: klicka på plustecknet igen i avsnittet Agentjobb, välj Bash-aktiviteten på fliken Verktyg och klicka sedan på Lägg till.
Klicka på bash-skriptaktiviteten bredvid Agentjobb.
För Typ väljer du Infogat.
Ersätt innehållet i Skript med följande kommando, som använder Databricks CLI för att köra jobbet på din Azure Databricks-arbetsyta:
databricks bundle run -t $(BUNDLE_TARGET) run-dabdemo-notebookAnge Visningsnamn till
Run notebook.Klicka på Spara > OK.
Nu har du slutfört konfigurationen av versionspipelinen. Den bör se ut så här:
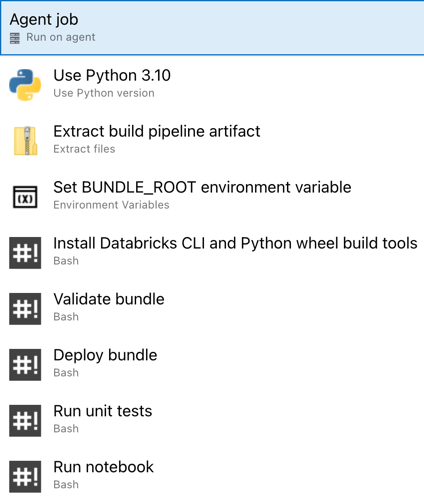
Steg 4: Kör bygg- och versionspipelines
I det här steget kör du pipelines manuellt. Information om hur du kör pipelines automatiskt finns i Ange händelser som utlöser pipelines och versionsutlösare.
Så här kör du bygg-pipelinen manuellt:
- Klicka på Pipelines på menyn Pipelines i sidofältet.
- Klicka på bygg-pipelinens namn och klicka sedan på Kör pipeline.
- För Gren/tagg väljer du namnet på grenen på din Git-lagringsplats som innehåller all källkod som du har lagt till. Det här exemplet förutsätter att detta finns i grenen
release. - Klicka på Kör. Versionspipelinens körningssida visas.
- Om du vill se bygg-pipelinens förlopp och visa relaterade loggar klickar du på den snurrande ikonen bredvid Jobb.
- När jobbikonen har omvandlats till en grön bockmarkering fortsätter du med att köra versionspipelinen.
Så här kör du versionspipelinen manuellt:
- När bygg-pipelinen har körts klickar du på Versioner på menyn Pipelines i sidofältet.
- Klicka på versionspipelinens namn och klicka sedan på Skapa version.
- Klicka på Skapa.
- Om du vill se versionspipelinens förlopp klickar du på namnet på den senaste versionen i listan med versioner.
- I rutan Faser klickar du på Steg 1 och klickar på Loggar.