Kopiera data stegvis från Azure SQL Database till Blob Storage med hjälp av ändringsspårning i Azure Portal
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I en dataintegrationslösning är stegvis inläsning av data efter den första datainläsningen ett vanligt scenario. Ändrade data inom en period i källdatalagret kan enkelt segmenteras (till exempel LastModifyTime, CreationTime). Men i vissa fall finns det inget explicit sätt att identifiera deltadata från den senaste gången du bearbetade data. Du kan använda teknik för ändringsspårning som stöds av datalager som Azure SQL Database och SQL Server för att identifiera deltadata.
I den här självstudien beskrivs hur du använder Azure Data Factory med ändringsspårning för att inkrementellt läsa in deltadata från Azure SQL Database till Azure Blob Storage. Mer information om ändringsspårning finns i Ändringsspårning i SQL Server.
I de här självstudierna går du igenom följande steg:
- Förbered källdatalagret.
- Skapa en datafabrik.
- Skapa länkade tjänster.
- Skapa datamängder för källa, mottagare och spårning av ändringar.
- Skapa, köra och övervaka den fullständiga kopieringspipelinen.
- Lägga till eller uppdatera data i källtabellen.
- Skapa, köra och övervaka pipelinen för inkrementell kopiering.
Lösning på hög nivå
I den här självstudien skapar du två pipelines som utför följande åtgärder.
Kommentar
I den här självstudien används Azure SQL Database som källdatalager. Du kan också använda SQL Server.
Inledande inläsning av historiska data: Du skapar en pipeline med en kopieringsaktivitet som kopierar hela data från källdatalagret (Azure SQL Database) till måldatalagret (Azure Blob Storage):
- Aktivera teknik för ändringsspårning i källdatabasen i Azure SQL Database.
- Hämta det initiala värdet
SYS_CHANGE_VERSIONför i databasen som baslinje för att samla in ändrade data. - Läs in fullständiga data från källdatabasen till Azure Blob Storage.

Inkrementell inläsning av deltadata enligt ett schema: Du skapar en pipeline med följande aktiviteter och kör den regelbundet:
Skapa två uppslagsaktiviteter för att hämta gamla och nya
SYS_CHANGE_VERSIONvärden från Azure SQL Database.Skapa en kopieringsaktivitet för att kopiera infogade, uppdaterade eller borttagna data (deltadata) mellan de två
SYS_CHANGE_VERSIONvärdena från Azure SQL Database till Azure Blob Storage.Du läser in deltadata genom att koppla de primära nycklarna till ändrade rader (mellan två
SYS_CHANGE_VERSIONvärden) frånsys.change_tracking_tablesmed data i källtabellen och sedan flytta deltadata till målet.Skapa en lagrad proceduraktivitet för att uppdatera värdet
SYS_CHANGE_VERSIONför för nästa pipelinekörning.

Förutsättningar
- Azure-prenumeration. Om du inte har ett konto kan du skapa ett kostnadsfritt konto innan du börjar.
- Azure SQL Database. Du använder en databas i Azure SQL Database som källdatalager . Om du inte har någon kan du läsa Skapa en databas i Azure SQL Database för steg för att skapa den.
- Azure Storage-konto. Du använder Blob Storage som datalager för mottagare . Om du inte har något Azure Storage-konto kan du läsa Skapa ett lagringskonto för steg för att skapa ett. Skapa en container med namnet adftutorial.
Kommentar
Vi rekommenderar att du använder Azure Az PowerShell-modulen för att interagera med Azure. Se Installera Azure PowerShell för att komma igång. Information om hur du migrerar till Az PowerShell-modulen finns i artikeln om att migrera Azure PowerShell från AzureRM till Az.
Skapa en datakällatabell i Azure SQL Database
Öppna SQL Server Management Studio och anslut till SQL Database.
Högerklicka på databasen i Server Explorer och välj sedan Ny fråga.
Kör följande SQL-kommando mot databasen för att skapa en tabell med namnet
data_source_tablesom källdatalager:create table data_source_table ( PersonID int NOT NULL, Name varchar(255), Age int PRIMARY KEY (PersonID) ); INSERT INTO data_source_table (PersonID, Name, Age) VALUES (1, 'aaaa', 21), (2, 'bbbb', 24), (3, 'cccc', 20), (4, 'dddd', 26), (5, 'eeee', 22);Aktivera ändringsspårning i databasen och källtabellen (
data_source_table) genom att köra följande SQL-fråga.Kommentar
- Ersätt
<your database name>med namnet på databasen i Azure SQL Database som hardata_source_table. - Ändrade data sparas i två dagar i det aktuella exemplet. Om du läser in ändrade data ungefär var tredje dag eller oftare inkluderas inte en del ändrade data. Du måste antingen ändra värdet
CHANGE_RETENTIONför till ett större tal eller se till att perioden för att läsa in ändrade data är inom två dagar. Mer information finns i Aktivera ändringsspårning för en databas.
ALTER DATABASE <your database name> SET CHANGE_TRACKING = ON (CHANGE_RETENTION = 2 DAYS, AUTO_CLEANUP = ON) ALTER TABLE data_source_table ENABLE CHANGE_TRACKING WITH (TRACK_COLUMNS_UPDATED = ON)- Ersätt
Skapa en ny tabell och lagringsplats med namnet
ChangeTracking_versionmed ett standardvärde genom att köra följande fråga:create table table_store_ChangeTracking_version ( TableName varchar(255), SYS_CHANGE_VERSION BIGINT, ); DECLARE @ChangeTracking_version BIGINT SET @ChangeTracking_version = CHANGE_TRACKING_CURRENT_VERSION(); INSERT INTO table_store_ChangeTracking_version VALUES ('data_source_table', @ChangeTracking_version)Kommentar
Om data inte ändras när du har aktiverat ändringsspårning för SQL Database är
0värdet för ändringsspårningsversionen .Kör följande fråga för att skapa en lagrad procedur i databasen. Pipelinen anropar den här lagrade proceduren för att uppdatera ändringsspårningsversionen i tabellen som du skapade i föregående steg.
CREATE PROCEDURE Update_ChangeTracking_Version @CurrentTrackingVersion BIGINT, @TableName varchar(50) AS BEGIN UPDATE table_store_ChangeTracking_version SET [SYS_CHANGE_VERSION] = @CurrentTrackingVersion WHERE [TableName] = @TableName END
Skapa en datafabrik
Öppna webbläsaren Microsoft Edge eller Google Chrome. För närvarande stöder endast dessa webbläsare användargränssnittet (UI) för Data Factory.
I Azure Portal går du till den vänstra menyn och väljer Skapa en resurs.
Välj Integration>Data Factory.
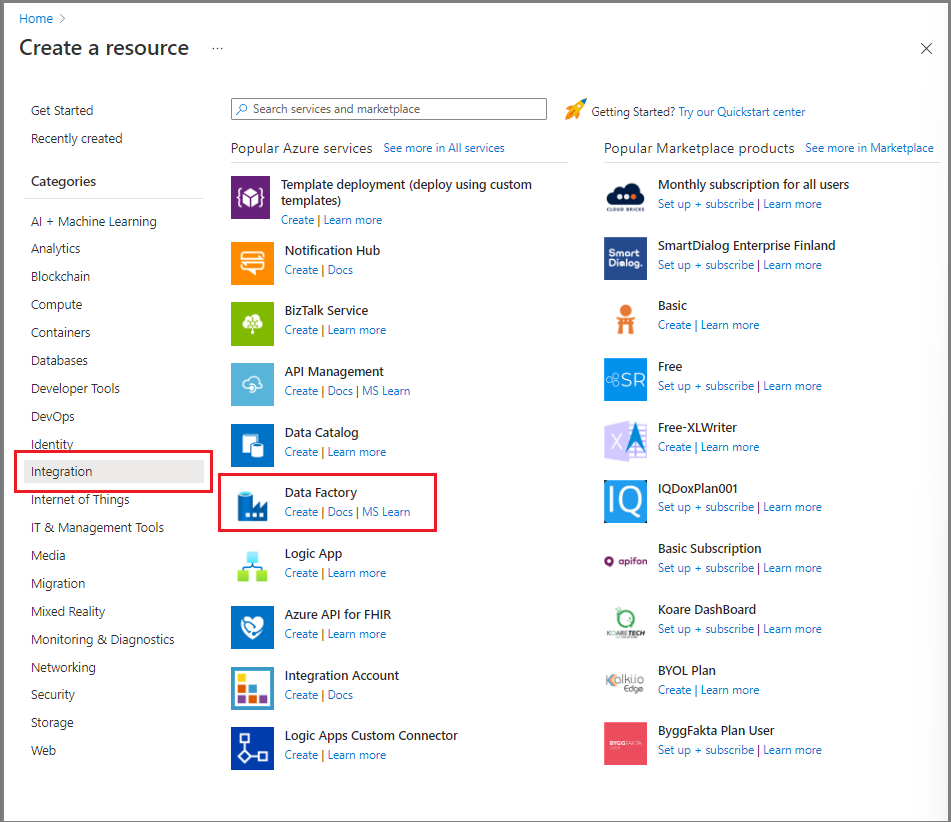
På sidan Ny datafabrik anger du ADFTutorialDataFactory som namn.
Namnet på datafabriken måste vara globalt unikt. Om du får ett felmeddelande om att namnet som du valde inte är tillgängligt ändrar du namnet (till exempel till dittnamnADFTutorialDataFactory) och försöker skapa datafabriken igen. Mer information finns i Namngivningsregler för Azure Data Factory.
Välj den Azure-prenumeration som du vill skapa den nya datafabriken i.
Gör något av följande för Resursgrupp:
- Välj Använd befintlig och välj sedan en befintlig resursgrupp i listrutan.
- Välj Skapa ny och ange sedan namnet på en resursgrupp.
Mer information om resursgrupper finns i Använda resursgrupper till att hantera Azure-resurser.
För Version väljer du V2.
För Region väljer du region för datafabriken.
Listrutan visar endast platser som stöds. Datalager (till exempel Azure Storage och Azure SQL Database) och beräkningar (till exempel Azure HDInsight) som en datafabrik använder kan finnas i andra regioner.
Välj Nästa: Git-konfiguration. Konfigurera lagringsplatsen genom att följa anvisningarna i Konfigurationsmetod 4: Markera kryssrutan Konfigurera Git senare när du skapar fabriken.
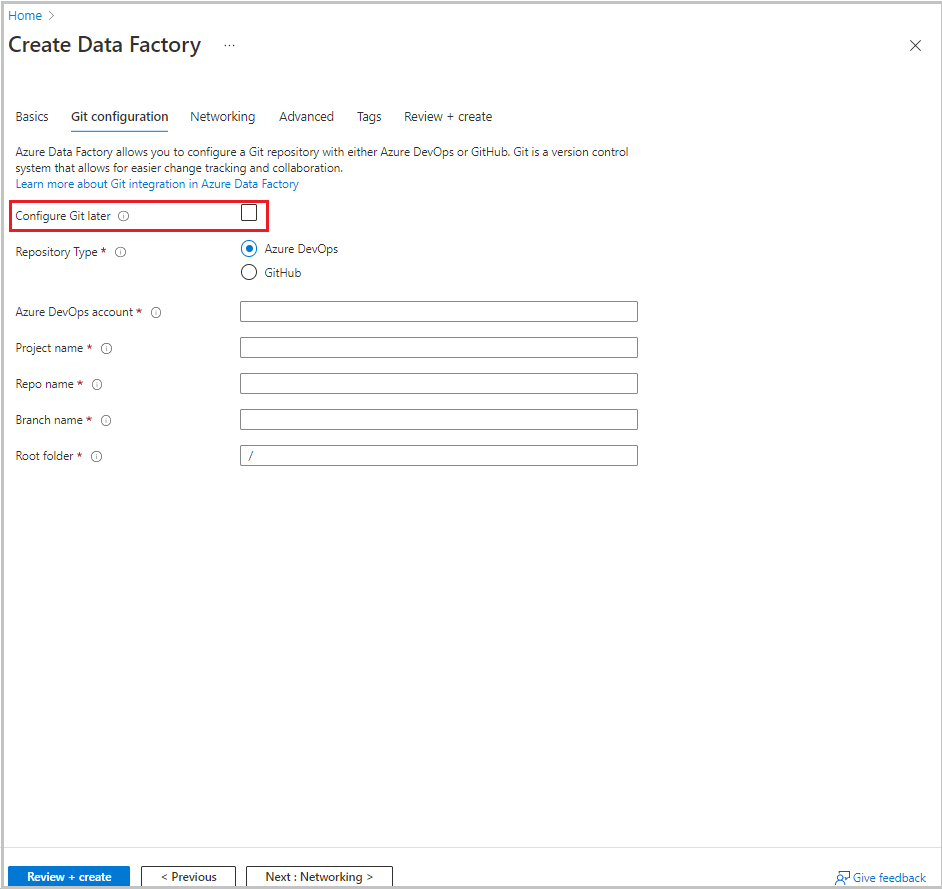
Välj Granska + skapa.
Välj Skapa.
På instrumentpanelen visar panelen Distribuera Data Factory status.

När skapandet är klart visas sidan Data Factory . Välj panelen Starta studio för att öppna Användargränssnittet för Azure Data Factory på en separat flik.
Skapa länkade tjänster
Du kan skapa länkade tjänster i en datafabrik för att länka ditt datalager och beräkna datafabrik-tjänster. I det här avsnittet skapar du länkade tjänster till ditt Azure Storage-konto och din databas i Azure SQL Database.
Skapa en länkad Azure Storage-tjänst
Så här länkar du ditt lagringskonto till datafabriken:
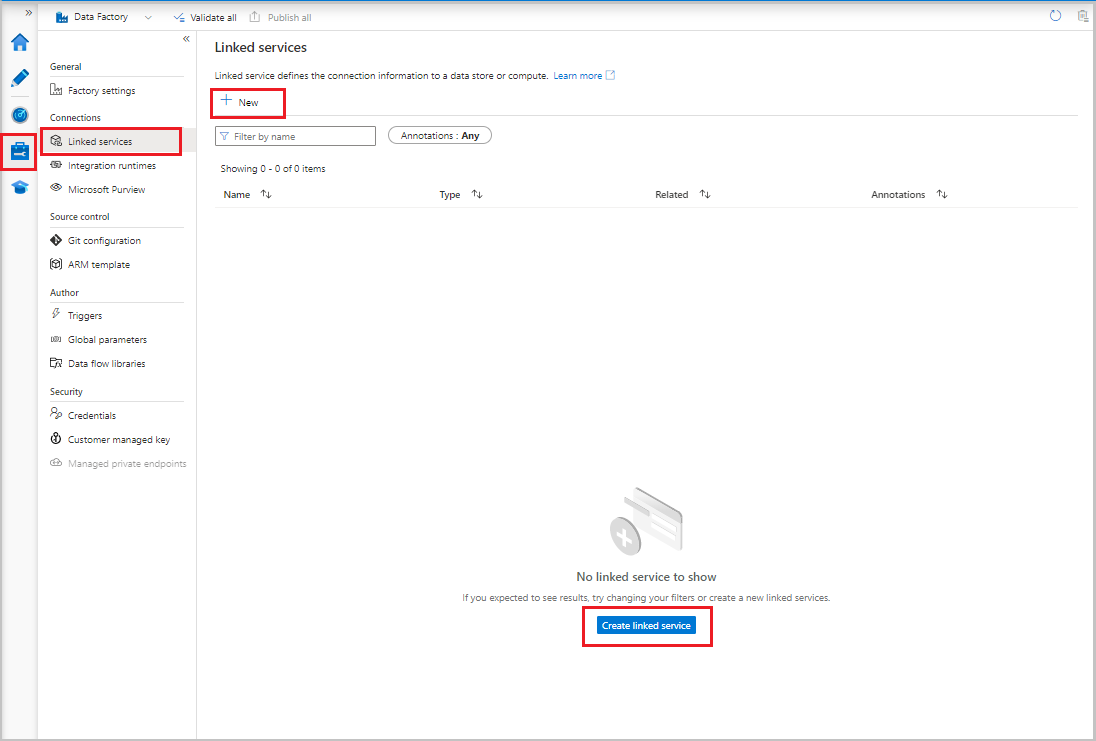
- I användargränssnittet för Data Factory går du till fliken Hantera och väljer Länkade tjänster under Anslutningar. Välj sedan + Ny eller knappen Skapa länkad tjänst .
- I fönstret Ny länkad tjänst väljer du Azure Blob Storage och sedan Fortsätt.
- Ange följande information:
- Som Namn anger du AzureStorageLinkedService.
- För Anslut via integrationskörning väljer du integrationskörningen.
- Som Autentiseringstyp väljer du en autentiseringsmetod.
- Som Lagringskontonamn väljer du ditt Azure-lagringskonto.
- Välj Skapa.
Skapa en länkad Azure SQL Database-tjänst
Så här länkar du databasen till datafabriken:
I användargränssnittet för Data Factory går du till fliken Hantera och väljer Länkade tjänster under Anslutningar. Välj sedan + Ny.
I fönstret Ny länkad tjänst väljer du Azure SQL Database och sedan Fortsätt.
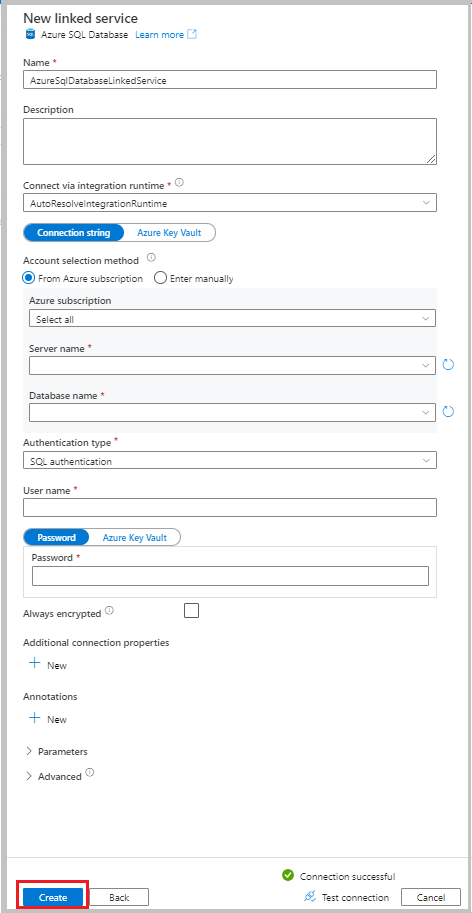
Ange följande information:
- Som Namn anger du AzureSqlDatabaseLinkedService.
- Som Servernamn väljer du din server.
- Som Databasnamn väljer du din databas.
- Som Autentiseringstyp väljer du en autentiseringsmetod. I den här självstudien används SQL-autentisering för demonstration.
- Som Användarnamn anger du namnet på användaren.
- För Lösenord anger du ett lösenord för användaren. Eller ange informationen för Azure Key Vault – länkad AKV-tjänst, hemligt namn och hemlig version.
Välj Testanslutning för att testa anslutningen.
Välj Skapa för att skapa den länkade tjänsten.
Skapa datauppsättningar
I det här avsnittet skapar du datauppsättningar som representerar datakällan och datamålet, tillsammans med platsen där värdena ska lagras SYS_CHANGE_VERSION .
Skapa en datauppsättning för att representera källdata
I användargränssnittet för Data Factory går du till fliken Författare och väljer plustecknet (+). Välj sedan Datauppsättning eller välj ellipsen för datauppsättningsåtgärder.
Välj Azure SQL Database och välj sedan Fortsätt.
I fönstret Ange egenskaper utför du följande steg:
- Som Namn anger du SourceDataset.
- För Länkad tjänst väljer du AzureSqlDatabaseLinkedService.
- Som Tabellnamn väljer du dbo.data_source_table.
- För Importera schema väljer du alternativet Från anslutning/arkiv .
- Välj OK.

Skapa en datauppsättning som representerar data som kopierats till datalagret för mottagare
I följande procedur skapar du en datauppsättning som representerar de data som kopieras från källdatalagret. Du skapade containern adftutorial i Azure Blob Storage som en del av förutsättningarna. Skapa containern om den inte finns, eller ställ in den för namnet på en befintlig. I den här självstudien genereras utdatafilens namn dynamiskt från uttrycket @CONCAT('Incremental-', pipeline().RunId, '.txt').
I användargränssnittet för Data Factory går du till fliken Författare och väljer +. Välj sedan Datauppsättning eller välj ellipsen för datauppsättningsåtgärder.
Välj Azure Blob Storage och välj sedan Fortsätt.
Välj formatet för datatypen som AvgränsadText och välj sedan Fortsätt.
I fönstret Ange egenskaper utför du följande steg:
- Som Namn anger du SinkDataset.
- För Länkad tjänst väljer du AzureBlobStorageLinkedService.
- För Filsökväg anger du adftutorial/incchgtracking.
- Välj OK.
När datauppsättningen visas i trädvyn går du till fliken Anslutning och väljer textrutan Filnamn . När alternativet Lägg till dynamiskt innehåll visas väljer du det.
Fönstret Pipeline expression builder (Pipelineuttrycksverktyget) visas. Klistra in
@concat('Incremental-',pipeline().RunId,'.csv')i textrutan.Välj OK.
Skapa en datauppsättning för att representera ändrad spårningsdata
I följande procedur skapar du en datauppsättning för lagring av ändringsspårningsversionen. Du skapade table_store_ChangeTracking_version tabellen som en del av förutsättningarna.
- I användargränssnittet för Data Factory går du till fliken Författare , väljer +och väljer sedan Datauppsättning.
- Välj Azure SQL Database och välj sedan Fortsätt.
- I fönstret Ange egenskaper utför du följande steg:
- Som Namn anger du ChangeTrackingDataset.
- För Länkad tjänst väljer du AzureSqlDatabaseLinkedService.
- Som Tabellnamn väljer du dbo.table_store_ChangeTracking_version.
- För Importera schema väljer du alternativet Från anslutning/arkiv .
- Välj OK.
Skapa en pipeline för hela kopian
I följande procedur skapar du en pipeline med en kopieringsaktivitet som kopierar hela data från källdatalagret (Azure SQL Database) till måldatalagret (Azure Blob Storage):
I användargränssnittet för Data Factory går du till fliken Författare, väljer +och väljer sedan Pipeline-pipeline>.
En ny flik visas för att konfigurera pipelinen. Pipelinen visas också i trädvyn. I fönstret Egenskaper ändrar du pipelinenamnet till FullCopyPipeline.
I verktygslådan Aktiviteter expanderar du Flytta och transformera. Utför något av följande steg:
- Dra kopieringsaktiviteten till pipelinedesignytan.
- I sökfältet under Aktiviteter söker du efter kopieringsdataaktiviteten och anger sedan namnet till FullCopyActivity.
Växla till fliken Källa . För Källdatauppsättning väljer du SourceDataset.
Växla till fliken Mottagare . För Datauppsättning för mottagare väljer du SinkDataset.
Om du vill verifiera pipelinedefinitionen väljer du Verifiera i verktygsfältet. Kontrollera att det inte finns några verifieringsfel. Stäng pipelinens valideringsutdata.
Om du vill publicera entiteter (länkade tjänster, datauppsättningar och pipelines) väljer du Publicera alla. Vänta tills du ser meddelandet om att entiteterna har publicerats.
Om du vill se meddelanden väljer du knappen Visa meddelanden .
Kör den fullständiga kopieringspipelinen
I användargränssnittet för Data Factory går du till verktygsfältet för pipelinen, väljer Lägg till utlösare och väljer sedan Utlösare nu.
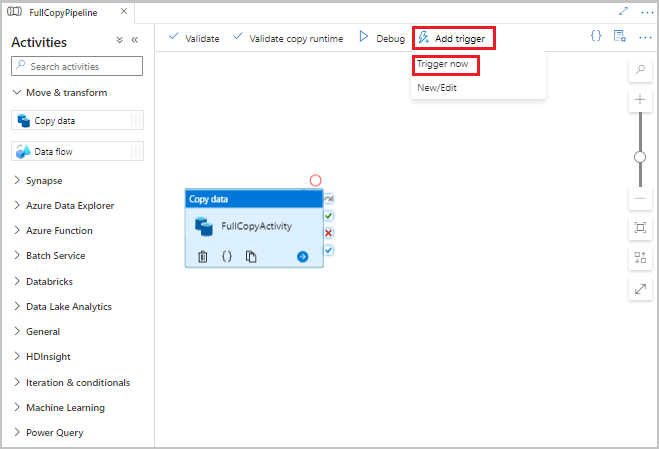
I fönstret Pipelinekörning väljer du OK.

Övervaka den fullständiga kopieringspipelinen
I användargränssnittet för Data Factory väljer du fliken Övervaka . Pipelinekörningen och dess status visas i listan. Om du vill uppdatera listan väljer du Uppdatera. Hovra över pipelinekörningen för att hämta alternativet Kör om eller förbrukning .
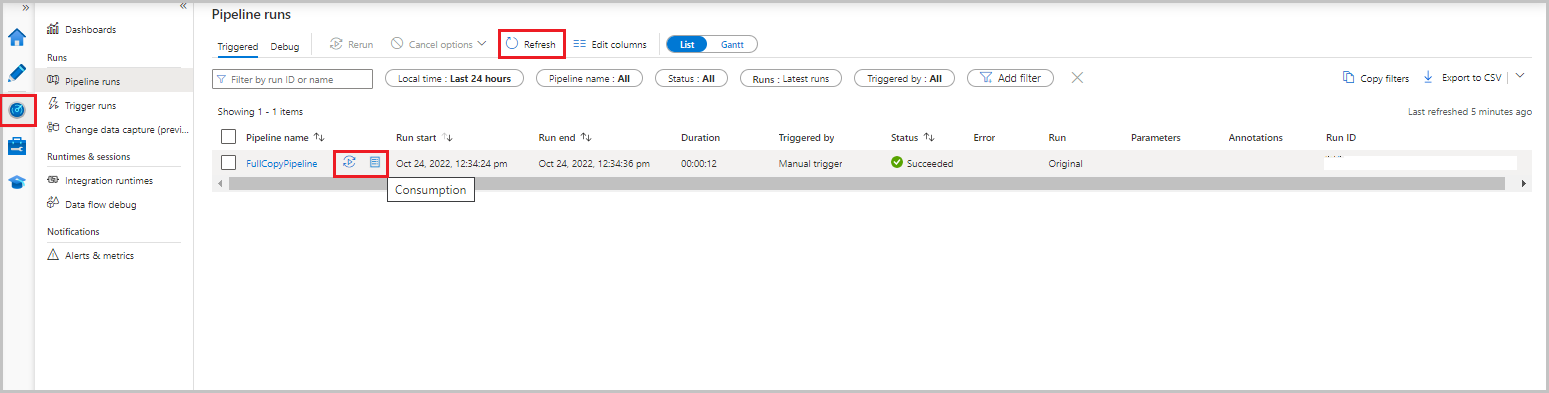
Om du vill visa aktivitetskörningar som är associerade med pipelinekörningen väljer du pipelinenamnet i kolumnen Pipelinenamn . Det finns bara en aktivitet i pipelinen, så det finns bara en post i listan. Om du vill växla tillbaka till vyn över pipelinekörningar väljer du länken Alla pipelinekörningar längst upp.
Granska resultaten
Mappen incchgtracking för containern adftutorial innehåller en fil med namnet incremental-<GUID>.csv.
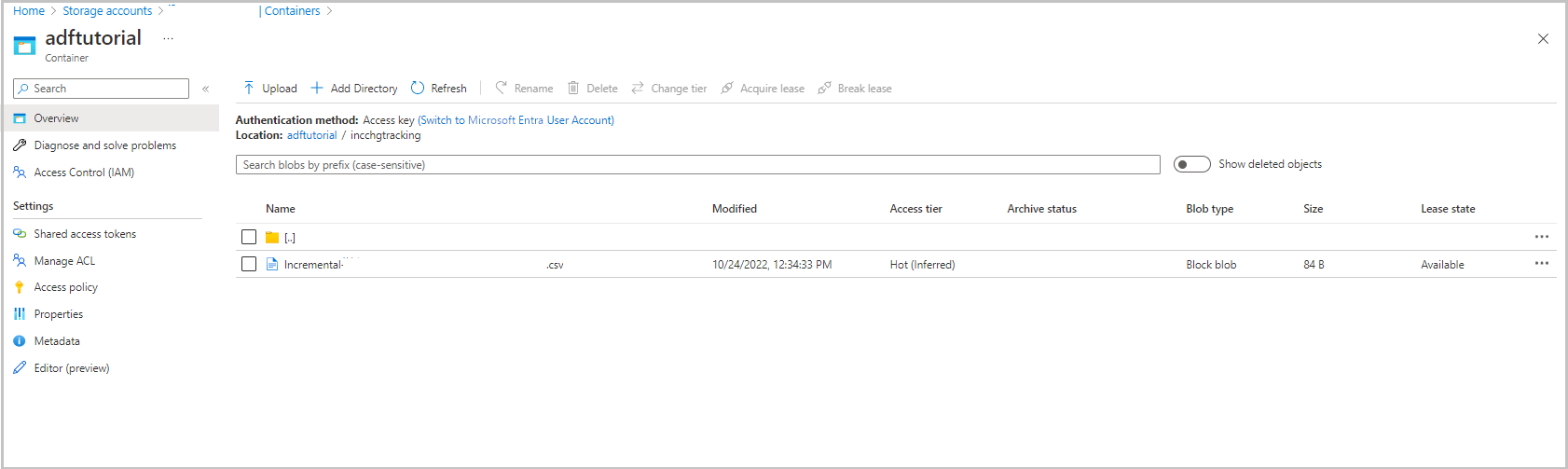
Filen ska ha data från databasen:
PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
5,eeee,PersonID,Name,Age
1,"aaaa",21
2,"bbbb",24
3,"cccc",20
4,"dddd",26
5,"eeee",22
Lägga till mer data i källtabellen
Kör följande fråga mot databasen för att lägga till en rad och uppdatera en rad:
INSERT INTO data_source_table
(PersonID, Name, Age)
VALUES
(6, 'new','50');
UPDATE data_source_table
SET [Age] = '10', [name]='update' where [PersonID] = 1
Skapa en pipeline för deltakopian
I följande procedur skapar du en pipeline med aktiviteter och kör den regelbundet. När du kör pipelinen:
- Uppslagsaktiviteterna hämtar gamla och nya
SYS_CHANGE_VERSIONvärden från Azure SQL Database och skickar dem till kopieringsaktiviteten. - Kopieringsaktiviteten kopierar infogade, uppdaterade eller borttagna data mellan de två
SYS_CHANGE_VERSIONvärdena från Azure SQL Database till Azure Blob Storage. - Aktiviteten lagrad procedur uppdaterar värdet
SYS_CHANGE_VERSIONför för nästa pipelinekörning.
I användargränssnittet för Data Factory växlar du till fliken Författare. Välj +och välj sedan Pipeline-pipeline>.
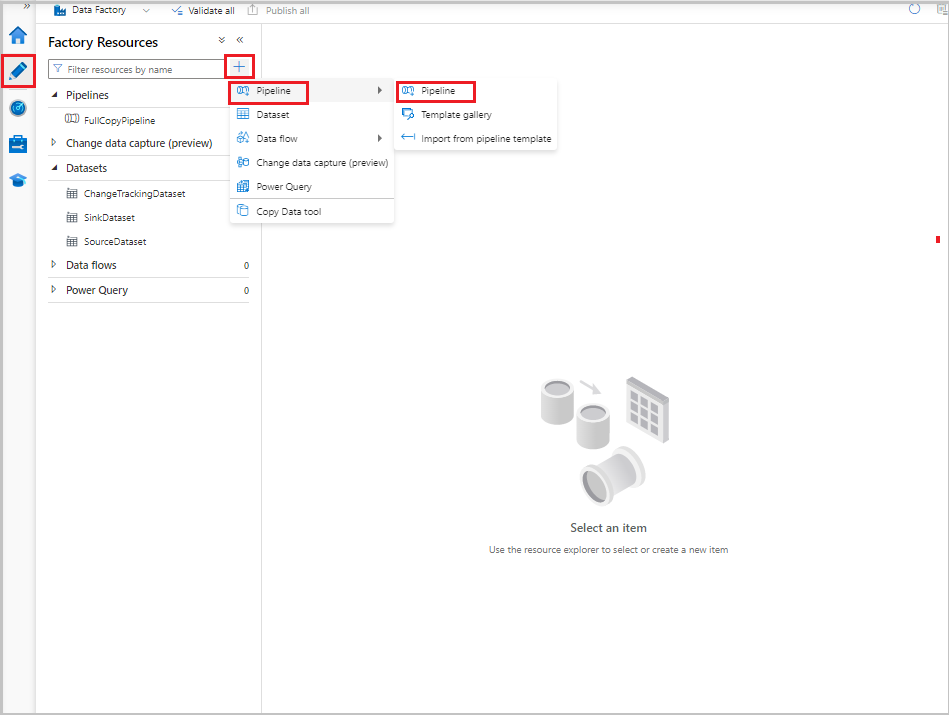
En ny flik visas för att konfigurera pipelinen. Pipelinen visas också i trädvyn. I fönstret Egenskaper ändrar du pipelinenamnet till IncrementalCopyPipeline.
Expandera Allmänt i verktygslådan Aktiviteter . Dra uppslagsaktiviteten till pipelinedesignerns yta eller sök i rutan Sökaktiviteter . Ange aktivitetens namn som LookupLastChangeTrackingVersionActivity. Den här aktiviteten hämtar ändringsspårningsversionen som användes i den senaste kopieringsåtgärden
table_store_ChangeTracking_versionsom lagras i tabellen.Växla till fliken Inställningar i fönstret Egenskaper . För Källdatauppsättning väljer du ChangeTrackingDataset.
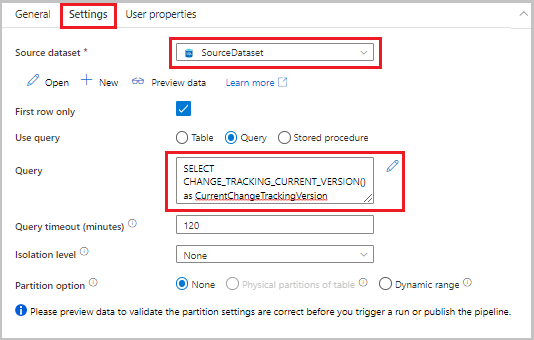
Dra uppslagsaktiviteten från verktygslådan Aktiviteter till pipelinedesignerns yta. Ange aktivitetens namn som LookupCurrentChangeTrackingVersionActivity. Den här aktiviteten hämtar den aktuella versionen för ändringsspårning.
Växla till fliken Inställningar i fönstret Egenskaper och utför sedan följande steg:
För Källdatauppsättning väljer du SourceDataset.
För Använd fråga väljer du Fråga.
För Fråga anger du följande SQL-fråga:
SELECT CHANGE_TRACKING_CURRENT_VERSION() as CurrentChangeTrackingVersion
I verktygslådan Aktiviteter expanderar du Flytta och transformera. Dra aktiviteten kopiera data till pipelinedesignerns yta. Ange IncrementalCopyActivity som namn på aktiviteten. Den här aktiviteten kopierar data mellan den senaste ändringsspårningsversionen och den aktuella ändringsspårningsversionen till måldatalagret.
Växla till fliken Källa i fönstret Egenskaper och utför sedan följande steg:
För Källdatauppsättning väljer du SourceDataset.
För Använd fråga väljer du Fråga.
För Fråga anger du följande SQL-fråga:
SELECT data_source_table.PersonID,data_source_table.Name,data_source_table.Age, CT.SYS_CHANGE_VERSION, SYS_CHANGE_OPERATION from data_source_table RIGHT OUTER JOIN CHANGETABLE(CHANGES data_source_table, @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.SYS_CHANGE_VERSION}) AS CT ON data_source_table.PersonID = CT.PersonID where CT.SYS_CHANGE_VERSION <= @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}
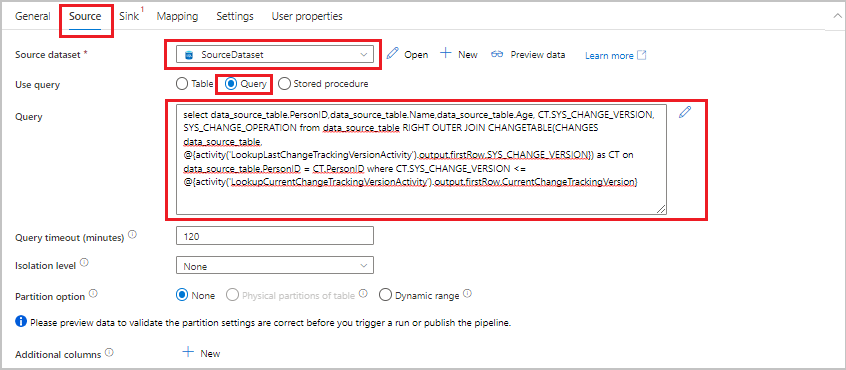
Växla till fliken Mottagare . För Datauppsättning för mottagare väljer du SinkDataset.
Anslut båda uppslagsaktiviteterna till kopieringsaktiviteten en i taget. Dra den gröna knappen som är kopplad till uppslagsaktiviteten till kopieringsaktiviteten.
Dra den lagrade proceduraktiviteten från verktygslådan Aktiviteter till pipelinedesignerns yta. Ange aktivitetens namn som StoredProceduretoUpdateChangeTrackingActivity. Den här aktiviteten uppdaterar ändringsspårningsversionen i
table_store_ChangeTracking_versiontabellen.Växla till fliken Inställningar och utför sedan följande steg:
- För Länkad tjänst väljer du AzureSqlDatabaseLinkedService.
- Som Namn på lagrad procedur väljer du Update_ChangeTracking_Version.
- Välj Importera.
- I avsnittet Parametrar för lagrad procedur anger du följande värden för parametrarna:
Namn Typ Värde CurrentTrackingVersionInt64 @{activity('LookupCurrentChangeTrackingVersionActivity').output.firstRow.CurrentChangeTrackingVersion}TableNameString @{activity('LookupLastChangeTrackingVersionActivity').output.firstRow.TableName}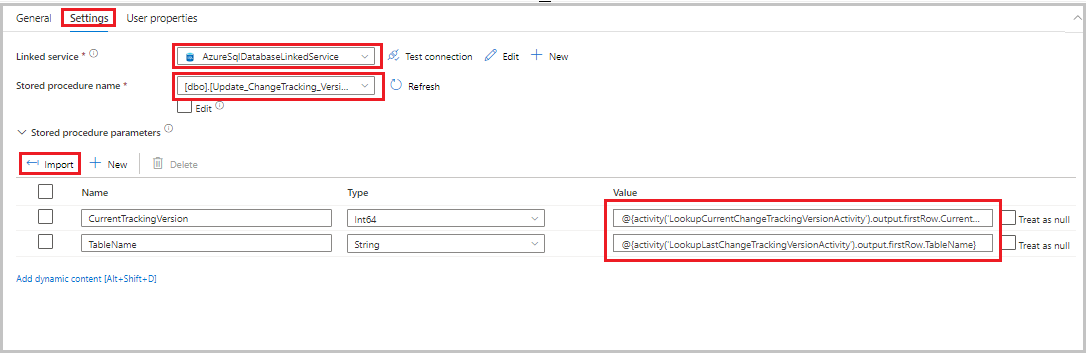
Anslut kopieringsaktiviteten till den lagrade procedureaktiviteten. Dra den gröna knappen som är kopplad till kopieringsaktiviteten till den lagrade procedureaktiviteten.
Välj Verifiera i verktygsfältet. Kontrollera att det inte finns några verifieringsfel. Stäng fönstret Pipelineverifieringsrapport .
Publicera entiteter (länkade tjänster, datauppsättningar och pipelines) till Data Factory-tjänsten genom att välja knappen Publicera alla . Vänta tills meddelandet Publiceringen lyckades visas.
Kör den inkrementella kopieringspipelinen
Välj Lägg till utlösare i verktygsfältet för pipelinen och välj sedan Utlösare nu.
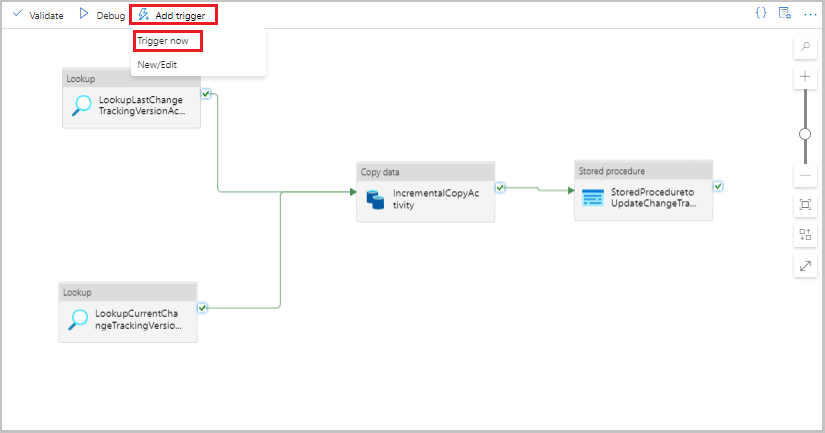
I fönstret PipelineKörning väljer du OK.
Övervaka den inkrementella kopieringspipelinen
Välj fliken Övervaka . Pipelinekörningen och dess status visas i listan. Om du vill uppdatera listan väljer du Uppdatera.
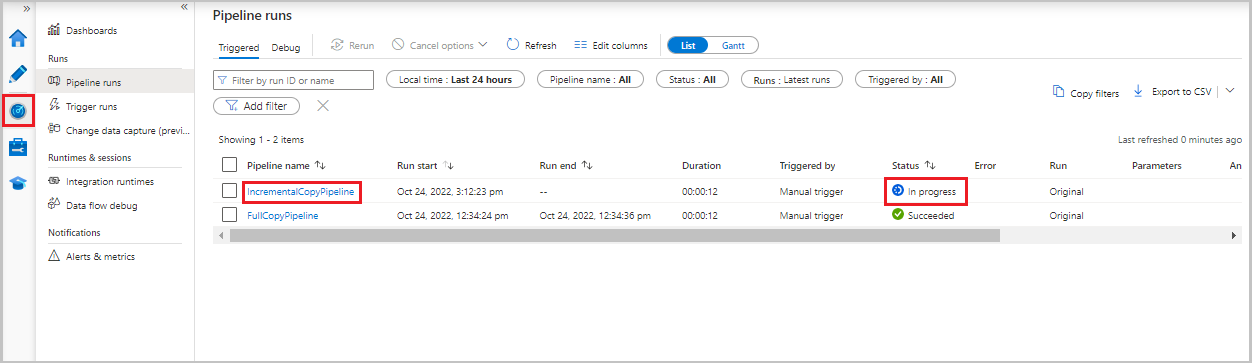
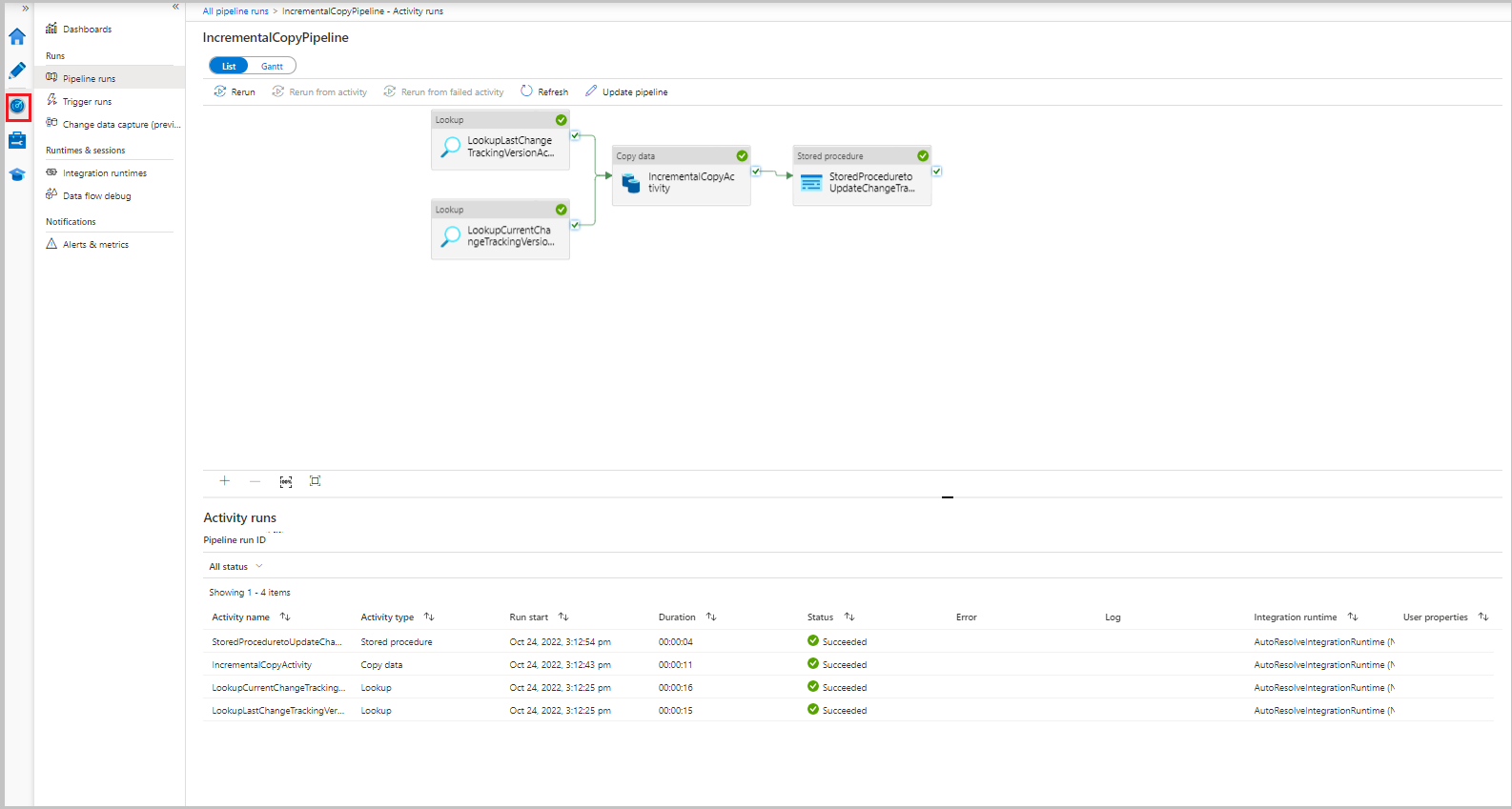
Om du vill visa aktivitetskörningar som är associerade med pipelinekörningen väljer du länken IncrementalCopyPipeline i kolumnen Pipelinenamn . Aktivitetskörningarna visas i en lista.
Granska resultaten
Den andra filen visas i mappen incchgtracking i containern adftutorial .
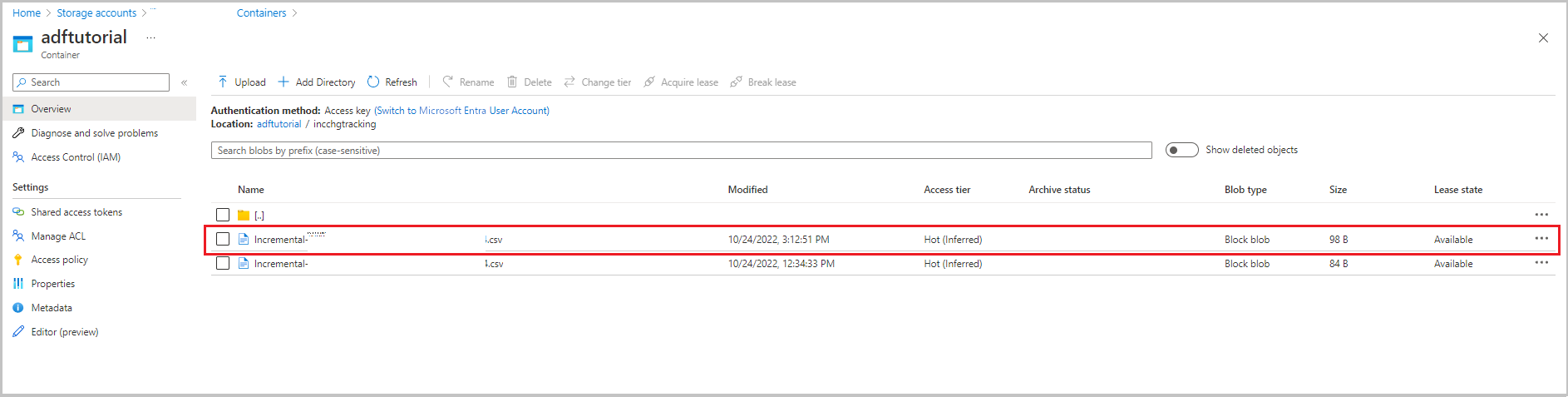
Filen ska bara ha deltadata från databasen. Posten med U är den uppdaterade raden i databasen och I är den rad som har lagts till.
PersonID,Name,Age,SYS_CHANGE_VERSION,SYS_CHANGE_OPERATION
1,update,10,2,U
6,new,50,1,I
De första tre kolumnerna ändras data från data_source_table. De två sista kolumnerna är metadata från tabellen för ändringsspårningssystemet. Den fjärde kolumnen är värdet SYS_CHANGE_VERSION för varje ändrad rad. Den femte kolumnen är åtgärden: U = update, I = insert. Mer information om ändringsspårningsinformation finns i CHANGETABLE.
==================================================================
PersonID Name Age SYS_CHANGE_VERSION SYS_CHANGE_OPERATION
==================================================================
1 update 10 2 U
6 new 50 1 I
Relaterat innehåll
Gå vidare till följande självstudie om du bara vill lära dig om att kopiera nya och ändrade filer baserat på LastModifiedDate: