Kopiera data från en SQL Server-databas till Azure Blob Storage med verktyget Kopiera data
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
I den här självstudien skapar du en datafabrik i Azure Portal. Sedan använder du verktyget Kopiera data för att skapa en pipeline som kopierar data från en SQL Server-databas till Azure Blob Storage.
Kommentar
- Om du inte har använt Azure Data Factory tidigare kan du läsa Introduktion till Data Factory.
I den här självstudien får du göra följande:
- Skapa en datafabrik.
- Använd verktyget Kopiera data för att skapa en pipeline.
- Övervaka pipelinen och aktivitetskörningarna.
Förutsättningar
Azure-prenumeration
Om du inte redan har en Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar.
Azure-roller
Om du vill skapa Data Factory-instanser måste det användarkonto du använder för att logga in på Azure vara tilldelad en deltagare eller ägare, eller vara en administratör för Azure-prenumerationen.
Gå till Azure Portal om du vill se vilka behörigheter du har i prenumerationen. Välj användarnamnet längst upp till höger och välj sedan Behörigheter. Om du har åtkomst till flera prenumerationer väljer du rätt prenumeration. Exempelinstruktioner om hur du lägger till en användare i en roll finns i Tilldela Azure-roller med hjälp av Azure Portal.
SQL Server 2014, 2016 och 2017
I den här självstudien använder du en SQL Server-databas som källdatalager. Pipelinen i datafabriken som du skapar i den här självstudien kopierar data från den här SQL Server-databasen (källa) till Blob Storage (mottagare). Skapa sedan en tabell med namnet emp i SQL Server-databasen och infoga ett par exempelposter i tabellen.
Starta SQL Server Management Studio. Om det inte redan är installerat på datorn öppnar du Ladda ner SQL Server Management Studio.
Anslut till SQL Server-instansen med hjälp av dina autentiseringsuppgifter.
Skapa en exempeldatabas. I trädvyn högerklickar du på Databaser och sedan väljer du Ny databas.
I fönstret Ny databas anger du ett namn för databasen och sedan väljer du OK.
Skapa tabellen emp och infoga lite exempeldata i den genom att köra följande frågeskript mot databasen. I trädvyn högerklickar du på databasen du skapade och sedan väljer du Ny fråga.
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Azure-lagringskonto
I den här självstudien använder du ett allmänt Azure Storage-konto (Blob Storage, för att vara specifik) som datalager för destination/mottagare. Om du inte har något allmänt lagringskonto finns det anvisningar om hur du skapar ett i artikeln Skapa ett lagringskonto. Pipelinen i datafabriken som du skapar i den här självstudien kopierar data från SQL Server-databasen (källa) till denna Blob Storage (mottagare).
Hämta lagringskontots namn och åtkomstnyckel
Du använder namnet och nyckeln för lagringskontot i den här självstudien. Gör så här för att hämta namnet och nyckeln till lagringskontot:
Logga in på Azure Portal med användarnamnet och lösenordet för Azure.
Välj Alla tjänster i rutan till vänster. Filtrera genom att använda nyckelordet Lagring och välj sedan Lagringskonton.
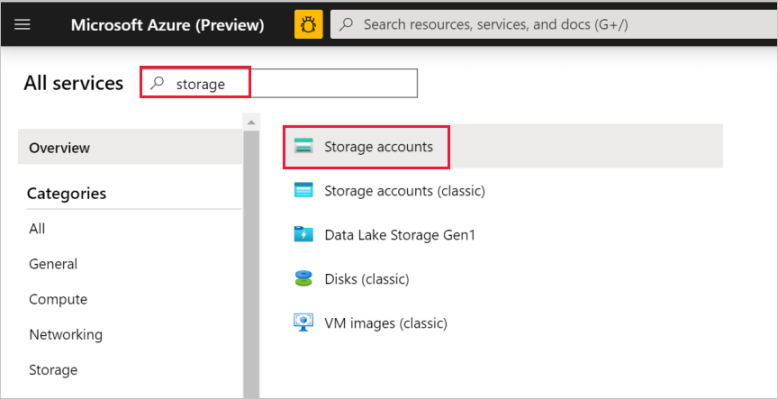
Filtrera på ditt lagringskonto (om det behövs) i listan med lagringskonton. Välj sedan ditt lagringskonto.
I fönstret Lagringskonto väljer du Åtkomstnycklar.
I rutorna Lagringskontonamn och key1 kopierar du värdena och klistrar sedan in dem i Anteckningar eller annat redigeringsprogram så att du har dem när du behöver dem senare i självstudien.
Skapa en datafabrik
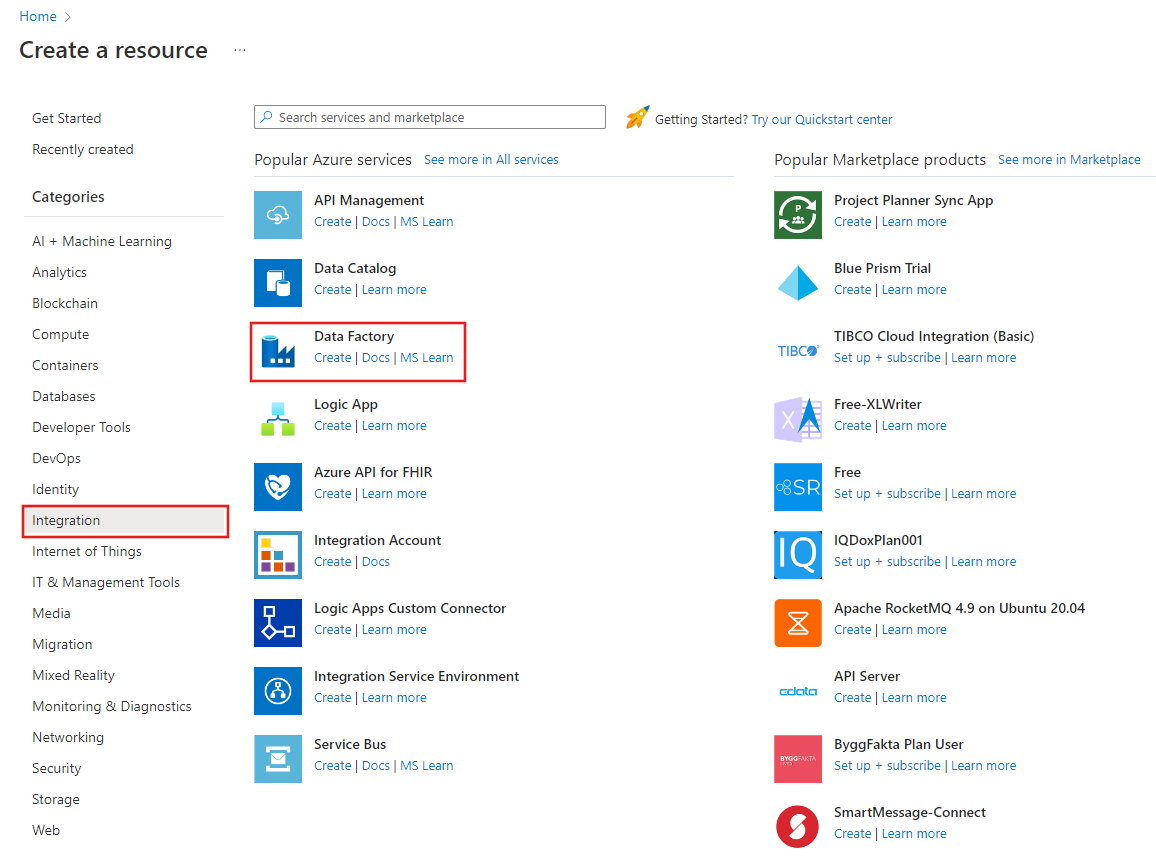
På menyn till vänster väljer du Skapa en resurs>Integration>Data Factory.
I fönstret Ny datafabrik, under Namn anger du ADFTutorialDataFactory.
Namnet på datafabriken måste vara globalt unikt. Om följande felmeddelande visas för namnfältet ändrar du namnet på datafabriken (t.ex. dittnamnADFTutorialDataFactory). Se artikeln om namnregler för datafabriker för namnregler för datafabriksartefakter.
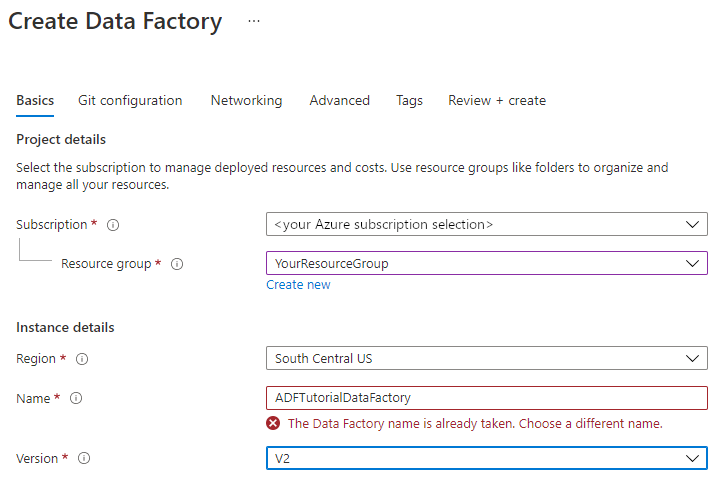
Välj den Azure-prenumeration som du vill skapa den nya datafabriken i.
Gör något av följande för Resursgrupp:
Välj Använd befintlig och välj en befintlig resursgrupp i listrutan.
Välj Skapa ny och ange namnet på en resursgrupp.
Mer information om resursgrupper finns i Använda resursgrupper för att hantera Azure-resurser.
Under Version väljer du V2.
Under Plats väljer du en plats för datafabriken. Endast platser som stöds visas i listrutan. Datalagren (t.ex. Azure Storage och SQL-databas) och beräkningarna (t.ex. Azure HDInsight) som används i Data Factory kan finnas på andra platser/i andra regioner.
Välj Skapa.
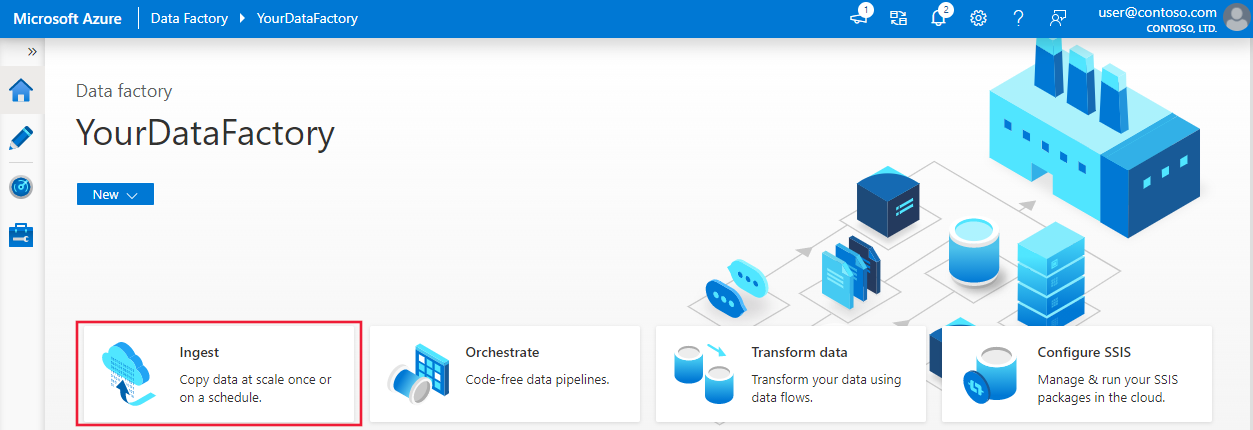
När datafabriken har skapats visas sidan Datafabrik som på bilden.

Välj Öppna på panelen Öppna Azure Data Factory Studio för att starta Data Factory-användargränssnittet på en separat flik.
Använd verktyget Kopiera data för att skapa en pipeline
På startsidan för Azure Data Factory väljer du Mata in för att starta verktyget Kopiera data.
På sidan Egenskaper i verktyget Kopiera data väljer du Inbyggd kopieringsaktivitet under Aktivitetstyp och väljer Kör en gång nu under Aktivitetstakt eller aktivitetsschema och väljer sedan Nästa.
På sidan Källdatalager väljer du på + Skapa ny anslutning.
Under Ny anslutning söker du efter SQL Server och väljer sedan Fortsätt.
I dialogrutan Ny anslutning (SQL Server) under Namn anger du SqlServerLinkedService. Välj +Ny under Connect via integration runtime (Anslut via Integration Runtime). Du måste skapa en lokal integreringskörning, ladda ned den på din dator och registrera den med Data Factory. Den lokala integreringskörningen kopierar data mellan din lokala miljö och molnet.
I dialogrutan Installation av integrationskörning väljer du Lokalt installerad. Välj sedan Fortsätt.
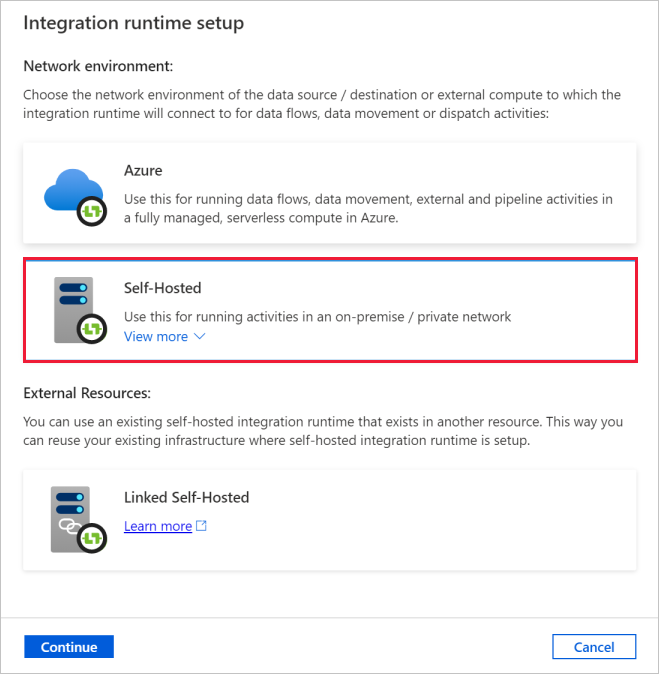
I dialogrutan Installation av integrationskörning går du till Namn och anger TutorialIntegrationRuntime. Välj sedan Skapa.
I dialogrutan Installation av integrationskörning väljer du Klicka här för att starta expresskonfigurationen för den här datorn. Med den här åtgärden installeras integreringskörningen på datorn och registreras med Data Factory. Alternativt kan du använda det manuella installationsalternativet för att ladda ned installationsfilen, köra den och använda nyckeln för att registrera integreringskörning.
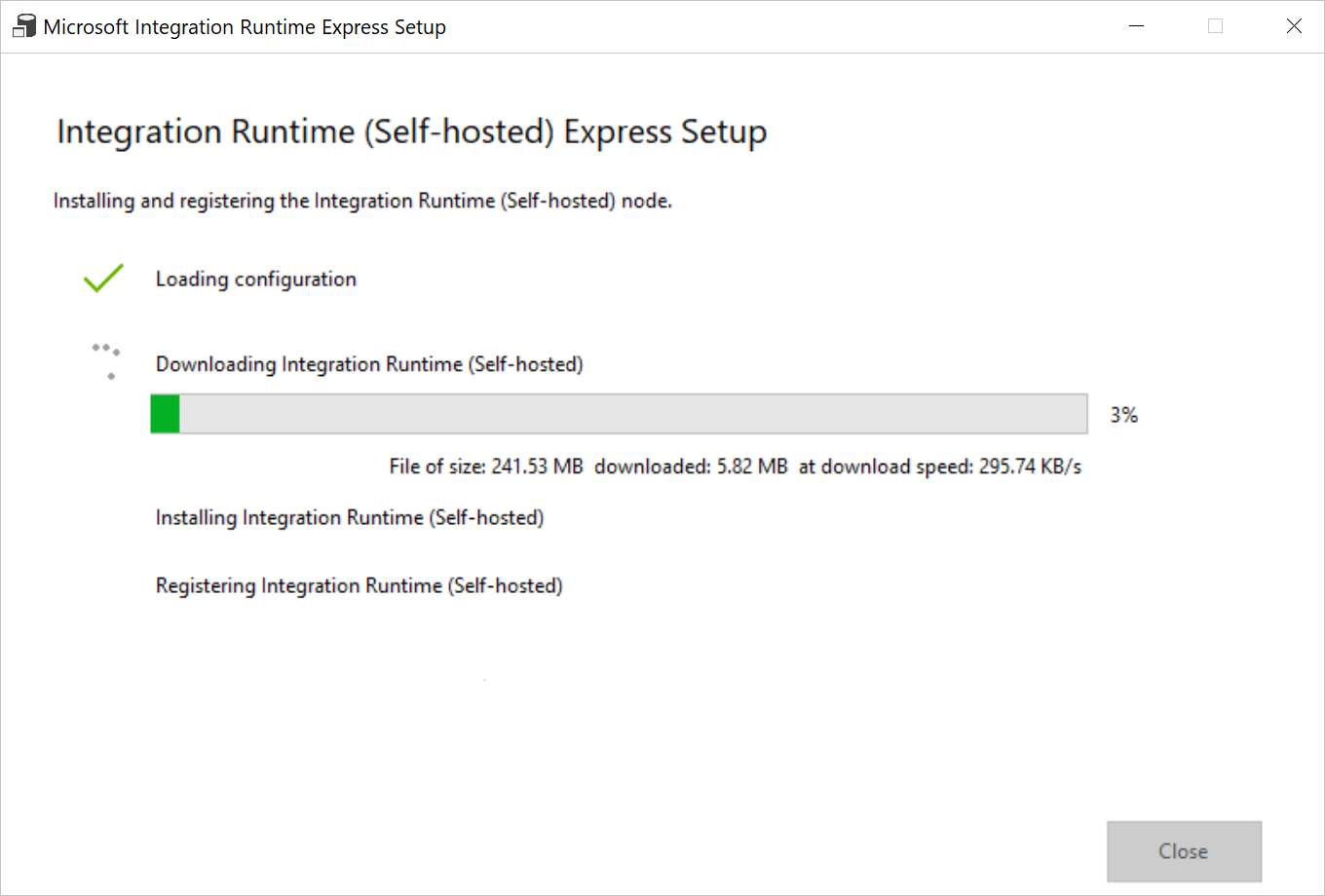
Kör programmet som laddats ned. I fönstret visas status för expressinstallationen.
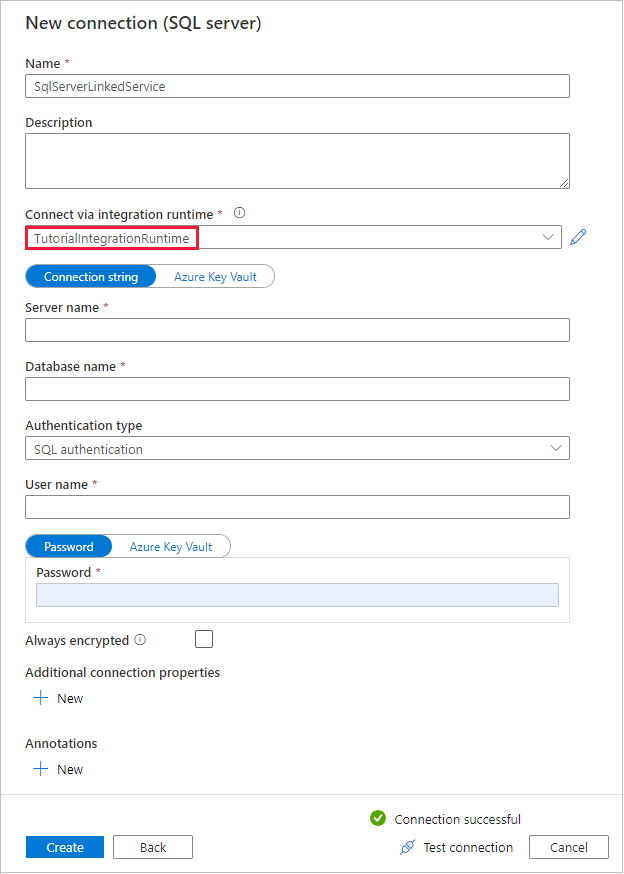
I dialogrutan Ny anslutning (SQL Server) bekräftar du att TutorialIntegrationRuntime har valts under Anslut via integrationskörning. Utför sedan följande steg:
a. Under Namn anger du SqlServerLinkedService.
b. Under Servernamn anger du namnet på SQL Server-instansen.
c. Under Databasnamn anger du namnet på din lokala databas.
d. Under Autentiseringstyp väljer du lämplig autentisering.
e. Under Användarnamn anger du namnet på användaren med åtkomst till SQL Server.
f. Ange lösenordet för användaren.
g. Testa anslutningen och välj Skapa.
På sidan Källdatalager kontrollerar du att den nyligen skapade SQL Server-anslutningen är markerad i anslutningsblocket. I avsnittet Källtabeller väljer du SEDAN BEFINTLIGA TABELLER och väljer tabellen dbo.emp i listan och väljer Nästa. Du kan välja andra tabeller baserade på din databas.
På sidan Tillämpa filter kan du förhandsgranska data och visa schemat för indata genom att välja knappen Förhandsgranska data . Välj sedan Nästa.
På sidan Måldatalager väljer du + Skapa ny anslutning
I Ny anslutning söker du efter och väljer Azure Blob Storage och väljer sedan Fortsätt.

I dialogrutan Ny anslutning (Azure Blob Storage) utför du följande steg:
a. Under Namn anger du AzureStorageLinkedService.
b. Under Anslut via integrationskörning väljer du TutorialIntegrationRuntime och sedan Kontonyckel under Autentiseringsmetod.
c. Under Azure-prenumeration väljer du din Azure-prenumeration i listrutan.
d. Under Lagringskontonamn väljer du ditt lagringskonto i listrutan.
e. Testa anslutningen och välj Skapa.
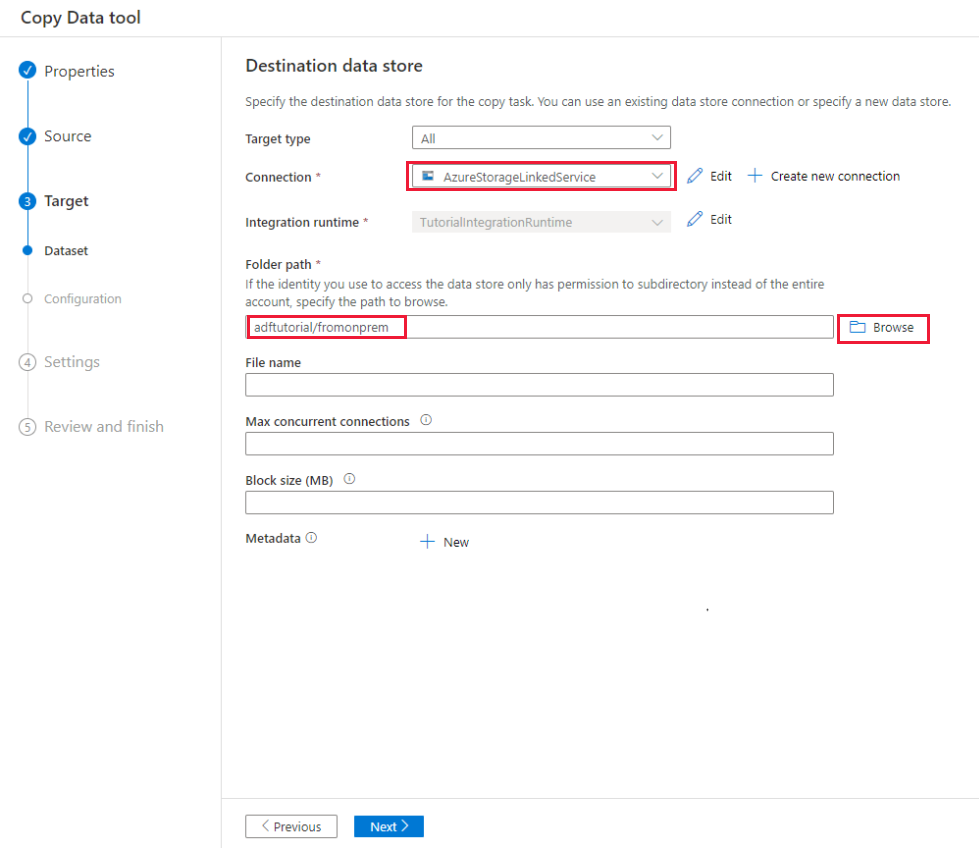
I dialogrutan Måldatalager kontrollerar du att den nyligen skapade Azure Blob Storage-anslutningen är markerad i anslutningsblocket. Under Mappsökväg anger du sedan adftutorial/fromonprem. Du skapade containern adftutorial som en del av förutsättningarna. Om utdatamappen inte finns (i det här fallet fromonprem) skapas den automatiskt av Data Factory. Du kan också använda knappen Bläddra för att bläddra i bloblagringen och dess containrar/mappar. Om du inte anger något värde under Filnamn används som standard namnet från källan (i det här fallet dbo.emp).
I dialogrutan Filformatsinställningar väljer du Nästa.
I dialogrutan Inställningar under Aktivitetsnamn anger du CopyFromOnPremSqlToAzureBlobPipeline och väljer sedan Nästa. Verktyget Kopiera data skapar en pipeline med det namn som du anger i det här fältet.
Granska värdena för alla inställningar i dialogrutan Sammanfattning och välj Nästa.
Välj Övervaka på sidan Distribution för att övervaka pipelinen (aktiviteten).
När pipelinekörningen är klar kan du visa status för den pipeline som du skapade.
På sidan "Pipelinekörningar" väljer du Uppdatera för att uppdatera listan. Välj länken under Pipelinenamn om du vill visa aktivitetskörningsinformation eller köra pipelinen igen.
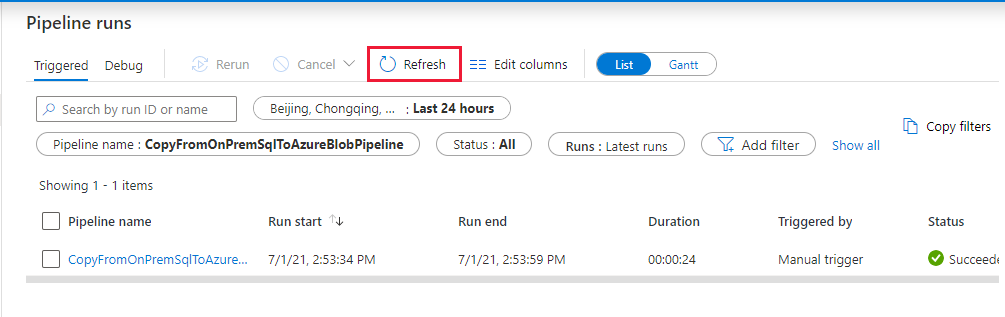
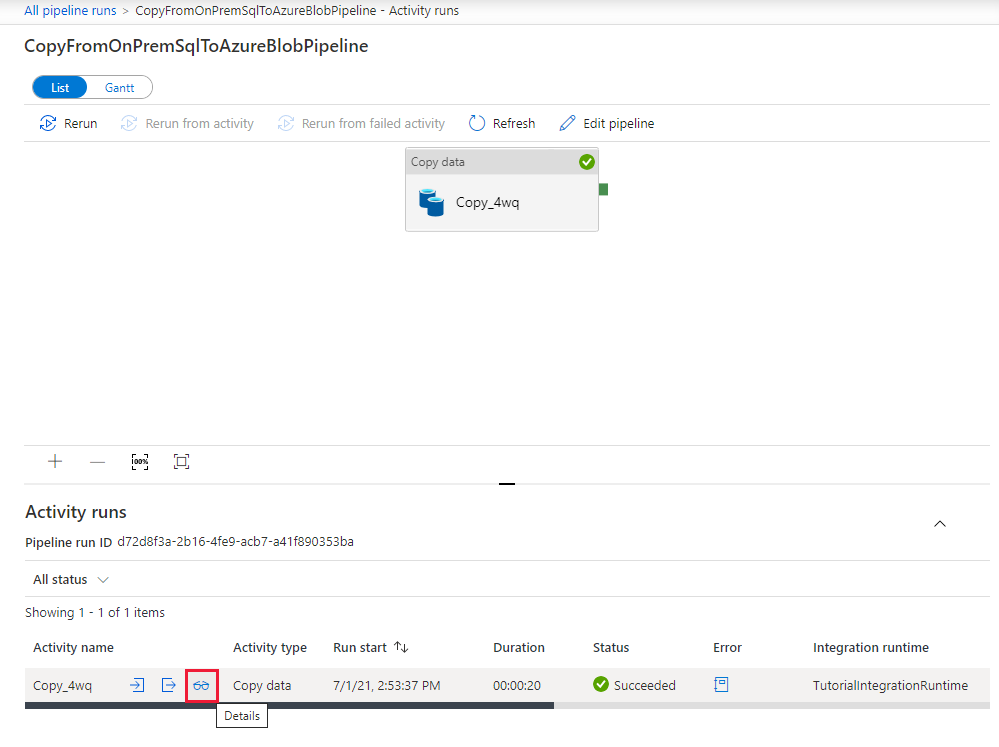
På sidan Aktivitetskörningar väljer du länken Information (glasögonikon) under kolumnen Aktivitetsnamn för mer information om kopieringsåtgärden. Om du vill gå tillbaka till sidan "Pipelinekörningar" väljer du länken Alla pipelinekörningar på menyn breadcrumb. Välj Uppdatera för att uppdatera vyn.
Bekräfta att utdatafilen visas i mappen fromonprem för containern adftutorial.
Klicka på fliken Författare till vänster för att växla till redigeringsläget. Du kan uppdatera de länkade tjänster, datauppsättningar och pipeliner som skapats med verktyget med hjälp av redigeraren. Klicka på Kod för att visa JSON-koden som är associerad med den entitet som har öppnats i redigeraren. Mer information om hur du redigerar dessa entiteter i användargränssnittet för Data Factory finns i Azure Portal-versionen av den här självstudiekursen.
Relaterat innehåll
Pipelinen i det här exemplet kopierar data från en SQL Server-databas till Blob Storage. Du har lärt dig att:
- Skapa en datafabrik.
- Använd verktyget Kopiera data för att skapa en pipeline.
- Övervaka pipelinen och aktivitetskörningarna.
Se Datalager som stöds för att få en lista över datalager som stöds av Data Factory.
Fortsätt till följande självstudie för att lära dig att masskopiera data från en källa till ett mål: