Transformera data genom att köra en Databricks-notebook-fil
GÄLLER FÖR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
Azure Databricks Notebook-aktiviteten i en pipeline kör en Databricks-notebook-fil på din Azure Databricks-arbetsyta. Den här artikeln bygger på artikeln om datatransformeringsaktiviteter , som visar en allmän översikt över datatransformering och de omvandlingsaktiviteter som stöds. Azure Databricks är en hanterad plattform för att köra Apache Spark.
Du kan skapa en Databricks-notebook-fil med en ARM-mall med hjälp av JSON eller direkt via Användargränssnittet för Azure Data Factory Studio. En stegvis genomgång av hur du skapar en databricks notebook-aktivitet med hjälp av användargränssnittet finns i självstudien Kör en Databricks-anteckningsbok med Databricks Notebook-aktiviteten i Azure Data Factory.
Lägga till en Notebook-aktivitet för Azure Databricks i en pipeline med användargränssnittet
Utför följande steg för att använda en Notebook-aktivitet för Azure Databricks i en pipeline:
Sök efter Notebook i fönstret PipelineAktiviteter och dra en notebook-aktivitet till pipelinearbetsytan.
Välj den nya notebook-aktiviteten på arbetsytan om den inte redan är markerad.
Välj fliken Azure Databricks för att välja eller skapa en ny länkad Azure Databricks-tjänst som ska köra notebook-aktiviteten.
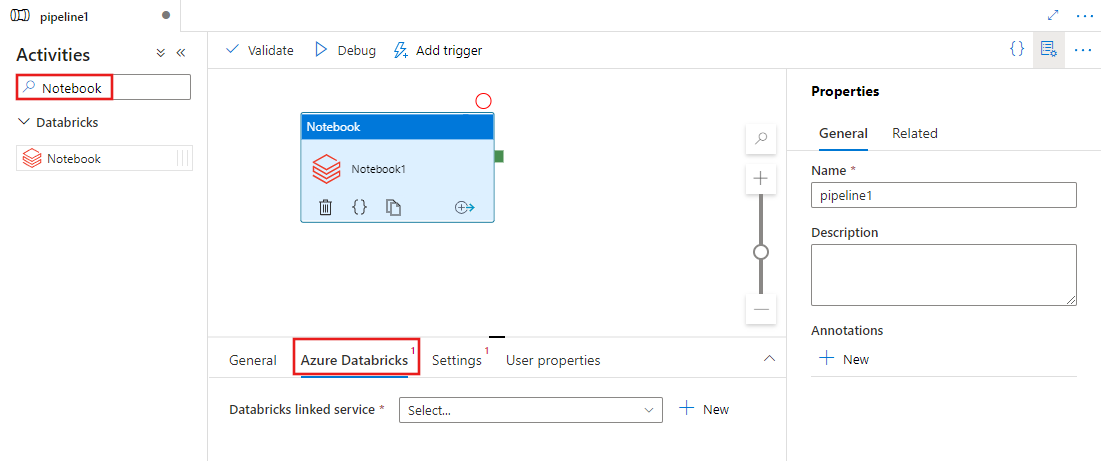
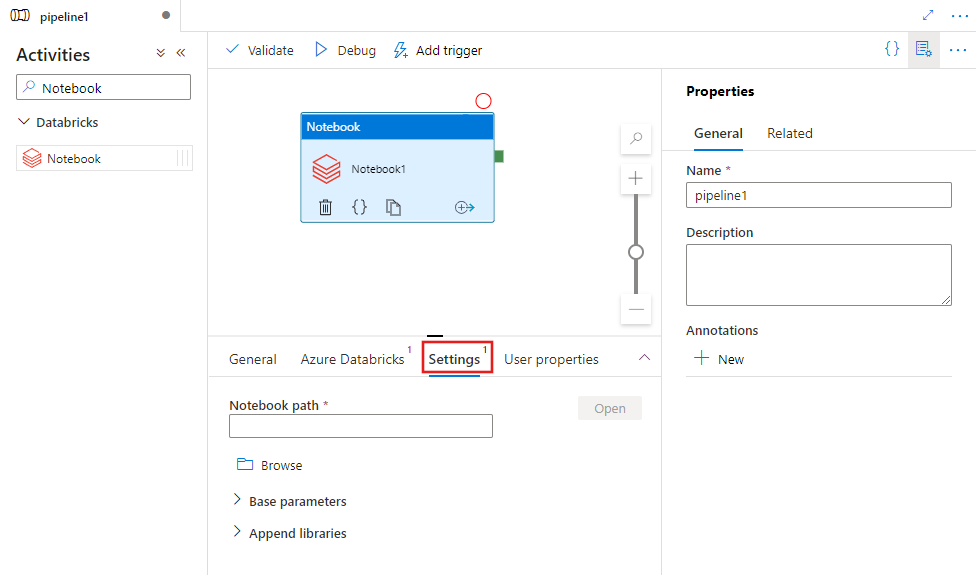
Välj fliken Inställningar och ange den notebook-sökväg som ska köras på Azure Databricks, valfria basparametrar som ska skickas till notebook-filen och andra bibliotek som ska installeras i klustret för att köra jobbet.
Databricks Notebook-aktivitetsdefinition
Här är JSON-exempeldefinitionen för en Databricks Notebook-aktivitet:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksNotebook",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedservice",
"type": "LinkedServiceReference"
},
"typeProperties": {
"notebookPath": "/Users/user@example.com/ScalaExampleNotebook",
"baseParameters": {
"inputpath": "input/folder1/",
"outputpath": "output/"
},
"libraries": [
{
"jar": "dbfs:/docs/library.jar"
}
]
}
}
}
Databricks Notebook-aktivitetsegenskaper
I följande tabell beskrivs de JSON-egenskaper som används i JSON-definitionen:
| Property | Beskrivning | Obligatoriskt |
|---|---|---|
| name | Namnet på aktiviteten i pipelinen. | Ja |
| description | Text som beskriver vad aktiviteten gör. | Nej |
| type | För Databricks Notebook-aktivitet är aktivitetstypen DatabricksNotebook. | Ja |
| linkedServiceName | Namnet på den länkade Databricks-tjänst som Databricks-notebook-filen körs på. Mer information om den här länkade tjänsten finns i artikeln Compute linked services (Beräkningslänkade tjänster ). | Ja |
| notebookPath | Den absoluta sökvägen för anteckningsboken som ska köras på Databricks-arbetsytan. Den här sökvägen måste börja med ett snedstreck. | Ja |
| baseParameters | En matris med nyckel/värde-par. Basparametrar kan användas för varje aktivitetskörning. Om notebook-filen tar en parameter som inte har angetts används standardvärdet från notebook-filen. Läs mer om parametrar i Databricks Notebooks. | Nej |
| bibliotek | En lista över bibliotek som ska installeras i klustret som ska köra jobbet. Det kan vara en matris med <sträng, objekt>. | Nej |
Bibliotek som stöds för Databricks-aktiviteter
I databricks-aktivitetsdefinitionen ovan anger du följande bibliotekstyper: jar, egg, whl, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"whl": "dbfs:/mnt/libraries/mlflow-0.0.1.dev0-py2-none-any.whl"
},
{
"whl": "dbfs:/mnt/libraries/wheel-libraries.wheelhouse.zip"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Mer information finns i Databricks-dokumentationen för bibliotekstyper.
Skicka parametrar mellan notebook-filer och pipelines
Du kan skicka parametrar till notebook-filer med hjälp av egenskapen baseParameters i databricks-aktiviteten.
I vissa fall kan du behöva skicka tillbaka vissa värden från notebook-filen till tjänsten, som kan användas för kontrollflöde (villkorsstyrda kontroller) i tjänsten eller användas av underordnade aktiviteter (storleksgränsen är 2 MB).
I notebook-filen kan du anropa dbutils.notebook.exit("returnValue") och motsvarande "returnValue" returneras till tjänsten.
Du kan använda utdata i tjänsten med hjälp av uttryck som
@{activity('databricks notebook activity name').output.runOutput}.Viktigt!
Om du skickar JSON-objekt kan du hämta värden genom att lägga till egenskapsnamn. Exempel:
@{activity('databricks notebook activity name').output.runOutput.PropertyName}
Ladda upp ett bibliotek i Databricks
Du kan använda arbetsytans användargränssnitt:
Om du vill hämta dbfs-sökvägen för biblioteket som lagts till med hjälp av användargränssnittet kan du använda Databricks CLI.
Vanligtvis lagras Jar-biblioteken under dbfs:/FileStore/jars när användargränssnittet används. Du kan visa en lista över hela CLI: databricks fs ls dbfs:/FileStore/job-jars
Eller så kan du använda Databricks CLI:
Använda Databricks CLI (installationssteg)
Om du till exempel vill kopiera en JAR-fil till dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar