Transformera data i Azure Virtual Network med hive-aktivitet i Azure Data Factory med hjälp av Azure Portal
GÄLLER FÖR:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I den här självstudien använder du Azure Portal för att skapa en Data Factory-pipeline som transformerar data med en Hive-aktivitet på ett HDInsight-kluster som finns i Azure Virtual Network (VNet). I de här självstudierna går du igenom följande steg:
- Skapa en datafabrik.
- Skapa en lokalt installerad integrationskörning
- Skapa länkade Azure Storage- och Azure HDInsight-tjänster
- Skapa en pipeline med Hive-aktivitet.
- Utlös en pipelinekörning.
- Övervaka pipelinekörningen
- Verifiera utdata
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
Kommentar
Vi rekommenderar att du använder Azure Az PowerShell-modulen för att interagera med Azure. Se Installera Azure PowerShell för att komma igång. Information om hur du migrerar till Az PowerShell-modulen finns i artikeln om att migrera Azure PowerShell från AzureRM till Az.
Azure Storage-konto. Du skapar ett hive-skript och överför det till Azure Storage. Hive-skriptets utdata lagras på det här lagringskontot. I det här exemplet använder HDInsight-klustret det här Azure Storage-kontot som primär lagring.
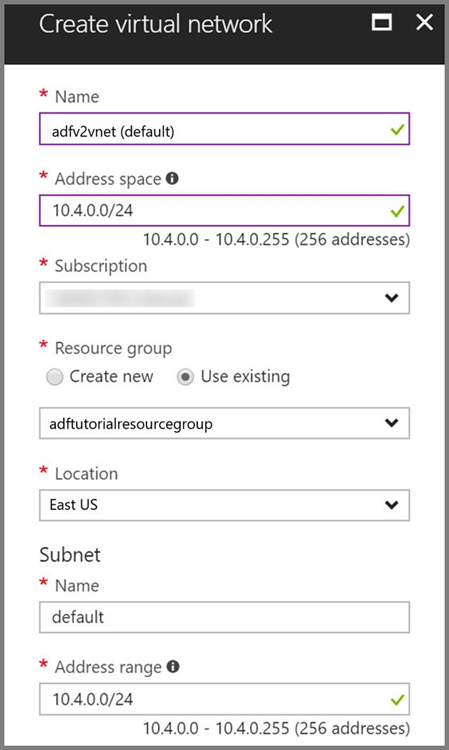
Azure Virtual Network. Om du inte har något virtuellt Azure-nätverk skapar du det genom att följa de här instruktionerna. I det här exemplet är HDInsight i ett virtuellt Azure-nätverk. Här är en exempelkonfiguration av Azure Virtual Network.
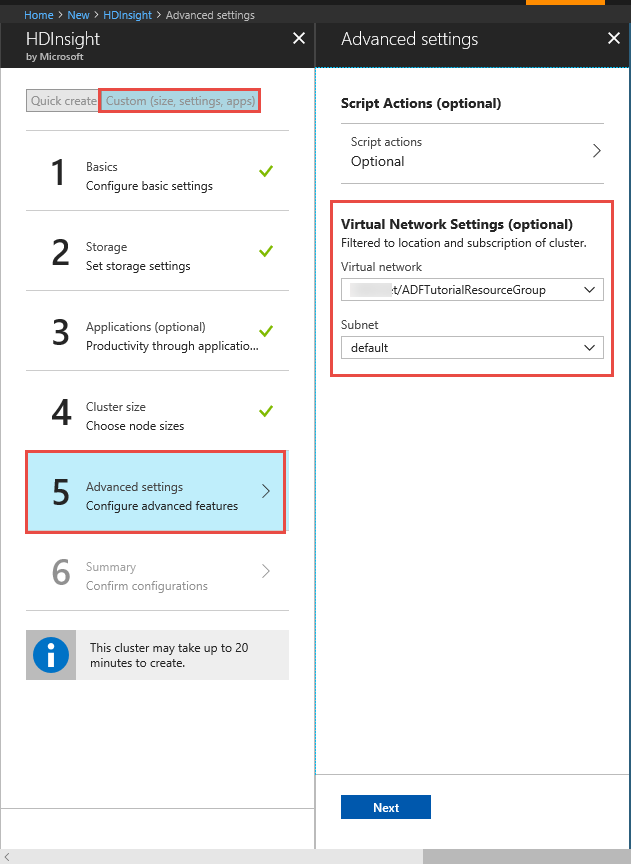
HDInsight-kluster. Skapa ett HDInsight-kluster och anslut det till det virtuella nätverket som du skapade i föregående steg genom att följa stegen i den här artikeln: Extend Azure HDInsight using an Azure Virtual Network (Utöka HDInsight med ett Azure Virtual Network). Här är en exempelkonfiguration av HDInsight i ett virtuellt nätverk.
Azure PowerShell. Följ instruktionerna i Så här installerar och konfigurerar du Azure PowerShell.
En virtuell dator. Skapa en virtuell Azure-dator och koppla den till samma virtuella nätverk som innehåller ditt HDInsight-kluster. Läs mer i informationen om att skapa virtuella datorer.
Överföra Hive-skriptet till ditt Blob Storage-konto
Skapa en Hive SQL-fil med namnet hivescript.hql med följande innehåll:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableSkapa en container med namnet adftutorial i Azure Blob Storage om den inte finns.
Skapa en mapp med namnet hivescripts.
Ladda upp filen hivescript.hql till undermappen hivescripts.
Skapa en datafabrik
Om du inte har skapat din datafabrik ännu följer du stegen i Snabbstart: Skapa en datafabrik med hjälp av Azure Portal och Azure Data Factory Studio för att skapa en. När du har skapat den bläddrar du till datafabriken i Azure Portal.

Välj Öppna på panelen Öppna Azure Data Factory Studio för att starta Dataintegration-programmet på en separat flik.
Skapa en lokalt installerad integrationskörning
Eftersom Hadoop-klustret är inne i ett virtuellt nätverk måste du installera en lokal integreringskörning i samma virtuella nätverk. I det här avsnittet skapar du en ny virtuell dator, ansluter den till samma virtuella nätverk och installerar en lokal IR på den. Med en lokal IR kan Data Factory-tjänsten skicka bearbetningsbegäranden till en databearbetningstjänst som HDInsight inne i ett virtuellt nätverk. Den gör också så att du kan flytta data till och från datalager inne i ett virtuellt nätverk till Azure. Du använder också en lokal IR när datalagret eller databearbetningstjänsten finns i en lokal miljö.
I användargränssnittet för Azure Data Factory klickar du på Anslutningar längst ned i fönstret, växlar till fliken med integreringskörningar och klickar på + Ny i verktygsfältet.
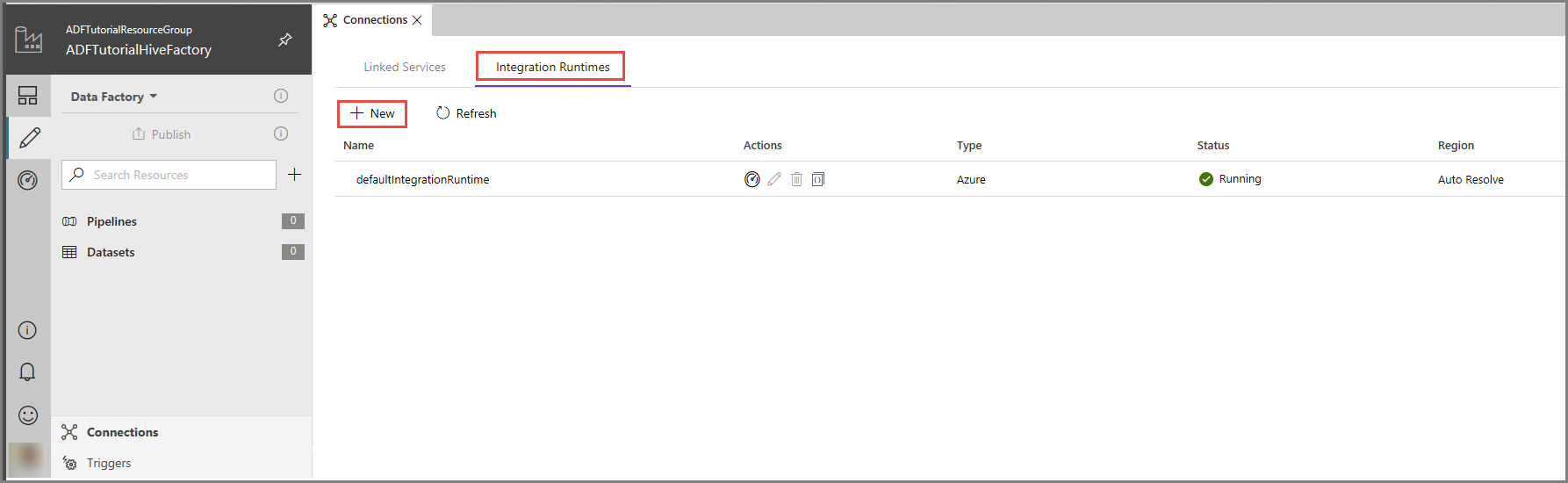
I installationsfönstret för Integration Runtime väljer du alternativet Perform data movement and dispatch activities to external computes (Utför dataflytt och skicka aktiviteter till externa databearbetningstjänster) och klickar på Nästa.
Välj Privat nätverk och klicka på Nästa.
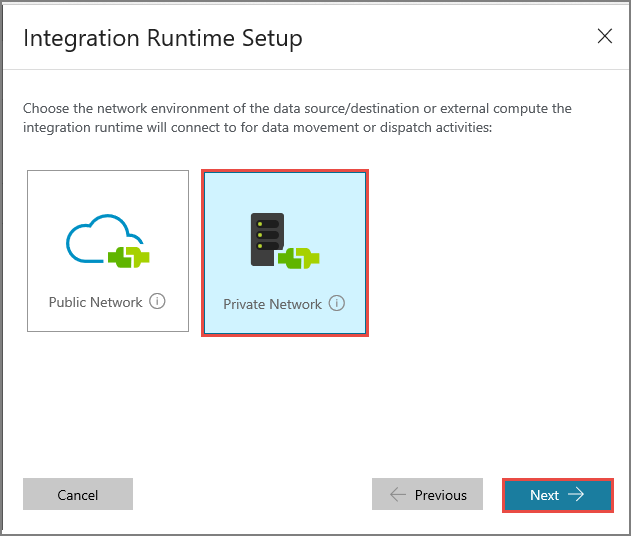
Ange MySelfHostedIR som namn och klicka på Nästa.
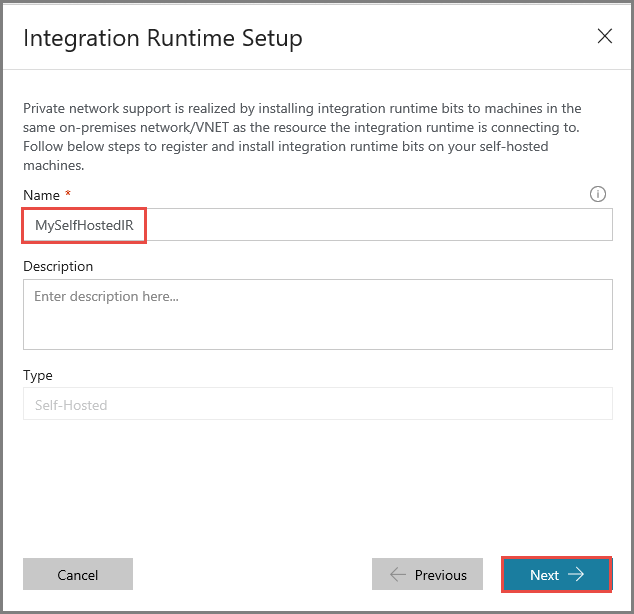
Kopiera autentiseringsnyckeln för integreringskörningen genom att klicka på kopieringsknappen och spara den. Lämna fönstret öppet. Du kan använda den här nyckeln till att registrera den IR som installerats på en virtuell dator.
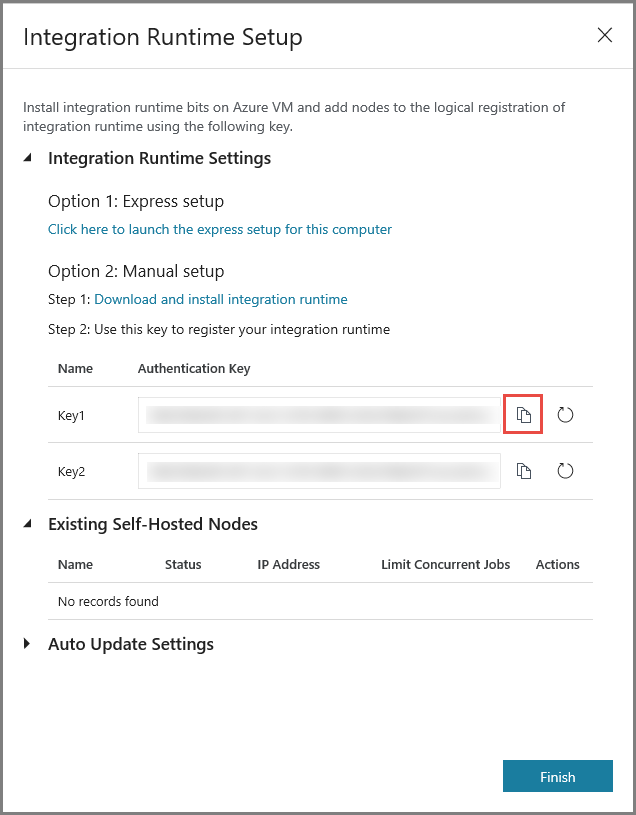
Installera IR på en virtuell dator
Ladda ned integration runtime med egen värd till den virtuella Azure-datorn. Använd autentiseringsnyckeln som hämtades i föregående steg för att manuellt registrera den lokala integreringskörningen.
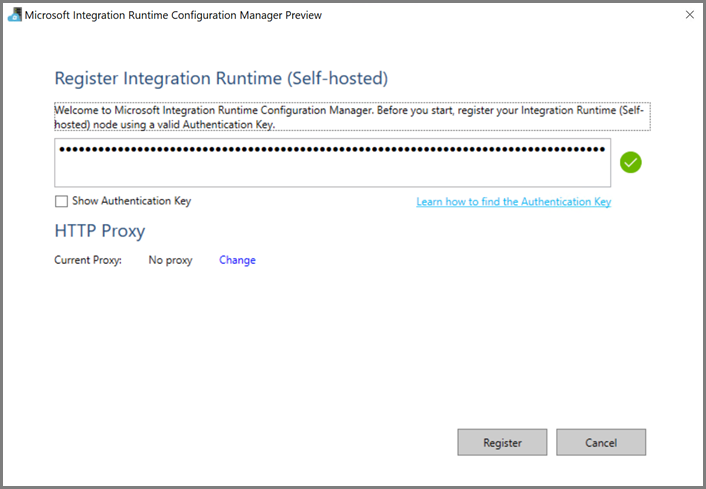
När den lokala integreringskörningen har registrerats ser du följande meddelande.
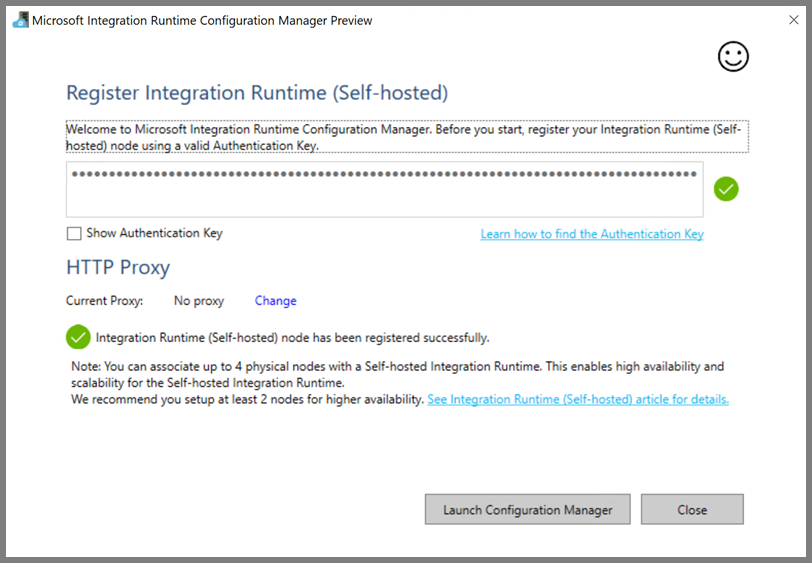
Klicka på Starta Konfigurationshanteraren. Du ser följande sida när noden är ansluten till molntjänsten:
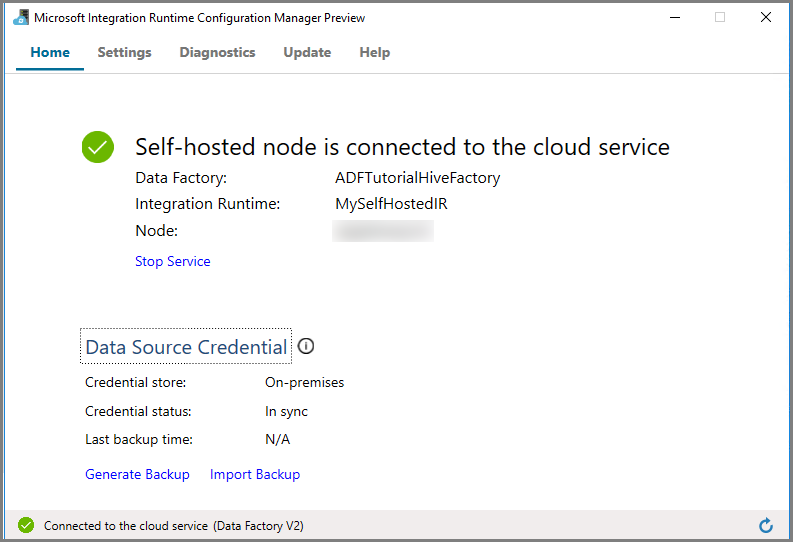
Lokal IR i användargränssnittet för Azure Data Factory
I användargränssnittet för Azure Data Factory bör du se namnet på den lokala virtuella datorn och dess status.
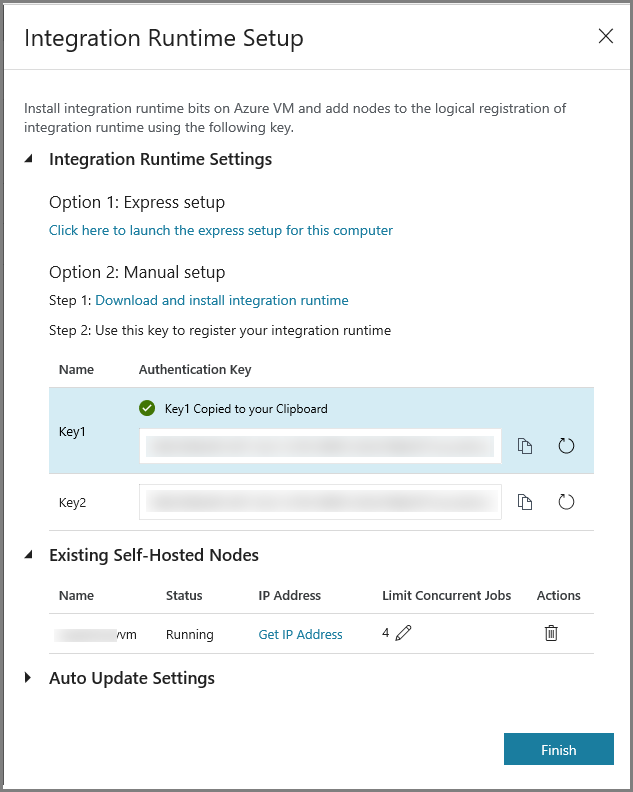
Klicka på Slutför för att stänga installationsfönstret för Integration Runtime. Den lokala integreringskörningen visas i listan med integreringskörningar.

Skapa länkade tjänster
Du skapar och distribuerar två länkade tjänster i det här avsnittet:
- En länkad Azure Storage-tjänst som länkar ett Azure Storage-konto till datafabriken. Den här lagringen är den som primärt används av ditt HDInsight-kluster. I det här fallet använder du det här Azure Storage-kontot för att lagra Hive-skriptet och dess utdata.
- En länkad HDInsight-tjänst. Azure Data Factory skickar Hive-skriptet till det här HDInsight-klustret för körning.
Skapa en länkad Azure-lagringstjänst
Växla till fliken Länkade tjänster och klicka på Ny.
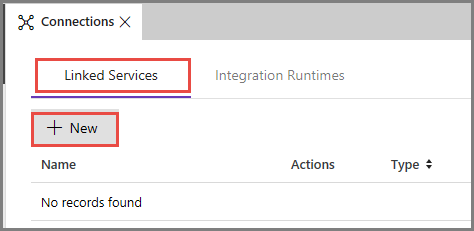
I fönstret New Linked Service (Ny länkad tjänst) väljer du Azure Blob Storage och klickar på Fortsätt.
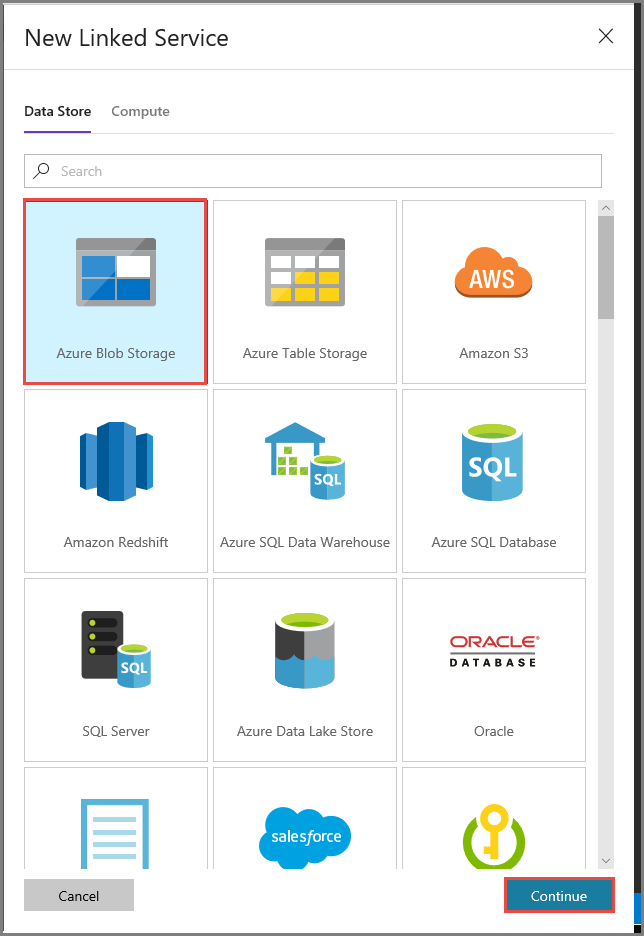
Utför följande steg i fönstret New Linked Service (Ny länkad tjänst):
Ange AzureStorageLinkedService som namn.
Välj MySelfHostedIR för Connect via integration runtime (Anslut via Integration Runtime).
Välj ditt Azure-lagringskonto i Lagringskontonamn.
Testa anslutningen till lagringskontot genom att klicka på Testa anslutning.
Klicka på Spara.
Skapa länkad HDInsight-tjänst
Klicka på Ny igen för att skapa ytterligare en länkad tjänst.
Växla till fliken Compute (Beräkna), välj Azure HDInsight och klicka på Fortsätt.
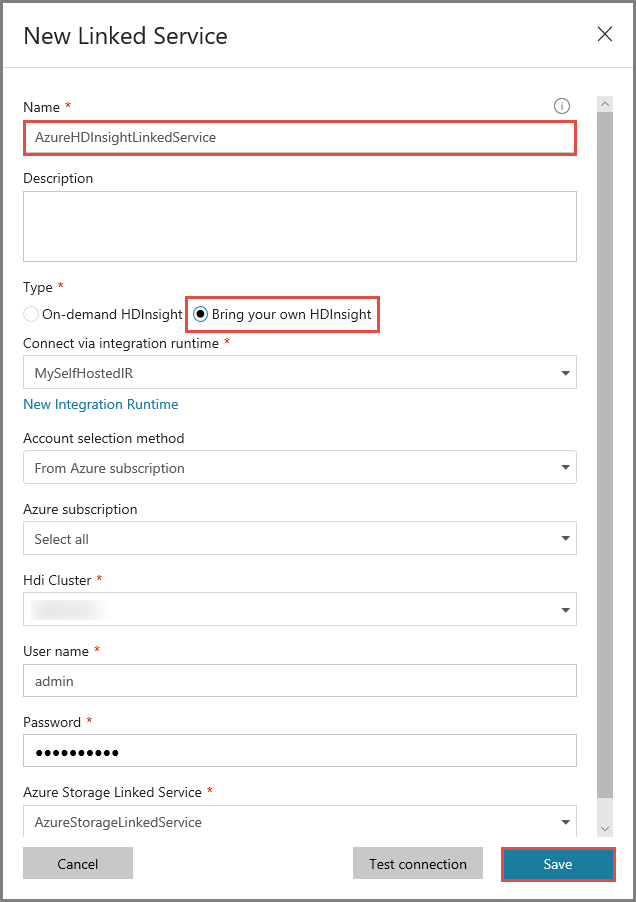
Utför följande steg i fönstret New Linked Service (Ny länkad tjänst):
Ange AzureHDInsightLinkedService som namn.
Välj Bring your own HDInsight (Använd egen HDInsight).
Välj ditt HDInsight-kluster för Hdi cluster (HDI-kluster).
Ange användarnamnet för HDInsight-klustret.
Ange lösenordet för användaren.
Den här artikeln förutsätter att du har åtkomst till klustret via internet. Till exempel att du kan ansluta till klustret i https://clustername.azurehdinsight.net. Den här adressen använder den offentliga gatewayen, som inte är tillgänglig om du har använt nätverkssäkerhetsgrupper (NSG:er) eller användardefinierade vägar (UDR:er) för att begränsa åtkomst från internet. För att Data Factory ska kunna skicka jobb till HDInsight-klustret i Azure Virtual Network måste du konfigurera ditt Azure Virtual Network så att URL-adressen kan matchas med gatewayens privata IP-adress som används av HDInsight.
Från Azure-portalen öppnar du det virtuella nätverket som HDInsight finns i. Öppna nätverksgränssnittet med namnet som börjar med
nic-gateway-0. Skriv ned dess privata IP-adress. Till exempel 10.6.0.15.Om din Azure Virtual Network har en DNS-server uppdaterar du DNS-posten så HDInsight-klustrets URL
https://<clustername>.azurehdinsight.netkan matchas mot10.6.0.15. Om du inte har någon DNS-server i Azure Virtual Network kan du tillfälligt lösa detta genom att redigera värdfilen (C:\Windows\System32\drivers\etc) för alla virtuella datorer som är registrerade som lokala integreringskörningsnoder genom att lägga till en post som ser ut ungefär så här:10.6.0.15 myHDIClusterName.azurehdinsight.net
Skapa en pipeline
I det här steget kan du skapa en ny pipeline med en Hive-aktivitet. Aktiviteten kör Hive-skript för att returnera data från en exempeltabell och spara dem till en sökväg som du har definierat.
Observera följande:
- scriptPath pekar på sökvägen till Hive-skriptet i Azure Storage-kontot du använde för MyStorageLinkedService. Sökvägen är skiftlägeskänslig.
- Utdata är ett argument som används i Hive-skriptet. Använd formatet
wasbs://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/för att peka på en befintlig mapp i Azure Storage. Sökvägen är skiftlägeskänslig.
I användargränssnittet för Data Factory klickar du på + (plustecknet) i det vänstra fönstret och klickar på Pipeline.
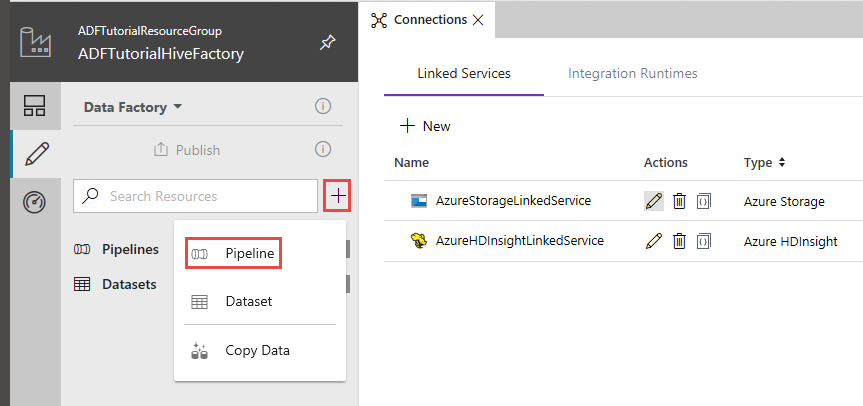
I verktygslådan Aktiviteter visar du HDInsight och drar och släpper Hive-aktiviteten till pipelinedesignytan.
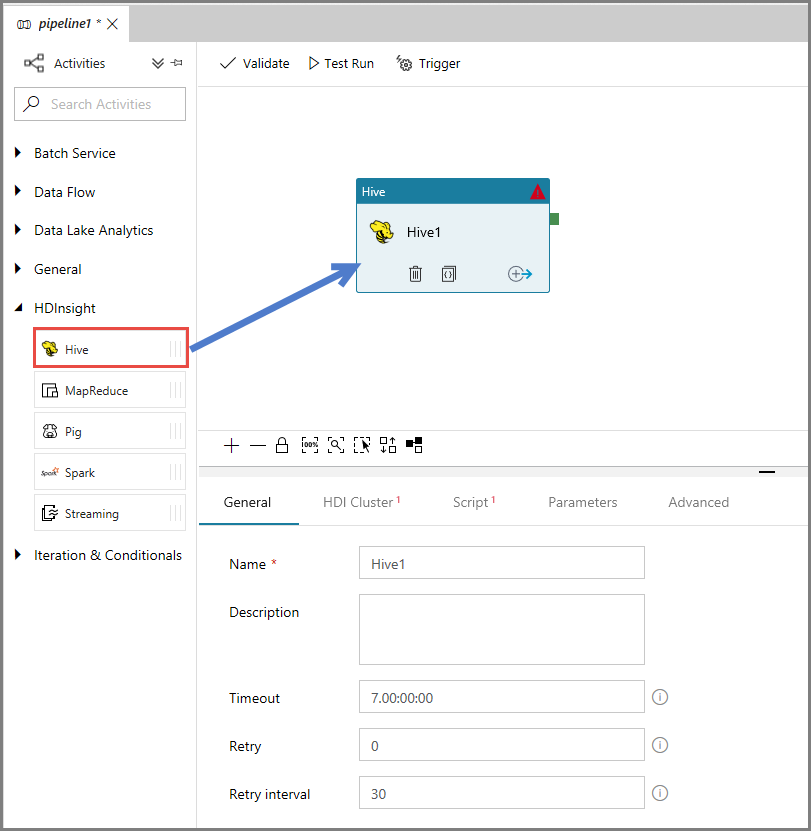
I egenskapsfönstret växlar du till fliken HDI Cluster (HDI-kluster) och väljer AzureHDInsightLinkedService för HDInsight Linked Service.

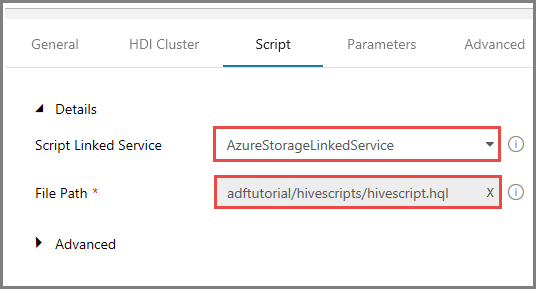
Växla till fliken Skript och gör följande:
Välj AzureStorageLinkedService för Skriptlänkad tjänst.
För Filsökväg klickar du på Bläddra i lagring.
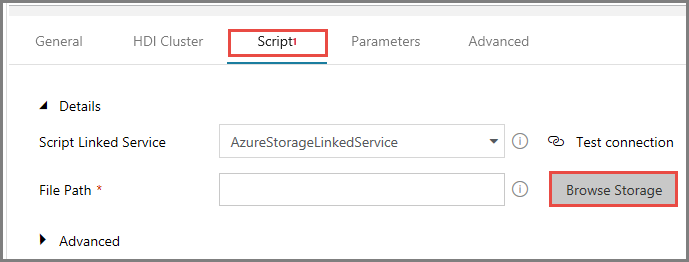
I fönstret Choose a file or folder (Välj en fil eller mapp) navigerar du till mappen hivescripts i containern adftutorial och väljer hivescript.hql. Klicka sedan på Slutför.
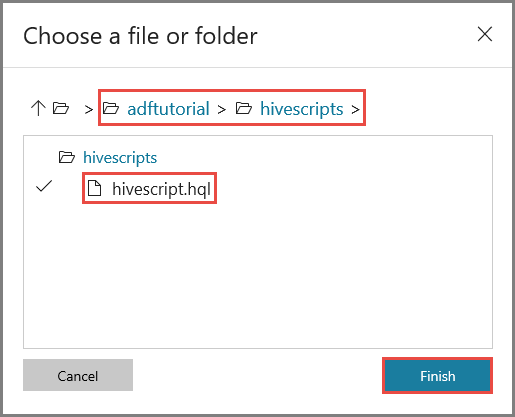
Bekräfta att det står adftutorial/hivescripts/hivescript.hql som filsökväg.
Visa avsnittet Avancerat på fliken Skript.
Klicka på Auto-fill from script (Fyll i automatiskt från skript) för Parametrar.
Ange värdet för parametern Utdata i följande format:
wasbs://<Blob Container>@<StorageAccount>.blob.core.windows.net/outputfolder/. Exempel:wasbs://adftutorial@mystorageaccount.blob.core.windows.net/outputfolder/.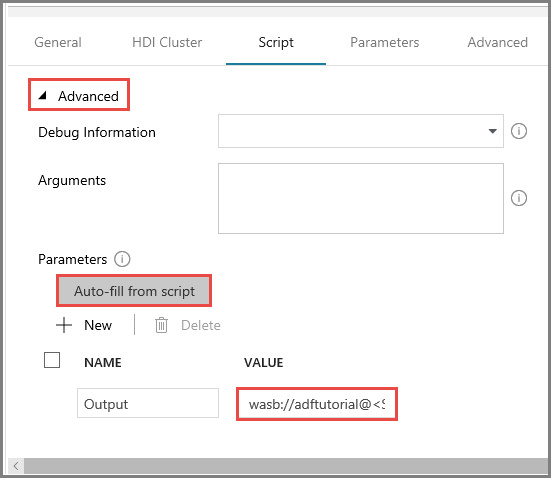
Om du vill publicera artefakter till Data Factory klickar du på Publicera.
Utlös en pipelinekörning
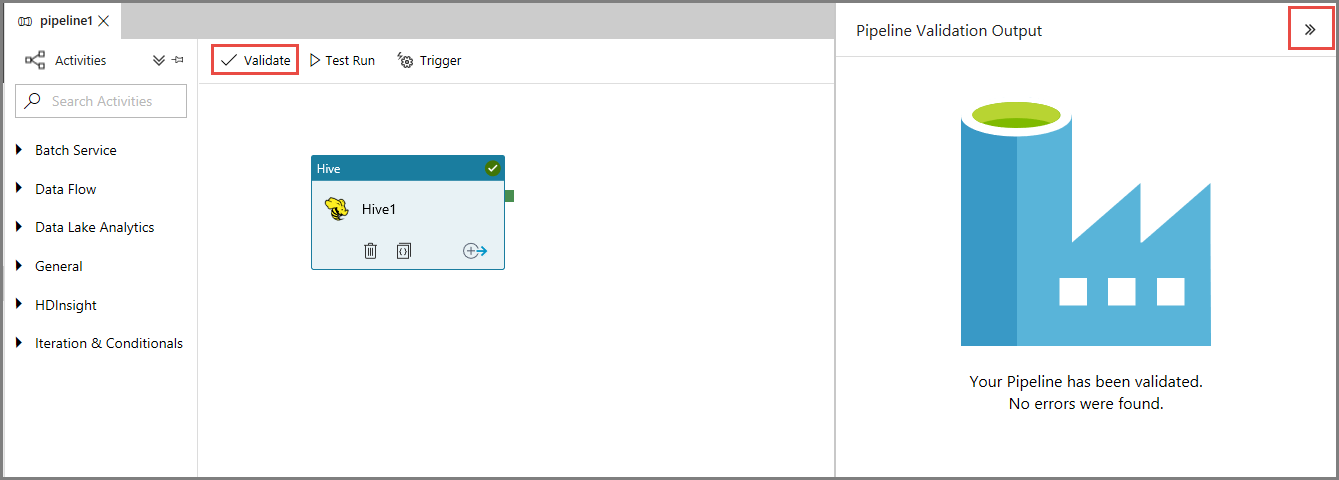
Verifiera först pipelinen genom att klicka på knappen Verifiera i verktygsfältet. Stäng fönstret Utdata för pipelineverifiering genom att klicka på högerpilen (>>).
Om du vill utlösa en pipelinekörning klickar du på Utlösare i verktygsfältet och klickar på Trigger Now (Utlös nu).
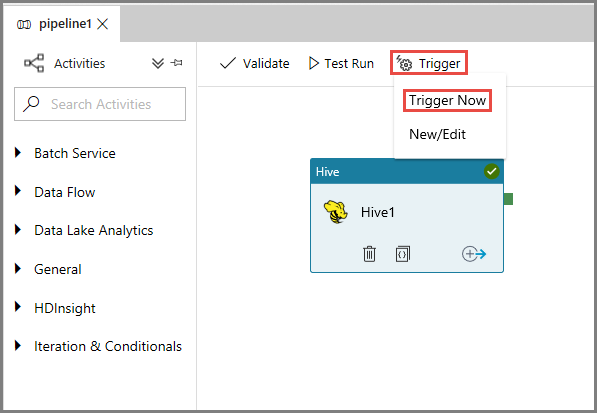
Övervaka pipelinekörningen
Växla till fliken Övervaka till vänster. En pipelinekörning visas i listan Pipeline Runs (Pipelinekörningar).
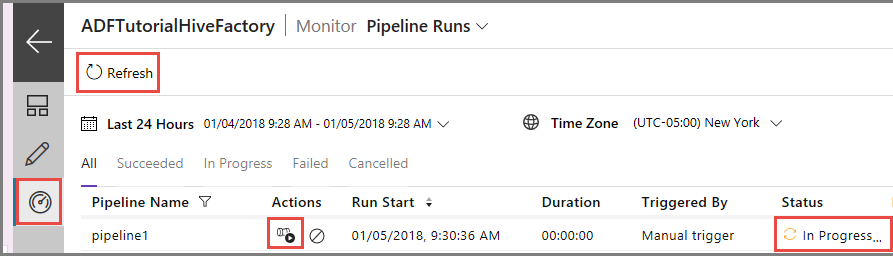
Om du vill uppdatera listan klickar du på Uppdatera.
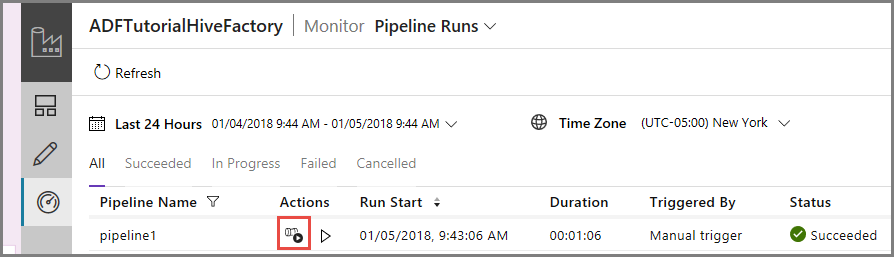
Om du vill visa aktivitetskörningar som är associerade med pipelinekörningarna klickar du på View activity runs (Visa aktivitetskörningar) i kolumnen Action (Åtgärd). Övriga åtgärdslänkar är till för att stoppa pipelinen respektive köra den på nytt.
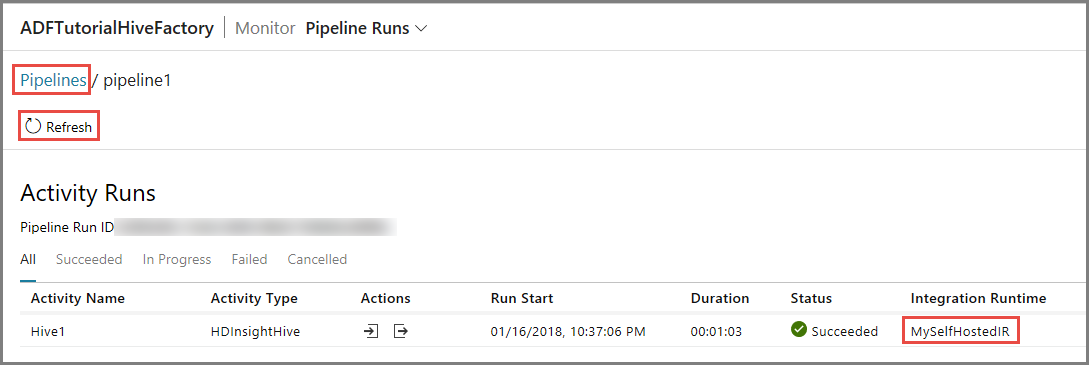
Du ser bara en aktivitetskörning eftersom det bara finns en aktivitet i pipelinen av typen HDInsightHive. Om du vill växla tillbaka till föregående vy klickar du på Pipeliner längst upp.
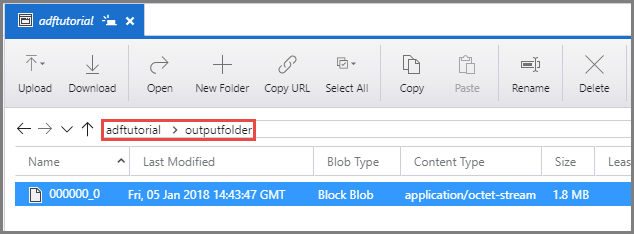
Bekräfta att du ser en utdatafil i outputfolder för containern adftutorial.
Relaterat innehåll
I den här självstudiekursen fick du:
- Skapa en datafabrik.
- Skapa en lokalt installerad integrationskörning
- Skapa länkade Azure Storage- och Azure HDInsight-tjänster
- Skapa en pipeline med Hive-aktivitet.
- Utlös en pipelinekörning.
- Övervaka pipelinekörningen
- Verifiera utdata
Fortsätt till följande självstudie och lär dig att transformera data med ett Spark-kluster på Azure: