Konfigurera AI Gateway på modellserverslutpunkter
I den här artikeln får du lära dig hur du konfigurerar Mosaic AI Gateway på en modell som betjänar slutpunkten.
Krav
- En Databricks-arbetsyta i en externa modeller som stöds eller etablerat dataflöde som stöds.
- En modell som betjänar slutpunkten.
- Om du vill skapa en slutpunkt för externa modeller slutför du steg 1 och 2 i Skapa en extern modell som betjänar slutpunkten.
- Information om hur du skapar en slutpunkt för etablerat dataflöde finns i API:er för etablering av dataflödesmodell.
Konfigurera AI Gateway med hjälp av användargränssnittet
I avsnittet AI Gateway på sidan för att skapa slutpunkter kan du konfigurera AI Gateway-funktioner individuellt. Se Stödda funktioner för att se vilka funktioner som är tillgängliga på slutpunkter för externt modellbetjänande och slutpunkter med etablerad genomströmning.
I följande tabell sammanfattas hur du konfigurerar AI-gatewayen när slutpunkten skapas med hjälp av serveringsgränssnittet. Om du föredrar att göra detta programmatiskt kan du läsa notebook-exemplet.
| Egenskap | Så här aktiverar du | Detaljer |
|---|---|---|
| Användningsspårning | Välj Aktivera för användningsspårning för att aktivera spårning och övervakning av dataanvändningsmått. |
|
| Nyttolastregistrering | Välj Aktivera slutsatsdragningstabeller för att automatiskt logga begäranden och svar från slutpunkten i Delta-tabeller som hanteras av Unity Catalog. |
|
| AI-skyddsräcken | Se Konfigurera AI Guardrails i användargränssnittet. |
|
| Hastighetsbegränsningar | Välj Hastighetsbegränsningar för att tillämpa hastighetsbegränsningar som hanterar trafiken för din slutpunkt baserat på per användare och per slutpunkt. |
|
| Trafikdelning | I avsnittet Serverade entiteter anger du procentandelen av trafiken du vill dirigeras till specifika modeller. Information om hur du konfigurerar trafikdelning på slutpunkten programmatiskt finns i Hantera flera externa modeller till en slutpunkt. |
|
| Återställningar | Välj Aktivera återfallsmodell i avsnittet AI Gateway för att skicka din begäran till andra tjänstgörande modeller på slutpunkten som en reserv. |
|
Följande diagram visar ett exempel där,
- Tre betjänade entiteter hanteras på en modell som betjänar slutpunkten.
- Begäran dirigeras ursprungligen till Hanterad entitet 3.
- Om begäran returnerar ett 200-svar, var begäran framgångsrik på Hanterad entitet 3 och begäran samt dess svar loggas i slutpunktens loggningstabeller för användningsspårning och nyttolast.
- Om begäran returnerar ett 429- eller 5xx-fel på Hanterad entitet 3, återgår begäran till nästa betjänade entitet på slutpunkten, Hanterad entitet 1.
- Om begäran returnerar ett 429- eller 5xx-fel på Hanterad entitet 1, återgår begäran till nästa betjänade entitet på slutpunkten, Betjänad entitet 2.
- Om begäran returnerar ett 429- eller 5xx-fel på Hanterad entitet 2misslyckas begäran eftersom det här är det maximala antalet återställningsentiteter. Den misslyckade begäran och svarsfelet loggas till loggningstabellerna för användningsspårning och nyttolast.

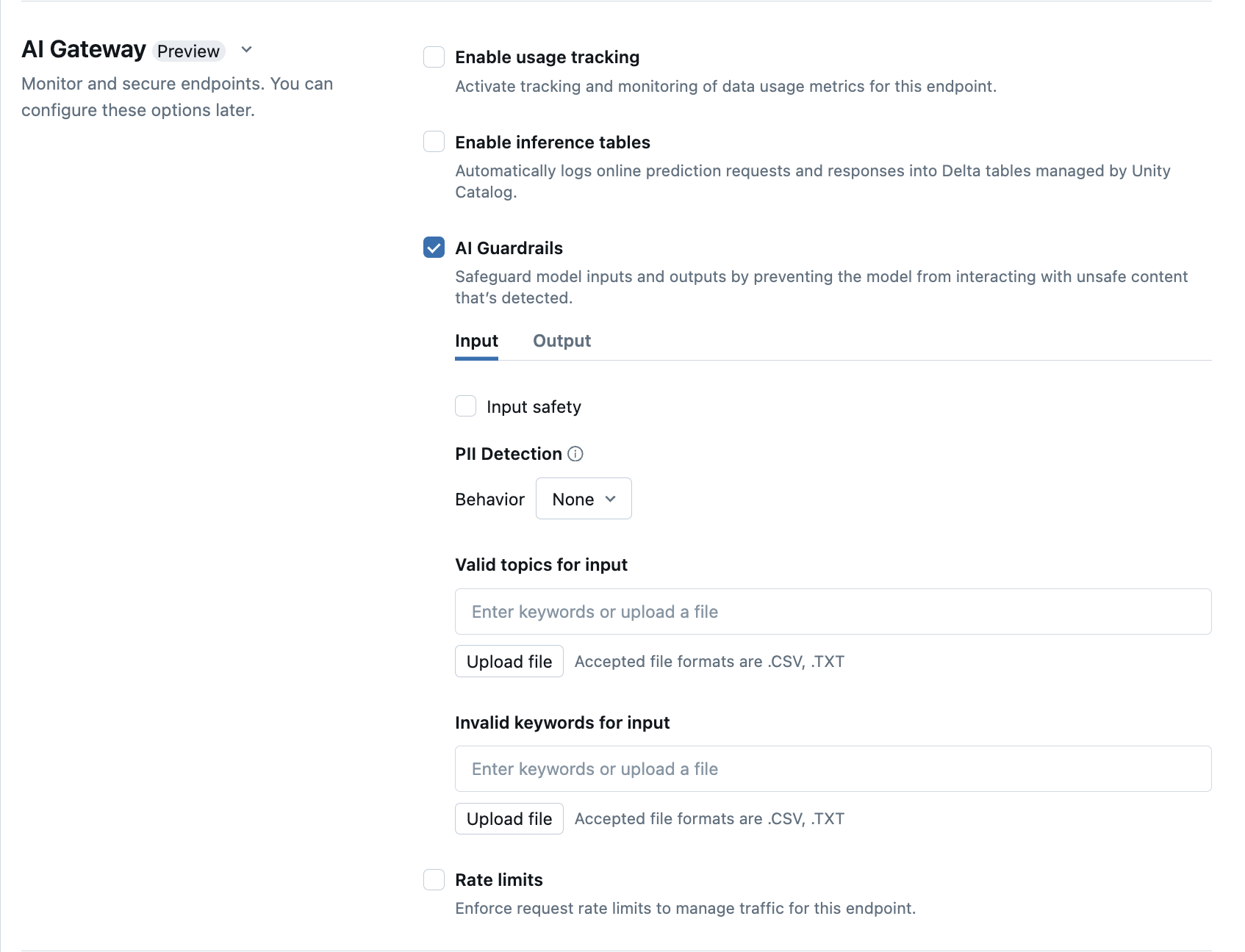
Konfigurera AI Guardrails i användargränssnittet
Följande tabell visar hur du konfigurerar de skyddsräcken som stöds av .
| Skyddsräcke | Så här aktiverar du | Detaljer |
|---|---|---|
| Säkerhet | Välj Säkerhets för att aktivera skydd för att förhindra att din modell interagerar med osäkert och skadligt innehåll. | |
| Identifiering av personligt identifierbar information (PII) | Välj PII-identifiering för att identifiera PII-data, till exempel namn, adresser, kreditkortsnummer. | |
| Giltiga ämnen | Du kan skriva in ämnen direkt i det här fältet. Om du har flera inmatningar måste du trycka på Retur efter varje ämne. Alternativt kan du ladda upp en .csv eller .txt fil. |
Högst 50 giltiga ämnen kan anges. Varje ämne får inte överstiga 100 tecken |
| Ogiltiga nyckelord | Du kan skriva in ämnen direkt i det här fältet. Om du har flera poster, se till att trycka på Retur efter varje ämne. Alternativt kan du ladda upp en .csv-fil eller en .txt-fil. |
Högst 50 ogiltiga nyckelord kan anges. Varje nyckelord får inte överstiga 100 tecken. |
Tabellscheman för användningsspårning
I följande avsnitt sammanfattas scheman för användningsspårningstabeller för system.serving.served_entities- och system.serving.endpoint_usage-systemtabeller.
system.serving.served_entities tabellschema för användningsspårning
Den system.serving.served_entities systemtabellen för användningsspårning har följande schema:
| Kolumnnamn | beskrivning | Typ |
|---|---|---|
served_entity_id |
Det unika ID:t för den betjänade entiteten. | STRÄNG |
account_id |
Kundkonto-ID för Delta Sharing. | STRÄNG |
workspace_id |
Kundens arbetsyte-ID för serverdelsslutpunkten. | STRÄNG |
created_by |
Skaparens ID. | sträng |
endpoint_name |
Namnet på tjänsteslutpunkten. | STRÄNG |
endpoint_id |
Det unika ID:t för tjänsteslutpunkten. | STRÄNG |
served_entity_name |
Namnet på den betjänade entiteten. | STRÄNG |
entity_type |
Typ av entitet som hanteras. Kan vara FEATURE_SPEC, EXTERNAL_MODEL, FOUNDATION_MODEL, eller CUSTOM_MODEL |
STRÄNG |
entity_name |
Det underliggande namnet på entiteten. Annorlunda från served_entity_name, som är ett namn angivet av användaren. Till exempel är entity_name namnet på Unity Catalog-modellen. |
STRÄNG |
entity_version |
Versionen av den betjänade entiteten. | sträng |
endpoint_config_version |
Versionen av slutpunktskonfigurationen. | INT |
task |
Aktivitetstypen. Kan vara llm/v1/chat, llm/v1/completionseller llm/v1/embeddings. |
STRÄNG |
external_model_config |
Konfigurationer för externa modeller. Till exempel: {Provider: OpenAI} |
STRUCT |
foundation_model_config |
Konfigurationer för grundmodeller. Till exempel{min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
STRUKTUR |
custom_model_config |
Konfigurationer för anpassade modeller. Till exempel{ min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
Konfigurationer för funktionsspecifikationer. Till exempel: { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
struktur |
change_time |
Tidsstämpel för ändring för den betjänade entiteten. | TIMESTAMP |
endpoint_delete_time |
Tidsstämpel för borttagning av entitet. Slutpunkten är containern för den betjänade entiteten. När slutpunkten har tagits bort tas även den hanterade entiteten bort. | TIMESTAMP |
system.serving.endpoint_usage tabellschema för användningsspårning
Den system.serving.endpoint_usage systemtabellen för användningsspårning har följande schema:
| Kolumnnamn | beskrivning | Typ |
|---|---|---|
account_id |
Kundkontots ID. | STRÄNG |
workspace_id |
Kundens arbetsyte-ID för tjänande slutpunkt. | STRÄNG |
client_request_id |
Användaren angav begärandeidentifierare som kan anges i den modell som betjänar begärandetexten. | STRÄNG |
databricks_request_id |
En Azure Databricks-genererad begärandeidentifierare som är kopplad till alla modelltjänstbegäranden. | STRÄNG |
requester |
ID:t för användaren eller tjänstens huvudnamn vars behörigheter används för anropsbegäran för serverdelsslutpunkten. | STRÄNG |
status_code |
HTTP-statuskoden som returnerades från modellen. | INTEGER |
request_time |
Tidsstämpeln där begäran tas emot. | TIMESTAMP |
input_token_count |
Tokenantalet för indata. | LÅNG |
output_token_count |
Tokenantalet för utdata. | LÅNG |
input_character_count |
Teckenantalet för indatasträngen eller prompten. | LÅNG |
output_character_count |
Teckenantalet för utdatasträngen för svaret. | LÅNG |
usage_context |
Den mapp som användaren angav innehåller identifierare för slutanvändaren eller kundprogrammet som anropar slutpunkten. Se Definiera användning ytterligare med usage_context. |
KARTA |
request_streaming |
Om begäran är i strömmande läge. | BOOLESK |
served_entity_id |
Det unika ID:t som används för att kopplas till system.serving.served_entities-dimensionstabellen för att hämta information om slutpunkten och den tillhandahållna entiteten. |
STRÄNG |
Definiera användning ytterligare med usage_context
När du kör frågor mot en extern modell med användningsspårning aktiverat kan du ange parametern usage_context med typen Map[String, String]. Mappningen av användningskontexten visas i tabellen för användningsspårning i kolumnen usage_context. Kartstorleken usage_context får inte överstiga 10 KiB.
Kontoadministratörer kan aggregera olika rader baserat på användningskontexten för att få insikter och kan koppla den här informationen till informationen i loggningstabellen för nyttolast. Till exempel kan du lägga till end_user_to_charge till usage_context för att spåra kostnadsattribution för slutanvändare.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Uppdatera AI Gateway-funktioner på slutpunkter
Du kan uppdatera AI Gateway-funktioner på modellbetjänande slutpunkter som tidigare hade dem aktiverade och slutpunkter som inte hade dem. Det tar cirka 20–40 sekunder att tillämpa uppdateringar av AI Gateway-konfigurationer, men det kan ta upp till 60 sekunder att uppdatera hastighetsbegränsningen.
Följande visar hur du uppdaterar AI Gateway-funktioner på en modell som betjänar slutpunkten med hjälp av användargränssnittet för servering.
I avsnittet Gateway på slutpunktssidan kan du se vilka funktioner som är aktiverade. Om du vill uppdatera dessa funktioner klickar du på Redigera AI Gateway-.

Notebook-exempel
Följande notebook-fil visar hur du programmatiskt aktiverar och använder Ai Gateway-funktioner för Databricks Mosaic för att hantera och styra modeller från leverantörer. Mer information finns i PUT /api/2.0/serving-endpoints/{name}/ai-gateway.