Läs in data stegvis från Azure SQL Managed Instance till Azure Storage med hjälp av CDC (Change Data Capture)
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I den här självstudien skapar du en Azure-datafabrik med en pipeline som läser in deltadata baserat på CDC-information (Change Data Capture) i azure SQL Managed Instance-källdatabasen till en Azure Blob Storage.
I de här självstudierna går du igenom följande steg:
- Förbereda källdatalagret
- Skapa en datafabrik.
- Skapa länkade tjänster.
- Skapa datauppsättningar för källa och mottagare.
- Skapa, felsöka och kör pipelinen för att söka efter ändrade data
- Ändra data i källtabellen
- Slutför, kör och övervakar den fullständiga inkrementella kopieringspipelinen
Översikt
Tekniken Change Data Capture som stöds av datalager som Azure SQL Managed Instances (MI) och SQL Server kan användas för att identifiera ändrade data. I den här självstudien beskrivs hur du använder Azure Data Factory med SQL Change Data Capture-teknik för inkrementell inläsning av deltadata från Azure SQL Managed Instance till Azure Blob Storage. Mer konkret information om SQL Change Data Capture-teknik finns i Ändra datainsamling i SQL Server.
Arbetsflödet slutpunkt till slutpunkt
Här följer de vanliga stegen för arbetsflöden från slutpunkt till slutpunkt för inkrementell inläsning med hjälp av tekniken För ändringsdatainsamling.
Kommentar
Både Azure SQL MI och SQL Server stöder Change Data Capture-tekniken. I den här självstudien används Azure SQL Managed Instance som källdatalager. Du kan också använda en lokal SQL Server.
Lösning på hög nivå
I den här självstudien skapar du en pipeline som utför följande åtgärder:
- Skapa en uppslagsaktivitet för att räkna antalet ändrade poster i tabellen SQL Database CDC och skicka den till en IF Condition-aktivitet.
- Skapa ett if-villkor för att kontrollera om det finns ändrade poster och i så fall anropa kopieringsaktiviteten.
- Skapa en kopieringsaktivitet för att kopiera infogade/uppdaterade/borttagna data mellan CDC-tabellen till Azure Blob Storage.
Om du inte har någon Azure-prenumeration skapar du ett kostnadsfritt konto innan du börjar.
Förutsättningar
- Azure SQL Managed Instance. Du använder databasen som källa för datalagringen. Om du inte har någon Hanterad Azure SQL-instans kan du läsa artikeln Skapa en hanterad Azure SQL Database-instans för steg för att skapa en.
- Azure Storage-konto. Du kan använda blob-lagringen som mottagare för datalagringen. Om du inte har ett Azure Storage-konto finns det anvisningar om hur du skapar ett i artikeln Skapa ett lagringskonto . Skapa en container med namnet raw.
Skapa en datakällatabell i Azure SQL Database
Starta SQL Server Management Studio och anslut till din Azure SQL Managed Instances-server.
I Server Explorer högerklickar du på databasen och väljer Ny fråga.
Kör följande SQL-kommando mot din Azure SQL Managed Instances-databas för att skapa en tabell med namnet
customerssom datakälllager.create table customers ( customer_id int, first_name varchar(50), last_name varchar(50), email varchar(100), city varchar(50), CONSTRAINT "PK_Customers" PRIMARY KEY CLUSTERED ("customer_id") );Aktivera mekanismen för ändringsdatainsamling i databasen och källtabellen (kunder) genom att köra följande SQL-fråga:
Kommentar
- Ersätt <källschemanamnet> med schemat för din Azure SQL MI som har tabellen kunder.
- Ändringsdatainsamling gör ingenting som en del av de transaktioner som ändrar tabellen som spåras. I stället skrivs åtgärderna insert, update och delete till transaktionsloggen. Data som deponeras i ändringstabeller växer ohanterligt om du inte regelbundet och systematiskt rensar data. Mer information finns i Aktivera ändringsdatainsamling för en databas
EXEC sys.sp_cdc_enable_db EXEC sys.sp_cdc_enable_table @source_schema = 'dbo', @source_name = 'customers', @role_name = NULL, @supports_net_changes = 1Infoga data i kundtabellen genom att köra följande kommando:
insert into customers (customer_id, first_name, last_name, email, city) values (1, 'Chevy', 'Leward', 'cleward0@mapy.cz', 'Reading'), (2, 'Sayre', 'Ateggart', 'sateggart1@nih.gov', 'Portsmouth'), (3, 'Nathalia', 'Seckom', 'nseckom2@blogger.com', 'Portsmouth');Kommentar
Inga historiska ändringar i tabellen samlas in innan ändringsdatainsamling aktiveras.
Skapa en datafabrik
Följ stegen i artikeln Snabbstart: Skapa en datafabrik med hjälp av Azure Portal för att skapa en datafabrik om du inte redan har en att arbeta med.
Skapa länkade tjänster
Du kan skapa länkade tjänster i en datafabrik för att länka ditt datalager och beräkna datafabrik-tjänster. I det här avsnittet skapar du länkade tjänster till ditt Azure Storage-konto och Azure SQL MI.
Skapa en länkad Azure-lagringstjänst.
I det här steget länkar du ditt Azure-lagringskonto till datafabriken.
Klicka på Anslutningar och sedan på + Ny.
I fönstret New Linked Service (Ny länkad tjänst) väljer du Azure Blob Storage och klickar på Fortsätt.
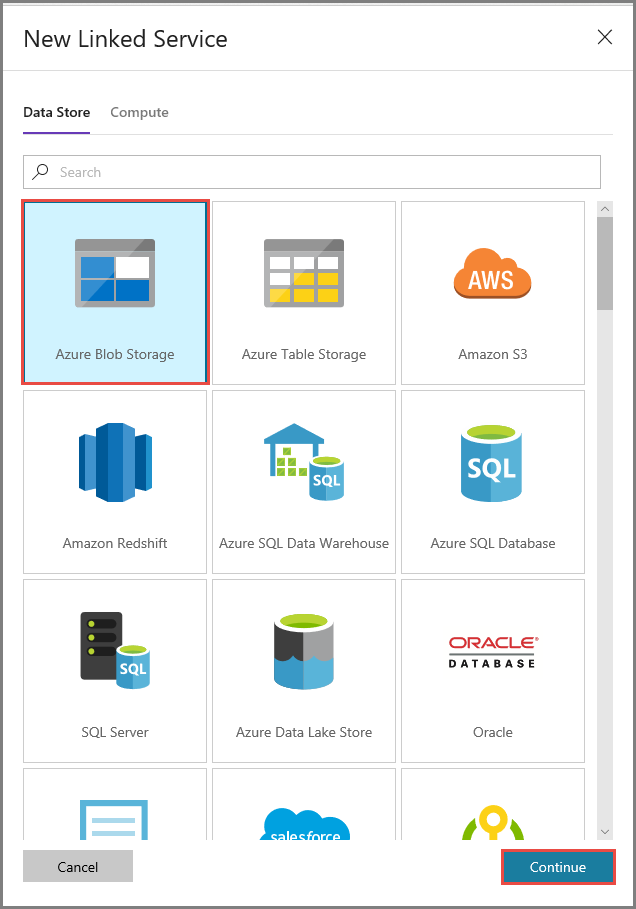
Utför följande steg i fönstret New Linked Service (Ny länkad tjänst):
- Ange AzureStorageLinkedService som namn.
- Välj ditt Azure Storage-konto i Lagringskontonamn.
- Klicka på Spara.
Skapa en länkad Azure SQL MI Database-tjänst.
I det här steget länkar du din Azure SQL MI-databas till datafabriken.
Kommentar
För dem som använder SQL MI, se här för information om åtkomst via offentlig eller privat slutpunkt. Om du använder en privat slutpunkt måste du köra den här pipelinen med hjälp av en lokalt installerad integrationskörning. Samma sak gäller för dem som kör SQL Server lokalt, i scenarier med virtuella datorer eller virtuella nätverk.
Klicka på Anslutningar och sedan på + Ny.
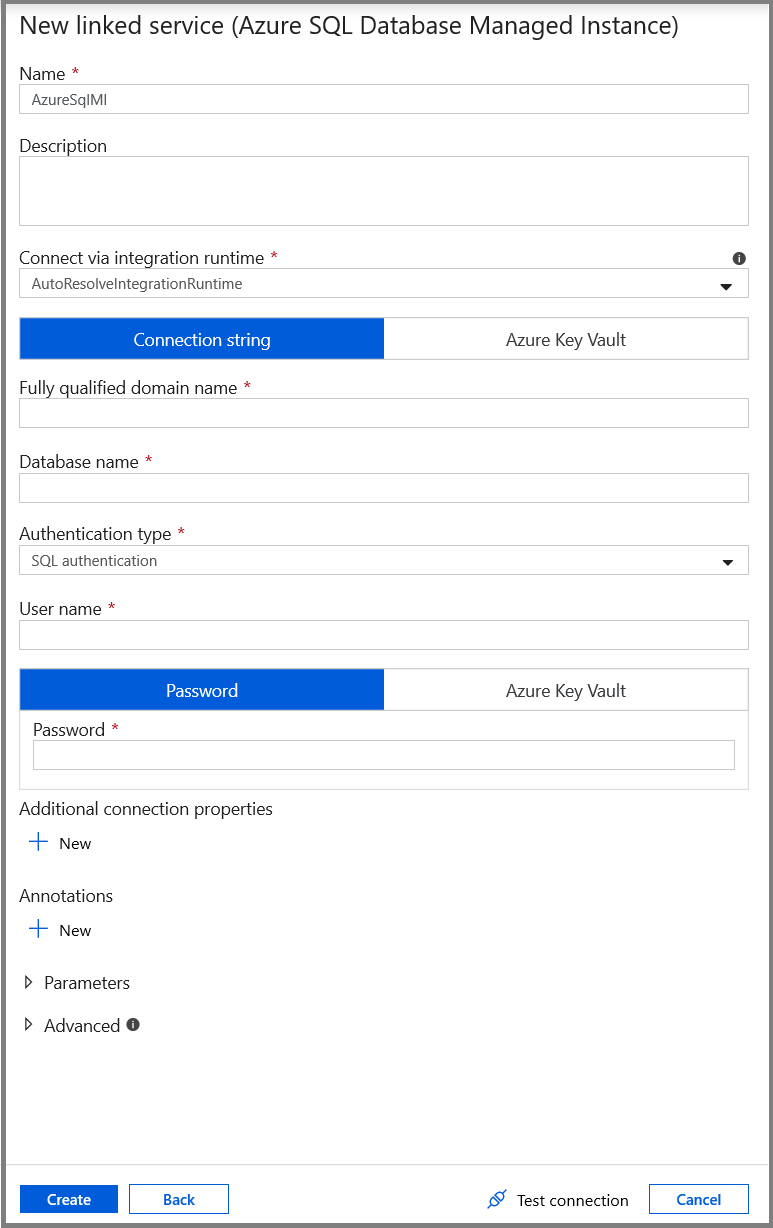
I fönstret Ny länkad tjänst väljer du Azure SQL Database Managed Instance och klickar på Fortsätt.
Utför följande steg i fönstret New Linked Service (Ny länkad tjänst):
- Ange AzureSqlMI1 som namnfält.
- Välj sql-servern för fältet Servernamn .
- Välj sql-databasen för fältet Databasnamn .
- Ange användarens namn i fältet Användarnamn.
- Ange användarens lösenord i fältet Lösenord.
- Testa anslutningen genom att klicka på Testa anslutning.
- Klicka på Spara för att spara den länkade tjänsten.
Skapa datauppsättningar
I det här steget skapar du datauppsättningar som representerar datakällan och datamålet.
Skapa en datauppsättning för att representera källdata
I det här steget skapar du en datamängd för att representera källdata.
I trädvyn klickar du på + (plus) och sedan på Datauppsättning.
Välj Azure SQL Database Managed Instance och klicka på Fortsätt.
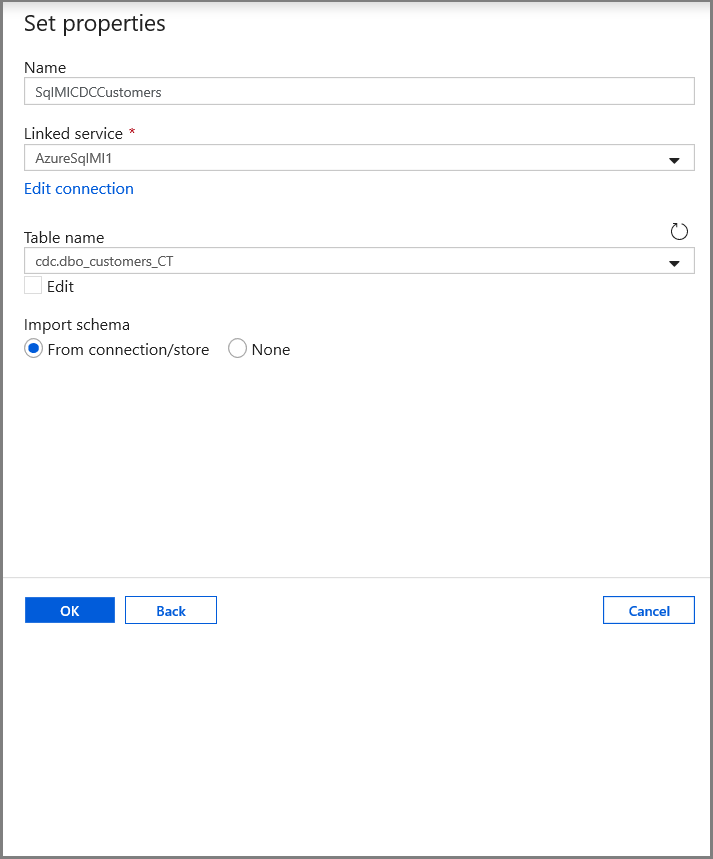
På fliken Ange egenskaper anger du datauppsättningens namn och anslutningsinformation:
- Välj AzureSqlMI1 för länkad tjänst.
- Välj [dbo].[ dbo_customers_CT] som Tabellnamn. Obs! Den här tabellen skapades automatiskt när CDC aktiverades i kundtabellen. Ändrade data efterfrågas aldrig direkt från den här tabellen, utan extraheras i stället via CDC-funktionerna.
Skapa en datauppsättning för att representera data som kopierats till datalagret för mottagare.
I det här steget skapar du en datamängd för att representera data som kopieras från källdatalagret. Du skapade data lake-containern i Azure Blob Storage som en del av förutsättningarna. Skapa containern om den inte finns (eller) ställ in den för namnet på en befintlig. I den här självstudien genereras utdatafilens namn dynamiskt med hjälp av utlösartiden, som kommer att konfigureras senare.
I trädvyn klickar du på + (plus) och sedan på Datauppsättning.
Välj Azure Blob Storage och klicka på Fortsätt.

Välj AvgränsadText och klicka på Fortsätt.

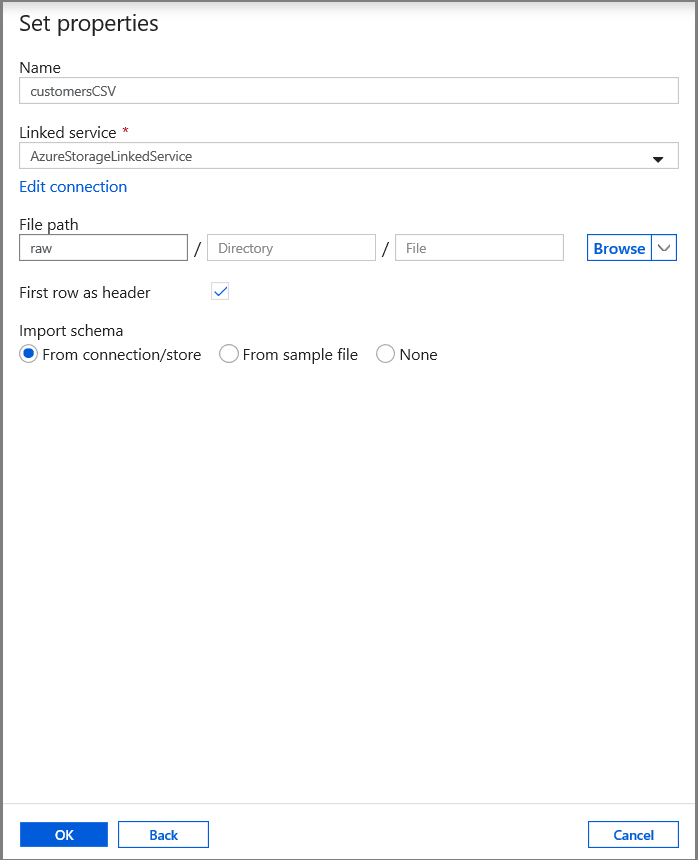
På fliken Ange egenskaper anger du datauppsättningens namn och anslutningsinformation:
- Välj AzureStorageLinkedService för Länkad tjänst.
- Ange raw för containerdelen av filePath.
- Aktivera första raden som rubrik
- Klicka på Ok
Skapa en pipeline för att kopiera ändrade data
I det här steget skapar du en pipeline som först kontrollerar antalet ändrade poster som finns i ändringstabellen med hjälp av en uppslagsaktivitet. En IF-villkorsaktivitet kontrollerar om antalet ändrade poster är större än noll och kör en kopieringsaktivitet för att kopiera infogade/uppdaterade/borttagna data från Azure SQL Database till Azure Blob Storage. Slutligen konfigureras en utlösare för rullande fönster och start- och sluttiderna skickas till aktiviteterna som start- och slutfönsterparametrar.
I användargränssnittet för Data Factory växlar du till fliken Redigera . Klicka på + (plus) i det vänstra fönstret och klicka på Pipeline.
En ny flik öppnas för inställningar för pipelinen. Du kan också se pipelinen i trädvyn. I fönstret Egenskaper ändrar du pipelinenamnet till IncrementalCopyPipeline.
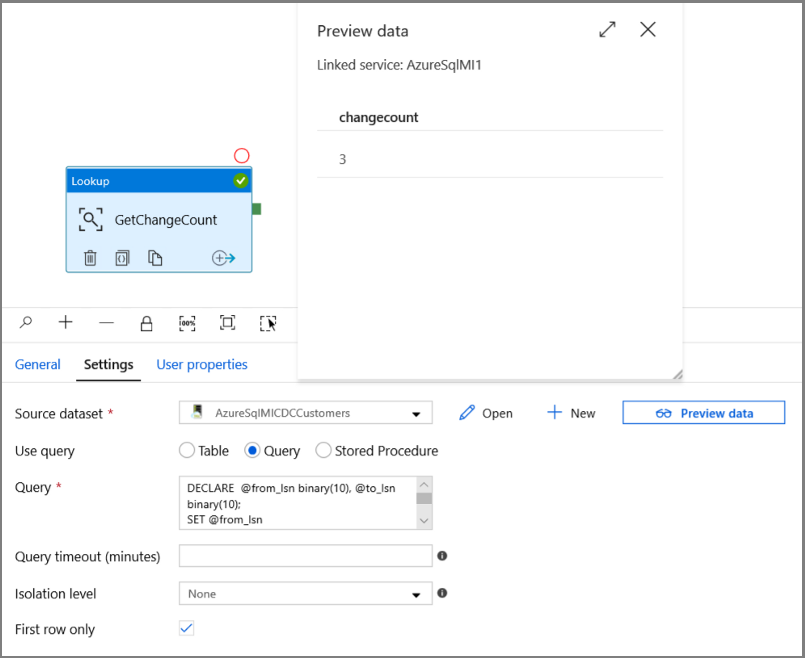
Visa verktygslådan Allmänt i verktygslådan Aktiviteter och dra och släpp sökningen på pipelinedesignytan. Ange namnet på aktiviteten till GetChangeCount. Den här aktiviteten hämtar antalet poster i ändringstabellen för ett visst tidsfönster.
Växla till Inställningar i fönstret Egenskaper :
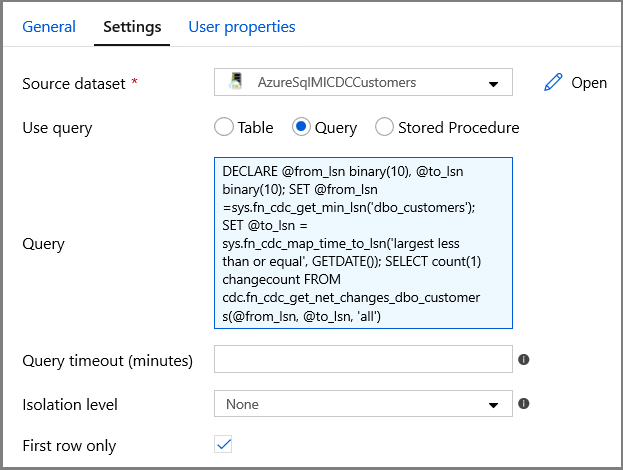
Ange SQL MI-datauppsättningens namn för fältet Källdatauppsättning .
Välj alternativet Fråga och ange följande i frågerutan:
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')- Aktivera endast första raden
Klicka på knappen Förhandsgranska data för att se till att ett giltigt utdata hämtas av uppslagsaktiviteten
Expandera Iteration och villkor i verktygslådan Aktiviteter och dra och släpp aktiviteten If Condition till pipelinedesignerns yta. Ange namnet på aktiviteten till HasChangedRows.
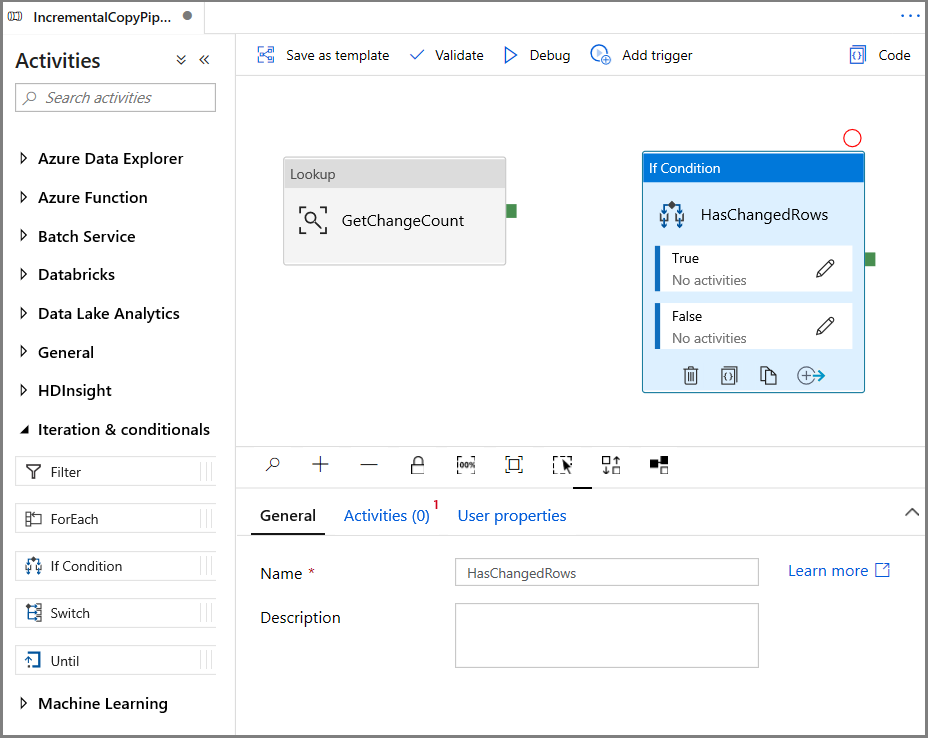
Växla till aktiviteterna i fönstret Egenskaper:
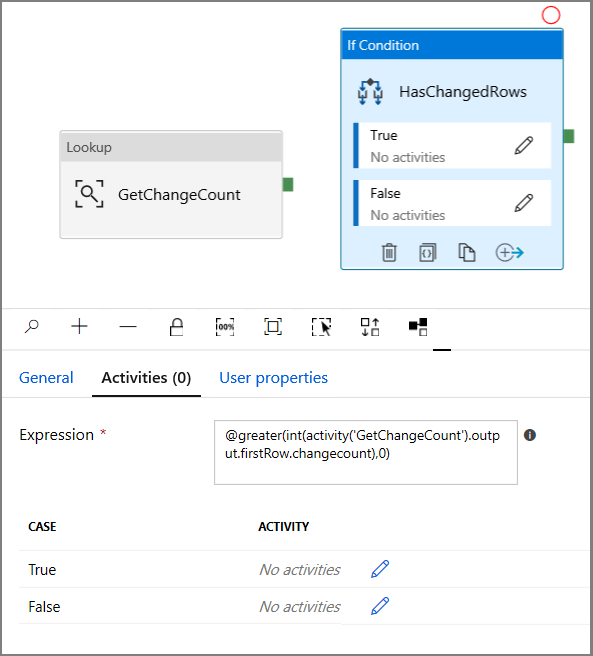
- Ange följande uttryck
@greater(int(activity('GetChangeCount').output.firstRow.changecount),0)- Klicka på pennikonen för att redigera villkoret Sant.
- Expandera Allmänt i verktygslådan Aktiviteter och dra och släpp en vänta-aktivitet till pipelinedesignytan. Det här är en tillfällig aktivitet för att felsöka villkoret If och ändras senare i självstudien.
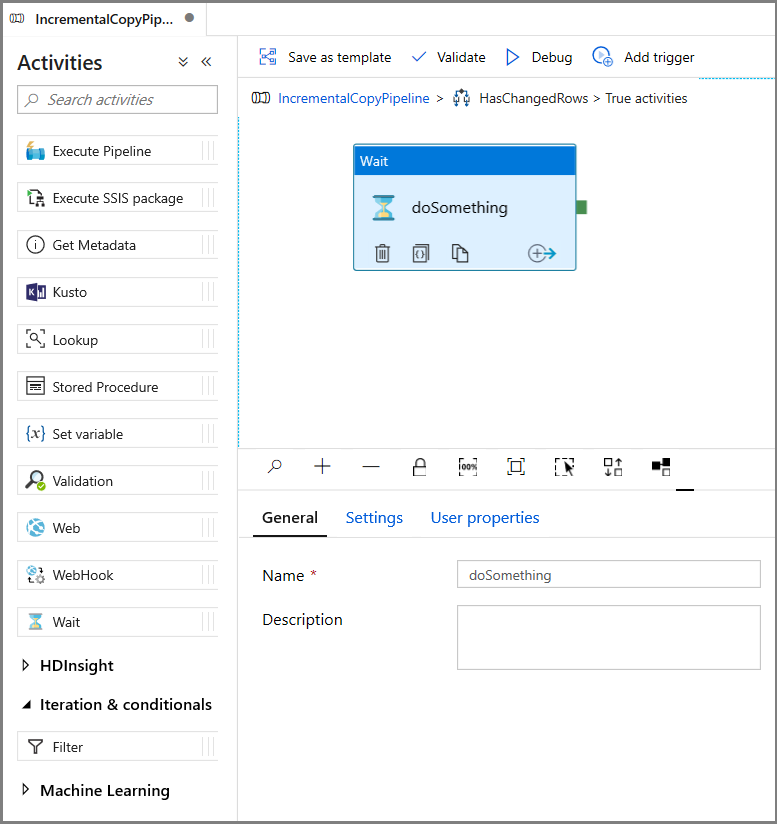
- Klicka på sökvägsrutan IncrementalCopyPipeline för att återgå till huvudpipelinen.
Kör pipelinen i felsökningsläge för att verifiera att pipelinen körs.
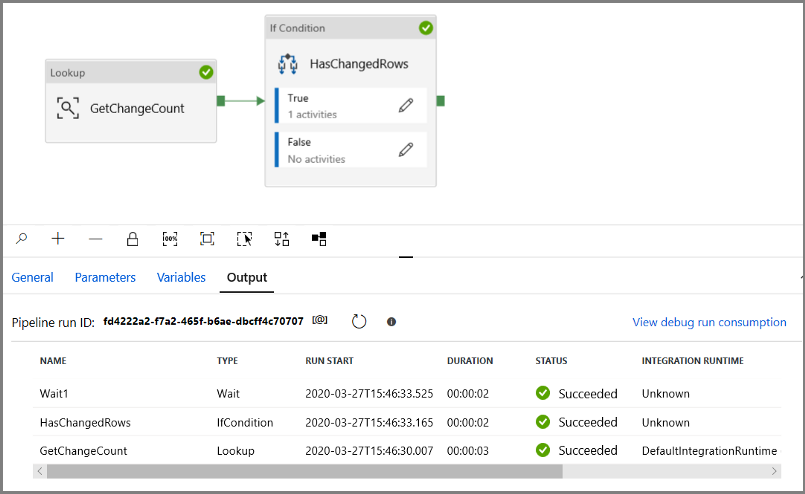
Gå sedan tillbaka till steget Sant villkor och ta bort aktiviteten Vänta . I verktygslådan Aktiviteter expanderar du Flytta och transformerar och drar och släpper en kopieringsaktivitet till pipelinedesignytan. Ange IncrementalCopyActivity som namn på aktiviteten.
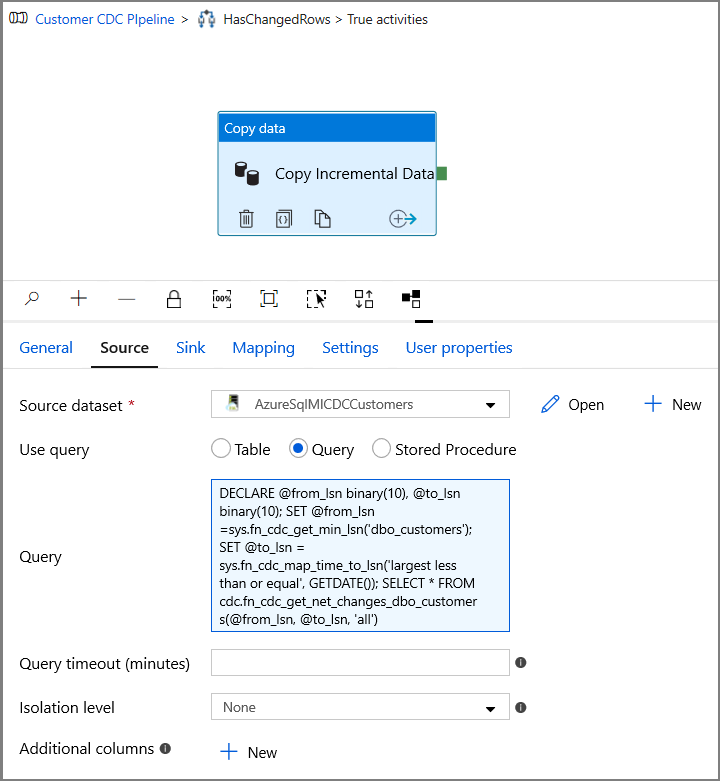
Växla till fliken Källa i fönstret Egenskaper och utför följande steg:
Ange SQL MI-datauppsättningens namn för fältet Källdatauppsättning .
Välj Fråga för Använd fråga.
Ange följande för Fråga.
DECLARE @from_lsn binary(10), @to_lsn binary(10); SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_customers'); SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE()); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, 'all')
Klicka på förhandsgranska för att kontrollera att frågan returnerar de ändrade raderna korrekt.
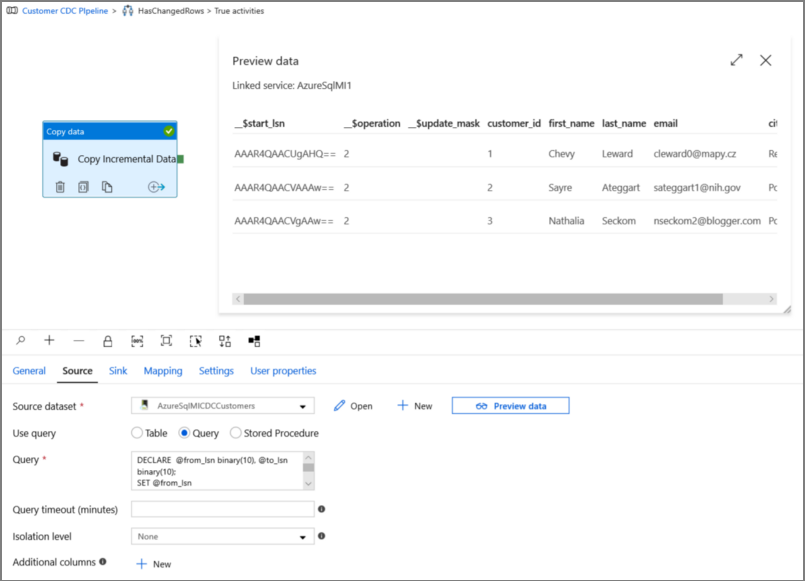
Växla till fliken Mottagare och ange Azure Storage-datauppsättningen för fältet Mottagardatauppsättning .

Klicka tillbaka till huvudarbetsytan för pipelinen och anslut uppslagsaktiviteten till if condition-aktiviteten en i taget. Dra den gröna knappen som är kopplad till uppslagsaktiviteten till if condition-aktiviteten .
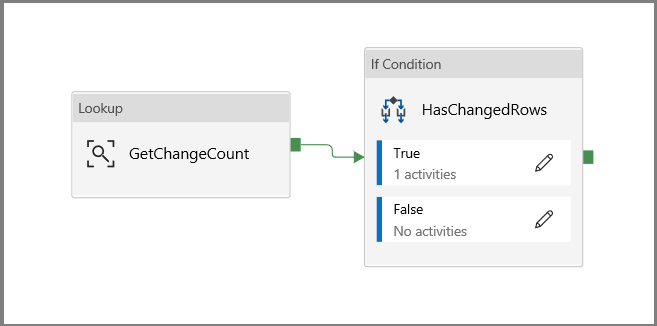
Klicka på Verifiera i verktygsfältet. Kontrollera att det inte finns några verifieringsfel. Stäng fönstret med verifieringsrapporten för pipeline genom att klicka på >>.
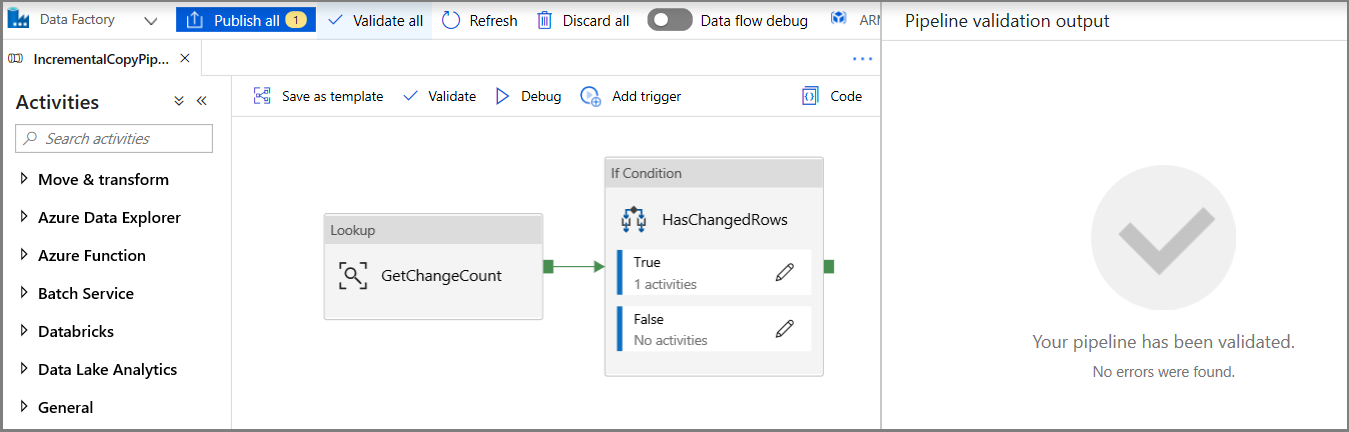
Klicka på Felsök för att testa pipelinen och kontrollera att en fil genereras på lagringsplatsen.
Publicera entiteter (länkade tjänster, datauppsättningar och pipelines) till Data Factory-tjänsten genom att klicka på knappen Publicera alla . Vänta tills du ser meddelandet Publiceringen är klar.
Konfigurera parametrarna för utlösare för rullande fönster och CDC-fönster
I det här steget skapar du en utlösare för rullande fönster för att köra jobbet enligt ett vanligt schema. Du använder systemvariablerna WindowStart och WindowEnd i utlösaren för rullande fönster och skickar dem som parametrar till din pipeline som ska användas i CDC-frågan.
Gå till fliken Parametrar i pipelinen IncrementalCopyPipeline och lägg till två parametrar (triggerStartTime och triggerEndTime) i pipelinen med knappen + Ny, vilket representerar start- och sluttiden för rullande fönster. I felsökningssyfte lägger du till standardvärden i formatet YYYY-MM-DD HH24:MI:SS.FFF , men se till att triggerStartTime inte är innan CDC aktiveras i tabellen, annars resulterar det i ett fel.
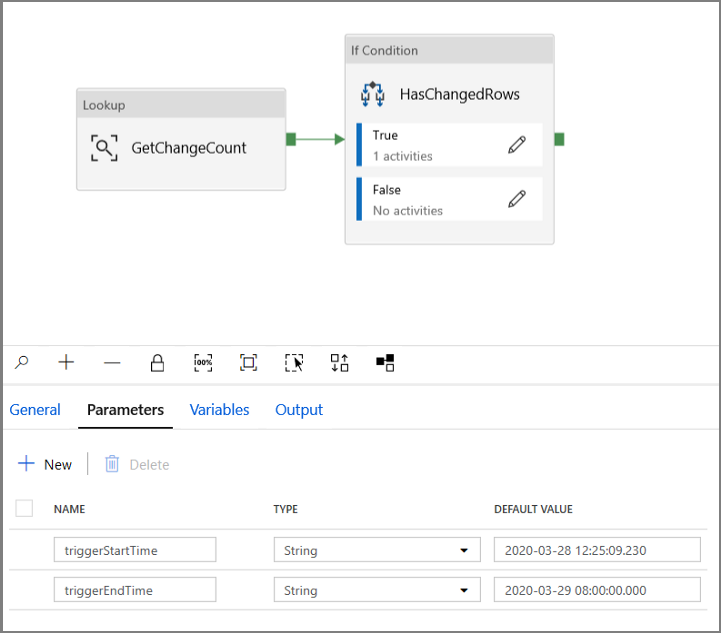
Klicka på inställningsfliken för uppslagsaktiviteten och konfigurera frågan så att den använder start- och slutparametrarna. Kopiera följande till frågan:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT count(1) changecount FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Gå till kopieringsaktiviteten i true-fallet för if condition-aktiviteten och klicka på fliken Källa. Kopiera följande till frågan:
@concat('DECLARE @begin_time datetime, @end_time datetime, @from_lsn binary(10), @to_lsn binary(10); SET @begin_time = ''',pipeline().parameters.triggerStartTime,'''; SET @end_time = ''',pipeline().parameters.triggerEndTime,'''; SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @begin_time); SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than'', @end_time); SELECT * FROM cdc.fn_cdc_get_net_changes_dbo_customers(@from_lsn, @to_lsn, ''all'')')Klicka på fliken Mottagare i aktiviteten Kopiera och klicka på Öppna för att redigera datauppsättningsegenskaperna. Klicka på fliken Parametrar och lägg till en ny parameter med namnet triggerStart
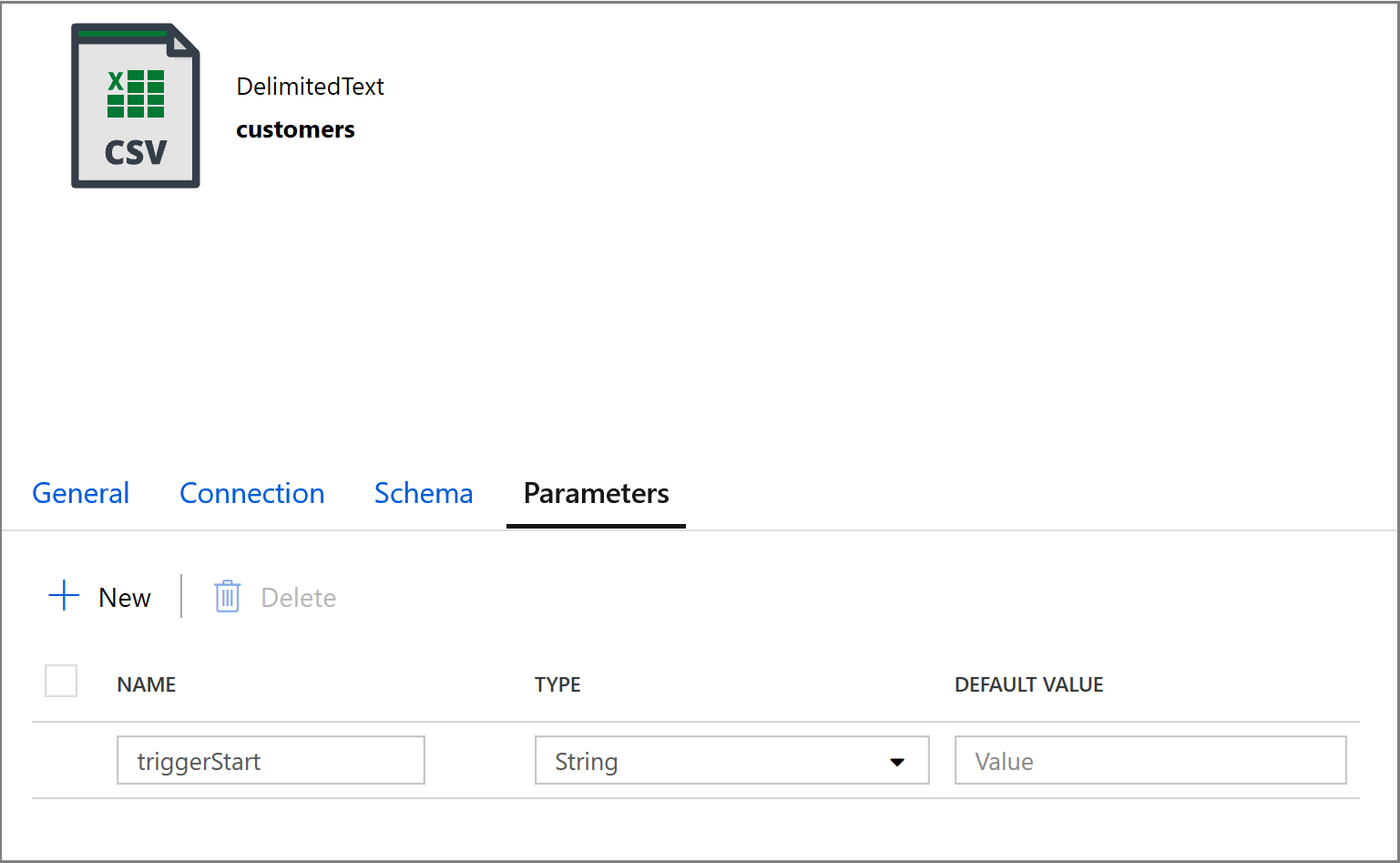
Konfigurera sedan datauppsättningsegenskaperna för att lagra data i en kund/inkrementell underkatalog med datumbaserade partitioner.
Klicka på fliken Anslutning för datamängdsegenskaperna och lägg till dynamiskt innehåll för både katalog- och filavsnitten.
Ange följande uttryck i avsnittet Katalog genom att klicka på länken för dynamiskt innehåll under textrutan:
@concat('customers/incremental/',formatDateTime(dataset().triggerStart,'yyyy/MM/dd'))Ange följande uttryck i avsnittet Arkiv . Detta skapar filnamn baserat på utlösarens startdatum och tid, suffix med csv-tillägget:
@concat(formatDateTime(dataset().triggerStart,'yyyyMMddHHmmssfff'),'.csv')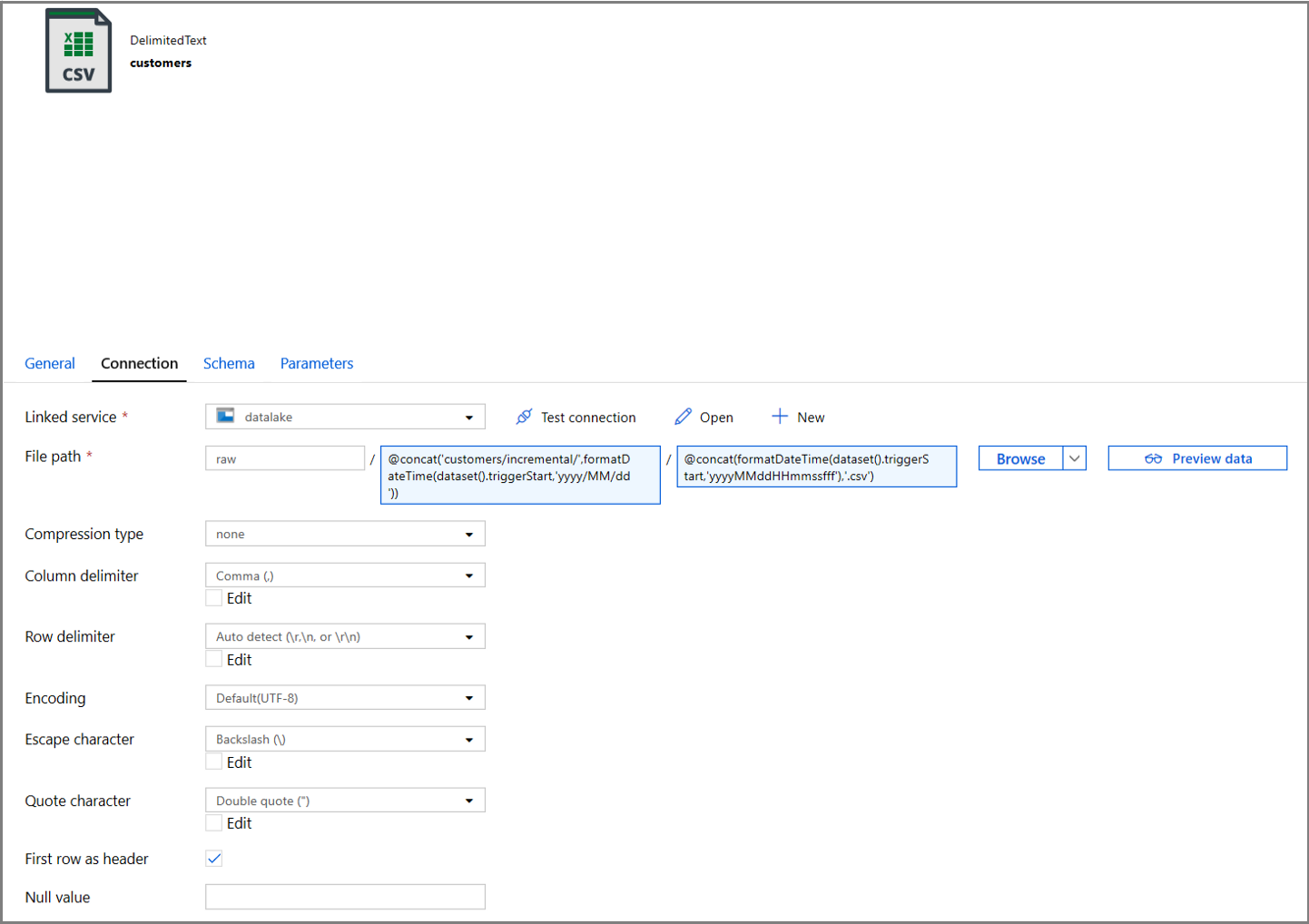
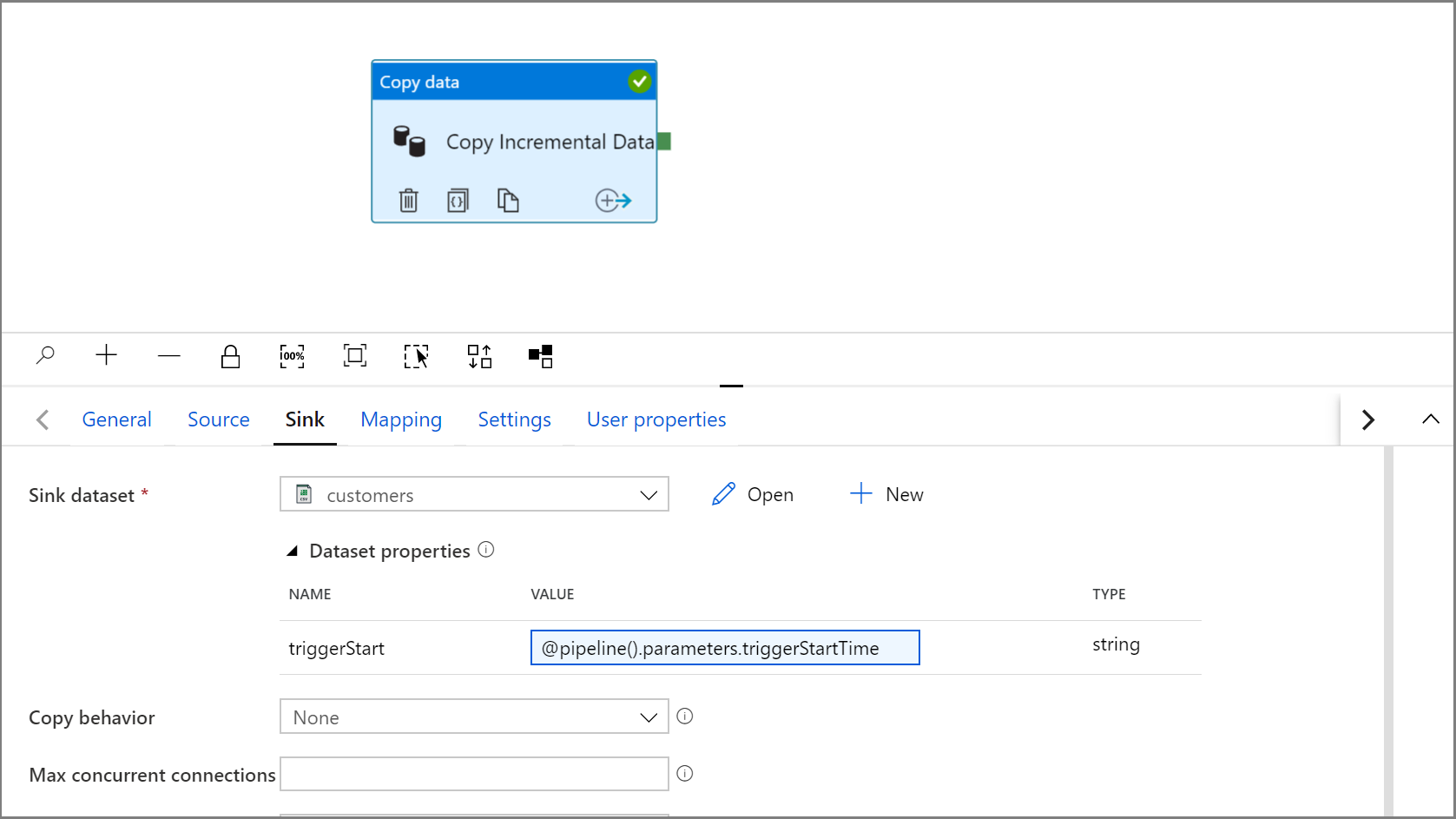
Gå tillbaka till mottagarinställningarna i Kopieringsaktivitet genom att klicka på fliken IncrementalCopyPipeline.
Expandera egenskaperna för datamängden och ange dynamiskt innehåll i parametervärdet triggerStart med följande uttryck:
@pipeline().parameters.triggerStartTime
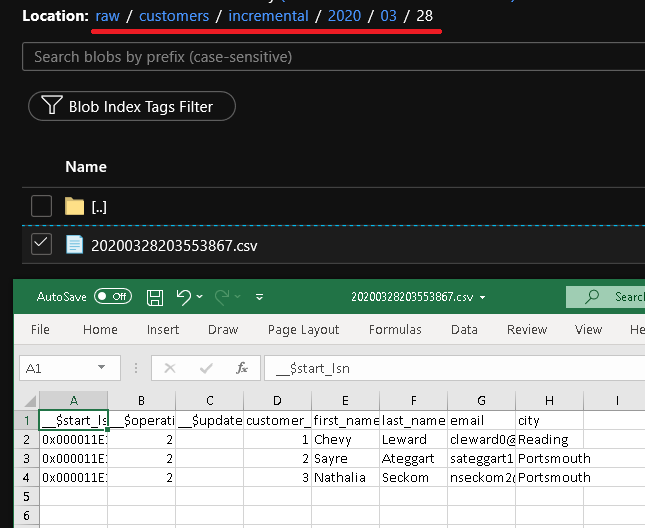
Klicka på Felsök för att testa pipelinen och se till att mappstrukturen och utdatafilen genereras som förväntat. Ladda ned och öppna filen för att verifiera innehållet.
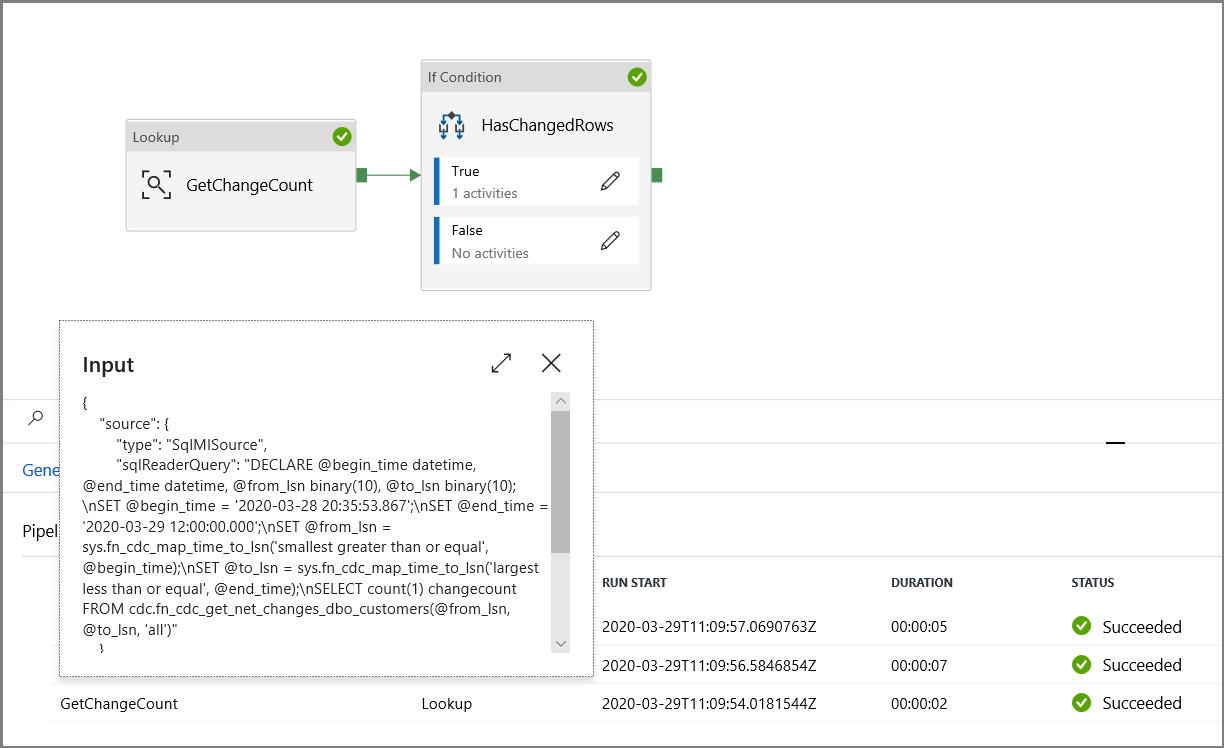
Kontrollera att parametrarna matas in i frågan genom att granska indataparametrarna för pipelinekörningen.
Publicera entiteter (länkade tjänster, datauppsättningar och pipelines) till Data Factory-tjänsten genom att klicka på knappen Publicera alla . Vänta tills du ser meddelandet Publiceringen är klar.
Konfigurera slutligen en utlösare för rullande fönster för att köra pipelinen med ett regelbundet intervall och ange parametrar för start- och sluttid.
- Klicka på knappen Lägg till utlösare och välj Ny/Redigera
- Ange ett utlösarnamn och ange en starttid som är lika med sluttiden för felsökningsfönstret ovan.
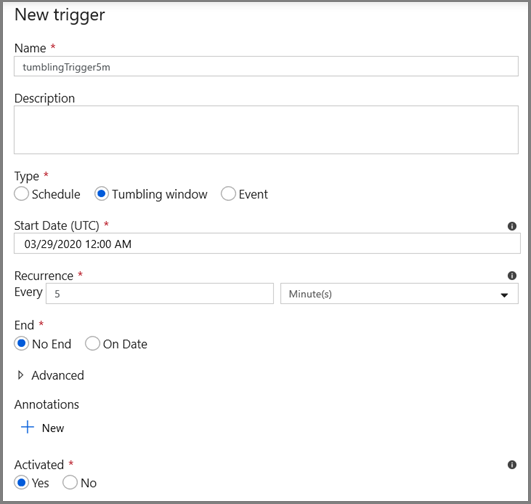
På nästa skärm anger du följande värden för start- respektive slutparametrarna.
@formatDateTime(trigger().outputs.windowStartTime,'yyyy-MM-dd HH:mm:ss.fff') @formatDateTime(trigger().outputs.windowEndTime,'yyyy-MM-dd HH:mm:ss.fff')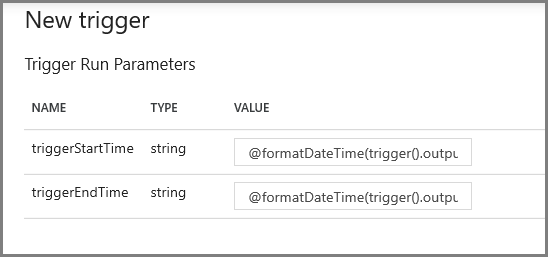
Kommentar
Utlösaren körs bara när den har publicerats. Dessutom är det förväntade beteendet för rullande fönster att köra alla historiska intervall från startdatumet fram till nu. Mer information om utlösare för rullande fönster finns här.
Använd SQL Server Management Studio för att göra några ytterligare ändringar i kundtabellen genom att köra följande SQL:
insert into customers (customer_id, first_name, last_name, email, city) values (4, 'Farlie', 'Hadigate', 'fhadigate3@zdnet.com', 'Reading'); insert into customers (customer_id, first_name, last_name, email, city) values (5, 'Anet', 'MacColm', 'amaccolm4@yellowbook.com', 'Portsmouth'); insert into customers (customer_id, first_name, last_name, email, city) values (6, 'Elonore', 'Bearham', 'ebearham5@ebay.co.uk', 'Portsmouth'); update customers set first_name='Elon' where customer_id=6; delete from customers where customer_id=5;Klicka på knappen Publicera alla . Vänta tills du ser meddelandet Publiceringen är klar.
Efter några minuter har pipelinen utlösts och en ny fil har lästs in i Azure Storage
Övervaka den inkrementella kopieringspipelinen
Klicka på fliken Övervaka till vänster. Du ser pipelinekörningen samt dess status i listan. Om du vill uppdatera listan klickar du på Uppdatera. Hovra nära namnet på pipelinen för att få åtkomst till åtgärden Kör om och förbrukningsrapporten.
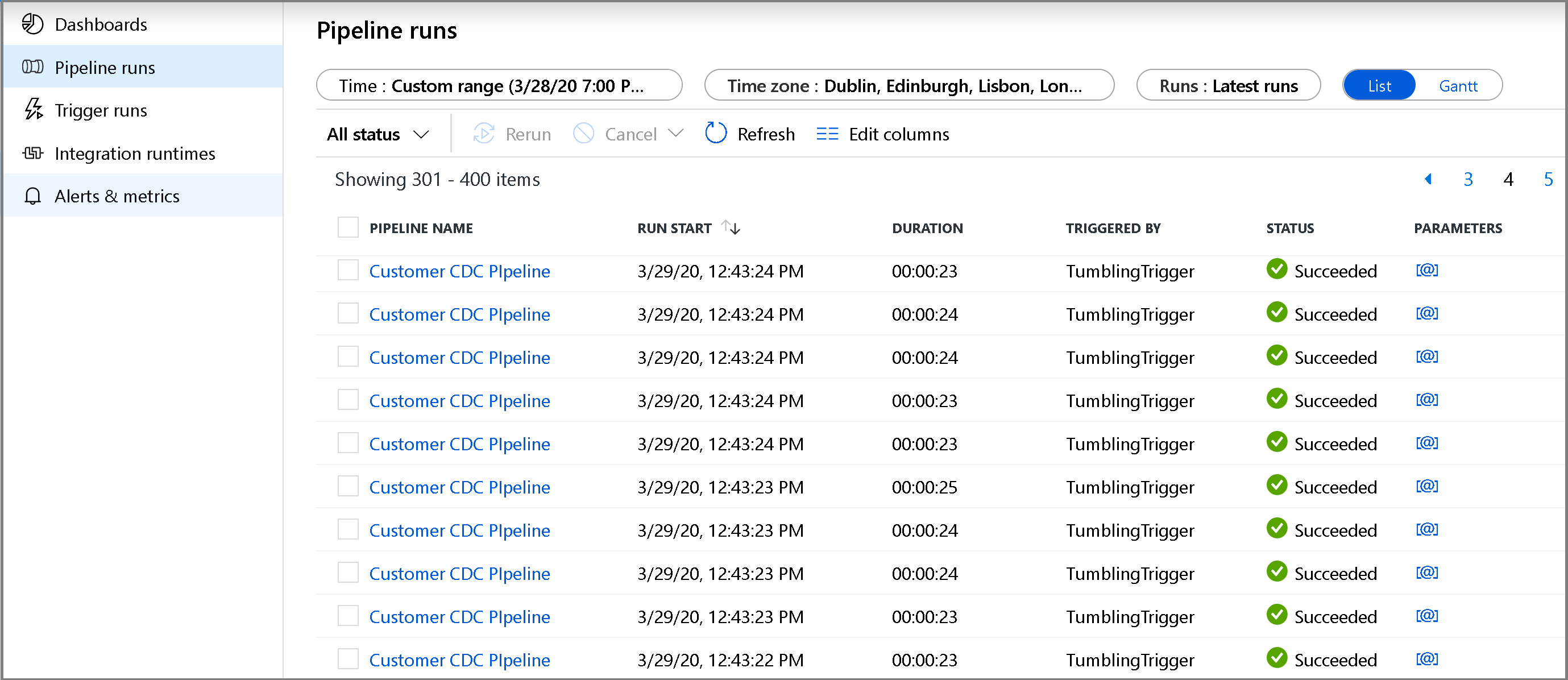
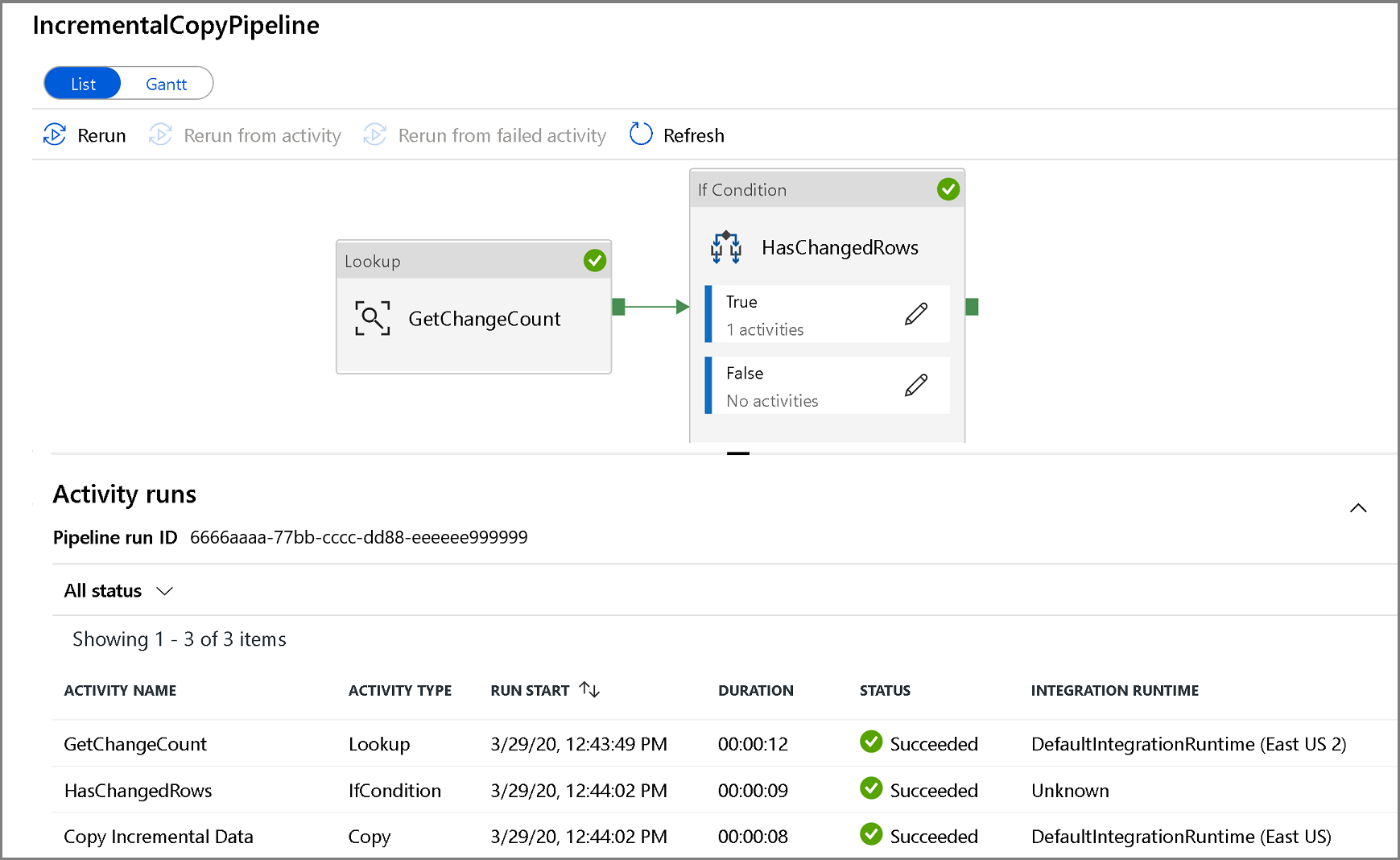
Om du vill visa aktivitetskörningar som är associerade med pipelinekörningen klickar du på pipelinenamnet. Om ändrade data har identifierats kommer det att finnas tre aktiviteter, inklusive kopieringsaktiviteten, annars finns det bara två poster i listan. Om du vill växla tillbaka till pipelinekörningsvyn klickar du på länken Alla pipelines högst upp.
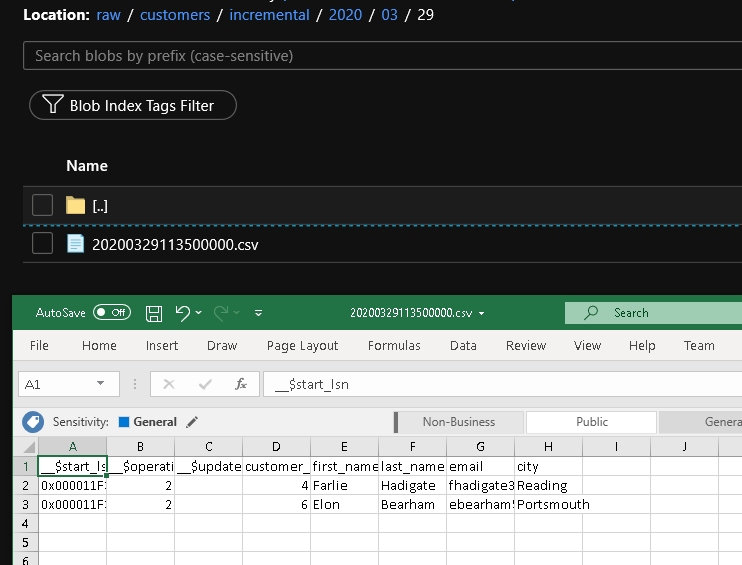
Granska resultaten
Du ser den andra filen i mappen customers/incremental/YYYY/MM/DD i containern raw.
Relaterat innehåll
Fortsätt till följande självstudie och lär dig mer om hur du kopierar nya och ändrade filer endast baserat på deras LastModifiedDate: