Transformera data i Azure Virtual Network med en Hive-aktivitet i Azure Data Factory
GÄLLER FÖR:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I den här självstudien använder du Azure PowerShell för att skapa en Data Factory-pipeline som transformerar data med en Hive-aktivitet på ett HDInsight-kluster som finns i Azure Virtual Network (VNet). I de här självstudierna går du igenom följande steg:
- Skapa en datafabrik.
- Skapa och konfigurera Integration Runtime med egen värd
- Skapa och distribuera länkade tjänster.
- Skapa och distribuera en pipeline som innehåller en Hive-aktivitet.
- Starta en pipelinekörning.
- Övervaka pipelinekörningen
- verifiera utdata.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
Kommentar
Vi rekommenderar att du använder Azure Az PowerShell-modulen för att interagera med Azure. Se Installera Azure PowerShell för att komma igång. Information om hur du migrerar till Az PowerShell-modulen finns i artikeln om att migrera Azure PowerShell från AzureRM till Az.
Azure Storage-konto. Du skapar ett hive-skript och överför det till Azure Storage. Hive-skriptets utdata lagras på det här lagringskontot. I det här exemplet använder HDInsight-klustret det här Azure Storage-kontot som primär lagring.
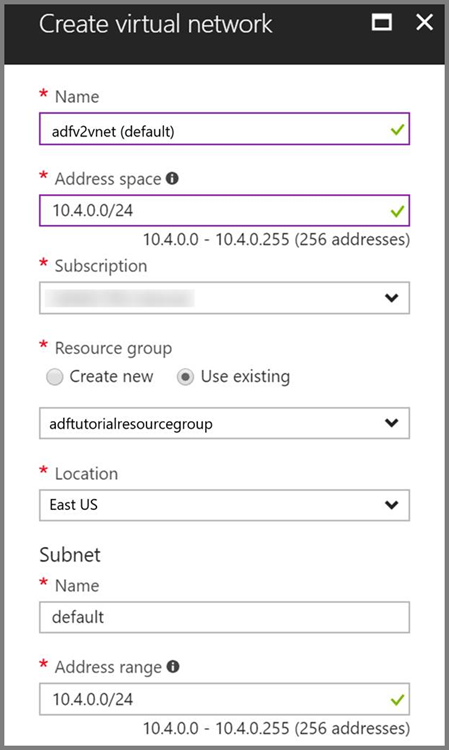
Azure Virtual Network. Om du inte har något virtuellt Azure-nätverk skapar du det genom att följa de här instruktionerna. I det här exemplet är HDInsight i ett virtuellt Azure-nätverk. Här är en exempelkonfiguration av Azure Virtual Network.
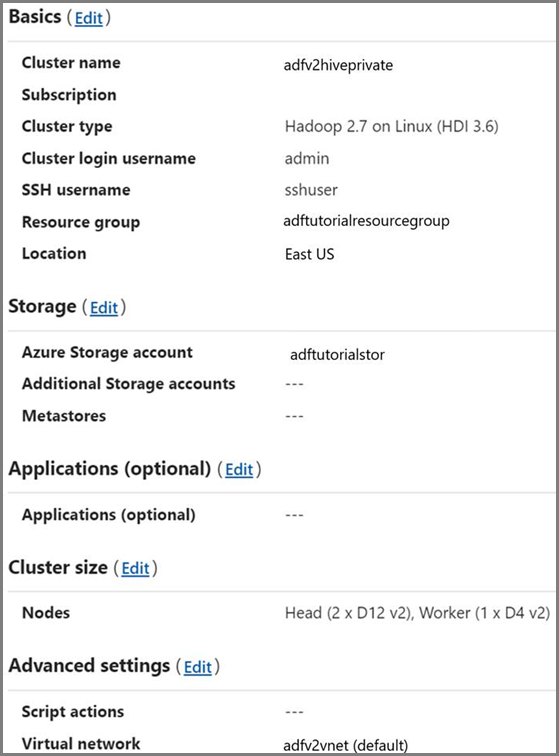
HDInsight-kluster. Skapa ett HDInsight-kluster och anslut det till det virtuella nätverket som du skapade i föregående steg genom att följa stegen i den här artikeln: Extend Azure HDInsight using an Azure Virtual Network (Utöka HDInsight med ett Azure Virtual Network). Här är en exempelkonfiguration av HDInsight i ett virtuellt nätverk.
Azure PowerShell. Följ instruktionerna i Så här installerar och konfigurerar du Azure PowerShell.
Överföra Hive-skriptet till ditt Blob Storage-konto
Skapa en Hive SQL-fil med namnet hivescript.hql med följande innehåll:
DROP TABLE IF EXISTS HiveSampleOut; CREATE EXTERNAL TABLE HiveSampleOut (clientid string, market string, devicemodel string, state string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '${hiveconf:Output}'; INSERT OVERWRITE TABLE HiveSampleOut Select clientid, market, devicemodel, state FROM hivesampletableSkapa en container med namnet adftutorial i Azure Blob Storage om den inte finns.
Skapa en mapp med namnet hivescripts.
Ladda upp filen hivescript.hql till undermappen hivescripts.
Skapa en datafabrik
Ange resursgruppsnamnet. Du skapar en resursgrupp som en del av den här självstudien. Men du kan även använda en befintlig resursgrupp om du vill.
$resourceGroupName = "ADFTutorialResourceGroup"Ange datafabriksnamnet. Det måste vara globalt unikt.
$dataFactoryName = "MyDataFactory09142017"Ange ett namn för din pipeline.
$pipelineName = "MyHivePipeline" #Ange ett namn för den lokala installationen av Integration Runtime. Du behöver en lokal installation av Integration Runtime när Data Factory behöver åtkomst till resurser (till exempel Azure SQL Database) i ett virtuellt nätverk.
$selfHostedIntegrationRuntimeName = "MySelfHostedIR09142017"Starta PowerShell. Låt Azure PowerShell vara öppet tills du är klar med snabbstarten. Om du stänger och öppnar det igen måste du köra kommandona en gång till. Om du vill se en lista med Azure-regioner där Data Factory är tillgängligt för närvarande markerar du de regioner du är intresserad av på följande sida. Expandera sedan Analytics och leta rätt på Data Factory: Tillgängliga produkter per region. Datalagren (Azure Storage, Azure SQL Database osv.) och beräkningarna (HDInsight osv.) som används i Data Factory kan finnas i andra regioner.
Kör följande kommando och ange det användarnamn och lösenord som du använder för att logga in i Azure Portal:
Connect-AzAccountKör följande kommando för att visa alla prenumerationer för det här kontot:
Get-AzSubscriptionKör följande kommando för att välja den prenumeration som du vill arbeta med. Ersätt SubscriptionId med ID:t för din Azure-prenumeration:
Select-AzSubscription -SubscriptionId "<SubscriptionId>"Skapa resursgruppen: ADFTutorialResourceGroup om den inte redan finns i din prenumeration.
New-AzResourceGroup -Name $resourceGroupName -Location "East Us"Skapa datafabriken.
$df = Set-AzDataFactoryV2 -Location EastUS -Name $dataFactoryName -ResourceGroupName $resourceGroupNameKör följande kommando för att se utdata:
$df
Skapa IR med egen värd
I det här avsnittet skapar du en Integration Runtime med egen värd och kopplar den till en virtuell Azure-dator i samma Azure Virtual Network som innehåller ditt HDInsight-kluster.
Skapa Integration Runtime med egen värd. Använd ett unikt namn om det finns en annan Integration Runtime med samma namn.
Set-AzDataFactoryV2IntegrationRuntime -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName -Type SelfHostedDetta kommando skapar en logisk registrering av din Integration Runtime med egen värd.
Använd PowerShell för att hämta autentiseringsnycklar för att registrera Integration Runtime med egen värd. Kopiera någon av nycklarna för att registrera Integration Runtime med egen värd.
Get-AzDataFactoryV2IntegrationRuntimeKey -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Name $selfHostedIntegrationRuntimeName | ConvertTo-JsonHär är exempel på utdata:
{ "AuthKey1": "IR@0000000000000000000000000000000000000=", "AuthKey2": "IR@0000000000000000000000000000000000000=" }Anteckna värdet AuthKey1 utan citattecken.
Skapa en virtuell Azure-dator och koppla den till samma virtuella nätverk som innehåller ditt HDInsight-kluster. Läs mer i informationen om att skapa virtuella datorer. Koppla dem till ett Azure Virtual Network.
Ladda ned integration runtime med egen värd till den virtuella Azure-datorn. Använd autentiseringsnyckeln som hämtades i föregående steg för att manuellt registrera integration runtime med egen värd.
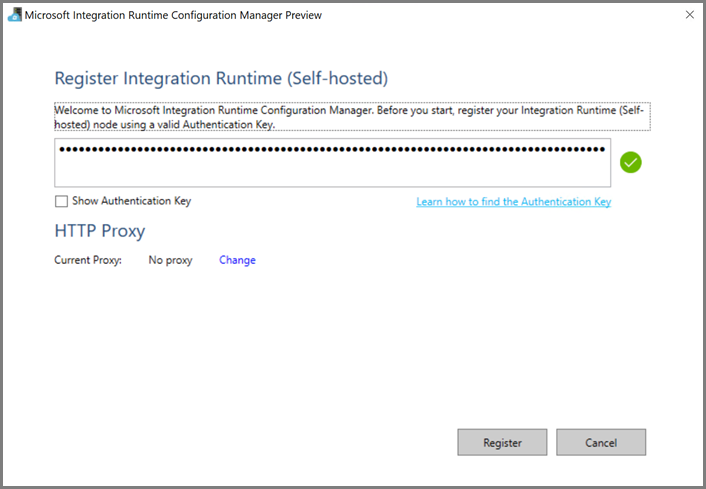
Du ser följande meddelande när den lokalt installerade integrationskörningen har registrerats:
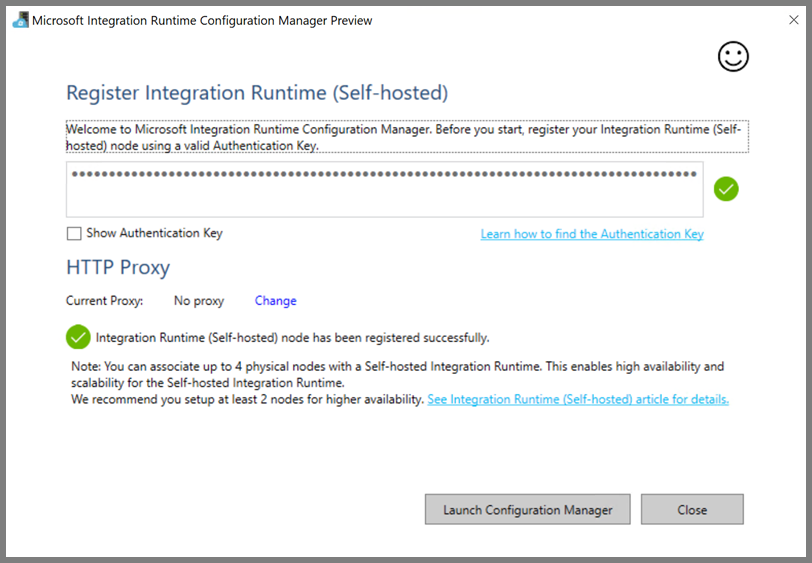
Du ser följande sida när noden är ansluten till molntjänsten:
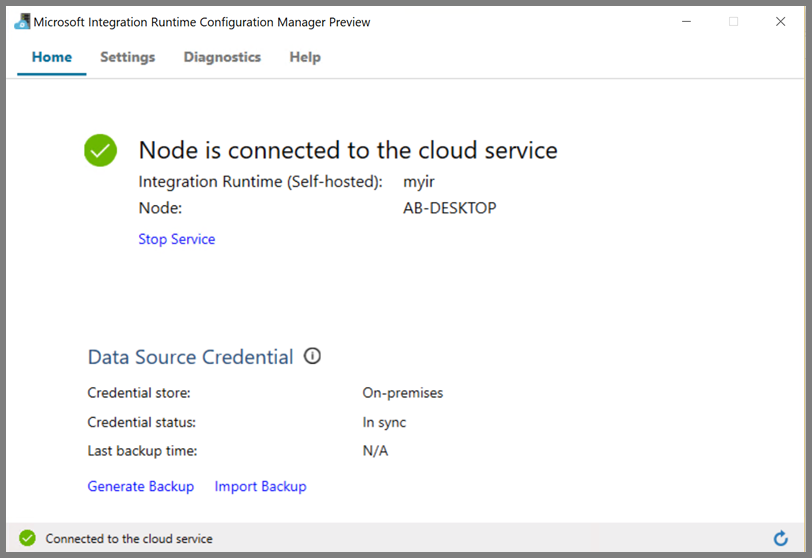
Skapa länkade tjänster
Du skapar och distribuerar två länkade tjänster i det här avsnittet:
- En länkad Azure Storage-tjänst som länkar ett Azure Storage-konto till datafabriken. Den här lagringen är den som primärt används av ditt HDInsight-kluster. I det här fallet använder vi även det här Azure Storage-kontot för att lagra Hive-skriptet och dess utdata.
- En länkad HDInsight-tjänst. Azure Data Factory skickar Hive-skriptet till det här HDInsight-klustret för körning.
Länkad Azure-lagringstjänst
Skapa en JSON-fil med önskat redigeringsprogram, kopiera följande JSON-definition för en länkad Azure Storage-tjänst och spara filen som MyStorageLinkedService.json.
{
"name": "MyStorageLinkedService",
"properties": {
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<storageAccountName>;AccountKey=<storageAccountKey>"
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
Ersätt <accountname> och <accountkey> med namnet och nyckeln för ditt Azure-lagringskonto.
Länkad HDInsight-tjänst
Skapa en JSON-fil med önskat redigeringsprogram, kopiera följande JSON-definition för en länkad Azure HDInsight-tjänst och spara filen som MyHDInsightLinkedService.json.
{
"name": "MyHDInsightLinkedService",
"properties": {
"type": "HDInsight",
"typeProperties": {
"clusterUri": "https://<clustername>.azurehdinsight.net",
"userName": "<username>",
"password": {
"value": "<password>",
"type": "SecureString"
},
"linkedServiceName": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
},
"connectVia": {
"referenceName": "MySelfhostedIR",
"type": "IntegrationRuntimeReference"
}
}
}
Uppdatera värden för följande egenskaper i definitionen för den länkade tjänsten:
userName. Namnet på användaren för klusterinloggningen som du angav när du skapade klustret.
password. Ange lösenordet för användaren.
clusterUri. Ange URL:en för HDInsight-klustret i följande format:
https://<clustername>.azurehdinsight.net. Den här artikeln förutsätter att du har åtkomst till klustret via internet. Du kan till exempel ansluta till klustret påhttps://clustername.azurehdinsight.net. Den här adressen använder den offentliga gatewayen, som inte är tillgänglig om du har använt nätverkssäkerhetsgrupper (NSG:er) eller användardefinierade vägar (UDR:er) för att begränsa åtkomst från internet. För att Data Factory ska kunna skicka jobb till HDInsight-kluster i Azure Virtual Network, måste du konfigurera ditt Azure Virtual Network så att URL:en kan matchas med gatewayens privata IP-adress som används av HDInsight.Från Azure-portalen öppnar du det virtuella nätverket som HDInsight finns i. Öppna nätverksgränssnittet med namnet som börjar med
nic-gateway-0. Skriv ned dess privata IP-adress. Till exempel 10.6.0.15.Om din Azure Virtual Network har en DNS-server uppdaterar du DNS-posten så HDInsight-klustrets URL
https://<clustername>.azurehdinsight.netkan matchas mot10.6.0.15. Detta är den rekommenderade metoden. Om du inte har någon DNS-server i Azure Virtual Network kan du tillfälligt lösa detta genom att redigera värdfilen (C:\Windows\System32\drivers\etc) för alla virtuella datorer som är registrerade som noder för lokal installation av Integration Runtime genom att lägga till en post så här:10.6.0.15 myHDIClusterName.azurehdinsight.net
Skapa länkade tjänster
Växla till den mapp där du skapade JSON-filerna i PowerShell och kör följande kommando för att distribuera de länkade tjänsterna:
Växla till den mapp i PowerShell där du skapade JSON-filerna.
Kör följande kommando för att skapa en länkad Azure Storage-tjänst.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyStorageLinkedService" -File "MyStorageLinkedService.json"Kör följande kommando för att skapa en länkad Azure HDInsight-tjänst.
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "MyHDInsightLinkedService" -File "MyHDInsightLinkedService.json"
Skapa en pipeline
I det här steget kan du skapa en ny pipeline med en Hive-aktivitet. Aktiviteten kör Hive-skript för att returnera data från en exempeltabell och spara dem till en sökväg som du har definierat. Skapa en JSON-fil med önskat redigeringsprogram, kopiera följande JSON-definition för en pipelinedefinition och spara filen som MyHivePipeline.json.
{
"name": "MyHivePipeline",
"properties": {
"activities": [
{
"name": "MyHiveActivity",
"type": "HDInsightHive",
"linkedServiceName": {
"referenceName": "MyHDILinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptPath": "adftutorial\\hivescripts\\hivescript.hql",
"getDebugInfo": "Failure",
"defines": {
"Output": "wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/"
},
"scriptLinkedService": {
"referenceName": "MyStorageLinkedService",
"type": "LinkedServiceReference"
}
}
}
]
}
}
Observera följande:
- scriptPath pekar på sökvägen till Hive-skriptet i Azure Storage-kontot du använde för MyStorageLinkedService. Sökvägen är skiftlägeskänslig.
- Utdata är ett argument som används i Hive-skriptet. Använd formatet
wasb://<Container>@<StorageAccount>.blob.core.windows.net/outputfolder/för att peka på en befintlig mapp i Azure Storage. Sökvägen är skiftlägeskänslig.
Växla till den mapp där du skapade JSON-filerna och kör följande kommando för att distribuera dessa länkade pipelines:
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name $pipelineName -File "MyHivePipeline.json"
Starta pipelinen
Starta en pipelinekörning. Den samlar även in pipelinekörningens ID för kommande övervakning.
$runId = Invoke-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineName $pipelineNameKör följande skript för att kontinuerligt kontrollera pipelinekörningens status tills den är klar.
while ($True) { $result = Get-AzDataFactoryV2ActivityRun -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -PipelineRunId $runId -RunStartedAfter (Get-Date).AddMinutes(-30) -RunStartedBefore (Get-Date).AddMinutes(30) if(!$result) { Write-Host "Waiting for pipeline to start..." -foregroundcolor "Yellow" } elseif (($result | Where-Object { $_.Status -eq "InProgress" } | Measure-Object).count -ne 0) { Write-Host "Pipeline run status: In Progress" -foregroundcolor "Yellow" } else { Write-Host "Pipeline '"$pipelineName"' run finished. Result:" -foregroundcolor "Yellow" $result break } ($result | Format-List | Out-String) Start-Sleep -Seconds 15 } Write-Host "Activity `Output` section:" -foregroundcolor "Yellow" $result.Output -join "`r`n" Write-Host "Activity `Error` section:" -foregroundcolor "Yellow" $result.Error -join "`r`n"Här är utdata från exempelkörningen:
Pipeline run status: In Progress ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 000000000-0000-0000-000000000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : DurationInMs : Status : InProgress Error : Pipeline ' MyHivePipeline' run finished. Result: ResourceGroupName : ADFV2SampleRG2 DataFactoryName : SampleV2DataFactory2 ActivityName : MyHiveActivity PipelineRunId : 0000000-0000-0000-0000-000000000000 PipelineName : MyHivePipeline Input : {getDebugInfo, scriptPath, scriptLinkedService, defines} Output : {logLocation, clusterInUse, jobId, ExecutionProgress...} LinkedServiceName : ActivityRunStart : 9/18/2017 6:58:13 AM ActivityRunEnd : 9/18/2017 6:59:16 AM DurationInMs : 63636 Status : Succeeded Error : {errorCode, message, failureType, target} Activity Output section: "logLocation": "wasbs://adfjobs@adfv2samplestor.blob.core.windows.net/HiveQueryJobs/000000000-0000-47c3-9b28-1cdc7f3f2ba2/18_09_2017_06_58_18_023/Status" "clusterInUse": "https://adfv2HivePrivate.azurehdinsight.net" "jobId": "job_1505387997356_0024" "ExecutionProgress": "Succeeded" "effectiveIntegrationRuntime": "MySelfhostedIR" Activity Error section: "errorCode": "" "message": "" "failureType": "" "target": "MyHiveActivity"Titta i mappen
outputfolderefter filen som skapades som Hive-frågeresultat. Det bör se ut så här:8 en-US SCH-i500 California 23 en-US Incredible Pennsylvania 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 212 en-US SCH-i500 New York 246 en-US SCH-i500 District Of Columbia 246 en-US SCH-i500 District Of Columbia
Relaterat innehåll
I den här självstudiekursen fick du:
- Skapa en datafabrik.
- Skapa och konfigurera Integration Runtime med egen värd
- Skapa och distribuera länkade tjänster.
- Skapa och distribuera en pipeline som innehåller en Hive-aktivitet.
- Starta en pipelinekörning.
- Övervaka pipelinekörningen
- verifiera utdata.
Fortsätt till följande självstudie och lär dig att transformera data med ett Spark-kluster på Azure: