Transformering med Azure Databricks
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
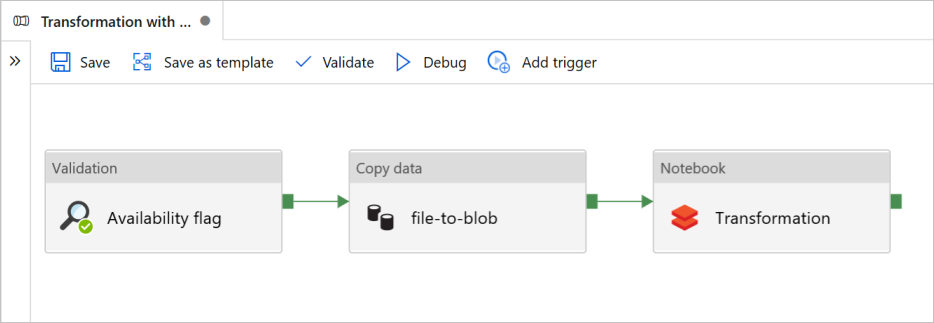
I den här självstudien skapar du en pipeline från slutpunkt till slutpunkt som innehåller aktiviteterna Validering, Kopiera data och Notebook i Azure Data Factory.
Validering säkerställer att källdatauppsättningen är redo för nedströmsförbrukning innan du utlöser kopierings- och analysjobbet.
Kopiera data duplicerar källdatauppsättningen till mottagarlagringen, som monteras som DBFS i Azure Databricks-notebook-filen. På så sätt kan datamängden förbrukas direkt av Spark.
Notebook utlöser Den Databricks-notebook-fil som transformerar datauppsättningen. Den lägger också till datamängden i en bearbetad mapp eller Azure Synapse Analytics.
För enkelhetens skull skapar mallen i den här självstudien inte någon schemalagd utlösare. Du kan lägga till en om det behövs.
Förutsättningar
Ett Azure Blob Storage-konto med en container som anropas
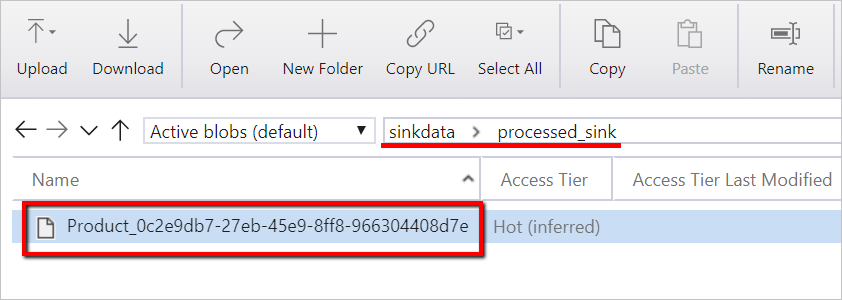
sinkdataför användning som mottagare.Anteckna lagringskontots namn, containernamn och åtkomstnyckel. Du behöver dessa värden senare i mallen.
En Azure Databricks-arbetsyta.
Importera en notebook-fil för transformering
Så här importerar du en transformeringsanteckningsbok till din Databricks-arbetsyta:
Logga in på din Azure Databricks-arbetsyta.
Högerklicka på en mapp på arbetsytan och välj Importera.
Välj Importera från: URL. I textrutan anger du
https://adflabstaging1.blob.core.windows.net/share/Transformations.html.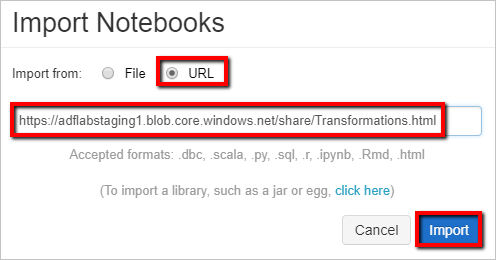
Nu ska vi uppdatera transformeringsanteckningsboken med information om lagringsanslutningen.
I den importerade notebook-filen går du till kommando 5 enligt följande kodfragment.
- Ersätt
<storage name>och<access key>med din egen lagringsanslutningsinformation. - Använd lagringskontot med containern
sinkdata.
# Supply storageName and accessKey values storageName = "<storage name>" accessKey = "<access key>" try: dbutils.fs.mount( source = "wasbs://sinkdata\@"+storageName+".blob.core.windows.net/", mount_point = "/mnt/Data Factorydata", extra_configs = {"fs.azure.account.key."+storageName+".blob.core.windows.net": accessKey}) except Exception as e: # The error message has a long stack track. This code tries to print just the relevant line indicating what failed. import re result = re.findall(r"\^\s\*Caused by:\s*\S+:\s\*(.*)\$", e.message, flags=re.MULTILINE) if result: print result[-1] \# Print only the relevant error message else: print e \# Otherwise print the whole stack trace.- Ersätt
Generera en Databricks-åtkomsttoken för Data Factory för åtkomst till Databricks.
- I din Azure Databricks-arbetsyta väljer du ditt Användarnamn för Azure Databricks i det övre fältet och väljer sedan Inställningar i listrutan.
- Välj Utvecklare.
- Bredvid Åtkomsttoken väljer du Hantera.
- Välj Generera ny token.
- (Valfritt) Ange en kommentar som hjälper dig att identifiera den här token i framtiden och ändra tokens standardlivslängd på 90 dagar. Om du vill skapa en token utan livslängd (rekommenderas inte) lämnar du rutan Livslängd (dagar) tom (tom).
- Välj Generera.
- Kopiera den visade token till en säker plats och välj sedan Klar.
Spara åtkomsttoken för senare användning när du skapar en länkad Databricks-tjänst. Åtkomsttoken ser ut ungefär som dapi32db32cbb4w6eee18b7d87e45exxxxxx.
Så här använder du den här mallen
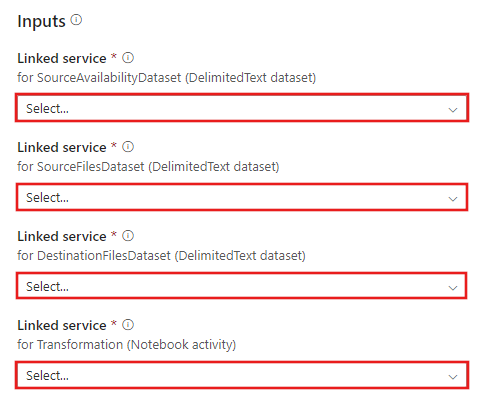
Gå till mallen Transformering med Azure Databricks och skapa nya länkade tjänster för följande anslutningar.
Källblobanslutning – för att komma åt källdata.
I den här övningen kan du använda den offentliga bloblagringen som innehåller källfilerna. Referera till följande skärmbild för konfigurationen. Använd följande SAS-URL för att ansluta till källlagring (skrivskyddad åtkomst):
https://storagewithdata.blob.core.windows.net/data?sv=2018-03-28&si=read%20and%20list&sr=c&sig=PuyyS6%2FKdB2JxcZN0kPlmHSBlD8uIKyzhBWmWzznkBw%3D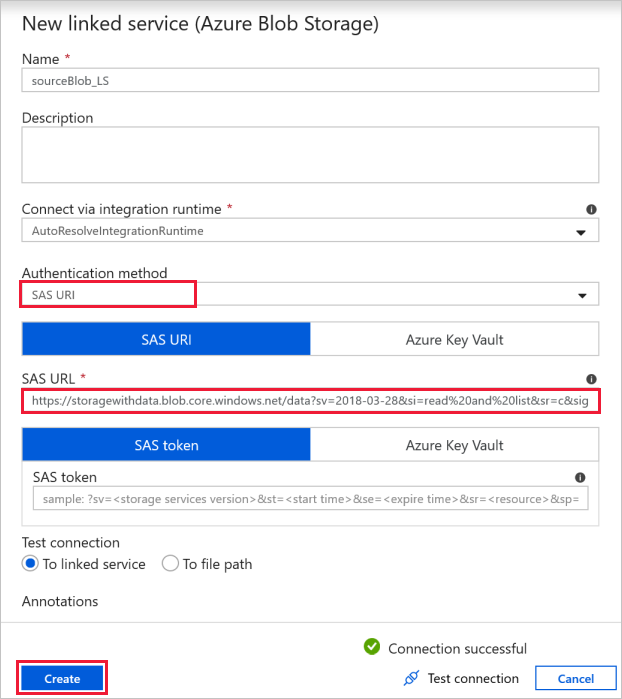
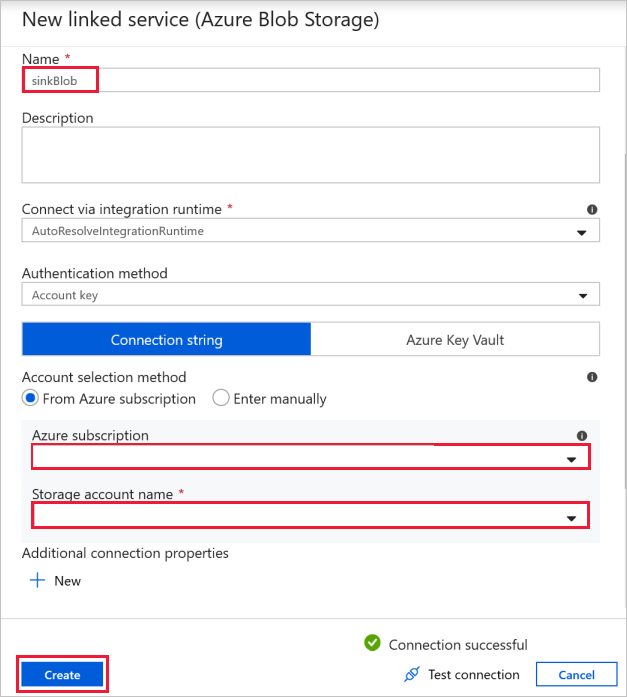
Målblobanslutning – för att lagra kopierade data.
I fönstret Ny länkad tjänst väljer du din lagringsblob för mottagare.
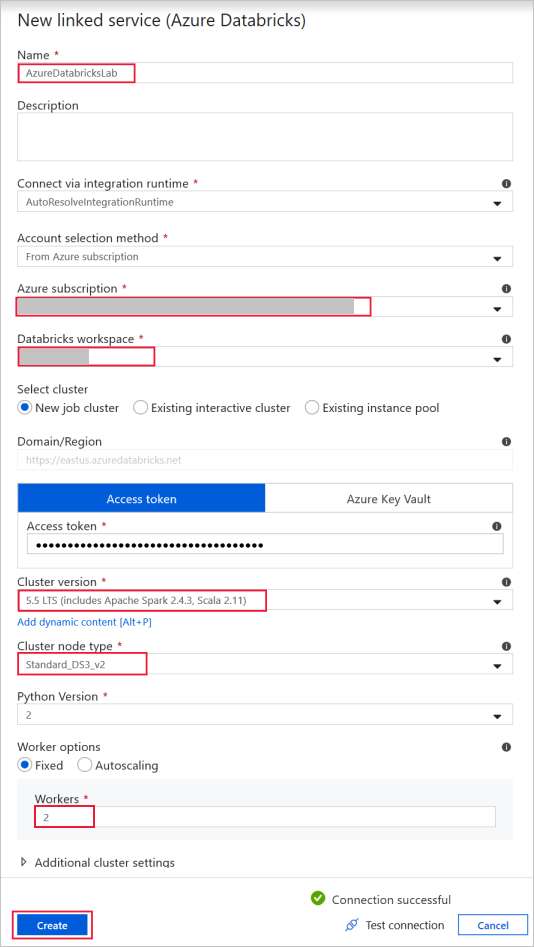
Azure Databricks – för att ansluta till Databricks-klustret.
Skapa en Databricks-länkad tjänst med hjälp av åtkomstnyckeln som du genererade tidigare. Du kan välja att välja ett interaktivt kluster om du har ett. I det här exemplet används alternativet Nytt jobbkluster .
Välj Använd denna mall. Du ser en pipeline som skapats.
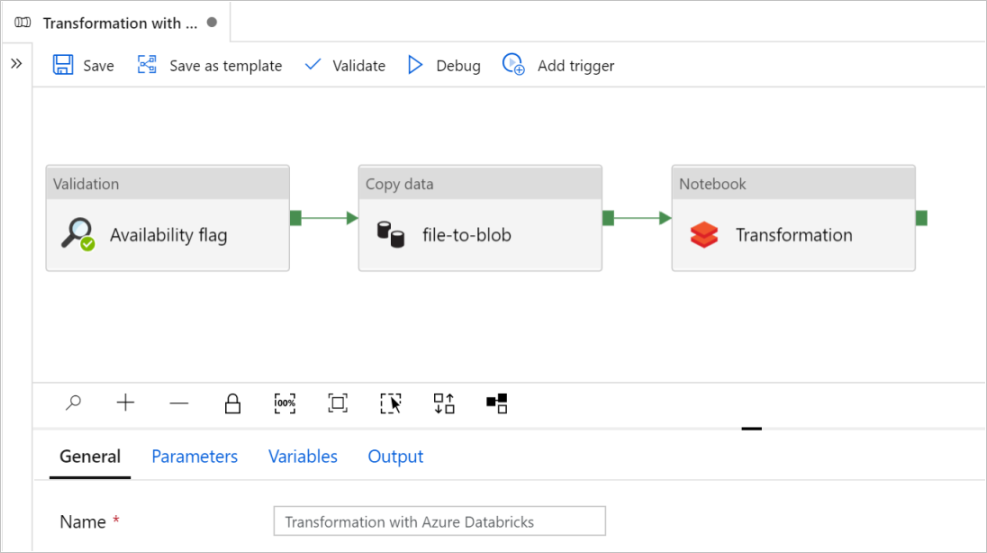
Introduktion och konfiguration av pipeline
I den nya pipelinen konfigureras de flesta inställningar automatiskt med standardvärden. Granska konfigurationerna för din pipeline och gör nödvändiga ändringar.
I flaggan Tillgänglighet för valideringsaktivitet kontrollerar du att värdet för datauppsättningen för källan är inställt på
SourceAvailabilityDatasetdet som du skapade tidigare.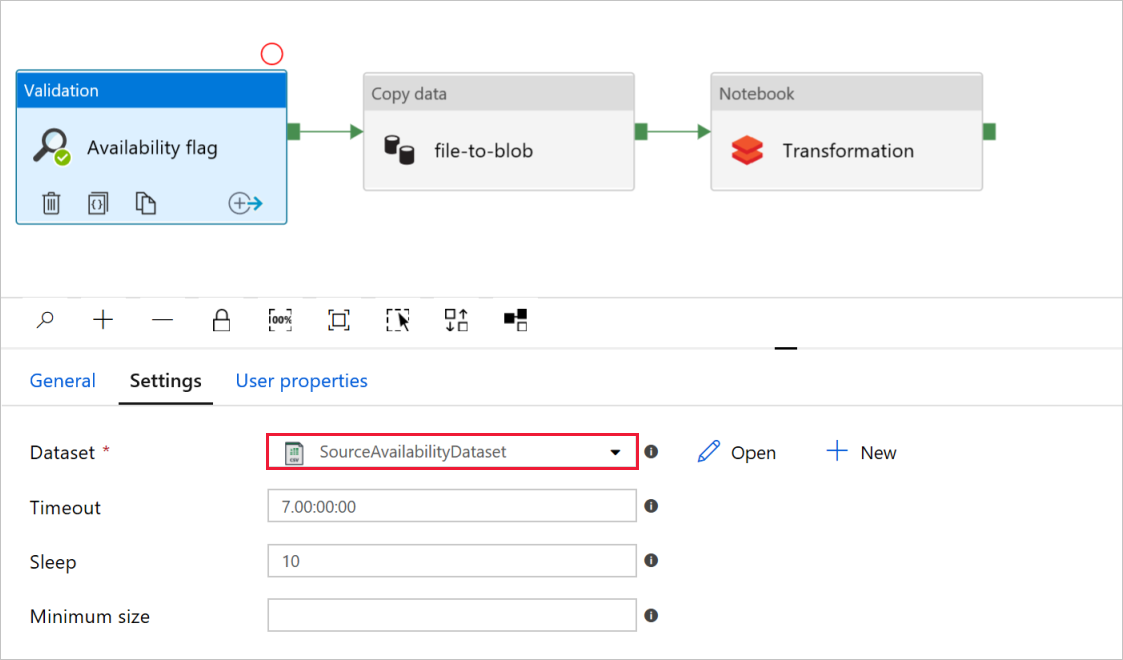
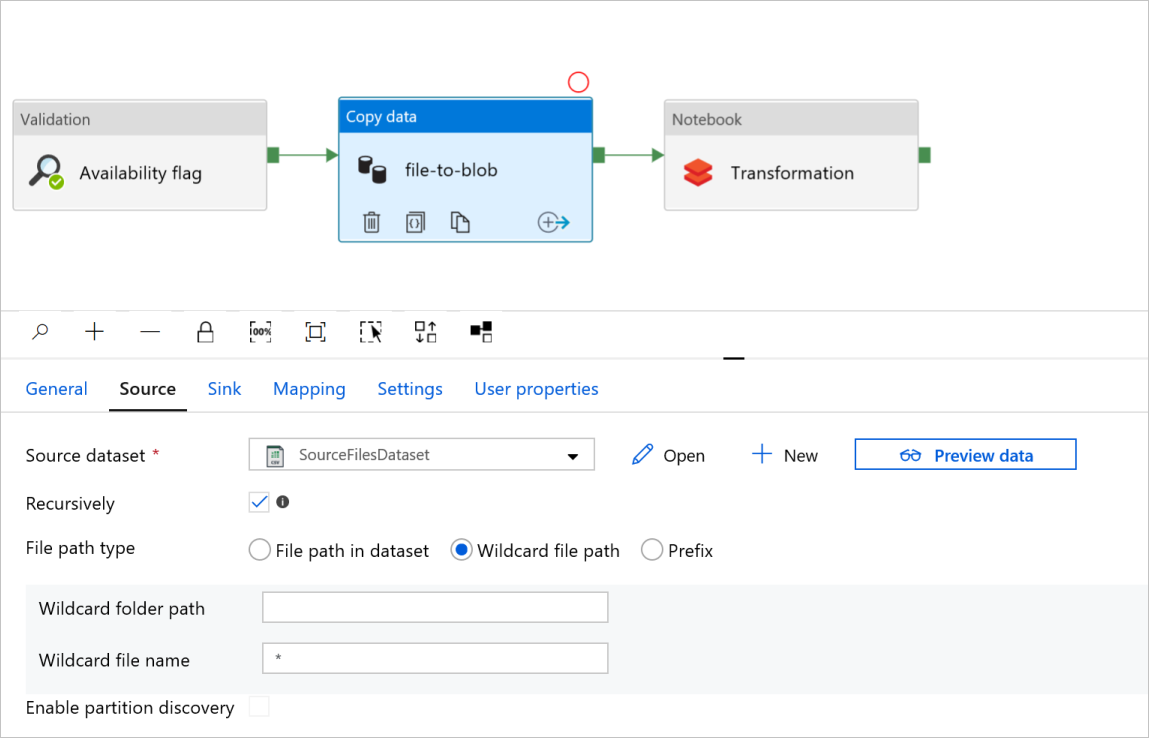
I fil-till-blob-filen Kopiera dataaktivitet kontrollerar du flikarna Källa och Mottagare. Ändra inställningarna om det behövs.
Fliken Källa
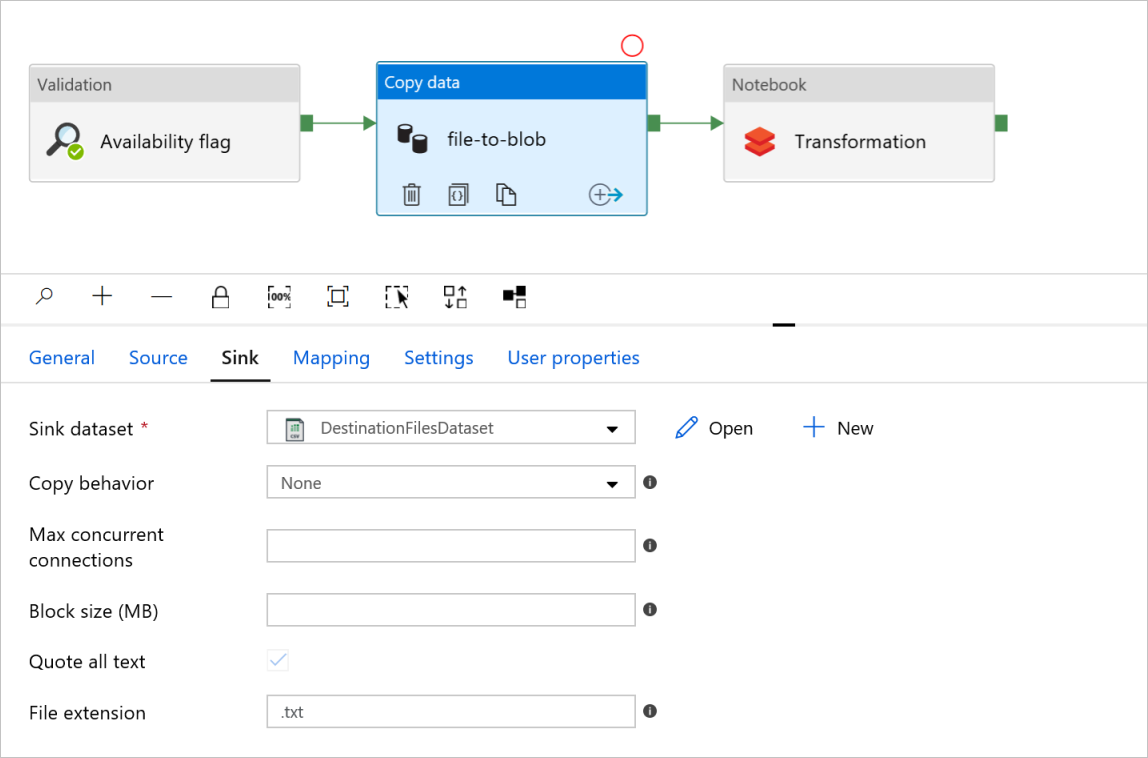
Fliken Mottagare
Granska och uppdatera sökvägarna och inställningarna efter behov i notebook-aktivitetstransformeringen.
Den länkade Databricks-tjänsten bör fyllas i i förväg med värdet från ett tidigare steg, enligt följande:
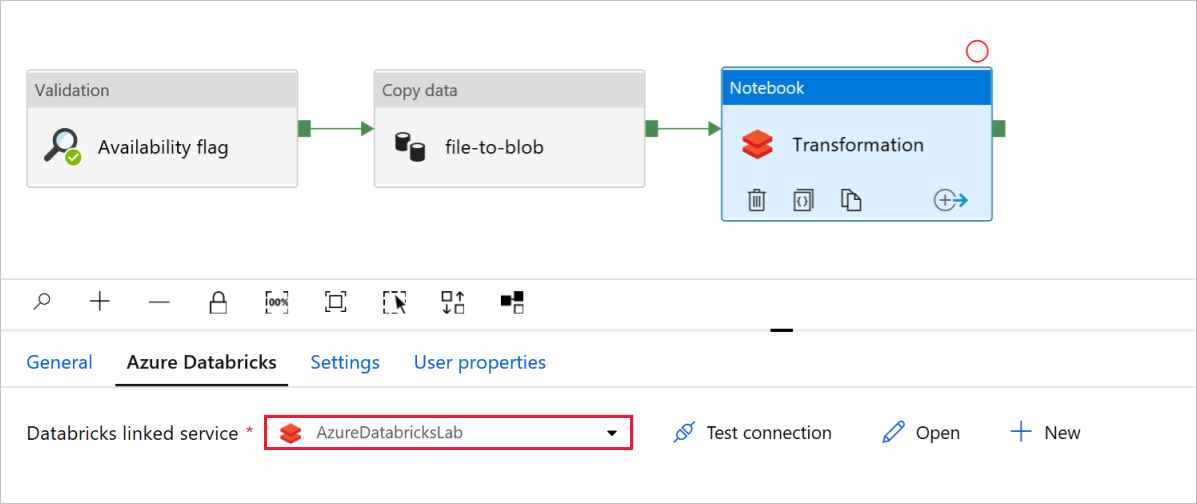
Så här kontrollerar du notebook-inställningarna :
Välj fliken Inställningar . Kontrollera att standardsökvägen är korrekt för Notebook-sökvägen. Du kan behöva bläddra och välja rätt notebook-sökväg.
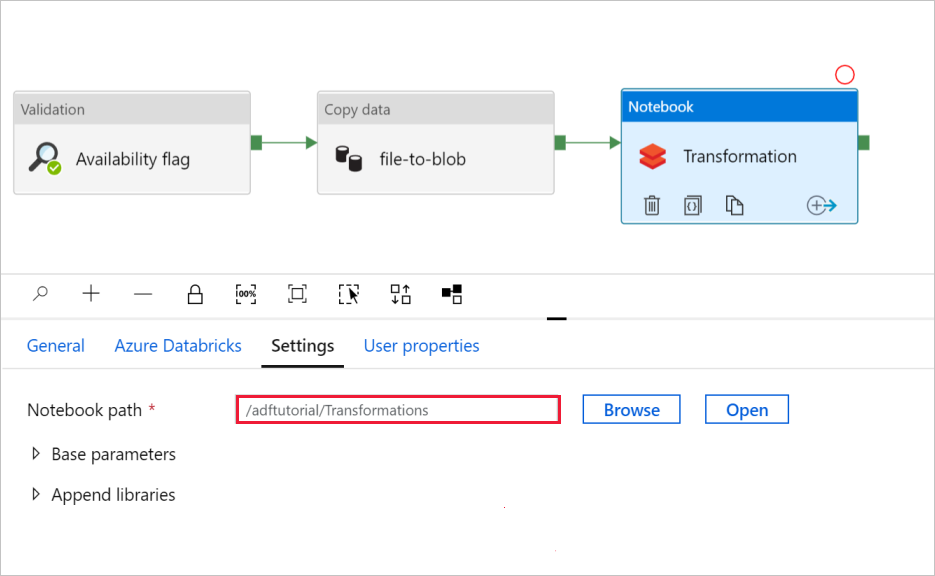
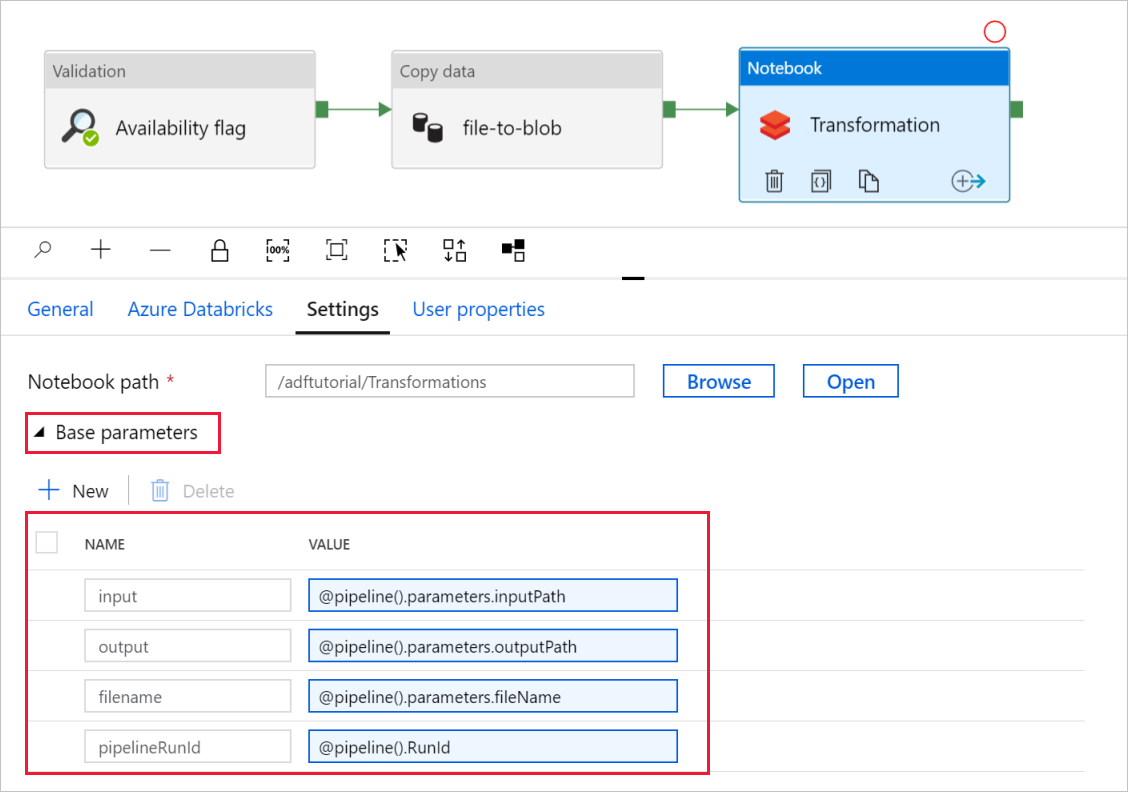
Expandera väljaren Basparametrar och kontrollera att parametrarna matchar det som visas i följande skärmbild. Dessa parametrar skickas till Databricks-notebook-filen från Data Factory.
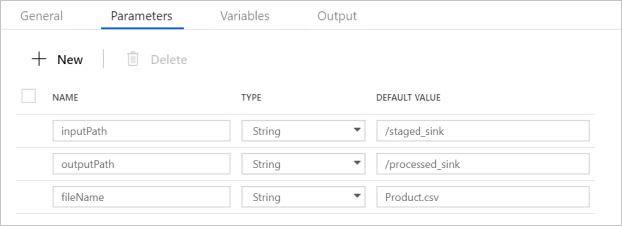
Kontrollera att pipelineparametrarna matchar det som visas på följande skärmbild:
Anslut till dina datauppsättningar.
Kommentar
I datauppsättningarna nedan har filsökvägen angetts automatiskt i mallen. Om det krävs ändringar kontrollerar du att du anger sökvägen för både containern och katalogen om det skulle uppstå anslutningsfel.
SourceAvailabilityDataset – för att kontrollera att källdata är tillgängliga.
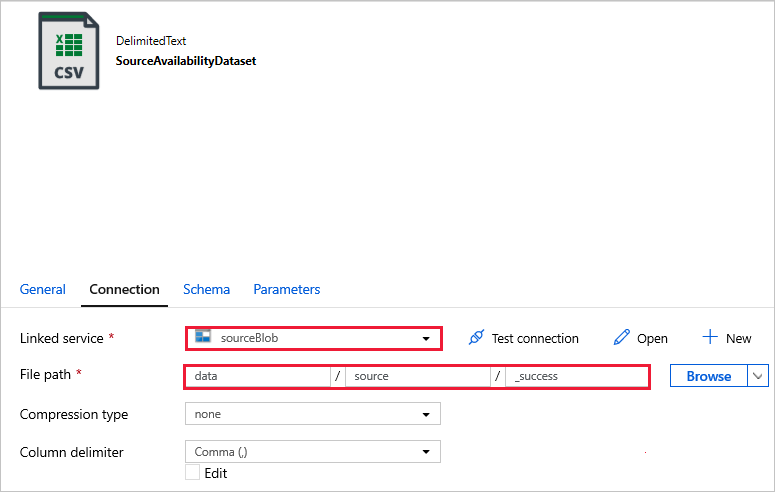
SourceFilesDataset – för att komma åt källdata.
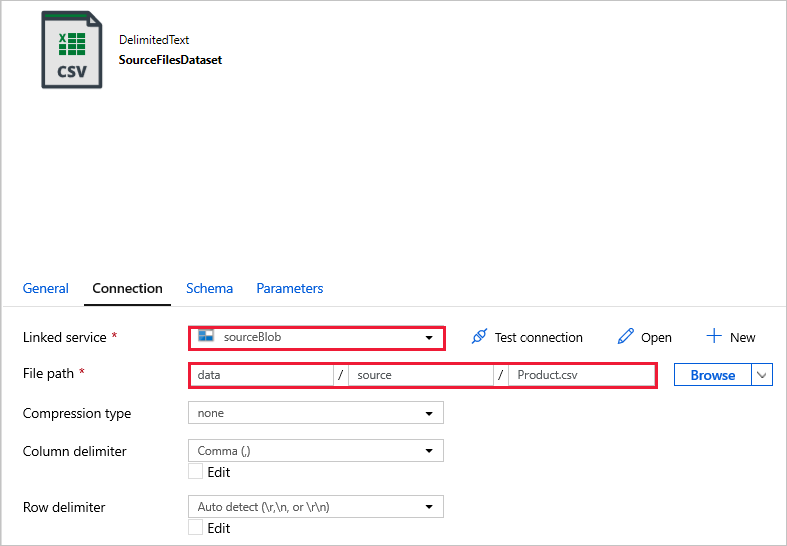
DestinationFilesDataset – för att kopiera data till målplatsen för mottagare. Ange följande värden:
Länkad tjänst -
sinkBlob_LSsom skapades i ett tidigare steg.Filsökväg -
sinkdata/staged_sink.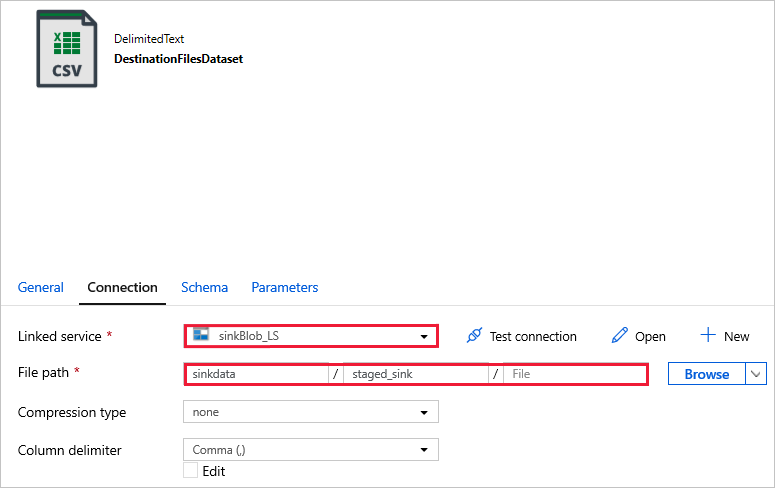
Välj Felsök för att köra pipelinen. Du hittar länken till Databricks-loggar för mer detaljerade Spark-loggar.
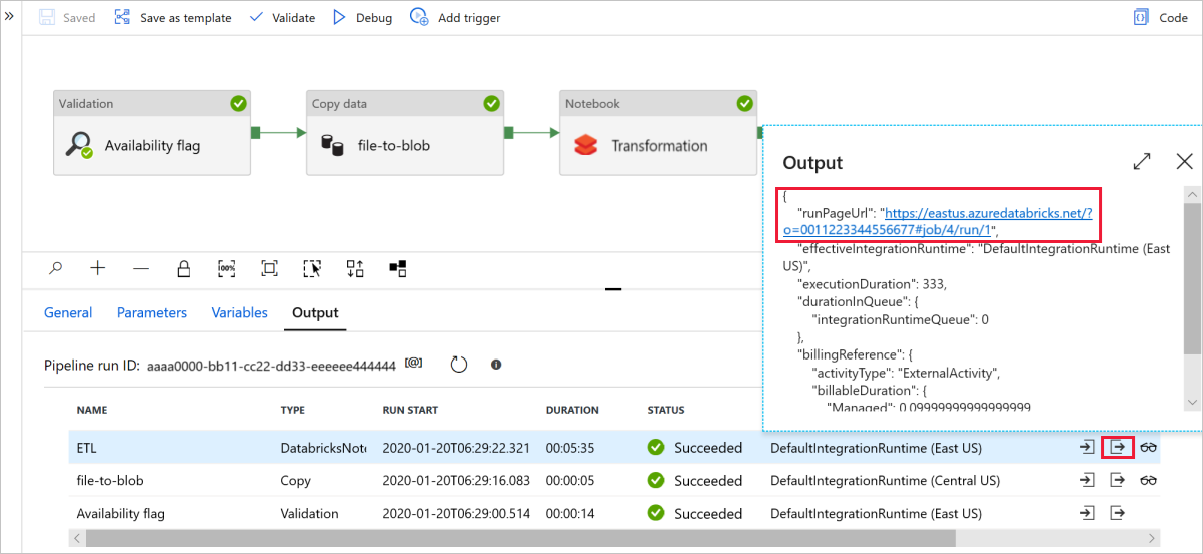
Du kan också verifiera datafilen med hjälp av Azure Storage Explorer.
Kommentar
För korrelering med Data Factory-pipelinekörningar lägger det här exemplet till pipelinekörnings-ID:t från datafabriken till utdatamappen. Detta hjälper till att hålla reda på filer som genereras av varje körning.