Dataintegrering med Azure Data Factory och Azure Data Share
GÄLLER FÖR:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dricks
Prova Data Factory i Microsoft Fabric, en allt-i-ett-analyslösning för företag. Microsoft Fabric omfattar allt från dataflytt till datavetenskap, realtidsanalys, business intelligence och rapportering. Lär dig hur du startar en ny utvärderingsversion kostnadsfritt!
När kunderna påbörjar sina moderna datalager- och analysprojekt behöver de inte bara mer data utan också mer insyn i sina data i sin dataegendom. I den här workshopen går vi in på hur förbättringar av Azure Data Factory och Azure Data Share förenklar dataintegrering och hantering i Azure.
Från att aktivera kodfri ETL/ELT till att skapa en omfattande vy över dina data, ger förbättringar i Azure Data Factory dina datatekniker möjlighet att på ett säkert sätt ta in mer data, och därmed mer värde, till ditt företag. Med Azure Data Share kan du göra affärer med företagsdelning på ett styrt sätt.
I den här workshopen använder du Azure Data Factory (ADF) för att mata in data från Azure SQL Database till Azure Data Lake Storage Gen2 (ADLS Gen2). När du har landställt data i sjön transformerar du dem via mappning av dataflöden, datafabrikens interna transformeringstjänst och sänker dem till Azure Synapse Analytics. Sedan delar du tabellen med transformerade data tillsammans med lite extra data med hjälp av Azure Data Share.
De data som används i det här labbet är Taxidata för New York City. Om du vill importera den till databasen i SQL Database laddar du ned bacpac-filen taxi-data. Välj alternativet Ladda ned råfil i GitHub.
Förutsättningar
Azure-prenumeration: Om du inte har någon Azure-prenumeration kan du skapa ett kostnadsfritt konto innan du börjar.
Azure SQL Database: Om du inte har någon Azure SQL Database kan du lära dig hur du skapar en SQL Database.
Azure Data Lake Storage Gen2-lagringskonto: Om du inte har något ADLS Gen2-lagringskonto kan du lära dig hur du skapar ett ADLS Gen2-lagringskonto.
Azure Synapse Analytics: Om du inte har en Azure Synapse Analytics-arbetsyta lär du dig hur du kommer igång med Azure Synapse Analytics.
Azure Data Factory: Om du inte har någon datafabrik kan du se hur du skapar en datafabrik.
Azure Data Share: Om du inte har någon dataresurs kan du läsa om hur du skapar en dataresurs.
Konfigurera din Azure Data Factory-miljö
I det här avsnittet får du lära dig hur du kommer åt Azure Data Factory-användarupplevelsen (ADF UX) från Azure Portal. Väl i ADF UX konfigurerar du tre länkade tjänster för vart och ett av de datalager som vi använder: Azure SQL Database, ADLS Gen2 och Azure Synapse Analytics.
I länkade Azure Data Factory-tjänster definierar du anslutningsinformationen till externa resurser. Azure Data Factory stöder för närvarande över 85 anslutningsappar.
Öppna Azure Data Factory UX
Öppna Azure Portal i Antingen Microsoft Edge eller Google Chrome.
Använd sökfältet överst på sidan och sök efter Datafabriker.
Välj din datafabriksresurs för att öppna dess resurser i den vänstra rutan.
Välj Öppna Azure Data Factory Studio. Data Factory Studio kan också nås direkt på adf.azure.com.

Du omdirigeras till startsidan för ADF i Azure Portal. Den här sidan innehåller snabbstarter, instruktionsvideor och länkar till självstudier för att lära dig begrepp i datafabriken. Börja redigera genom att välja pennikonen i det vänstra sidofältet.


Skapa en länkad Azure SQL Database-tjänst
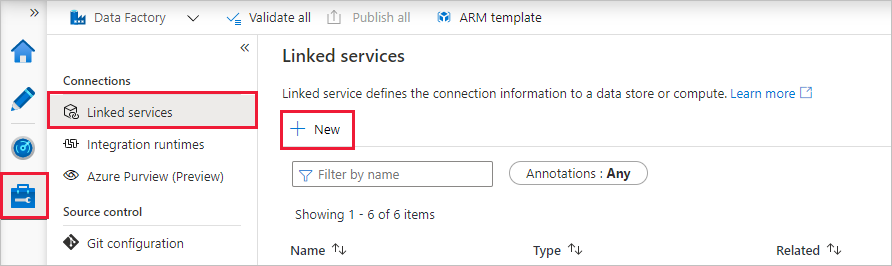
Om du vill skapa en länkad tjänst väljer du Hantera hubb i det vänstra sidofältet. I fönstret Anslutningar väljer du Länkade tjänster och sedan Nytt för att lägga till en ny länkad tjänst.
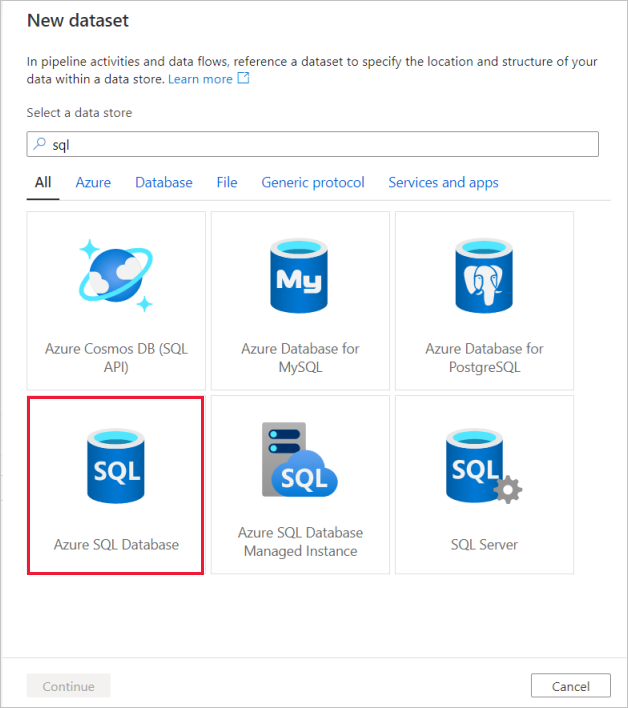
Den första länkade tjänsten som du konfigurerar är en Azure SQL Database. Du kan använda sökfältet för att filtrera datalagerlistan. Välj på Azure SQL Database-panelen och välj fortsätt.

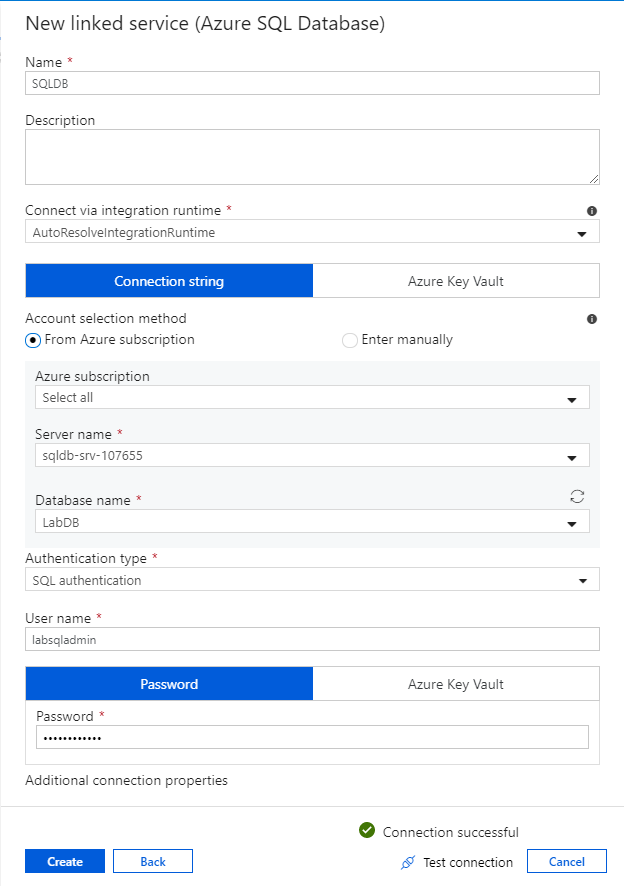
I konfigurationsfönstret för SQL Database anger du "SQLDB" som ditt länkade tjänstnamn. Ange dina autentiseringsuppgifter för att tillåta att datafabriken ansluter till databasen. Om du använder SQL-autentisering anger du i servernamnet, databasen, ditt användarnamn och lösenord. Du kan kontrollera att anslutningsinformationen är korrekt genom att välja Testa anslutning. Välj Skapa när du är klar.

Skapa en länkad Azure Synapse Analytics-tjänst
Upprepa samma process för att lägga till en länkad Azure Synapse Analytics-tjänst. På fliken Anslutningar väljer du Nytt. Välj panelen Azure Synapse Analytics och välj fortsätt.
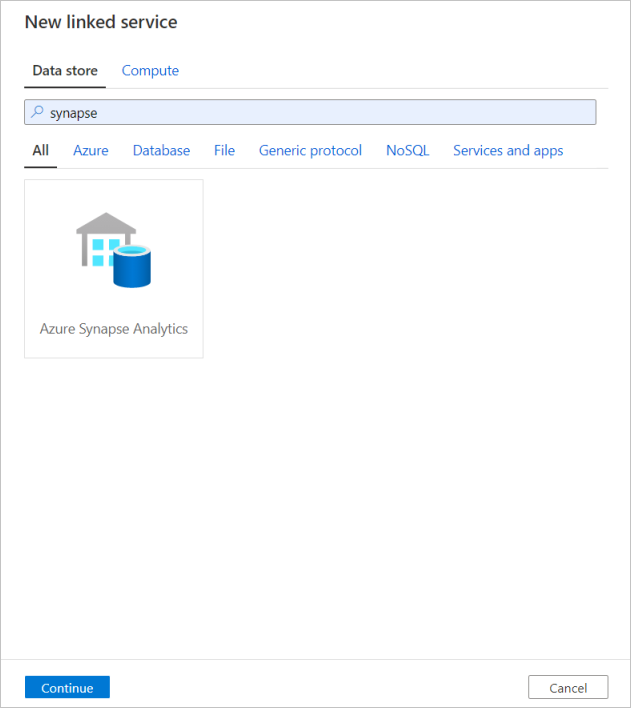
I konfigurationsfönstret för länkad tjänst anger du "SQLDW" som ditt länkade tjänstnamn. Ange dina autentiseringsuppgifter för att tillåta att datafabriken ansluter till databasen. Om du använder SQL-autentisering anger du i servernamnet, databasen, ditt användarnamn och lösenord. Du kan kontrollera att anslutningsinformationen är korrekt genom att välja Testa anslutning. Välj Skapa när du är klar.
Skapa en länkad Azure Data Lake Storage Gen2-tjänst
Den senaste länkade tjänsten som behövs för det här labbet är en Azure Data Lake Storage Gen2. På fliken Anslutningar väljer du Nytt. Välj panelen Azure Data Lake Storage Gen2 och välj fortsätt.
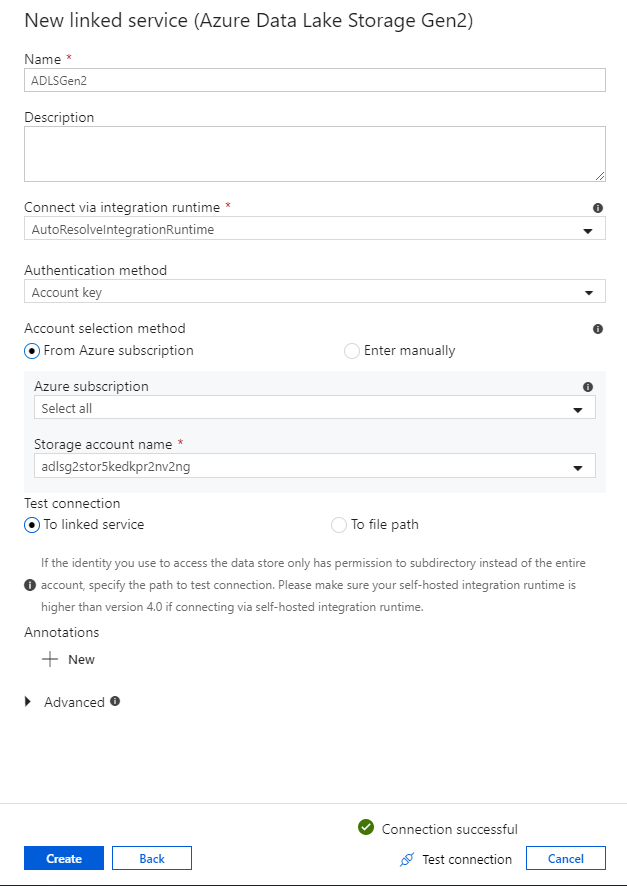
I konfigurationsfönstret för länkad tjänst anger du "ADLSGen2" som ditt länkade tjänstnamn. Om du använder kontonyckelautentisering väljer du ditt ADLS Gen2-lagringskonto i listrutan Lagringskontonamn . Du kan kontrollera att anslutningsinformationen är korrekt genom att välja Testa anslutning. Välj Skapa när du är klar.
Aktivera felsökningsläge för dataflöde
I avsnittet Transformera data med hjälp av mappningsdataflöde skapar du mappning av dataflöden. Bästa praxis innan du skapar mappning av dataflöden är att aktivera felsökningsläge, vilket gör att du kan testa transformeringslogik på några sekunder på ett aktivt Spark-kluster.
Om du vill aktivera felsökning väljer du skjutreglaget För felsökning av dataflöde i det övre fältet för arbetsytan för dataflöden eller pipelinearbetsytan när du har dataflödesaktiviteter . Välj OK när bekräftelsedialogrutan visas. Klustret startar om cirka 5 till 7 minuter. Fortsätt att mata in data från Azure SQL Database till ADLS Gen2 med hjälp av kopieringsaktiviteten när den initieras.

Mata in data med kopieringsaktiviteten
I det här avsnittet skapar du en pipeline med en kopieringsaktivitet som matar in en tabell från en Azure SQL Database till ett ADLS Gen2-lagringskonto. Du lär dig hur du lägger till en pipeline, konfigurerar en datauppsättning och felsöker en pipeline via ADF UX. Konfigurationsmönstret som används i det här avsnittet kan tillämpas på kopiering från ett relationsdatalager till ett filbaserat datalager.
I Azure Data Factory är en pipeline en logisk gruppering av aktiviteter som tillsammans utför en uppgift. En aktivitet definierar en åtgärd som ska utföras på dina data. En datauppsättning pekar på de data som du vill använda i en länkad tjänst.
Skapa en pipeline med en kopieringsaktivitet
I fönstret Fabriksresurser väljer du på plusikonen för att öppna den nya resursmenyn. Välj Pipeline.
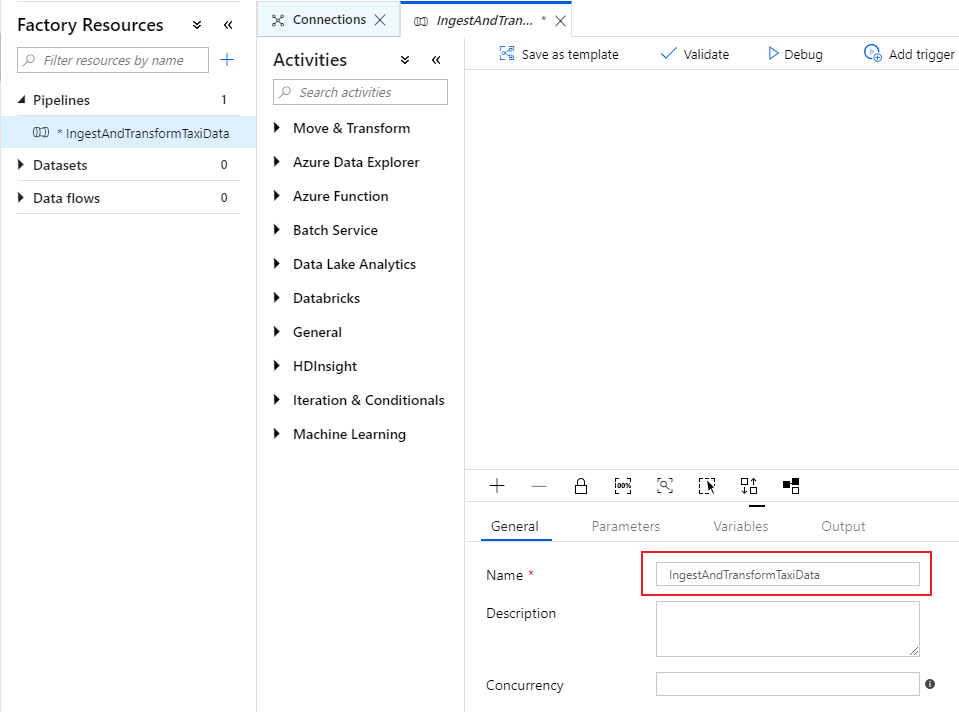
På fliken Allmänt på pipelinearbetsytan ger du pipelinen ett beskrivande namn, till exempel "IngestAndTransformTaxiData".
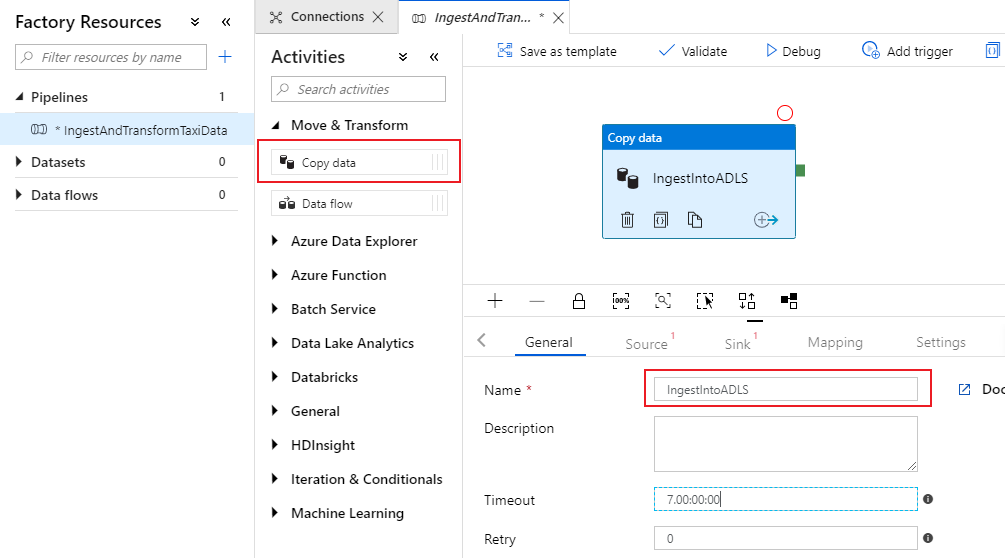
Öppna dragspelet Flytta och transformera i åtgärdsfönstret på pipelinearbetsytan och dra aktiviteten Kopiera data till arbetsytan. Ge kopieringsaktiviteten ett beskrivande namn, till exempel "IngestIntoADLS".


Konfigurera Azure SQL DB-källdatauppsättning
Välj på fliken Källa för kopieringsaktiviteten. Om du vill skapa en ny datauppsättning väljer du Ny. Källan är tabellen
dbo.TripDatasom finns i den länkade tjänsten "SQLDB" som konfigurerades tidigare.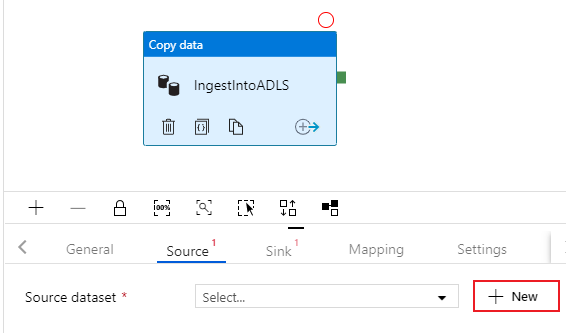
Sök efter Azure SQL Database och välj fortsätt.
Anropa din datauppsättning "TripData". Välj "SQLDB" som länkad tjänst. Välj tabellnamn
dbo.TripDatai listrutan tabellnamn. Importera schemat Från anslutning/arkiv. Välj OK när du är klar.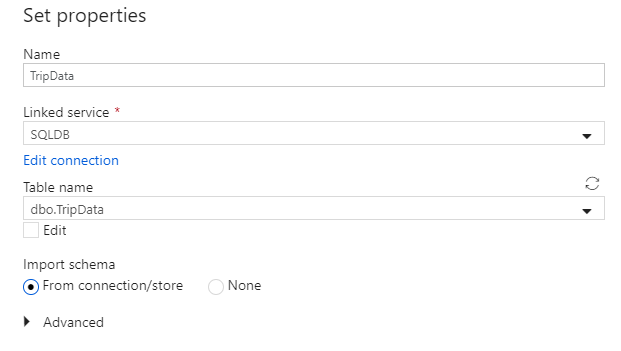
Du har skapat din källdatauppsättning. Kontrollera att standardvärdet Tabell är markerat i fältet Använd fråga i källinställningarna.
Konfigurera ADLS Gen2-mottagardatauppsättning
Välj på fliken Mottagare för kopieringsaktiviteten. Om du vill skapa en ny datauppsättning väljer du Ny.
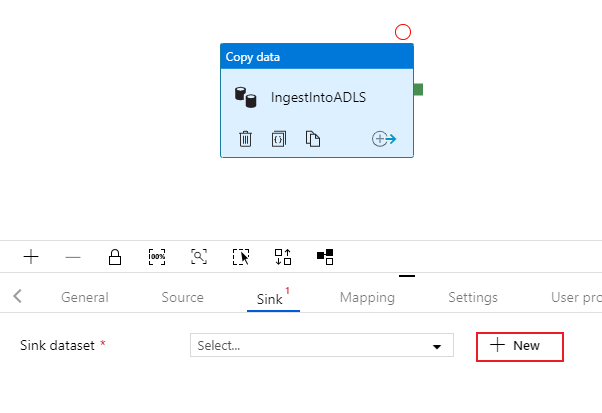
Sök efter Azure Data Lake Storage Gen2 och välj fortsätt.
I fönstret Välj format väljer du AvgränsadText när du skriver till en csv-fil. Välj Fortsätt.

Ge mottagarens datamängd namnet "TripDataCSV". Välj "ADLSGen2" som länkad tjänst. Ange var du vill skriva csv-filen. Du kan till exempel skriva dina data till filen
trip-data.csvi containernstaging-container. Ange Första raden som rubrik till true eftersom du vill att dina utdata ska ha rubriker. Eftersom det inte finns någon fil i målet ännu anger du Importera schema till Ingen. Välj OK när du är klar.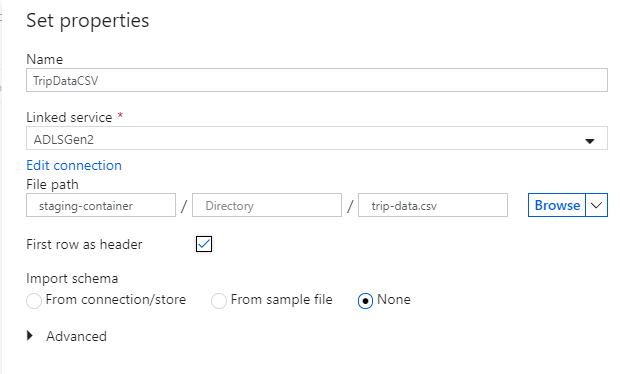
Testa kopieringsaktiviteten med en pipeline-felsökningskörning
Kontrollera att kopieringsaktiviteten fungerar korrekt genom att välja Felsök överst på pipelinearbetsytan för att köra en felsökningskörning. Med en felsökningskörning kan du testa din pipeline antingen från slutpunkt till slutpunkt eller tills en brytpunkt innan du publicerar den till datafabrikstjänsten.
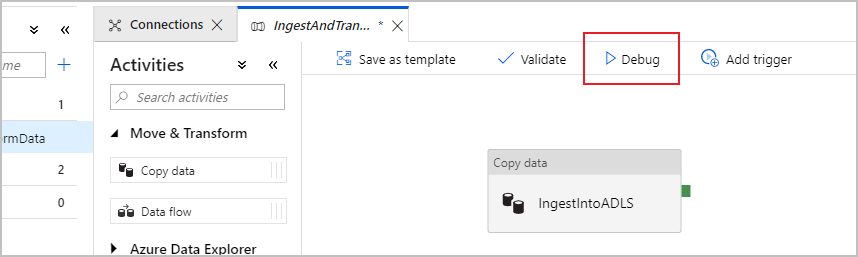
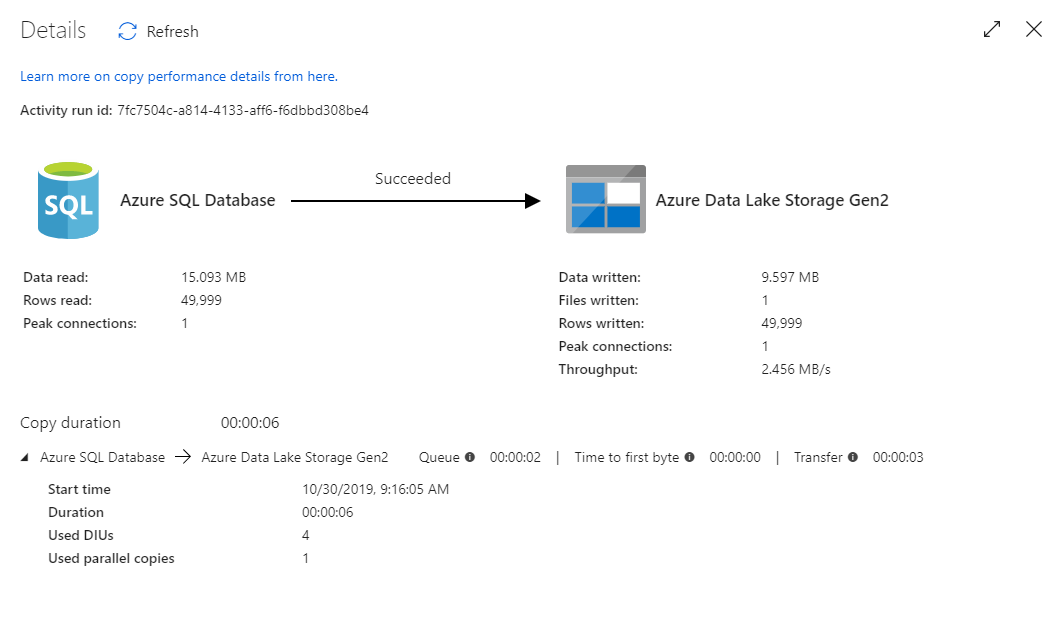
Om du vill övervaka felsökningskörningen går du till fliken Utdata på pipelinearbetsytan. Övervakningsskärmen uppdateras automatiskt var 20:e sekund eller när du väljer uppdateringsknappen manuellt. Kopieringsaktiviteten har en särskild övervakningsvy som du kan komma åt genom att välja glasögonikonen i kolumnen Åtgärder .
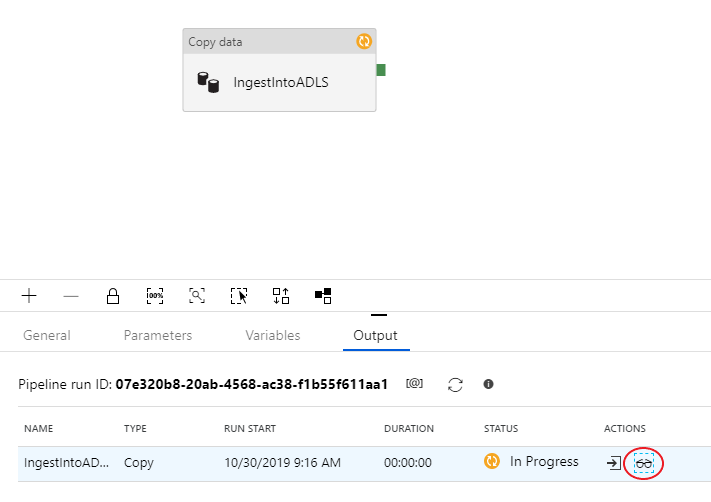
Kopieringsövervakningsvyn ger aktivitetens körningsinformation och prestandaegenskaper. Du kan se information som läsning/skrivning av data, läsning/skrivning av rader, läs-/skrivskyddade filer och dataflöde. Om du har konfigurerat allt korrekt bör du se 49 999 rader skrivna i en fil i ADLS-mottagaren.
Innan du går vidare till nästa avsnitt föreslås det att du publicerar dina ändringar i datafabrikstjänsten genom att välja Publicera alla i det översta fabriksfältet. Även om det inte beskrivs i det här labbet stöder Azure Data Factory fullständig git-integrering. Git-integrering möjliggör versionskontroll, iterativt sparande på en lagringsplats och samarbete på en datafabrik. Mer information finns i källkontroll i Azure Data Factory.


Omvandla data med Mappa dataflöden
Nu när du har kopierat data till Azure Data Lake Storage är det dags att ansluta och aggregera dessa data till ett informationslager. Vi använder dataflödet för mappning, Azure Data Factorys visuellt utformade transformeringstjänst. Genom att mappa dataflöden kan användarna utveckla en kodfri transformeringslogik och köra dem på spark-kluster som hanteras av ADF-tjänsten.
Dataflödet som skapades i det här steget ansluter datauppsättningen "TripDataCSV" som skapades i föregående avsnitt med en tabell dbo.TripFares som lagras i "SQLDB" baserat på fyra nyckelkolumner. Sedan aggregeras data baserat på kolumn payment_type för att beräkna medelvärdet av vissa fält och skrivs i en Azure Synapse Analytics-tabell.
Lägga till en dataflödesaktivitet i din pipeline
Öppna dragspelet Flytta och transformera i åtgärdsfönstret på pipelinearbetsytan och dra dataflödesaktiviteten till arbetsytan.
I sidofönstret som öppnas väljer du Skapa nytt dataflöde och väljer Mappa dataflöde. Välj OK.
Du dirigeras till dataflödesarbetsytan där du skapar omvandlingslogiken. På fliken Allmänt namnger du dataflödet "JoinAndAggregateData".


Konfigurera csv-källa för resedata
Det första du vill göra är att konfigurera dina två källtransformeringar. Den första källan pekar på datauppsättningen "TripDataCSV" DelimitedText. Om du vill lägga till en källtransformering väljer du i rutan Lägg till källa på arbetsytan.
Ge källan namnet "TripDataCSV" och välj datauppsättningen "TripDataCSV" i listrutan källa. Om du kommer ihåg importerar du inte ett schema från början när du skapade den här datamängden eftersom det inte fanns några data där. Eftersom
trip-data.csvdet finns nu väljer du Redigera för att gå till fliken inställningar för datauppsättning.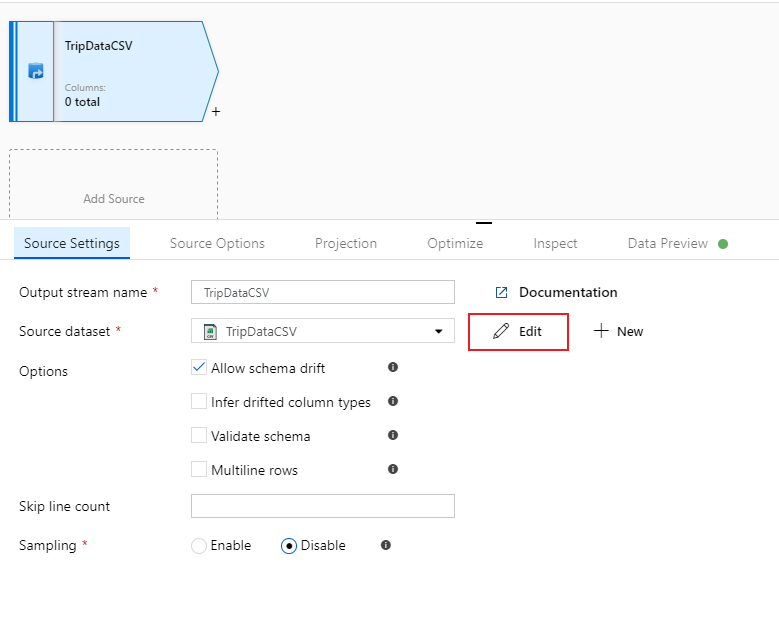
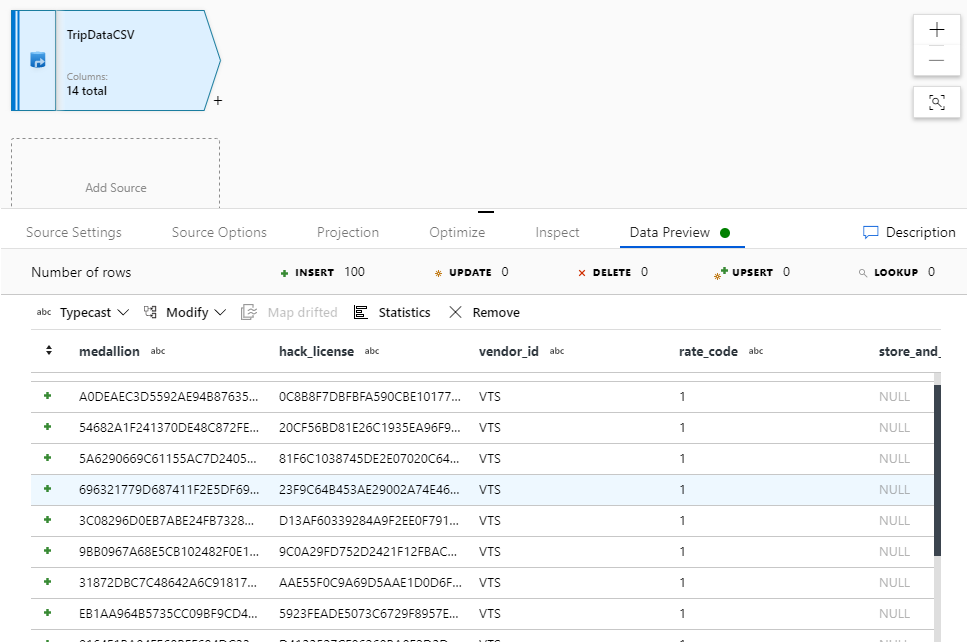
Gå till fliken Schema och välj Importera schema. Välj Från anslutning/arkiv för att importera direkt från filarkivet. 14 kolumner av typen sträng ska visas.

Gå tillbaka till dataflödet "JoinAndAggregateData". Om felsökningsklustret har startat (indikeras av en grön cirkel bredvid felsökningsreglaget) kan du hämta en ögonblicksbild av data på fliken Dataförhandsgranskning . Välj Uppdatera om du vill hämta en förhandsgranskning av data.


Kommentar
Dataförhandsvisning skriver inte data.
Konfigurera din resa priser SQL Database källa
Den andra källan som du lägger till punkter i SQL Database-tabellen
dbo.TripFares. Under din TripDataCSV-källa finns det en annan rutan Lägg till källa . Välj den för att lägga till en ny källtransformering.
Ge den här källan namnet "TripFaresSQL". Välj Nytt bredvid källdatauppsättningsfältet för att skapa en ny SQL Database-datauppsättning.
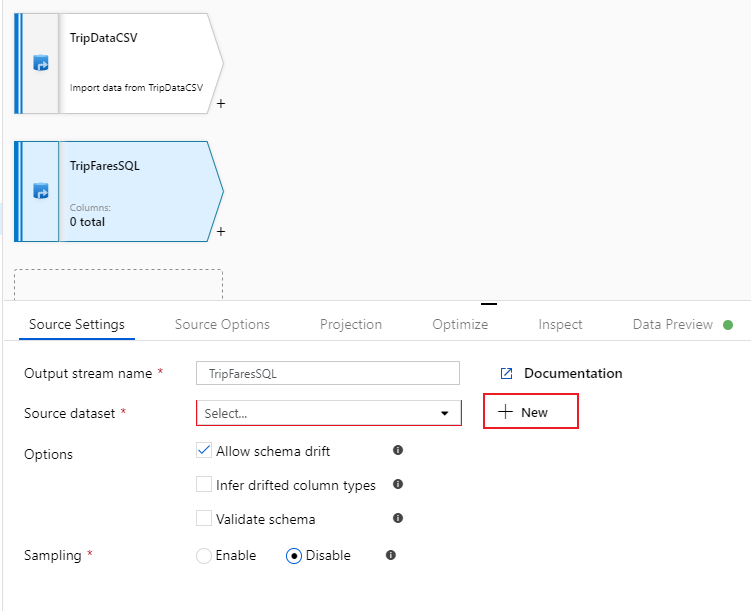
Välj Azure SQL Database-panelen och välj fortsätt. Du kanske märker att många av anslutningsapparna i datafabriken inte stöds i mappning av dataflöde. Om du vill omvandla data från en av dessa källor matar du in dem i en källa som stöds med hjälp av kopieringsaktiviteten.

Anropa din datauppsättning "TripFares". Välj "SQLDB" som länkad tjänst. Välj tabellnamn
dbo.TripFaresi listrutan tabellnamn. Importera schemat Från anslutning/arkiv. Välj OK när du är klar.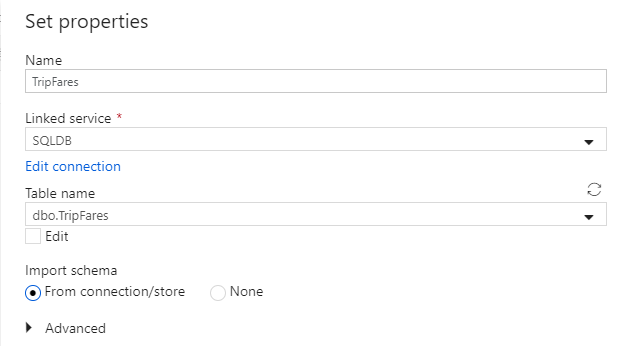
Om du vill verifiera dina data hämtar du en förhandsversion av data på fliken Dataförhandsgranskning .
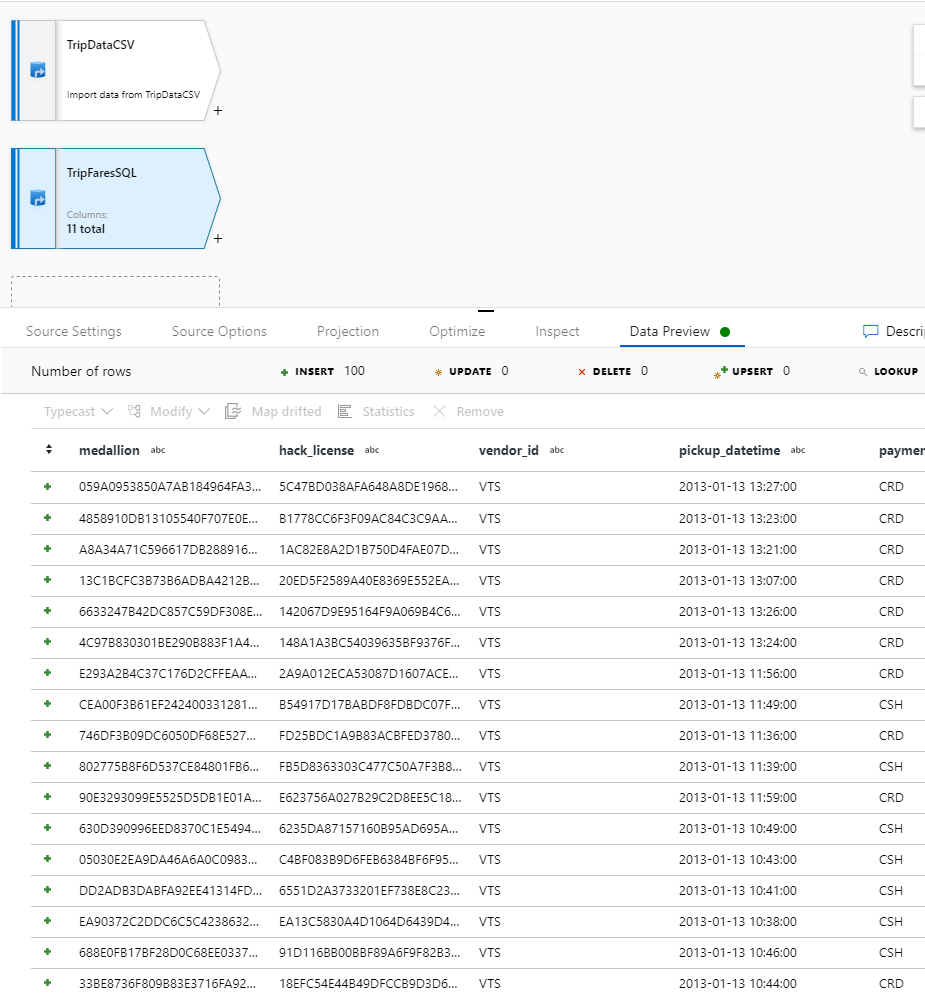

Inre koppling TripDataCSV och TripFaresSQL
Om du vill lägga till en ny transformering väljer du plusikonen i det nedre högra hörnet av "TripDataCSV". Under Flera indata/utdata väljer du Anslut.
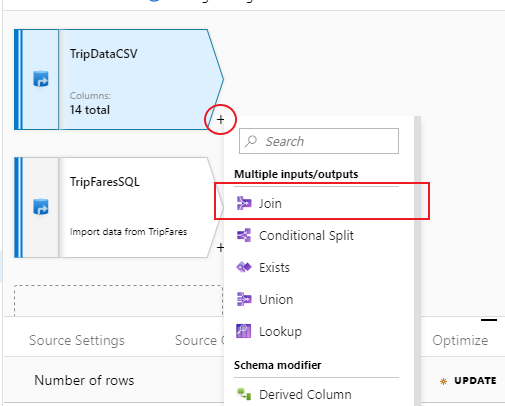
Ge din kopplingstransformeringen namnet "InnerJoinWithTripFares". Välj "TripFaresSQL" i listrutan för rätt dataström. Välj Inre som kopplingstyp. Mer information om de olika kopplingstyperna i mappning av dataflöde finns i kopplingstyper.
Välj vilka kolumner som du vill matcha på från varje ström via listrutan Kopplingsvillkor . Om du vill lägga till ytterligare ett kopplingsvillkor väljer du på plusikonen bredvid ett befintligt villkor. Som standard kombineras alla kopplingsvillkor med en AND-operator, vilket innebär att alla villkor måste uppfyllas för en matchning. I den här labbuppgiften vill vi matcha kolumnerna
medallion,hack_license,vendor_idochpickup_datetime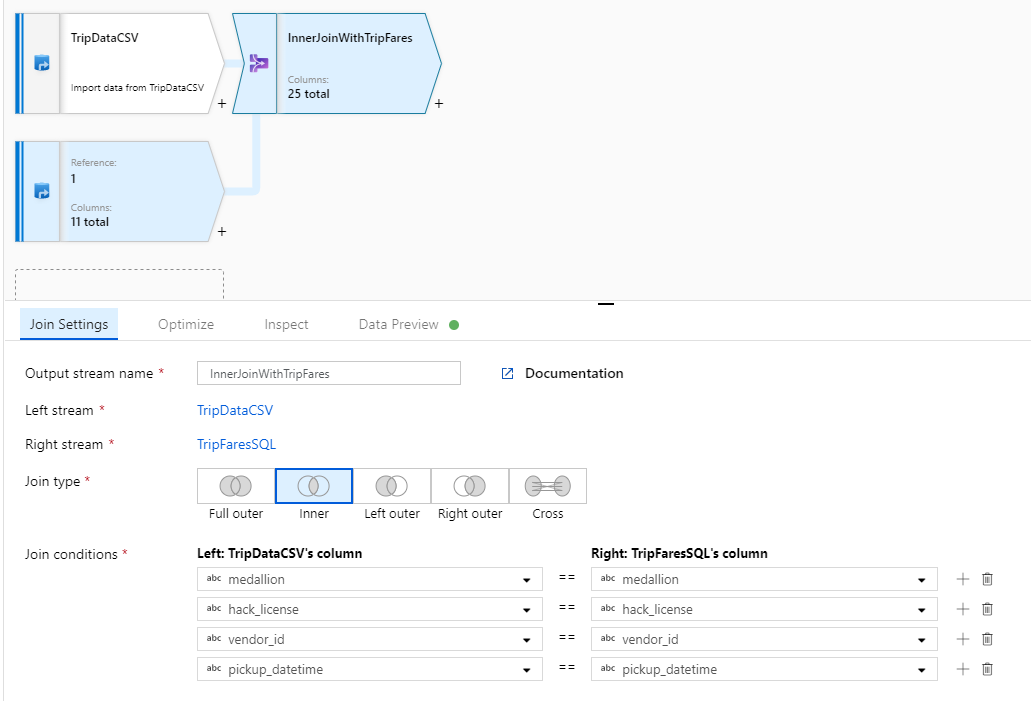
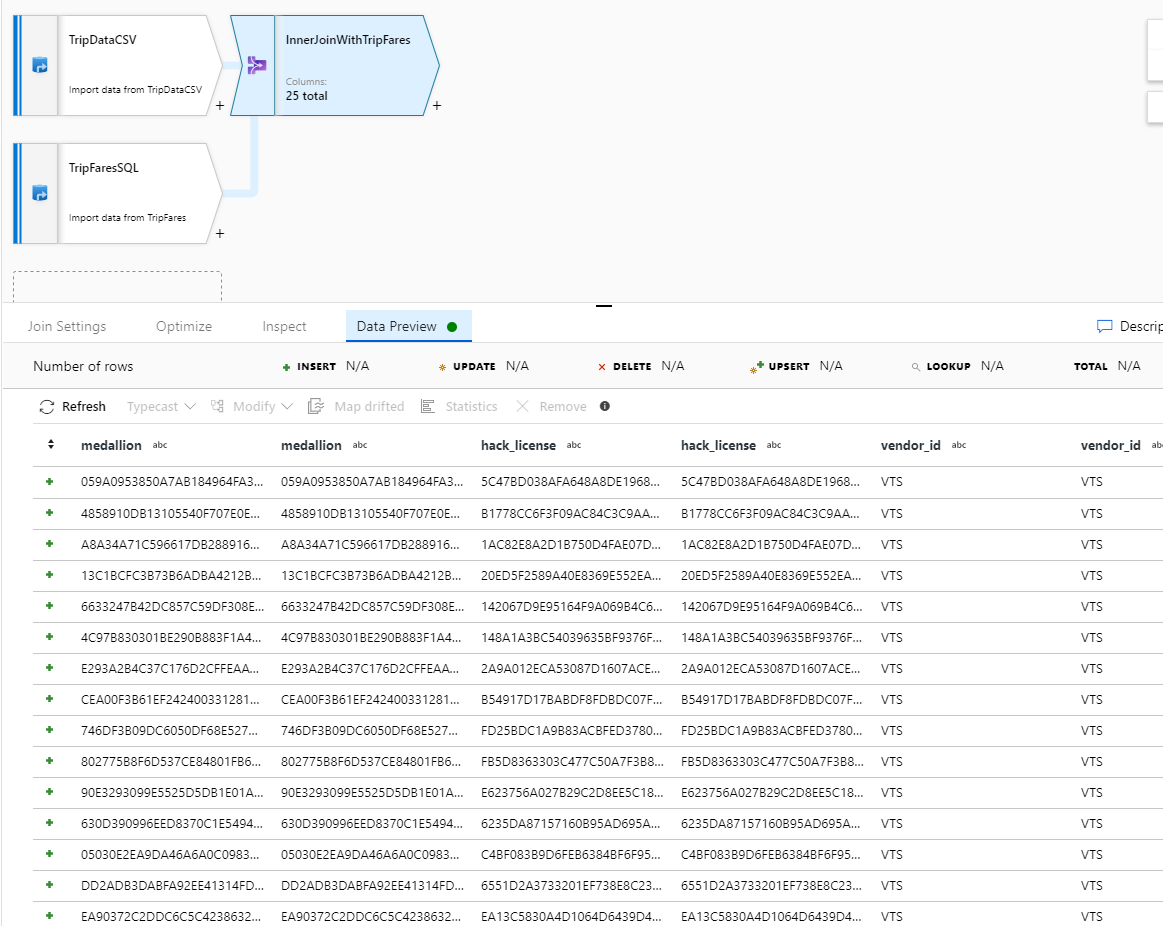
Kontrollera att du har anslutit 25 kolumner tillsammans med en förhandsversion av data.


Aggregera efter payment_type
När du har slutfört din kopplingstransformering lägger du till en aggregerad transformering genom att välja plusikonen bredvid InnerJoinWithTripFares. Välj Aggregera under Schemamodifierare.
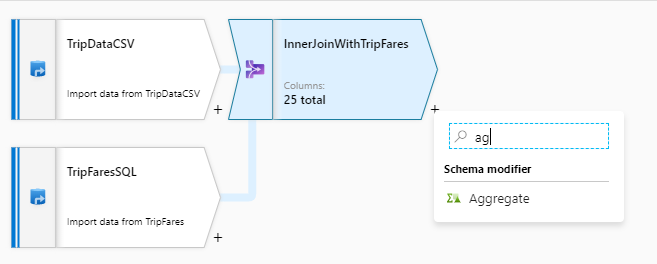
Ge din aggregerade omvandling namnet "AggregateByPaymentType". Välj
payment_typesom grupp efter kolumn.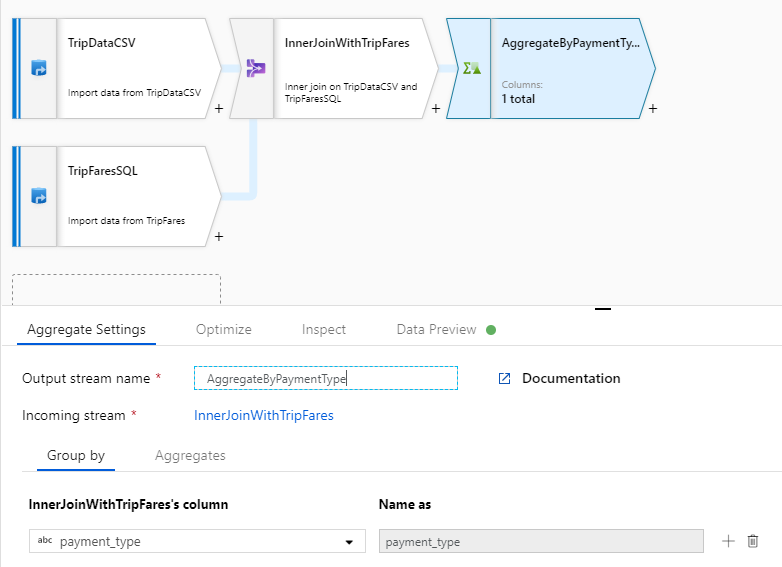
Gå till fliken Aggregeringar . Ange två sammansättningar:
- Det genomsnittliga priset grupperat efter betalningstyp
- Det totala reseavståndet grupperat efter betalningstyp
Först skapar du det genomsnittliga biljettuttrycket. I textrutan med etiketten Lägg till eller välj en kolumn anger du "average_fare".
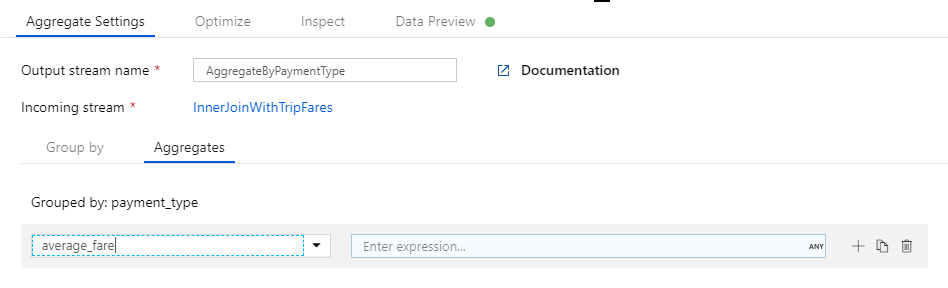
Om du vill ange ett aggregeringsuttryck väljer du den blå rutan med etiketten Returuttryck, som öppnar byggare för dataflödesuttryck, ett verktyg som används för att visuellt skapa dataflödesuttryck med hjälp av indataschema, inbyggda funktioner och åtgärder samt användardefinierade parametrar. Mer information om funktionerna i uttrycksverktyget finns i dokumentationen för uttrycksverktyget.
Om du vill hämta det genomsnittliga priset använder du
avg()aggregeringsfunktionen för att aggregera kolumnomkastningentotal_amounttill ett heltal medtoInteger(). I dataflödesuttrycksspråket definieras detta somavg(toInteger(total_amount)). Välj Spara och slutför när du är klar.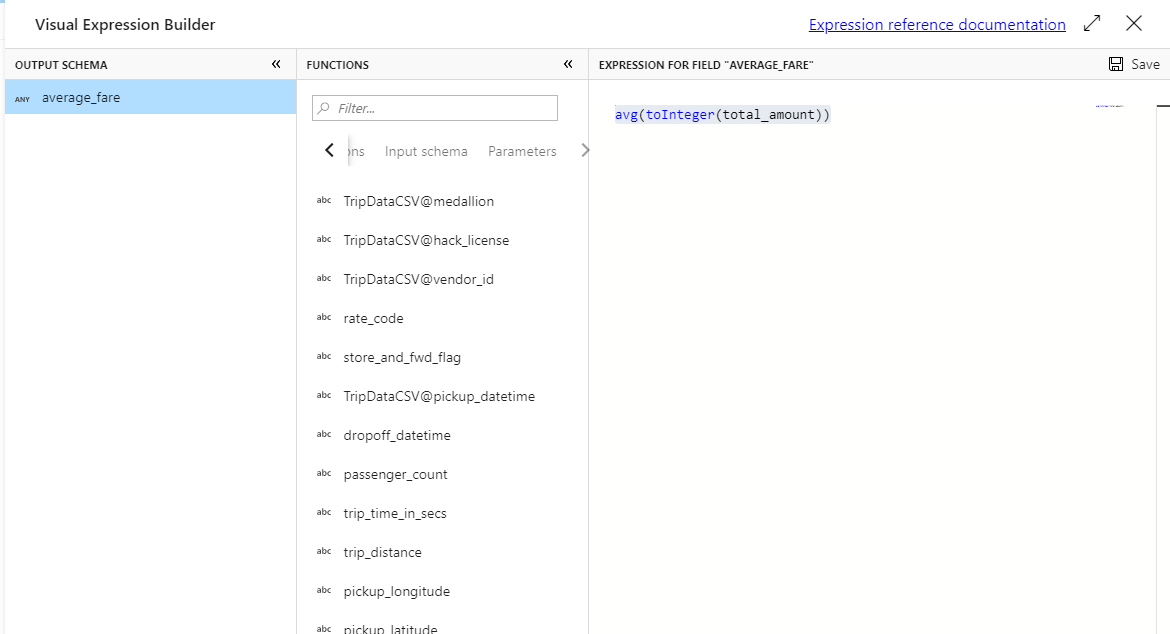
Om du vill lägga till ett extra aggregeringsuttryck väljer du på plusikonen bredvid
average_fare. Välj Lägg till kolumn.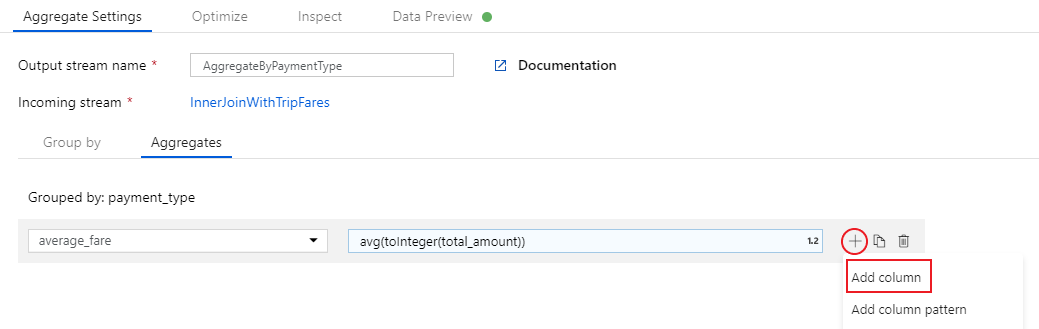
I textrutan med etiketten Lägg till eller välj en kolumn anger du "total_trip_distance". Precis som i det sista steget öppnar du uttrycksverktyget för att ange i uttrycket.
Om du vill hämta det totala reseavståndet
sum()använder du aggregeringsfunktionen för att aggregera kolumngjutningentrip_distancetill ett heltal medtoInteger(). I dataflödesuttrycksspråket definieras detta somsum(toInteger(trip_distance)). Välj Spara och slutför när du är klar.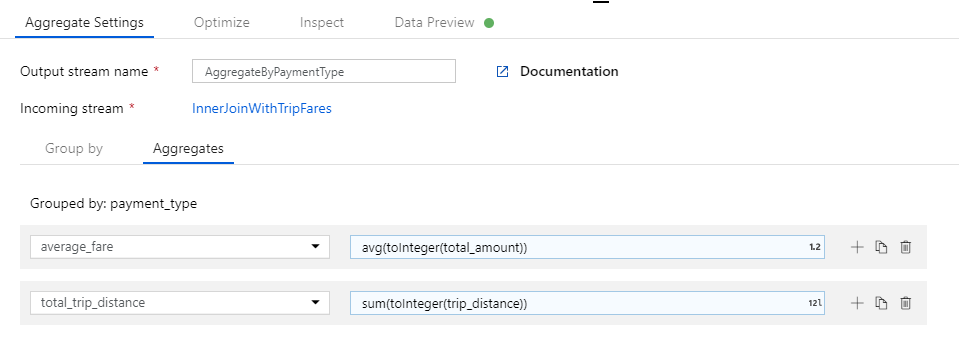
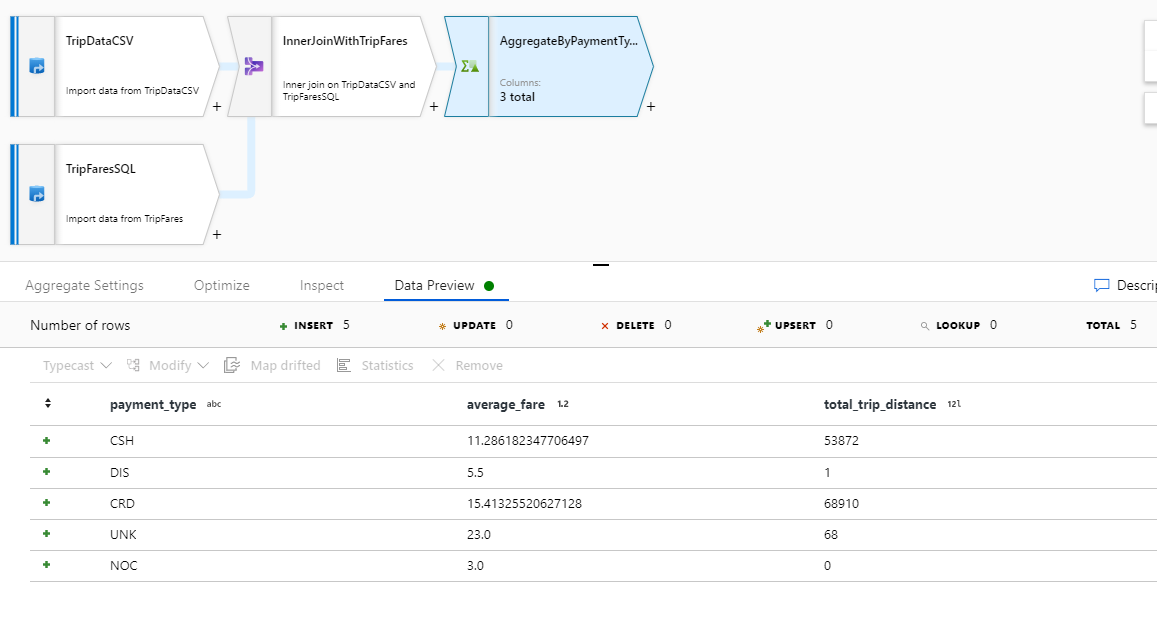
Testa omvandlingslogik på fliken Dataförhandsgranskning . Som du ser finns det färre rader och kolumner än tidigare. Endast de tre grupperna efter och aggregeringskolumnerna som definierats i den här omvandlingen fortsätter nedströms. Eftersom det bara finns fem betalningstypsgrupper i exemplet matas endast fem rader ut.





Konfigurera azure Synapse Analytics-mottagare
Nu när vi har slutfört vår omvandlingslogik är vi redo att sänka våra data i en Azure Synapse Analytics-tabell. Lägg till en mottagartransformering under avsnittet Mål .
Ge mottagaren namnet "SQLDWSink". Välj Nytt bredvid datauppsättningsfältet för mottagare för att skapa en ny Azure Synapse Analytics-datauppsättning.
Välj panelen Azure Synapse Analytics och välj fortsätt.
Anropa datamängden "AggregatedTaxiData". Välj "SQLDW" som länkad tjänst. Välj Skapa ny tabell och ge den nya tabellen
dbo.AggregateTaxiDatanamnet . Välj OK när du är klar.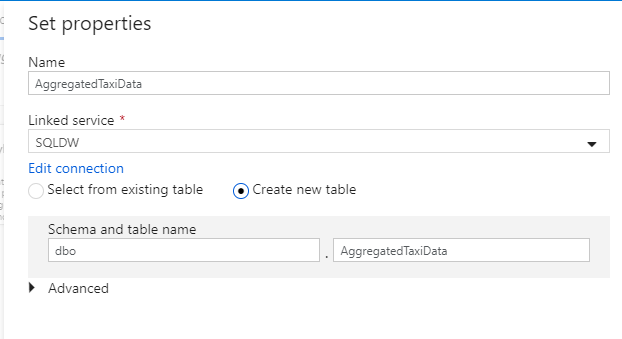
Gå till fliken Inställningar i mottagaren. Eftersom vi skapar en ny tabell måste vi välja Återskapa tabell under tabellåtgärd. Avmarkera Aktivera mellanlagring, vilket växlar om vi infogar rad för rad eller i batch.
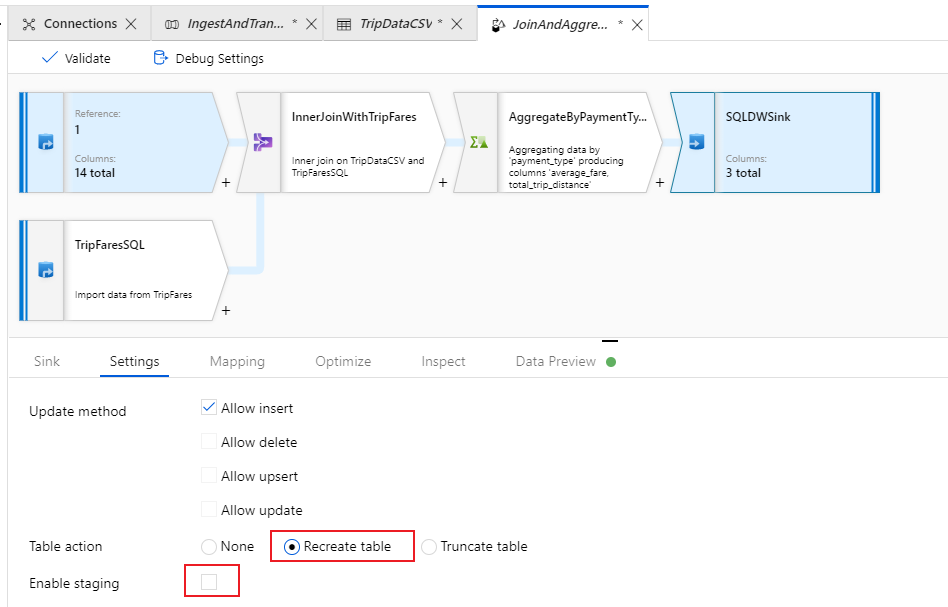


Du har skapat dataflödet. Nu är det dags att köra den i en pipelineaktivitet.
Felsöka pipelinen från slutpunkt till slutpunkt
Gå tillbaka till fliken för IngestAndTransformData-pipeline. Lägg märke till den gröna rutan för kopieringsaktiviteten "IngestIntoADLS". Dra över den till dataflödesaktiviteten JoinAndAggregateData. Detta skapar en "vid framgång", vilket gör att dataflödesaktiviteten endast körs om kopian lyckas.
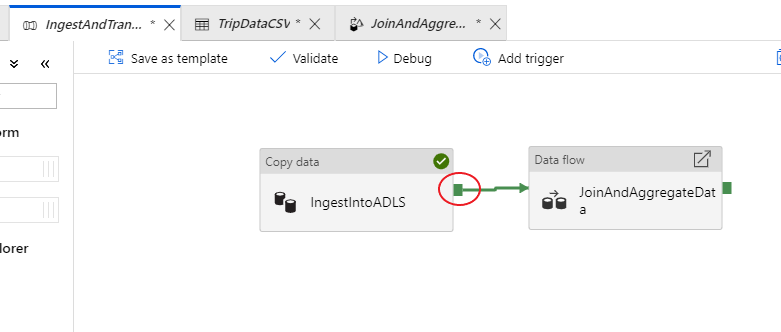
Precis som för kopieringsaktiviteten väljer du Felsök för att köra en felsökningskörning. För felsökningskörningar använder dataflödesaktiviteten det aktiva felsökningsklustret i stället för att skapa ett nytt kluster. Det tar lite mer än en minut att köra den här pipelinen.
Precis som kopieringsaktiviteten har dataflödet en särskild övervakningsvy som används av glasögonikonen när aktiviteten har slutförts.
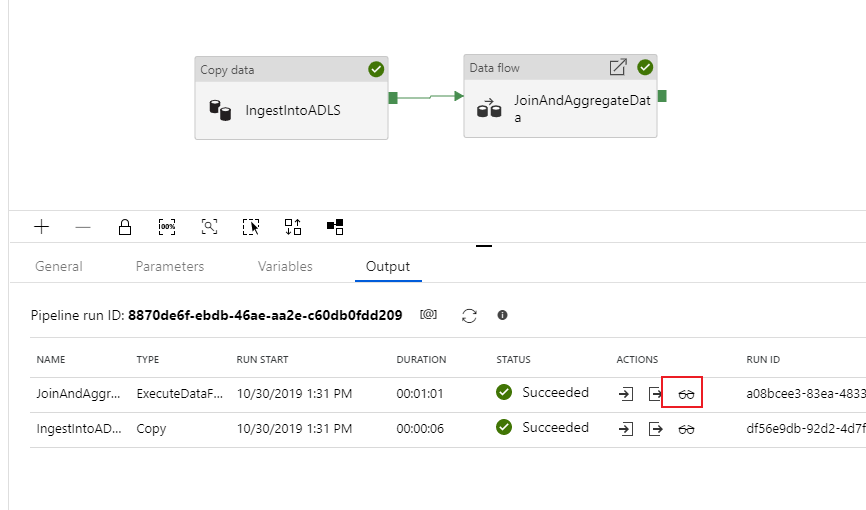
I övervakningsvyn kan du se ett förenklat dataflödesdiagram tillsammans med körningstiderna och raderna i varje körningssteg. Om det görs korrekt bör du ha aggregerat 49 999 rader till fem rader i den här aktiviteten.
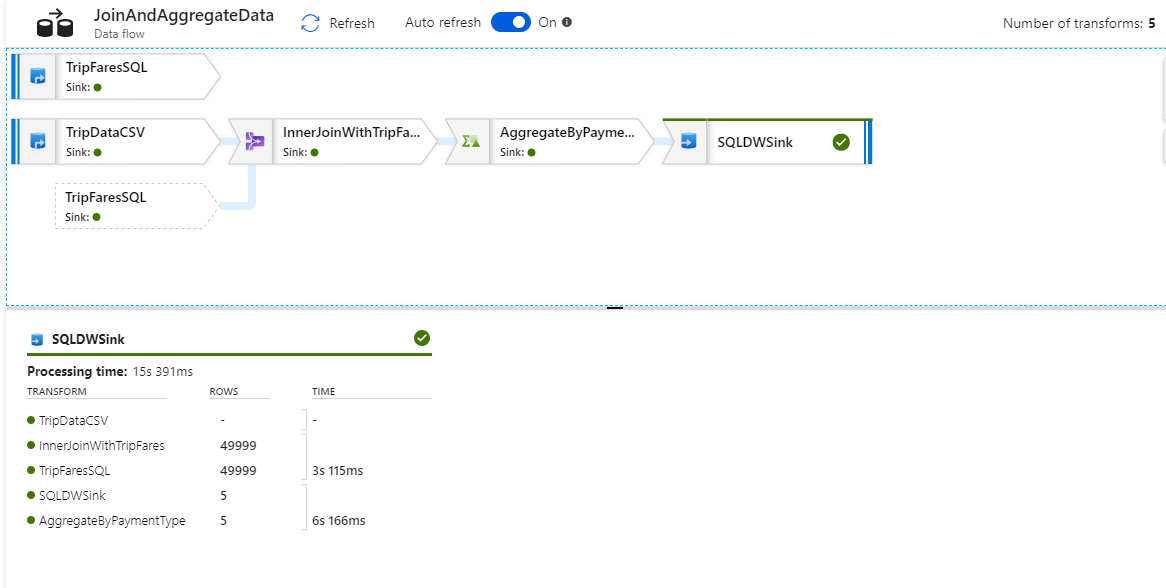
Du kan välja en transformering för att få ytterligare information om dess körning, till exempel partitioneringsinformation och nya/uppdaterade/borttagna kolumner.
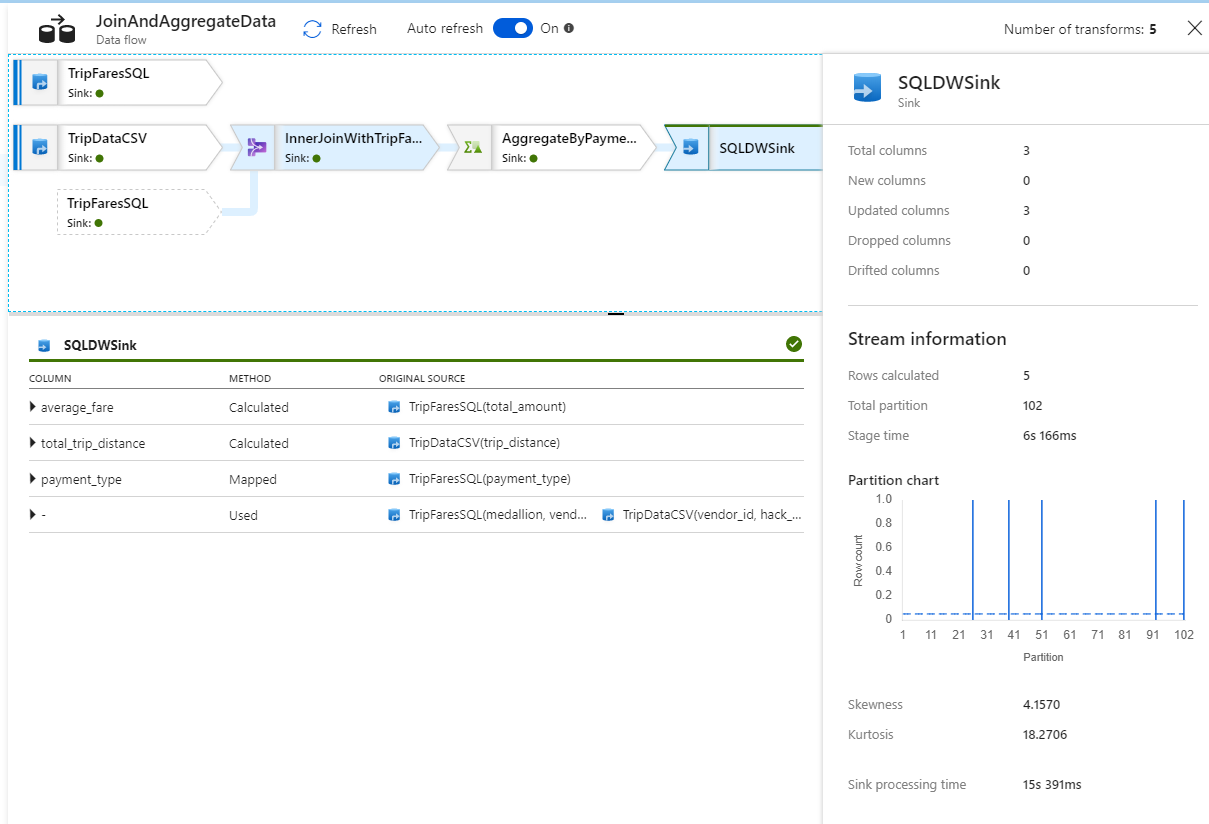




Nu har du slutfört datafabriksdelen av den här labbuppgiften. Publicera dina resurser om du vill operationalisera dem med utlösare. Du har kört en pipeline som matade in data från Azure SQL Database till Azure Data Lake Storage med hjälp av kopieringsaktiviteten och sedan aggregerade dessa data till en Azure Synapse Analytics. Du kan kontrollera att data har skrivits genom att titta på själva SQL Server.
Dela data med Azure Data Share
I det här avsnittet får du lära dig hur du konfigurerar en ny dataresurs med hjälp av Azure Portal. Det handlar om att skapa en ny dataresurs som innehåller datauppsättningar från Azure Data Lake Storage Gen2 och Azure Synapse Analytics. Sedan konfigurerar du ett schema för ögonblicksbilder som ger datakonsumenterna möjlighet att automatiskt uppdatera de data som delas med dem. Sedan bjuder du in mottagare till din dataresurs.
När du har skapat en dataresurs byter du sedan hattar och blir datakonsument. Som datakonsument går du igenom flödet för att acceptera en dataresursinbjudan, konfigurera var du vill att data ska tas emot och mappa datauppsättningar till olika lagringsplatser. Sedan utlöser du en ögonblicksbild som kopierar data som delas med dig till det angivna målet.
Dela data (dataproviderflöde)
Öppna Azure Portal i Microsoft Edge eller Google Chrome.
Använd sökfältet överst på sidan och sök efter dataresurser
Välj dataresurskontot med providern i namnet. Till exempel DataProvider0102.
Välj Börja dela dina data
Välj +Skapa för att börja konfigurera din nya dataresurs.
Under Resursnamn anger du ett valfritt namn. Det här är resursnamnet som visas av datakonsumenten, så se till att ge det ett beskrivande namn som TaxiData.
Under Beskrivning lägger du in en mening som beskriver innehållet i dataresursen. Dataresursen innehåller world-wide taxi trip data som lagras i en mängd olika butiker, inklusive Azure Synapse Analytics och Azure Data Lake Storage.
Under Användningsvillkor anger du en uppsättning villkor som du vill att datakonsumenten ska följa. Några exempel är "Distribuera inte dessa data utanför din organisation" eller "Referera till juridiskt avtal".
Välj Fortsätt.
Välj Lägg till datauppsättningar
Välj Azure Synapse Analytics för att välja en tabell från Azure Synapse Analytics som dina ADF-transformeringar landade i.
Du får ett skript att köra innan du kan fortsätta. Skriptet som tillhandahålls skapar en användare i SQL-databasen så att Azure Data Share MSI kan autentisera för dess räkning.
Viktigt!
Innan du kör skriptet måste du ange dig själv som Active Directory-administratör för den logiska SQL-servern i Azure SQL Database.
Öppna en ny flik och gå till Azure Portal. Kopiera skriptet som tillhandahålls för att skapa en användare i databasen som du vill dela data från. Gör detta genom att logga in på EDW-databasen med hjälp av Azure Portal Query-redigeraren med hjälp av Microsoft Entra-autentisering. Du måste ändra användaren i följande exempelskript:
CREATE USER [dataprovider-xxxx@contoso.com] FROM EXTERNAL PROVIDER; ALTER ROLE db_owner ADD MEMBER [wiassaf@microsoft.com];Växla tillbaka till Azure Data Share där du lade till datauppsättningar i din dataresurs.
Välj EDW och välj sedan AggregatedTaxiData för tabellen.
Välj Lägg till datauppsättning
Nu har vi en SQL-tabell som ingår i vår datauppsättning. Därefter lägger vi till ytterligare datauppsättningar från Azure Data Lake Storage.
Välj Lägg till datauppsättning och välj Azure Data Lake Storage Gen2
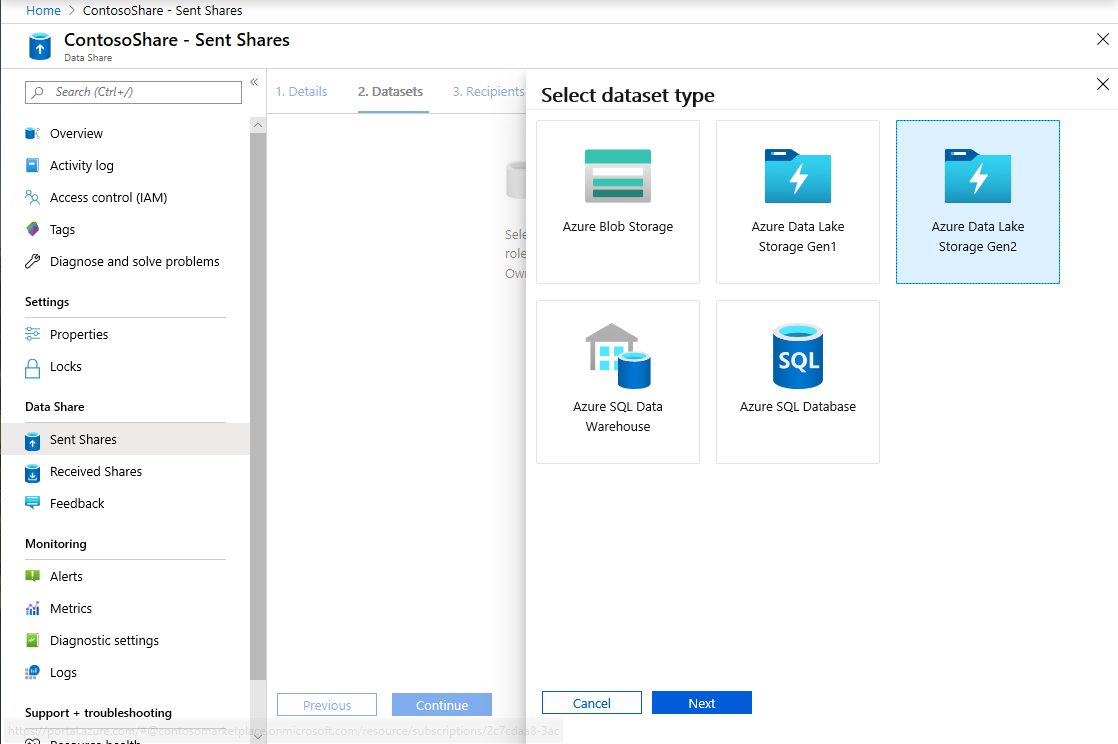
Välj Nästa
Expandera wwtaxidata. Expandera Boston Taxi Data. Du kan dela ned till filnivå.
Välj mappen Boston Taxi Data för att lägga till hela mappen i dataresursen.
Välj Lägg till datauppsättningar
Granska de datauppsättningar som har lagts till. Du bör ha en SQL-tabell och en ADLS Gen2-mapp tillagd i dataresursen.
Välj Fortsätt
På den här skärmen kan du lägga till mottagare i din dataresurs. Mottagarna som du lägger till får inbjudningar till din dataresurs. I den här labbuppgiften måste du lägga till två e-postadresser:
E-postadressen för den Azure-prenumeration du befinner dig i.
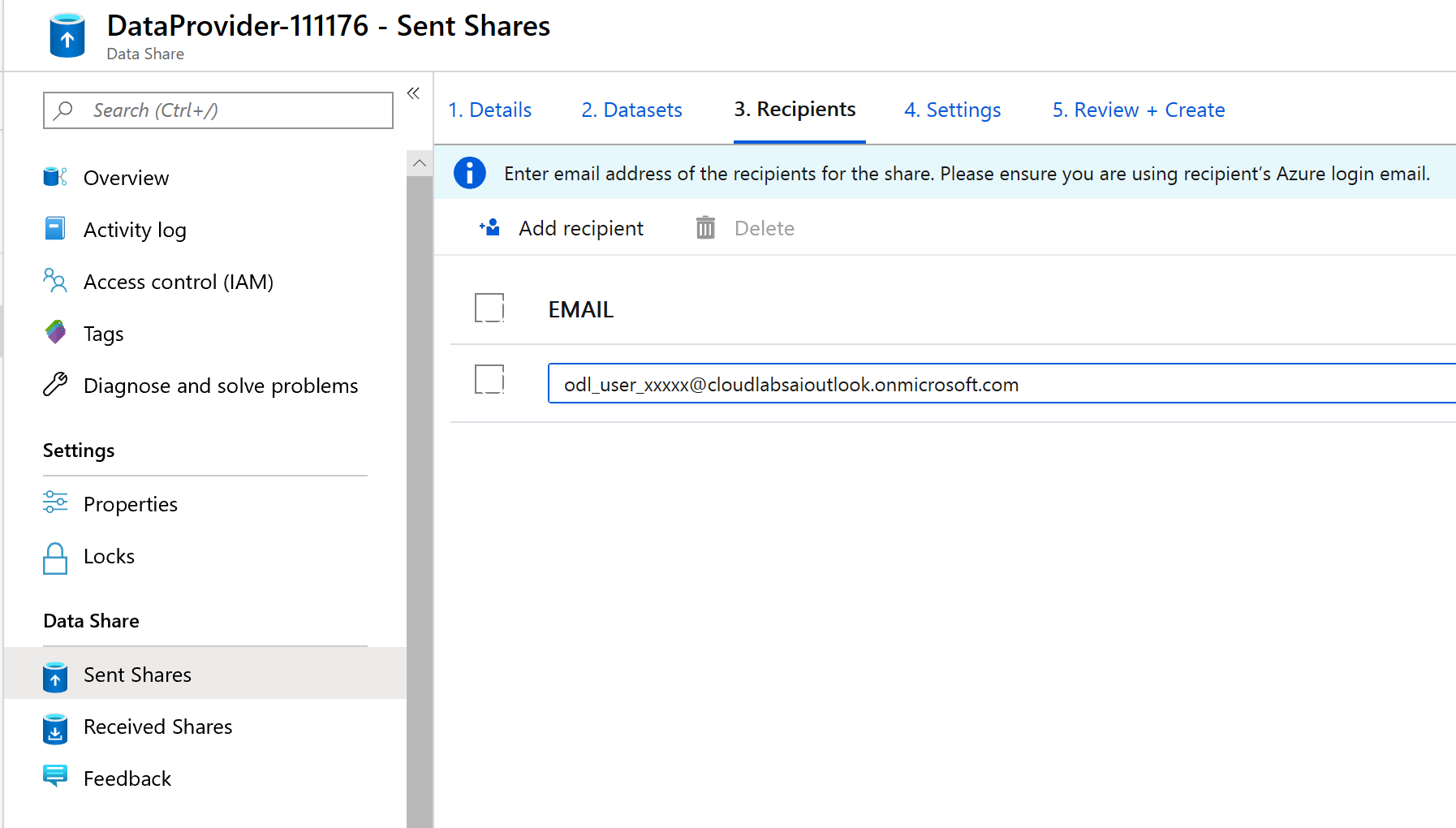
Lägg till den fiktiva datakonsumenten med namnet janedoe@fabrikam.com.
På den här skärmen kan du konfigurera en inställning för ögonblicksbilder för datakonsumenten. Detta gör att de kan ta emot regelbundna uppdateringar av dina data med ett intervall som definieras av dig.
Kontrollera schemat för ögonblicksbilder och konfigurera en uppdatering per timme av dina data med hjälp av listrutan Upprepning .
Välj Skapa.
Nu har du en aktiv dataresurs. Låt oss granska vad du kan se som en dataprovider när du skapar en dataresurs.
Välj den dataresurs som du skapade med titeln DataProvider. Du kan navigera till den genom att välja Skickade resurser i dataresurs.
Välj enligt schemat för ögonblicksbilder. Du kan inaktivera schemat för ögonblicksbilder om du vill.
Välj sedan fliken Datauppsättningar . Du kan lägga till ytterligare datauppsättningar i den här dataresursen när den har skapats.
Välj fliken Dela prenumerationer . Det finns inga resursprenumerationer ännu eftersom datakonsumenten ännu inte har accepterat din inbjudan.
Gå till fliken Inbjudningar . Här visas en lista över väntande inbjudningar.
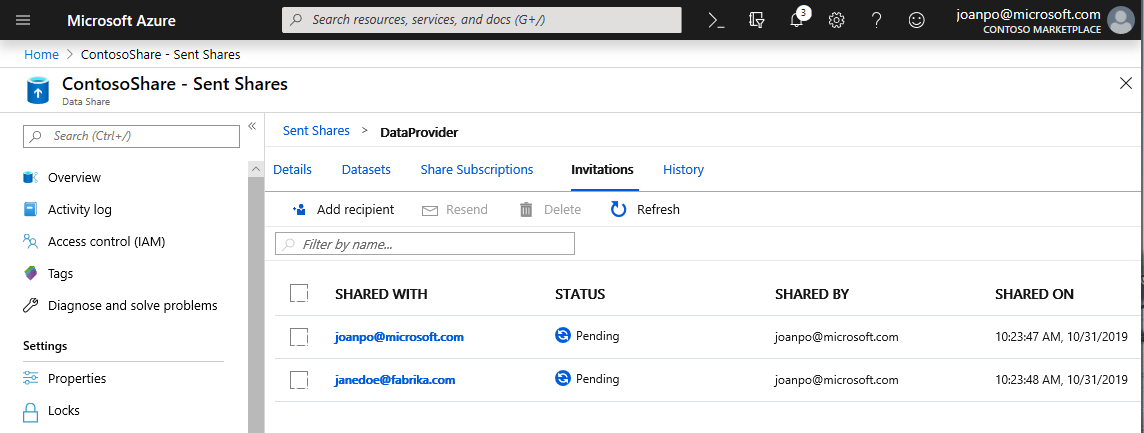
Välj inbjudan till janedoe@fabrikam.com. Välj Ta bort. Om mottagaren ännu inte har accepterat inbjudan kommer de inte längre att kunna göra det.
Välj fliken Historik . Ingenting visas ännu eftersom datakonsumenten ännu inte har accepterat din inbjudan och utlöst en ögonblicksbild.






Ta emot data (datakonsumentflöde)
Nu när vi har granskat vår dataresurs är vi redo att byta kontext och bära vår konsumenthatt för data.
Nu bör du ha en Azure Data Share-inbjudan i inkorgen från Microsoft Azure. Starta Outlook Web Access (outlook.com) och logga in med de autentiseringsuppgifter som angetts för din Azure-prenumeration.
I e-postmeddelandet som du borde ha fått väljer du "Visa inbjudan >". Nu ska du simulera datakonsumentupplevelsen när du accepterar en inbjudan från dataleverantörer till deras dataresurs.

Du kan uppmanas att välja en prenumeration. Se till att du väljer den prenumeration som du har arbetat i för det här labbet.
Välj på inbjudan med titeln DataProvider.
På den här inbjudningsskärmen ser du olika detaljer om dataresursen som du konfigurerade tidigare som dataprovider. Granska informationen och godkänn användningsvillkoren om det tillhandahålls.
Välj den prenumeration och resursgrupp som redan finns för labbet.
För Dataresurskonto väljer du DataConsumer. Du kan också skapa ett nytt dataresurskonto.
Bredvid Namnet på den mottagna resursen ser du att standardresursnamnet är det namn som angavs av dataprovidern. Ge resursen ett eget namn som beskriver de data som du ska ta emot, t.ex . TaxiDataShare.
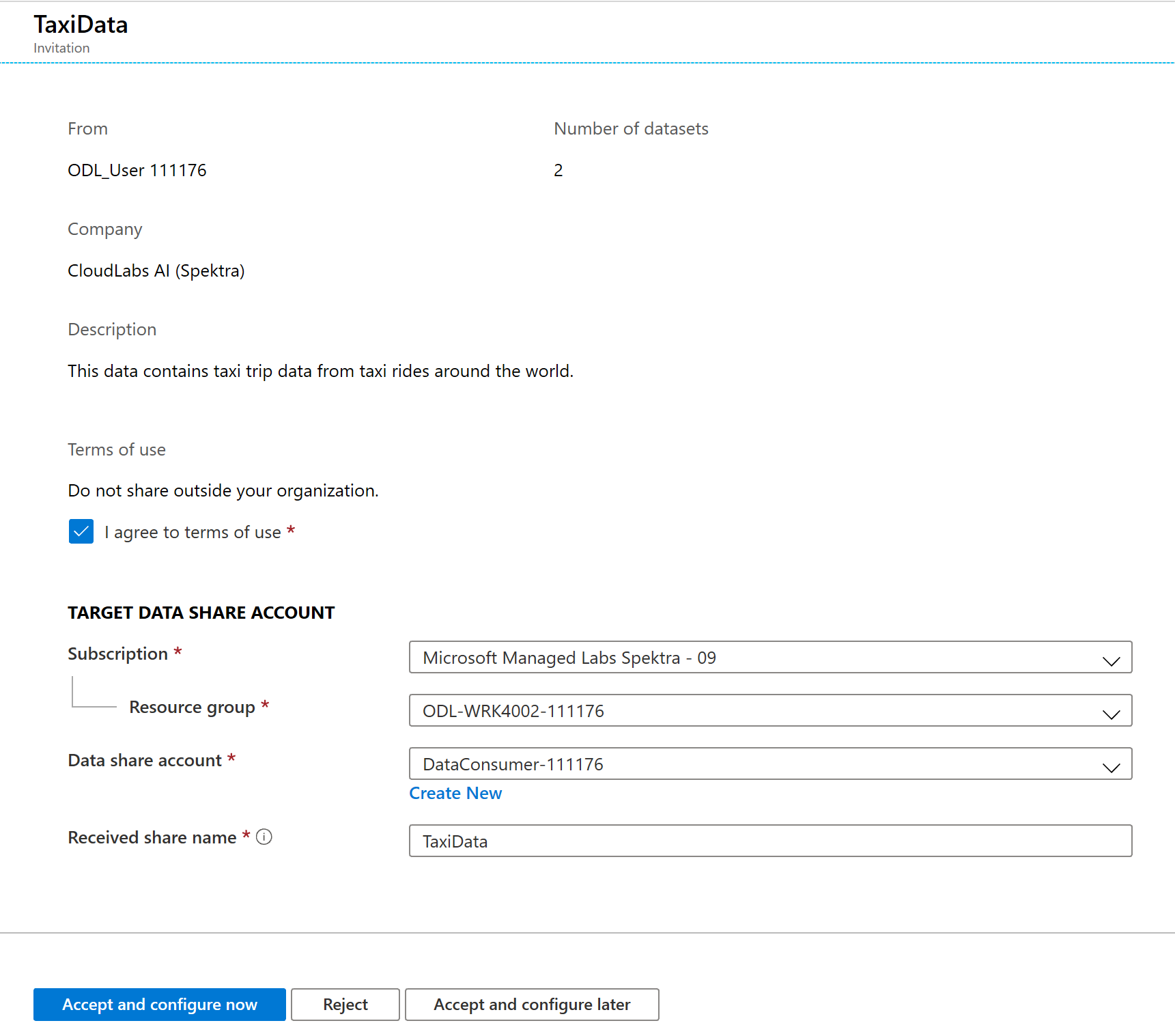
Du kan välja att Acceptera och konfigurera nu eller Acceptera och konfigurera senare. Om du väljer att acceptera och konfigurera nu anger du ett lagringskonto där alla data ska kopieras. Om du väljer att acceptera och konfigurera senare kommer datauppsättningarna i resursen att avmappas och du måste mappa dem manuellt. Vi kommer att välja det senare.
Välj Acceptera och konfigurera senare.
När du konfigurerar det här alternativet skapas en resursprenumeration, men det finns ingen plats för data att landa eftersom inget mål har mappats.
Konfigurera sedan datamängdsmappningar för dataresursen.
Välj den mottagna resursen (det namn som du angav i steg 5).
Ögonblicksbilden av utlösaren är nedtonad men resursen är Aktiv.
Välj fliken Datauppsättningar . Varje datauppsättning är Avmappad, vilket innebär att den inte har något mål att kopiera data till.
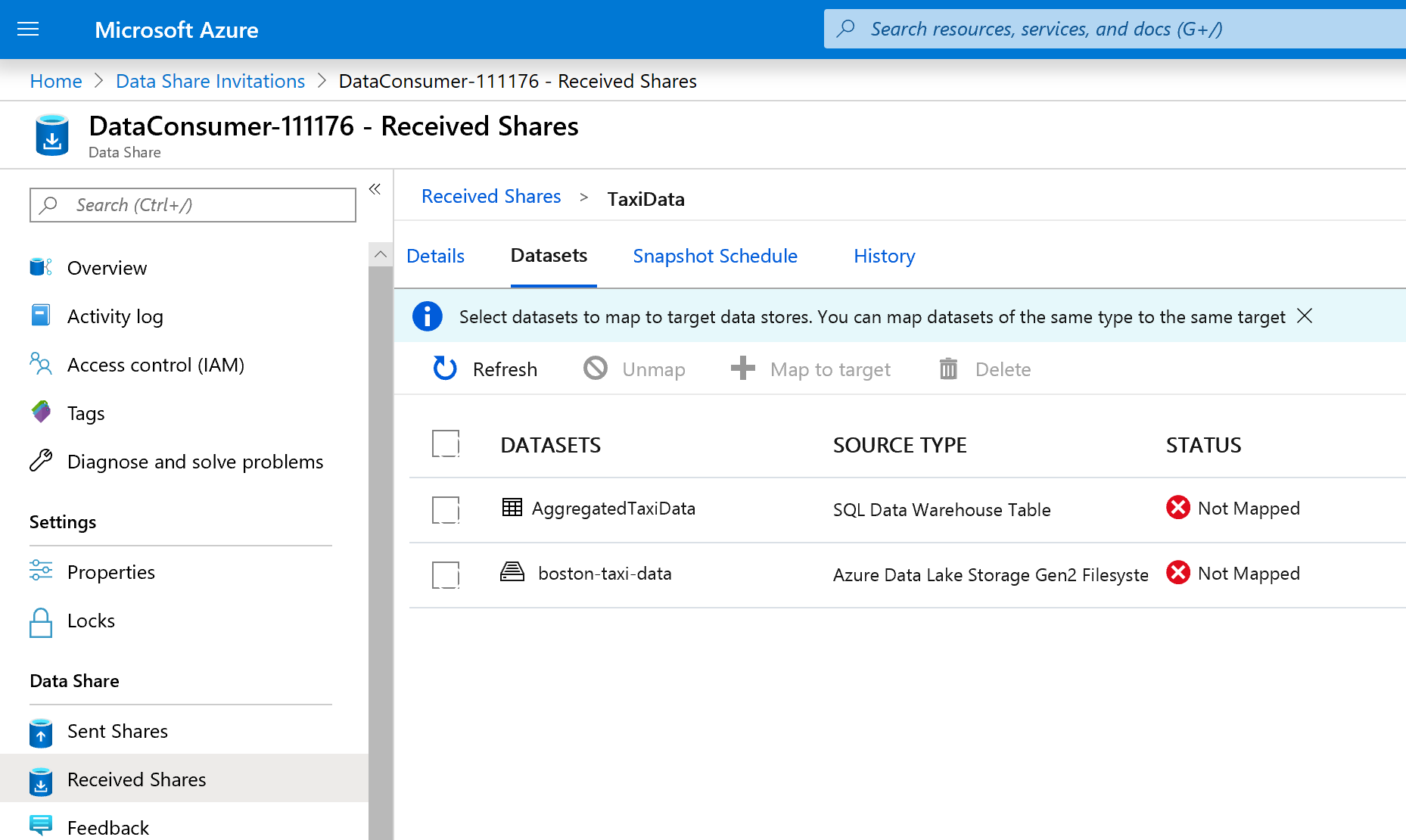
Välj tabellen Azure Synapse Analytics och välj sedan + Mappa till mål.
Välj listrutan Måldatatyp till höger på skärmen.
Du kan mappa SQL-data till en mängd olika datalager. I det här fallet mappas vi till en Azure SQL Database.
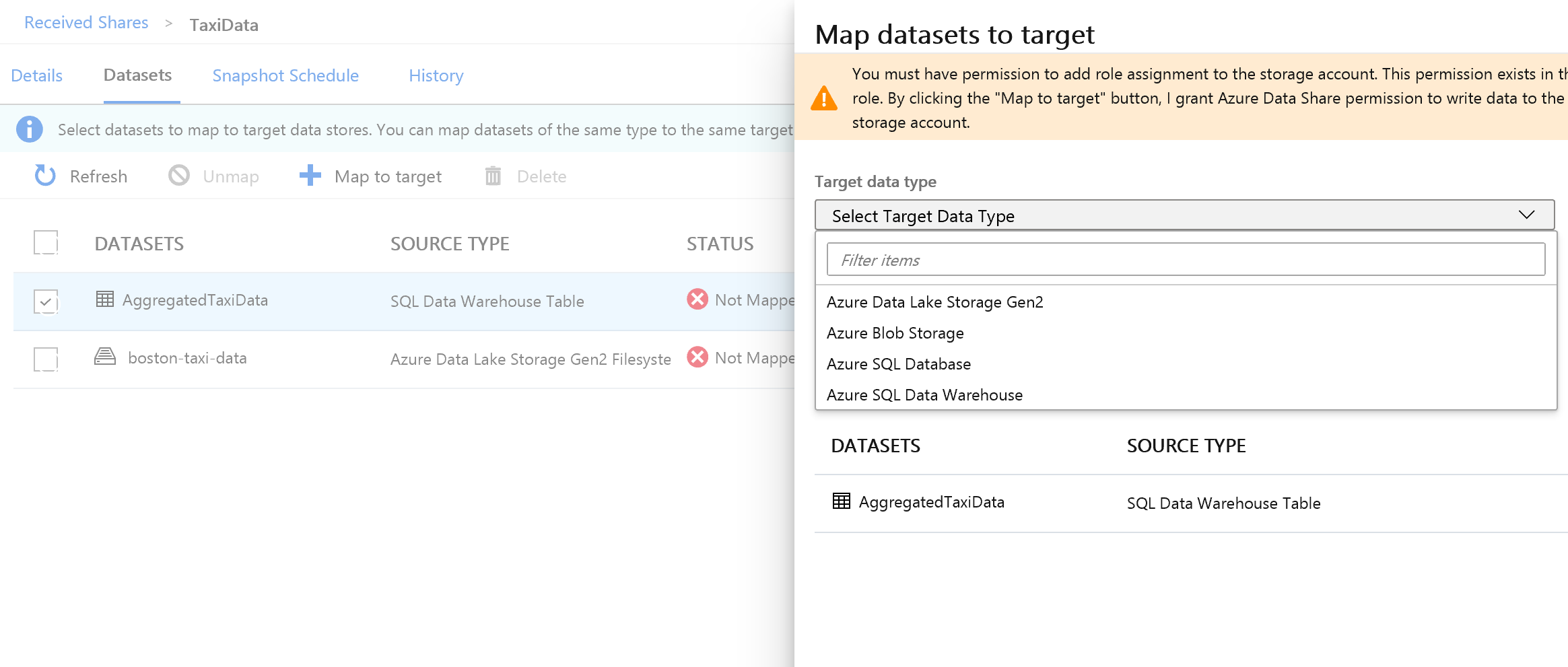
(Valfritt) Välj Azure Data Lake Storage Gen2 som måldatatyp.
(Valfritt) Välj det prenumerations-, resursgrupp- och lagringskonto som du har arbetat i.
(Valfritt) Du kan välja att ta emot data till din datasjö i csv- eller parquet-format.
Bredvid Måldatatyp väljer du Azure SQL Database.
Välj det prenumerations-, resursgrupp- och lagringskonto som du har arbetat i.

Innan du kan fortsätta måste du skapa en ny användare i SQL Server genom att köra det angivna skriptet. Kopiera först skriptet som tillhandahålls till Urklipp.
Öppna en ny Azure Portal flik. Stäng inte din befintliga flik eftersom du behöver komma tillbaka till den om en stund.
På den nya fliken som du öppnade går du till SQL-databaser.
Välj SQL-databasen (det bör bara finnas en i din prenumeration). Var försiktig så att du inte väljer informationslagret.
Välj Frågeredigeraren (förhandsversion)
Använd Microsoft Entra-autentisering för att logga in på frågeredigeraren.
Kör frågan som tillhandahålls i dataresursen (kopieras till Urklipp i steg 14).
Med det här kommandot kan Azure Data Share-tjänsten använda hanterade identiteter för Azure Services för att autentisera till SQL Server för att kunna kopiera data till den.
Gå tillbaka till den ursprungliga fliken och välj Mappa till mål.
Välj sedan mappen Azure Data Lake Storage Gen2 som ingår i datauppsättningen och mappa den till ett Azure Blob Storage-konto.

När alla datauppsättningar har mappats är du nu redo att börja ta emot data från dataprovidern.
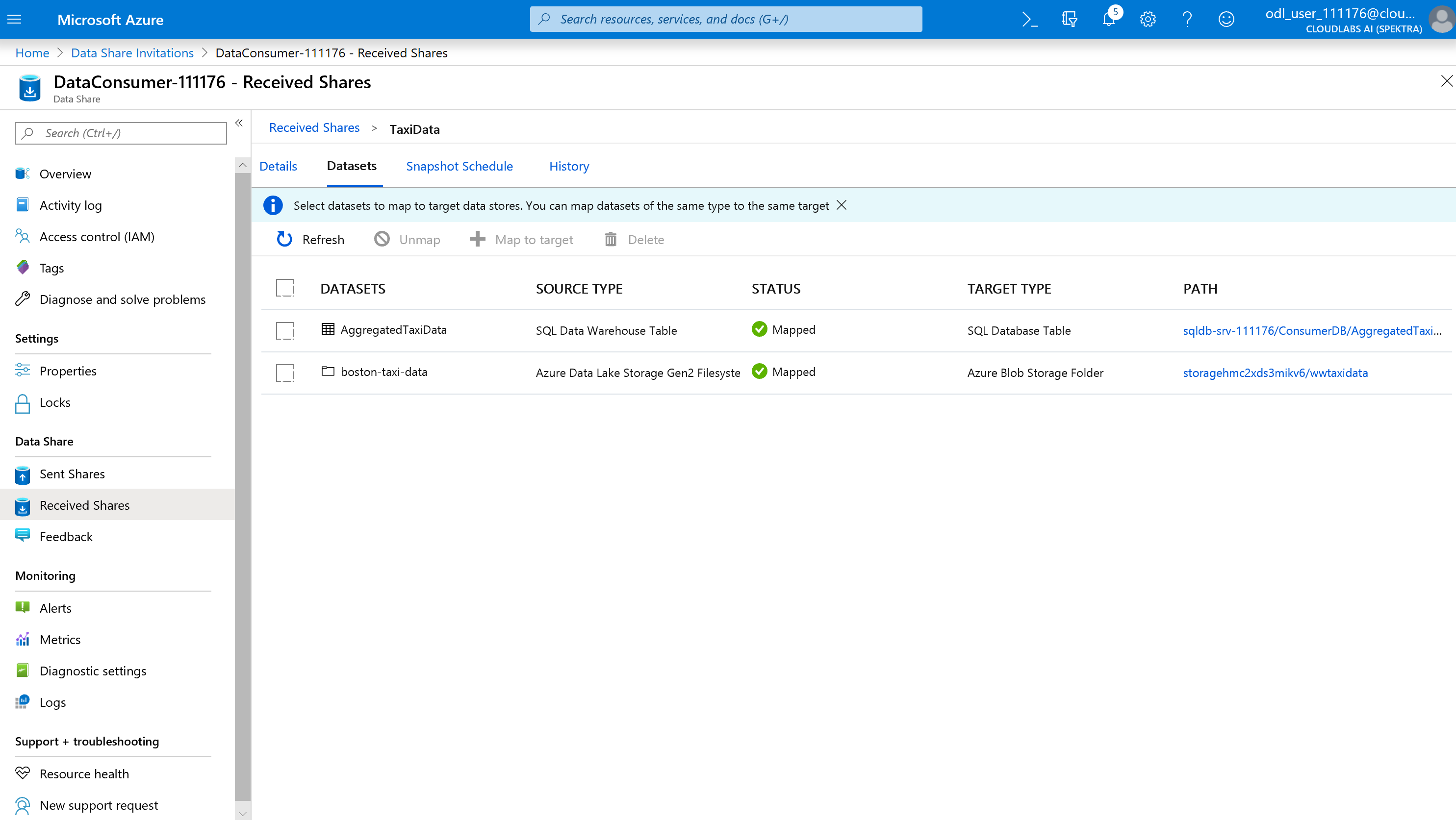
Välj detaljer.
Ögonblicksbilden av utlösaren är inte längre nedtonad eftersom dataresursen nu har mål att kopiera till.
Välj Utlösarögonblicksbild –> Fullständig kopia.
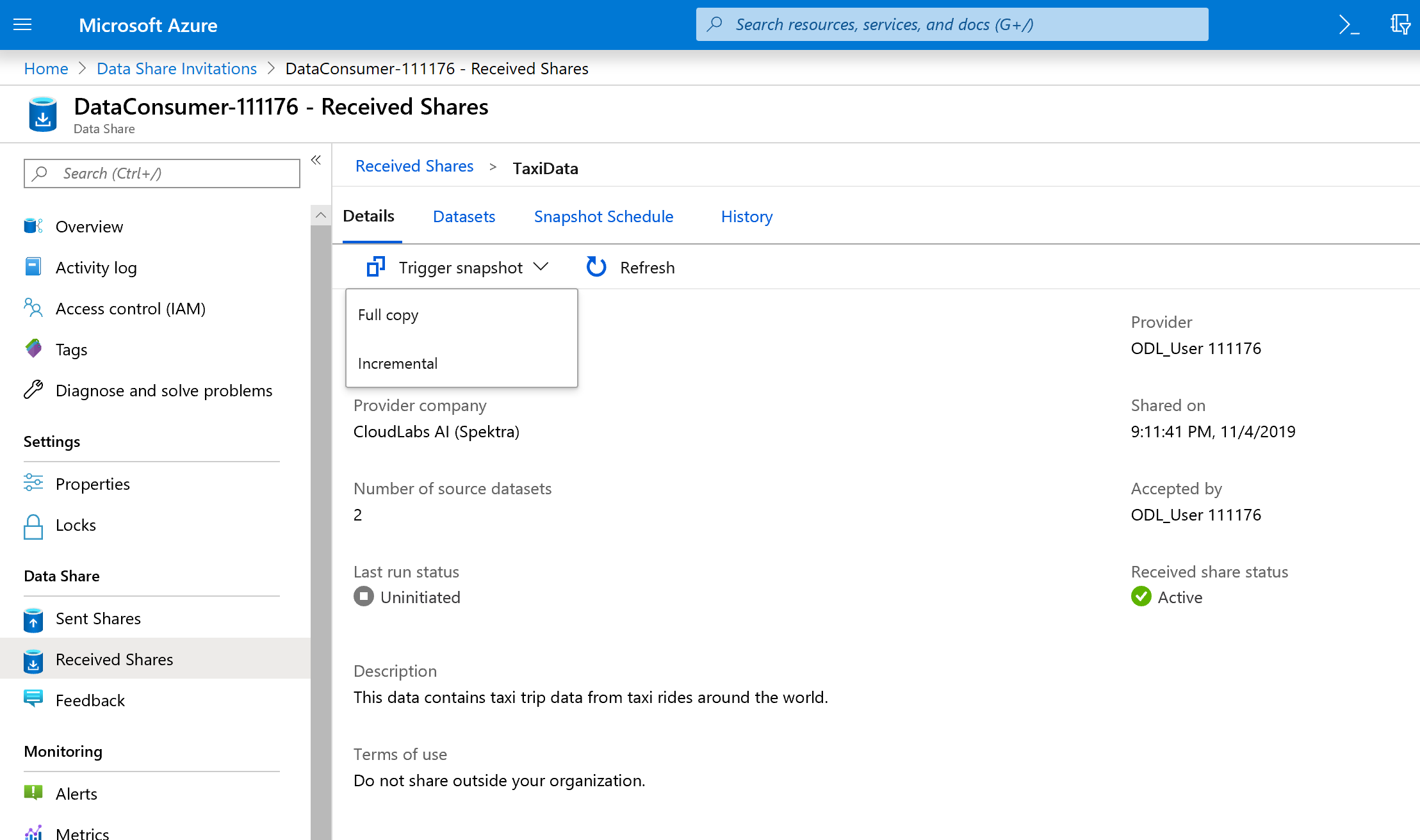
Detta börjar kopiera data till ditt nya dataresurskonto. I ett verkligt scenario skulle dessa data komma från en tredje part.
Det tar cirka 3–5 minuter för data att stöta på dem. Du kan övervaka förloppet genom att välja på fliken Historik .
Medan du väntar går du till den ursprungliga dataresursen (DataProvider) och visar status för fliken Dela prenumerationer och historik . Det finns nu en aktiv prenumeration, och som dataprovider kan du även övervaka när datakonsumenten har börjat ta emot data som delas med dem.
Gå tillbaka till datakonsumentens dataresurs. När statusen för utlösaren har lyckats navigerar du till SQL-måldatabasen och datasjön för att se att data har landat i respektive lager.







Grattis, du har slutfört labbet!